2.4 Методы прогнозной экстраполяции
При формировании прогнозов с помощью экстраполяции обычно исходят из статистически складывающихся тенденций изменения тех или иных количественных характеристик объекта. Экстраполируются оценочные функциональные системные и структурные характеристики. Экстраполяционные методы являются одними из самых распространенных и наиболее разработанных среди всей совокупности методов прогнозирования.
С помощью этих методов экстраполируются количественные параметры больших систем, количественные характеристики экономического, научного, производственного потенциала, данные о результативности научно-технического прогресса, характеристики соотношения отдельных подсистем, блоков, элементов в системе показателей сложных систем и др.
Однако степень реальности такого рода прогнозов и соответственно мера доверия к ним в значительной мере обусловливаются аргументированностью выбора пределов экстраполяции и стабильностью соответствия «измерителей» по отношению к сущности рассматриваемого явления. Следует обратить внимание на то, что сложные объекты, как правило, не могут быть охарактеризованы одним параметром. В связи с этим можно сделать некоторое представление о последовательности действий при статистическом анализе тенденций и экстраполировании, которое состоит в следующем:
— во-первых, должно быть четкое определение задачи, выдвижение гипотез о возможном развитии прогнозируемого объекта, обсуждение факторов, стимулирующих и препятствующих развитию данного объекта, определение необходимой экстраполяции и её допустимой дальности;
— во-вторых, выбор системы параметров, унификация различных единиц измерения, относящихся к каждому параметру в отдельности;
— в-третьих, сбор и систематизация данных. Перед сведением их в соответствующие таблицы еще раз проверяется однородность данных и их сопоставимость: одни данные относятся к серийным изделиям, а другие могут характеризовать лишь конструируемые объекты;
— в-четвертых, когда вышеперечисленные требования выполнены, задача состоит в том, чтобы в ходе статистического анализа и непосредственной экстраполяции данных выявить тенденции или симптомы изменения изучаемых величин. В экстраполяционных прогнозах особо важным является не столько предсказание конкретных значений изучаемого объекта или параметра в таком-то году, сколько своевременное фиксирование объективно намечающихся сдвигов, лежащих в зародыше назревающих тенденций.
Для повышения точности экстраполяции используются различные приемы. Один из них состоит, например, в том, чтобы экстраполируемую часть общей кривой развития (тренда) корректировать с учетом реального опыта развития отрасли-аналога исследований или объекта, опережающих в своем развитии прогнозируемый объект.
Под трендом понимается характеристика основной закономерности движения во времени, в некоторой мере свободной от случайных воздействий. Тренд — это длительная тенденция изменения экономических показателей. При разработке моделей прогнозирования тренд оказывается основной составляющей прогнозируемого временного ряда, на которую уже накладываются другие составляющие. Результат при этом связывается исключительно с ходом времени. Предполагается, что через время можно выразить влияние всех основных факторов.
Под тенденцией развития понимают некоторое его общее направление, долговременную эволюцию. Обычно тенденцию стремятся представить в виде более или менее гладкой траектории.
Анализ показывает, что ни один из существующих методов не может дать достаточной точности прогнозов на 20-25 лет. Применяемый в прогнозировании метод экстраполяции не дает точных результатов на длительный срок прогноза, потому что данный метод исходит из прошлого и настоящего, и тем самым погрешность накапливается. Этот метод дает положительные результаты на ближайшую перспективу прогнозирования тех или иных объектов не более 5 лет.
Для нахождения параметров приближенных зависимостей между двумя или несколькими прогнозируемыми величинами по их эмпирическим значениям применяется метод наименьших квадратов. Его сущность состоит в минимизации суммы квадратов отклонений между наблюдаемыми (фактическими) величинами и соответствующими оценками (расчетными величинами), вычисленными по подобранному уравнению связи.
Этот метод лучше других соответствует идее усреднения как единичного влияния учтенных факторов, так и общего влияния неучтенных.
Рассмотрим простейшие приемы экстраполяции. Операцию экстраполяции в общем виде можно представить в виде определения значения функции:
![]() , (2.7)
, (2.7)
где ![]() — экстраполируемое значение уровня; L – период упреждения; Уt – уровень, принятый за базу экстраполяции.
— экстраполируемое значение уровня; L – период упреждения; Уt – уровень, принятый за базу экстраполяции.
Под периодом упреждения при прогнозировании понимается отрезок времени от момента, для которого имеются последние статистические данные об изучаемом объекте, до момента, к которому относится прогноз.
Экстраполяция на основе среднего значения временного ряда. В самом простом случае при предположении о том, что средний уровень ряда не имеет тенденции к изменению или если это изменение незначительно, можно принять![]() т.е. прогнозируемый уровень равен среднему значению уровней в прошлом.
т.е. прогнозируемый уровень равен среднему значению уровней в прошлом.
Доверительные границы для средней при небольшом числе наблюдений определяются следующим образом:
![]() (2.8)
(2.8)
где ta – табличное значение t – статистики Стьюдента с n-1 степенями и уровнем вероятности p;![]() — средняя квадратическая ошибка средней величины. Значение ее определяется по формуле . В свою очередь, среднее квадратическое отклонение для выборки равно:
— средняя квадратическая ошибка средней величины. Значение ее определяется по формуле . В свою очередь, среднее квадратическое отклонение для выборки равно:
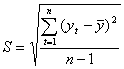 (2.9)
(2.9)
где yt – фактические значения показателя.
Доверительный интервал, полученный как ta![]() , учитывает неопределенность, которая связана с оценкой средней величины.
, учитывает неопределенность, которая связана с оценкой средней величины.
Общая дисперсия, связанная как с колеблемостью выборочной средней, так и с варьированием ндивидуальных значений вокруг средней, составит величину S2+S2/n. Таким образом, доверительные интервалы для прогностической оценки равны:
![]() (2.10)
(2.10)
Экстраполяция по скользящей и экспоненциальной средней. Для краткосрочного прогнозирования наряду с другими приемами могут быть применены адаптивная или экспоненциальная скользящие средние. Если прогнозирование ведется на один шаг вперед, то ![]() или
или ![]() , где Мt — адаптивная скользящая средняя; Nt — экспоненциальная средняя. Здесь доверительный интервал для скользящей средней можно определить по формуле (2.10), в которой число наблюдений обозначено символом n. Поскольку при расчете скользящей средней через m обозначалось число членов ряда, участвующих в расчете средней, то заменим в этой формуле n на m, равным нечетным числам.
, где Мt — адаптивная скользящая средняя; Nt — экспоненциальная средняя. Здесь доверительный интервал для скользящей средней можно определить по формуле (2.10), в которой число наблюдений обозначено символом n. Поскольку при расчете скользящей средней через m обозначалось число членов ряда, участвующих в расчете средней, то заменим в этой формуле n на m, равным нечетным числам.
При экспоненциальном сглаживании дисперсия экспоненциальной средней равна ![]() , где S -среднее квадратическое отклонение, вместо величины
, где S -среднее квадратическое отклонение, вместо величины ![]() в формуле (2.10) при исчислении доверительного интервала прогноза следует взять величину
в формуле (2.10) при исчислении доверительного интервала прогноза следует взять величину ![]() или
или ![]() . Здесь a— коэффициент экспоненциального сглаживания, изменяется от 0 до 1. Если 0<a<0,5, то при расчете прогноза учитываются прошлые значения временного ряда, а при 0,5<a<1 – значения, близкие к периоду упреждения. Примерное значение коэффициента сглаживания определяют по формуле Р.Брауна:
. Здесь a— коэффициент экспоненциального сглаживания, изменяется от 0 до 1. Если 0<a<0,5, то при расчете прогноза учитываются прошлые значения временного ряда, а при 0,5<a<1 – значения, близкие к периоду упреждения. Примерное значение коэффициента сглаживания определяют по формуле Р.Брауна:
![]() (2.11)
(2.11)
где m – число уровней временного ряда, входящих в интервал сглаживания.
Экстраполяция на основе среднего темпа. Если в основу прогностического расчета положен средний темп роста, то экстраполируемое значение уровня можно получить с помощью формулы: ![]() ,
, ![]() где — средний темп роста, Уt — уровень, принятый за базу для экстраполяции. Здесь принят только один путь развития — развитие по геометрической прогрессии, или по экспонентной кривой. Во многих же случаях фактическое развитие явления следует иному закону, и экстраполяция по среднему темпу нарушает основное допущение, принимаемое при экстраполяции, — допущение о том, что развитие будет следовать основной тенденции — тренду, наблюдавшемуся в прошлом. Чем больше фактический тренд отличается от экспоненты, тем больше данные, получаемые при экстраполяции тренда, будут отличаться от экстраполяции на основе среднего темпа.
где — средний темп роста, Уt — уровень, принятый за базу для экстраполяции. Здесь принят только один путь развития — развитие по геометрической прогрессии, или по экспонентной кривой. Во многих же случаях фактическое развитие явления следует иному закону, и экстраполяция по среднему темпу нарушает основное допущение, принимаемое при экстраполяции, — допущение о том, что развитие будет следовать основной тенденции — тренду, наблюдавшемуся в прошлом. Чем больше фактический тренд отличается от экспоненты, тем больше данные, получаемые при экстраполяции тренда, будут отличаться от экстраполяции на основе среднего темпа.
Средний темп или определяется на основе изучения прошлого, или оценивается каким-либо другим путем (например, подбор вариантов для различных ситуаций). В качестве исходного (базового) уровня для экстраполяции представляется естественным взять последний уровень ряда, поскольку будущее развитие начинается именно с этого уровня.
Статистическая надежность вышеприведенных методов оценивается с помощью коэффициента вариации:
![]() (2.12)
(2.12)
где![]() — среднее квадратическое отклонение;
— среднее квадратическое отклонение;
![]() — среднее значение временного ряда.
— среднее значение временного ряда.
Метод считается статистически надежным и может быть использован для прогнозирования, если значение коэффициента вариации не превышает 10%.
Однофакторные прогнозирующие функции
Это такие функции, в которых прогнозируемый показатель зависит только от одного факториального признака.
В научно-техническом и экономическом прогнозировании в качестве главного фактора аргумента обычно используют время. Вполне очевидно, что не ход времени определяет величины прогнозируемого показателя, а действие многочисленных влияющих на него факторов. Однако каждому моменту времени соответствуют определенные характеристики всех этих факториальных признаков, которые со временем в той или иной мере изменяются. Таким образом, время можно рассматривать как интегральный показатель суммарного воздействия всех факториальных признаков.
В качестве фактора-аргумента в однофакторной прогнозирующей функции можно использовать не только время, но и другие факторы, если известна их количественная оценка на перспективу.
Наиболее простым из методов прогнозирования является экстраполяция тренда явления (процесса) за истекший период. Тренд (или вековая тенденция) характеризует процесс изменения показателя за длительное время, исключая случайные колебания. Тренд явления находят путем аппроксимации фактических уровней временного ряда на основе выбранной функции. Наиболее часто применяемые при прогнозировании функции показаны в табл. 2.3. В них фактор-аргумент обозначен символом t.
Таблица 2.3 Однофакторные прогнозирующие функции
|
Наименования функции |
Вид функции |
|
Степенной полином |
y = a0 + a1t + a2t2 +…antn |
|
Парабола |
y=a0+a1t+a2t2 |
|
Линейная функция |
у = а0+а1t |
|
Экспоненциальная (показательная) |
|
|
Степенная |
|
|
Логарифмическая |
у = а0+а1lnt |
|
Комбинация линейной и логарифмической функций |
у = а0+a1t+а2lnt |
|
Функция Конюса |
|
|
Функция Торнквиста |
|
|
Логистическая (сигмоидальная) |
|
|
Частный случай логистической функции |
|
|
Гипербола |
|
|
Комбинация линейной функции и гиперболы |
у = а0+а1t + |
При прогнозировании колебательных (циклических) процессов применяют тригонометрические функции, ряды Фурье.
Степенной полином может описать любые процессы изменения показателя y в зависимости от значений t. Корреляционное отношение для степенного полинома, служащее мерой тесноты корреляционной связи в нелинейных моделях, приближается к единице по мере увеличения числа степеней полинома до числа уровней временного ряда. Одновременно линия регрессии приближается к фактическим уровням показателя за прошедшее время, что не позволяет установить его тренд и экстраполировать его на перспективу. Поэтому для прогнозирования обычно не применяют полином выше третьей степени. Таким образом, в качестве прогнозирующей функции целесообразно использовать лишь три частных случая степенного полинома: линейную модель, параболу и полином третьего порядка.
Однофакторная линейная модель отражает постоянный ежегодный абсолютный прирост в размере a1, т.е. арифметическую прогрессию. Парабола (степенной полином) второго порядка описывает случаи увеличения абсолютного ежегодного прироста на постоянную величину 2a2, а третьего порядка – S – образную кривую с двумя точками изгибов.
Экспонента первого порядка (показательная функция) предусматривает постоянный ежегодный темп роста, равный ![]() процентов (т.е. геометрическую прогрессию), а второго порядка – постоянное увеличение ежегодных темпов роста в
процентов (т.е. геометрическую прогрессию), а второго порядка – постоянное увеличение ежегодных темпов роста в ![]() раз. Степенная функция соответствует случаю ускоряющегося при а1>1 или замедляющегося при а1<1 роста абсолютного ежегодного прироста. Логарифмическая функция выражает случай сокращения абсолютного ежегодного прироста, а функции Торнквиста и Конюса, комбинация линейной функции с логарифмической – затухающий рост абсолютного ежегодного прироста. Логистическая (сигмоидальная) кривая представляет собой модифицированную геометрическую прогрессию, в которой возрастание затухает по мере приближения к определенному пределу. Наконец, гиперболы характерны для тех случаев, когда в начальной стадии абсолютные уровни показателя резко сокращаются, а на последующих этапах этот процесс сокращения постепенно затухает
раз. Степенная функция соответствует случаю ускоряющегося при а1>1 или замедляющегося при а1<1 роста абсолютного ежегодного прироста. Логарифмическая функция выражает случай сокращения абсолютного ежегодного прироста, а функции Торнквиста и Конюса, комбинация линейной функции с логарифмической – затухающий рост абсолютного ежегодного прироста. Логистическая (сигмоидальная) кривая представляет собой модифицированную геометрическую прогрессию, в которой возрастание затухает по мере приближения к определенному пределу. Наконец, гиперболы характерны для тех случаев, когда в начальной стадии абсолютные уровни показателя резко сокращаются, а на последующих этапах этот процесс сокращения постепенно затухает
Коэффициенты в однофакторных прогнозирующих функциях а0 и а1 определяются с помощью метода наименьших квадратов, сущность которого заключается в минимизации суммы квадратов отклонений фактических значений от расчетных:
![]() (2.13)
(2.13)
где![]() — вид исследуемой функции (см. табл.2.3)
— вид исследуемой функции (см. табл.2.3)
Пусть временной ряд может быть описан линейной функцией:
![]() .
.
Подставим это выражение в формулу (2.13), получим:
![]() .
.
Возьмем частные производные по а0 и а1:
![]() ,
,
![]() .
.
В результате алгебраических преобразований данной системы: (сокращений, раскрытия скобок, переноса известных величин вправо, а неизвестных влево) — получим систему нормальных уравнений:
Из первого уравнения найдем а0, из второго – а1.
Формулы расчета а0 и а1 имею вид:
![]()
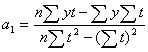 (2.14)
(2.14)
или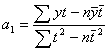
Прогнозируемые значения показателя у определяется по формуле:
![]() =а0+а1(t+L), где L=1,2,…,(2.15)
=а0+а1(t+L), где L=1,2,…,(2.15)
если фактором-аргументом является время t. В случае, когда фактор-аргумент – независимая переменная (любой показатель х) то необходимо найти его прогнозируемые значения. Тогда:
![]() =а0+а1хt+L, где L=1,2,… (2.16)
=а0+а1хt+L, где L=1,2,… (2.16)
Для оценки качества и надежности анализа регрессии используются следующие показатели: корреляционное отношение (η), коэффициент парной корреляции (r), коэффициент детерминации (r2), средняя ошибка предвидения (Sс), средняя ошибка коэффициента регрессии (Sаj, j=0, 1,2, …).
Корреляционное отношение (η) указывает на степень взаимозависимости между у и х. Принимает значения между 0 и 1:
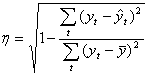 (2.17)
(2.17)
Коэффициент парной корреляции может быть определен по формуле:
![]() (2.18)
(2.18)
где S11, S22, S12 – соответственно остаточные дисперсии для функции, фактора-аргумента и их произведения: определяются по формулам:
![]() ;
;
![]() ;
;
![]() .
.
Коэффициент корреляции, рассчитывается по формуле (2.18) и принимает значения от -1 до +1. Чем ближе значения коэффициента к единице, тем большая связь существует между функцией и аргументом.
Для проверки гипотезы о наличии связи определим критерий Стьюдента:
![]() (2.19)
(2.19)
Если tr>tтабл, то принимаем гипотезу о наличии связи, в противном случае – она отсутствует.
Коэффициент детерминации (r2) показывает, насколько уравнение регрессии подходит к значениям временного ряда или какой процент составляют учтенные факторы в уравнении регрессии.
Точность регрессионной модели определяется с помощью средней ошибки предвидения или среднего отклонения по формуле:
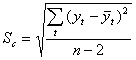 (2.20)
(2.20)
Средняя ошибка коэффициентов регрессии определяется по формуле:
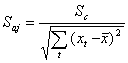 (2.21)
(2.21)
или 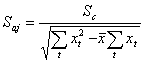 ,
,
где j=1, 2, … , m; m – число факторов;
t=1, 2, … , n; n – число данных.
Оценка Стьюдента (tаj) показывает удельный вес фактора-аргумента х при объяснении у. Она вычисляется делением коэффициентов aj на их средние ошибки Saj:
![]() (2.22)
(2.22)
Оценка Стьюдента показывает, во сколько раз значения j-го коэффициента превосходят его среднюю ошибку. Любое значение taj больше 2 или меньше -2 считается приемлемым. Чем больше величина taj, тем больше значимость коэффициентов регрессии, тем надежнее уравнение регрессии.
Статистическая надежность аппроксимирующей функции или коэффициента парной корреляции устанавливается также с помощью критерия Стьюдента (2.19).
С вероятностью ошибки р и с (n-2) степенями свободы выбранная функция признается статистически надежной, если рассчитанное значение критерия tr превышает табличное.
Ошибкой прогноза называется отклонение предсказанного значения от наблюдаемого (фактического). Для оценки совокупной ошибки прогноза используются два показателя: средняя абсолютная ошибка ( ![]() ) и средняя относительная ошибка (
) и средняя относительная ошибка ( ![]() ), которые определяются по формулам:
), которые определяются по формулам:
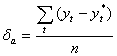 (2.23)
(2.23)
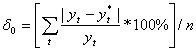 (2.24)
(2.24)
С помощью метода наименьших квадратов могут быть определены а0 и а1 во всех однофакторных прогнозирующих функциях, если эти функции предварительно линеаризовать, т.е. преобразовать в линейную модель. Линеаризация достигается логарифмированием или получением обратных значений функции, а также заменой переменных, представляющих собой преобразованные значения показателей у и t.
Многофакторные прогнозирующие функции
Каждый прогнозируемый показатель уt (t=1,2…,n) можно рассматривать не только как функцию одного фактора-аргумента, но и от нескольких:
— в виде линейной многофакторной модели:
уt=а0+а1х1t+а2х2t+…+аjхjt+…+аmхmt(2.25)
где а0, аj – коэффициенты модели при j=1, 2, … , k;
хjt – факторы-аргументы, влияющие на прогнозируемый показатель уt, при j=1, 2, … , m; t=1,2,…, n;
— в виде нелинейной многофакторной модели (степенного типа):
![]() (2.26)
(2.26)
которая путем логарифмирования преобразуется в линейную. Более сложные виды нелинейных многофакторных моделей редко используются в практике прогнозирования и планирования.
Коэффициенты а0, аj в моделях типа (2.25) и (2.26) определяются с помощью метода наименьших квадратов (2.13) из системы нормальных уравнений, представляющих собой частные производные по а0, аj равные нулю:
В результате решения данной системы уравнений находятся такие а0 и аj, при которых (2.13) стремится к нулю.
Факторы-аргументы должны отвечать следующим условиям: во-первых, иметь количественное измерение и отражаться в отчетах или, по крайней мере, определяться на основе специального анализа отчетных данных; во-вторых, иметь перспективные оценки значений на прогнозируемый период; в-третьих, число включаемых в модель факторов должно быть меньше числа данных ряда в три раза; в-четвертых, быть линейно независимыми.
Факторы считаются зависимыми (мультиколлинеарными), если линейный (парный) коэффициент корреляции (см. формулу 2.18) двух факторов более 0,8. Из них в модели оставляют тот, который имеет больший коэффициент корреляции с функцией у.
Оптимальное количество факторов-аргументов можно установить с помощью так называемого метода исключений. Сущность его заключается в следующем.
В модель типа (2.25) включают все возможные факторы, удовлетворяющие указанным выше условиям и строят эту модель. Для каждого j-го фактора-аргумента по формуле (2.22) находят оценки Стьюдента. Выбирают наименьшую величину оценки min ta1 и сравнивают с табличным значением – tp при (n-k-1) – степенях свободы и выбранном уровне значимости р (обычно принимают р=0,05 или 5%). Если минимальная из рассчитанных оценок ta>tp, то модель оставляют в полученном виде. Если же tap, то фактор а1 исключается из модели как незначимый. Затем с оставшимися факторами строят новую модель, определяют новое значение оценок Стьюдента, находят минимальную из них и т.д. до тех пор, пока в модели останутся все значимые факторы.
Тесноту связей между функцией и факторами-аргументами можно установить с помощью квадрата коэффициента множественной корреляции:
![]() (2.27)
(2.27)
где ![]()
Квадрат коэффициента множественной корреляции показывает, какая часть общего рассеяния зависимой переменной может быть объяснена функцией вида (2.25) или вида (2.26).
Статистическая надежность многофакторной регрессионной модели (или коэффициента детерминации) устанавливается с помощью критерия Фишера:
![]() (2.28)
(2.28)
где n – число данных;
m – число факторов-аргументов в модели;
R2 – квадрат коэффициента множественной корреляции.
Если расчетное значение критерия Фишера превышает табличное при (n-m) и (m-1) степенях свободы и принятом р – уровне значимости то модель признается статистически надежной и значимой. Многофакторная регрессионная модель может быть использована для прогнозирования не более трехлетнего периода упреждения. Ошибки прогноза определяются по формулам (2.23-2.24).
Метод экспоненциального сглаживания
Сущность этого метода заключается в том, что прогноз ожидаемых величин (объемов, продаж и т.д.) определяется путем взвешенных средних величин текущего периода и сглаженных значений, сделанных в предшествующий. Такой процесс продолжается назад к началу временного ряда и представляет собой простую экспоненциальную модель для временных рядов с устойчивым трендом и малыми (независимыми) периодическими колебаниями.
Для многих временных рядов (показателей) наблюдается очевидная картина периодичности и случайности. Поэтому простая экспоненциальная модель расширяется с включением в нее двух последних компонент.
а) С устойчивым трендом
Пусть глаженное значение в момент времени t определяется по рекуррентной формуле:
![]() (2.29)
(2.29)
где уt – фактическое значение в момент времени t; ![]() ;
;
а – параметр сглаживания, определяется по формуле (2.11)
Тогда сглаженное значение в момент времени (t-1) равно:
![]() (2.30)
(2.30)
Подставив в выражение (2.29), получим:
![]() (2.31)
(2.31)
Продолжая этот процесс, прогноз может быть выражен в величинах прошлых значений временного ряда, т.е.:
![]() , (2.32)
, (2.32)
где L – период предсказания, но не более трех-пяти лет.
При t=1,2,…, n сглаженные значения в момент времени t определяются по формуле (2.29). Для этого же периода времени определяется среднее квадратическое отклонение (см. формулу 2.9) и коэффициент вариации (см. формулу 2.12), чтобы оценить точность выбранного параметра сглаживания. При t=1
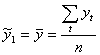 .
.
В случае если коэффициент вариации превышает 10%, то необходимо изменить интервал сглаживания, а следовательно, и параметр сглаживания .
При ![]() ,…, n прогнозы в момент времени t определяются по формуле (2.32) для оценки точности предсказания по среднему квадратическому отклонению и коэффициенту вариации.
,…, n прогнозы в момент времени t определяются по формуле (2.32) для оценки точности предсказания по среднему квадратическому отклонению и коэффициенту вариации.
При t=n+1, n+2, … определяются соответственно прогнозы данного показателя, в предположении, что текущее значение в момент времени t=n+1 совпадает с прогнозным в момент времени t=n.
б) С периодической компонентой
Пусть ![]() — сглаженное значение в момент времени t с учетом периодической компоненты. Периодичность совпадает с периодом предсказания. На практике обычно рассматриваются годовые или месячные изменения. Тогда оценка сглаженного значения запишется так:
— сглаженное значение в момент времени t с учетом периодической компоненты. Периодичность совпадает с периодом предсказания. На практике обычно рассматриваются годовые или месячные изменения. Тогда оценка сглаженного значения запишется так:
![]() (2.33)
(2.33)
![]() .
.
где ft—T – оценка периодической компоненты в предшествующем периоде; Т – длина периода.
В момент времени t периодическая компонента определяется по формуле:
![]() (2.34)
(2.34)
![]() .
.
Весовые параметры α и β подбираются либо с учетом текущих значений ![]() , либо с учетом прошлых значений
, либо с учетом прошлых значений ![]() . Оптимальные их значения устанавливаются по минимуму среднего квадратического отклонения.
. Оптимальные их значения устанавливаются по минимуму среднего квадратического отклонения.
Прогноз ожидаемых значений для оценки выбранных параметров α и β может быть определен мультипликативным образом по формуле:
![]() (2.35)
(2.35)
где![]() .
.
При t=n+1, n+2,…, N определяются собственно прогнозы по формуле:
![]() (2.36)
(2.36)
где ![]() — прогноз сглаженного значения определяемый по формуле (2.32).
— прогноз сглаженного значения определяемый по формуле (2.32).
в) С периодической и случайной компонентами
Пусть оценка сглаженного значения с учетом периодической и случайной компоненты имеет вид:
![]() (2.37)
(2.37)
где εt-1 – оценка случайной компоненты в момент времени (t-1), текущее значение εt определяется по формуле:
![]() (2.38)
(2.38)
где γ – параметр сглаживания для случайной компоненты, ![]() .
.
Прогноз ожидаемых значений для оценки выбранных параметров α, β и γ может быть получен по формуле:
![]() (2.39)
(2.39)
где Т – период предсказания, Т=1, 2, …, 5;
![]() ,…, n.
,…, n.
При t=n+1, n+2, …, N определяются собственно прогнозы по формуле:
![]() (2.40)
(2.40)
где — прогноз сглаженного значения, определяется по формуле (2.32).
Метод авторегрессионного преобразования
Сущность его заключается в построении модели по отклонениям значений временного ряда от выравненных по тренду значений. Пусть эти отклонения представляют собой случайные колебания временного ряда в каждый момент времени t:
![]() (2.41)
(2.41)
Тогда для случайной величины εt можно построить модель авторегрессии, т.е. регрессионную модель линейного вида для остатков значений временного ряда. Эти случайные переменные распределены со средним значением 0 и конечным рассеиванием (дисперсией) и подчиняются закону стохастического линейного разностного уровня 1-го порядка с постоянными коэффициентами (процесс Маркова), то есть:
![]() (2.42)
(2.42)
где εt-1 – временной ряд случайной компоненты, сдвинутый на один шаг, t=1, 2, …, n.
По формулам вида (2.14) определим b0 и b1, получим:
![]() ;
;
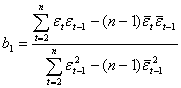 (2.43)
(2.43)
где![]() и
и ![]() — соответственно средние значения по данному временному ряду и сдвинутому на один шаг.
— соответственно средние значения по данному временному ряду и сдвинутому на один шаг.
Прогнозируемые значения случайной компоненты определяются по формуле:
![]() (2.44)
(2.44)
где L=1, 2, …
При L=1 , ![]() при L=2, 3, … справедлива формула (2.44).
при L=2, 3, … справедлива формула (2.44).
Определяем коэффициент автокорреляции r2 по формуле парного коэффициента корреляции (см. формулу 2.18). Тогда коэффициент автокорреляции для авторегрессионной модели 1-го порядка равен:
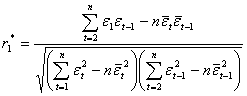 (2.45)
(2.45)
Затем строим авторегрессионную модель 2-го порядка:
![]() (2.46)
(2.46)
где εt-2 – временный ряд случайной компоненты, сдвинутой на два шага, при t=1, 2, …, n.
Коэффициенты b0, b1, b2 находятся с помощью метода наименьших квадратов из системы нормальных уравнений.
Находим:
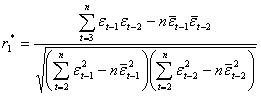 (2.47)
(2.47)
Если ![]() , то случайная компонента следует закону линейного разностного уравнения 1-го порядка (2.42), а прогнозы определяются по формуле (2.44). Если же
, то случайная компонента следует закону линейного разностного уравнения 1-го порядка (2.42), а прогнозы определяются по формуле (2.44). Если же ![]() , то строится линейное разностное уравнение 3-го порядка рассчитывается
, то строится линейное разностное уравнение 3-го порядка рассчитывается ![]() и т.д. Эти расчеты продолжаются до тех пор, пока
и т.д. Эти расчеты продолжаются до тех пор, пока ![]() , при τ=1,2,…, n/2. Выбирается авторегрессионная модель (τ-1) порядка. Оценка точности и надежности авторегрессионной модели определяется по среднему квадратическому отклонению (см. формулу 2.9) и коэффициенту вариации (см. формулу 2.12).
, при τ=1,2,…, n/2. Выбирается авторегрессионная модель (τ-1) порядка. Оценка точности и надежности авторегрессионной модели определяется по среднему квадратическому отклонению (см. формулу 2.9) и коэффициенту вариации (см. формулу 2.12).
Экстраполяцияпредставляет
метод прогнозирования, заключающийся
в изучении сложившихся в прошлом и
настоящем устойчивых тенденций развития
процессов и явлений и переносе их на
будущее. Метод экстраполяции применим,
если используются следующиедопущения:
а) период времени, для которого построена
функция, должен быть достаточным для
выявлении тенденции развития; б)
анализируемый процесс является устойчиво
динамическим и обладает инерционностью,
т.е. для значительных изменений
характеристик процесса требуется время;
в) не ожидается сильных внешних воздействий
на изучаемый процесс, которые могут
серьезно повлиять на тенденцию развития.
Прогнозирование с помощью метода
экстраполяции – один из простейших
методов статистического прогнозирования.
Его использование оправдано при
недостаточном знании о природе изучаемого
явления или отсутствии данных, необходимых
для применения более совершенных методов
прогнозирования.
Различают а) простую экстраполяцию,
которая предполагает, что все действовавшие
в прошлом и настоящем тенденции сохранятся
в полном объеме, так как все действовавшие
факторы останутся неизменными; б)прогнозную экстраполяцию, которая
базируется на предположении об изменении
факторов, определяющих динамику
изучаемого процесса или явления.
Основу экстраполяции составляет изучение
динамических рядов, представляющих
собой упорядоченные во времени наборы
измерений тех или иных показателей
исследуемого объекта. В основе
динамического анализа лежит понятие
траектории, которая описывает состояние
изучаемого процесса как функцию от
времени:Q=Q(t),t![]() [0,T],
[0,T],
[0,T] – отрезок времени.
При этом время может учитываться как
по интервалам, так и непрерывно. В первом
случае функция называется динамическим
рядом.
Использование экстраполяции имеет в
своей основе предположение о том, что
рассматриваемый процесс представляет
собой сочетание двух составляющих:
регулярной составляющей (Хt)
и случайной переменной (![]() ).
).
Временной ряд может условно представлен
в виде:Yt=Xt+
![]() t.
t.
Регулярная составляющаяназывается
трендом, тенденцией и характеризует
существующую динамику развития процесса
в целом.Случайная составляющаяотражает случайные колебания (шумы
процесса).
Показателями развития процессаявляются абсолютный прирост, темп роста,
темп прироста. Показатели изменения
динамического ряда могут вычисляться
на постоянной и переменой базе. Для
обобщающей оценки скорости и интенсивности
изменения динамического ряда используются
различные средние характеристики, среди
которых являются средний темп роста и
средний темп прироста. Средний темп
роста рассчитывают как среднее
геометрическое и как среднее параболическое.Среднее геометрическоерассчитывается
из последовательных цепных темпов
роста:![]() ;среднее параболическоеориентировано
;среднее параболическоеориентировано
на сумму динамического ряда и определяется
из уравнения:
Задача ППЭсостоит в определении
вида экстраполирующих функций Хtи
![]() tна основе исходных эмпирических данных
tна основе исходных эмпирических данных
и параметров выбранной функции.
Методика построениятрендовых
моделей представляет сочетание
качественного экономического анализа
и формальных математико-статистических
методов и включает несколько этапов:
1)Выбор класса функции тренда.Существует более 40 временных функций,
отличающихся своими свойствами. Надо
выбрать ту, которая отражает главные
особенности динамики исследуемого
показателя, прежде всего тип развития.
Можно выделить 4 типа экономического
роста: постоянный, увеличивающийся,
уменьшающийся и рост с качественными
изменениями характеристик на протяжении
рассматриваемого периода. 2)Оценка
параметров функции. Он проводится
методами регрессионного анализа. 3)Расчет значений формальных критериев
аппроксимации. Для характеристики
близости тренда к аппроксимируемому
динамическому ряду применяют несколько
формальных критериев: сумма квадратов
отклонений значений тренда от фактических
значений, значение коэффициента
детерминации и т.д. 4)Анализ остаточной
компоненты динамического ряда.5)Выбор функции тренда. Результатом
предшествующих этапов является построение
нескольких функций тренда для одного
показателя. Выбор лучшей осуществляется
путем сопоставления значений, возможностей
экономической интерпретации и
использования в прогнозировании.
МЕТОД ЛИНЕЙНОЙ экстраполяции.
Сущность метода заключается в том,
что прогнозные величины определяются
на основе среднего прироста (снижения)
исследуемого показателя за определенный
период времени.
Пример. Предположим, у нас имеются
данные об объеме ВНП страны за ряд лет:
Таблица — Объем
ВНП страны
|
Год |
Объем ВНП |
Прирост ВНП |
|
1995 |
16,0 |
— |
|
1996 |
21,8 |
5,8 |
|
1997 |
27,0 |
5,2 |
|
1998 |
32,0 |
5,0 |
|
1999 |
36,8 |
4,8 |
Рассчитаем средний темп прироста за
четыре года: (5,8 + 5,2 + 5,0 + 4,8)/4 = 5,2
Определив средний темп прироста,
рассчитаем прогнозное значение ВНП
страны на 2000 год: Y2000=Y1999+![]() Y= 36,8 + 5,2 = 42,0
Y= 36,8 + 5,2 = 42,0
В тех случаях, когда показатели базисного
и конечного прогнозного периода известны
и следует определить годовые промежуточные
показатели, используют метод линейной
интерполяции, рассчитывая средний
прирост за данный период времени:
Пример:Y2000=
205,Y2005 = 240.
![]() Y= (240 — 205)/5 = 7.
Y= (240 — 205)/5 = 7.
Y2002 =Y2000+ 2*![]() Y= 205 + 2*7 = 219.
Y= 205 + 2*7 = 219.
МЕТОД ПРОСТОЙ СРЕДНЕЙ. Применяется в
тех случаях, когда в уравнении линейной
зависимости Y=a+bx, коэффициентb= 0. При таком условии график будет
представлен прямой параллельной
горизонтальной оси графика, а прогноз
будет состоять в расчете простой средней
из всех имеющихся данных:Y=![]() Y/N.
Y/N.
Расчеты простой средней часто связывают
с сезонными колебаниями, происходящими
внутри общего тренда.
Пример.Имеются данные об объеме
ВНП за ряд лет по кварталам:
|
Год |
1 квартал |
2 квартал |
3 квартал |
В целом за |
|
|
1995 |
190 |
370 |
300 |
220 |
1080 |
|
1996 |
280 |
420 |
310 |
180 |
1190 |
|
1997 |
270 |
360 |
280 |
190 |
1100 |
|
1998 |
300 |
430 |
290 |
200 |
1220 |
|
1999 |
320 |
440 |
320 |
220 |
1300 |
|
Итого |
1360 |
2020 |
1500 |
1010 |
5890 |
|
Средний |
272 |
404 |
300 |
203 |
294,5 |
Рассчитываем квартальный индекс: 1
квартал = 272:294,5 = 0,92; 2 квартал = 404:294,5 =
1,37;
3 квартал
= 300:294,5 = 1,02; 4 квартал = 203:294,5 = 0,69.
Для того, чтобы составить прогноз
объема ВНП по кварталам на 2000 год,надо прогнозное значение ВНП за данный
год разделить на 4(количество кварталов)
и умножить на соответствующий квартальный
индекс. Предположим, что в 2000 году ВНП
будет равен 1450. Тогда в 1 квартале будет
произведено: (1450:4)*0,92= 333,5; 2 квартал =
(1450:4)*1,37 = 496,625 и т.д.
МЕТОД наименьших
квадратов. Позволяет подогнать
функцию под некоторый набор численных
значений и построить график функции по
некоторой совокупности точек. Выбор
этой функции считается наилучшим, если
стандартное отклонение определяемое
формулой:
E=
![]() (dt–d’t)2
(dt–d’t)2
![]() minоказывается сведено
minоказывается сведено
к минимальному значению.
dt–
фактические данные,
d`t
– данные рассчитанной функции.
Как правило, используется линейная
функция Y
= a + bx.
Задача состоит в том, чтобы определить
значения а и b, где
а – значение Yв базисном периоде,
b– угол наклона прямой.
Чтобы определить значения aиbиспользуется система
уравнений:
![]() Y=Na+b
Y=Na+b![]()
![]() Y=ax+bx2, гдеN- число периодов
Y=ax+bx2, гдеN- число периодов
х – номер
периода.
Пример. Имеются данные об
объеме ВНП.
|
Год |
Y(ВНП) |
x |
x2 |
xY |
Yсглаженный |
|
1995 |
108 |
0 |
0 |
0 |
108,4 |
|
1996 |
119 |
1 |
1 |
119 |
108,4 + 4,7 = |
|
1997 |
110 |
2 |
4 |
220 |
108,4 + 2* 4,7 = |
|
1998 |
122 |
3 |
9 |
366 |
108,4 + 3* 4,7 = |
|
1999 |
130 |
4 |
16 |
520 |
108,4 + 4* 4,7 = |
|
|
589 |
10 |
30 |
1225 |
Система уравнений выглядит следующим
образом: 589 = 5а + 10b
1225 = 10ф + 30b.
Решая их, находим а = 108,4, b= 4,7.
Можно рассчитать ВНП 2000 года : Y2000=Y1995+ 5b= 108,4 + 5*4,7 = 131,9.
В отдельных случаях лучшего соответствия
теоретических данных эмпирическим
можно достигнуть вычерчивая по точкам
кривой сглаживания вида Y=abx,
т.е. используяпоказательную функцию.
Если показательное уравнение
логарифмировать, то значения коэффициентов
а и можно определить методом наименьших
квадратов:
![]() log Y = log a + x* log b.
log Y = log a + x* log b.
logaиlogbнаходят, решая нормальные
уравнения:
![]() logY=Nloga+
logY=Nloga+
![]() xlogb.
xlogb.
![]() x log Y =
x log Y =
![]() x log a +
x log a +![]() x2
x2
log b.
Если определить х таким образом, что
![]() x= 0, то
x= 0, то
log a =
![]() log Y/ N, log b =
log Y/ N, log b =![]() x log Y/
x log Y/![]() x2.
x2.
МЕТОД СКОЛЬЗЯЩЕЙ СРЕДНЕЙ. При подготовке
прогноза методом скользящей привязки
число периодов, по которым производится
суммирование фактических данных,
несколько больше того числа, которое
было установлено и которое желательно
иметь для проведения необходимых
расчетов. Необходимость выравнивания
сезонных колебаний требует, чтобы
суммарная продолжительность всех
периодов была равна 1 году. Выравнивание
сезонных колебаний происходит в силу
того, что крайние значения тренда имеют
тенденцию к взаимному погашению.
Вовлечение в расчет скользящей средней
большего числа временных периодов
увеличивает эффект сглаживания и
одновременно уменьшает чувствительность
прогноза к данным последних периодов.
Движение скользящей средней во времени
дает возможность учесть самую последнюю
информацию и отказаться от использования
более старых данных. Использование
скользящей средней позволит подготовить
качественный прогноз только тогда,
когда данные будут относительно
стабильны.
Индекс сезонных колебаний, вычисленный
на основе скользящей средней, дает
возможность улучшить качество прогноза.
Индекс получают путем деления объема
фактического производства в соответствующем
периоде на величину центрированной
скользящей средней за тот же период.
Повысить надежность можно за счет
усреднения значения нескольких индексов
общих временных периодов.
Пример. Для разработки прогноза на
2000 год используем данные о квартальных
объемах производства. Скользящие средние
определяются исходя из разбивки года
на кварталы. Можно рассчитать скользящую
среднюю только за 2 квартал 1995 года путем
деления суммы данных за четыре квартала
данного года на 4: (190+370+300+220)/4= 270.
Для расчета следующей скользящей средней
берут данные за 2-4 кварталы 1995 года и 1
квартал 1996 года. Аналогично поступают
в дальнейшем.
Центрированная скользящая средняя
находится только для третьего квартала
путем деления суммы данных скользящей
средней за 2 и 3 кварталы 1995 года:
(270+292)/2 = 281.
Дальнейшие расчеты делаются аналогично,
заменяя одно значение другим.
Индекс сезонных колебаний получают
путем деления фактического объема
производства на величину центрированной
скользящей средней за тот же период.
Для 3 квартала 1995 года: 300:281 = 1,07.
Таблица. Расчет значений скользящей
средней и индексов сезонных колебаний
|
Год |
Квартал |
Объем |
Скользящая |
Центрированная |
Индекс |
|
1995 |
1 |
190 |
|||
|
2 |
370 |
(190+370+300+220):4=270 |
|||
|
3 |
300 |
(370+300+220+280):4=292 |
(270+292):2 = 281 |
1.07 |
|
|
4 |
220 |
(300+220+280+420):4=305 |
(292+305):2= |
0,74 |
|
|
1996 |
1 |
280 |
(220+280+420+310):4=307 |
(305+307):2= 306 |
0,91 |
|
2 |
420 |
(280+420+310+180):4=297 |
(307+297):2= 302 |
1,39 |
|
|
3 |
310 |
295 |
296 |
1,04 |
|
|
4 |
180 |
280 |
287,5 |
0,63 |
|
|
1997 |
1 |
270 |
273 |
276,5 |
0,98 |
|
2 |
360 |
275 |
274 |
1,32 |
|
|
3 |
280 |
283 |
279 |
1,00 |
|
|
4 |
190 |
300 |
286,5 |
0,66 |
|
|
1998 |
1 |
300 |
303 |
301,5 |
1,00 |
|
2 |
430 |
305 |
304 |
1,42 |
|
|
3 |
290 |
310 |
307,5 |
0,94 |
|
|
4 |
200 |
312 |
311 |
0,64 |
|
|
1999 |
1 |
320 |
320 |
316 |
1,01 |
|
2 |
440 |
325 |
322,5 |
1,37 |
|
|
3 |
320 |
||||
|
4 |
220 |
На основе рассчитанных данных индекса
сезонных колебаний заполняем таблицу
2 и делаем расчет скорректированного
индекса.
Таблица 2 Расчет скорректированного
индекса сезонных колебаний
|
Год |
1 квартал |
2 квартал |
3 квартал |
4 квартал |
|
1995 |
1.07 |
0,74 |
||
|
1996 |
0,91 |
1,39 |
1,04 |
0,63 |
|
1997 |
0,98 |
1,32 |
1,00 |
0,66 |
|
1998 |
1,00 |
1,42 |
0,94 |
0,64 |
|
1999 |
1,01 |
1,37 |
||
|
Итого |
3,90 |
5,50 |
4,05 |
2,67 |
|
Средний |
0.975 |
1,375 |
1,0125 |
0,6675 |
|
Скорректированный |
0,97 |
1,37 |
1,00 |
0,66 |
Средний индекс сезонных колебаний
рассчитываем путем деления суммы
индексов за данный квартал на количество
данных: для 1 квартала: 3,90:4 = 0,975 и т.д.
Полученные средние индексы сезонных
колебаний проверяют на точность расчета.
Среднее значение всех квартальных
индексов не должна превышать 1. В нашем
случае:
(0.975 + 1,375 + 1,0125 + 0,6675): 4 = 1,0075
Так как индекс больше 1, его следует
скорректировать, уменьшив на 0.0075.
Завершающая стадия – составление
прогноза. Для этого берут центрированную
скользящую среднюю за определенный
период и умножают на скорректированный
индекс сезонных колебаний. Для 2000 года
мы должны взять центрированную скользящую
среднюю за 1 квартал 1999 года (316) и умножить
на скорректированный индекс сезонных
колебаний за 1 квартал (0,97):
1 квартал 2000 года = 316*0,97 = 307.
И т.д.
ЭКСПОНЕНЦИАЛЬНОЕ СГЛАЖИВАНИЕ. При
экспоненциальном сглаживании в равенство
вводится постоянный коэффициент
сглаживания
![]() ,
,
придающий больший вес последним данным.
Уравнение прогноза, учитывающее
экспоненциальное сглаживание, записывается
в виде:
Fn=![]() Yn-1+ (1 —
Yn-1+ (1 —![]() )Fn-1,
)Fn-1,
где Fn
– прогноз предстоящего периода
Fn-1—
прогноз на текущий год
![]() — коэффициент сглаживания
— коэффициент сглаживания
Yn-1—
фактический объем прогнозируемого
показателя в текущем году.
Коэффициент
![]() находится в интервале от 0 до
находится в интервале от 0 до
1.Чувствительность к происходящим
изменениям повышается с увеличением
коэффициента сглаживания и уменьшением
числа рассматриваемых периодов (N).
Связь между![]() иNописывается отношением
иNописывается отношением![]() =
=![]() .
.
Поэтому, если нас не устраивает найденное
количество периодов N, то
мы легко можем найти значение![]() ,
,
которое нас устроит.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Добавлено в закладки: 0
Что такое метод экстраполяции? Описание и определение понятия.
Метод экстраполяции – это один из главных способов прогноза, который основывается на прогнозировании событий, учитывая анализ показателей, которые имели место в прошлые годы (при этом, не меньше чем за 5 – 8 лет). В данный момент есть приблизительно триста уравнений, которые дают возможность определить тенденции процессов и позволяют оценить линейную простую зависимость явления и квадратичную зависимость.
Экстраполи́рование, экстраполя́ция, (от лат. extrā — снаружи, вне, кроме, за и лат. polire — выправляю, приглаживаю, меняю, изменяю) — это особенный вид аппроксимации, при котором функция аппроксимируется вне заданного интервала, а не меж фиксированными значениями.
Другими словами, экстраполяция — это приближённое определение значений функции в точках, которые лежат вне отрезка, по её значениям в точках.
Методы
 Во многих случаях методы экстраполяции похожи с методами интерполяции.
Во многих случаях методы экстраполяции похожи с методами интерполяции.
Самый распространённый способ экстраполяции — это параболическая экстраполяция, при которой в точке берётся значение многочлена степени, которая принимает в точке заданные значения. Для параболической экстраполяции применяют интерполяционные формулы.
Применение
Общее значение — это распространение выводов, которые получены из наблюдения над одной частью явления, на его другую часть.
В маркетинге — это распространение выявленных закономерностей развития изучаемого предмета на будущее.
В статистике — это распространение тенденций, установленных в прошлом, на будущий период (экстраполяция во времени используется для перспективных расчетов населения); распространение выборочных данных на прочую часть совокупности, которая не подвергнута наблюдению (экстраполяция в пространстве).
Одним из более распространенных способов краткосрочного прогнозирования экономических явлений — это экстраполяция
Термин “экстраполяция” имеет немного толкований в широком смысле экстраполяция – это способ научного исследования, который заключается в распространении выводов, которые получены из наблюдений за одной частью явления, на а другую его часть В узком смысле – это определение по нескольким данным функции прочих ее значений вне данного ряда за этим рядом.
Прогноз экстраполяции
Экстраполяция заключена в изучении сложившихся в настоящем и прошлом устойчивых тенденций экономического развития и их перенос на будущее
Цель данного прогноза — это показать, к каким итогам можно сделать в будущем, когда передвигаться к нему с аналогичной ускорением или скоростью, что и в прошлом
 Прогноз определяет ожидаемые варианты данного экономического развития исходя из гипотезы, что главные факторы и тенденции прошлого периода сберегается на период прогноза или что возможно обосновать и учесть направление их изменений в рассматриваемой перспективе. Такую гипотезу выдвигают, учитывая инертность экономических процессов и явлений.
Прогноз определяет ожидаемые варианты данного экономического развития исходя из гипотезы, что главные факторы и тенденции прошлого периода сберегается на период прогноза или что возможно обосновать и учесть направление их изменений в рассматриваемой перспективе. Такую гипотезу выдвигают, учитывая инертность экономических процессов и явлений.
В прогнозировании экстраполяция используется при изучении временных рядов экстраполяции в общем типе можно представить, как определенное значение функции зависимо от особенностей изменения уровней в рядах динамики способы экстраполяции могут быть сложными и простыми.
Простые способы экстраполяции базируются на предположении относительной устойчивости в будущем абсолютных значений уровней, среднего абсолютного прироста, среднего уровня ряда, среднего темпа роста.
Различные способы экстраполяции
Рассмотрим дет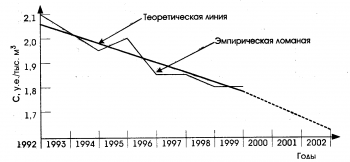 альнее названные способы экстраполяции.
альнее названные способы экстраполяции.
При экстраполяции на основании среднего уровня ряда применяется принцип, при котором прогнозируемый уровень равняется среднему значению в прошлом уровней ряда.
В данной ситуации экстраполяция дает точечную прогностическую оценку. Точное совпадение данных оценок с фактическими данными — маловероятное явление. Таким образом, прогноз обязан быть в виде интервала значений.
Полученный доверительный интервал учитывает неопределенность, которая связана с оценкой средней величины, и его использование для прогнозирования увеличивает степень надежности прогноза. Однако недостаток рассматриваемого подходов периода — это то, что доверительный интервал не связывается с периодом предупреждения.
Экстраполяцию по среднему абсолютному приросту можно провести тогда, когда линейной считать общую тенденцию развития явления.
Чтобы рассчитать прогнозное значение, уровень необходимо определить абсолютный средний прирост. Затем, зная уровень ряда динамики, который принимают за основу экстраполяции.
 Экстраполяцию по среднему темпу роста можно осуществить, когда есть основания полагать, что суммарная тенденция ряда динамики характеризуется показательной кривой.
Экстраполяцию по среднему темпу роста можно осуществить, когда есть основания полагать, что суммарная тенденция ряда динамики характеризуется показательной кривой.
Доверительный интервал прогноза по средним темпом роста можно определить лишь в том случае, когда средний темп роста рассчитывают при помощи статистического оценивания параметров экспоненциальной кривой.
Все три рассмотренные способа экстраполяции тренда простейшие, но вместе и самые приближенные.
Сложные способы экстраполяции предусматривают выявление главной тенденции, то есть использование статистических формул, которые описывают тренд.
Способы данной группы возможно разделить на два главных вида: адаптивные и аналитические (кривые роста).
Аналитические способы прогнозирования
В основание аналитических способов прогнозирования (кривых роста) лежит принцип получения при помощи метода самых малых квадратов оценки детерминированной компоненты, которая характеризует главную тенденцию
Адаптивные способы прогнозирования основываются на том, что процесс реализации их заключен в вычислении последовательных во времени значений прогнозируемого показателя, учитывая степень влияния прошлых уровней. К ним относят способы экспоненциальной и текучей средних, способ гармонических весов, способ авторегрессииї.
Способ аналитического выравнивания тренда (способ наименьших квадратов) может быть использован лишь тогда, когда развитие явления довольно хорошо описывают построенную модель и условия, которые определяют тенденцию развития в прошлом, не изменятся существенно в будущем. При выполнении данных требований прогнозирование производится при помощи подстановки в уравнение тренда значений независимой переменной знает величине периода предупреждения.
Процедура создания прогноза по применению аналитического выравнивания тренда включает в себя такие этапы:
1) выбор формы кривой, которая отображает тенденцию;
2) определение показателей, характеризующие количественно тенденции изменений;
3) оценка вероятности прогнозных расчетов
Подбор формы кривой возможно осуществлять на основании построения графика, суммарный тип которого обычно дает возможность установить:
а) имеет динамический ряд показателя выраженную четко тенденцию;
б) если так, то данная тенденция плавная;
в) каков характер тенденции
Отвечая на данные вопросы, нужно помнить, что наружная простота графика ложная. Каждая динамическая задача намного сложнее от статического и каждая точка кривой — это результат изменения явления во времени и пространстве.
Ввиду этого для увеличения достоверности и обоснованности выравнивания для более точного выявления тенденции, которая есть, нужно провести вариантный расчет по некоторым аналитическими функциями и на основании статистических и экспертных оценок определить лучшую форму связей.
На втором этапе нужно определить параметры уравнения связи. Для того, чтобы их найти, применяют способ малых квадратов. В данной ситуации выравнивающая функция будет занимать данное положение среди факт политических значений показателей, при котором общее отклонение точек от функции будет наименьшим.
Обоснованную и достоверную оценку имеющимся результатам можно дать, применяя статистические показатели: средний коэффициент увеличения, коэффициент корреляции, остаточная и общая дисперсия, другой индекс корреляции, коэффициент корреляции ряда отклонений и исходного ряда, определенного по разнице выровненных и фактических по любой аналитической функции.
Для того, чтобы проверить гипотезу об отсутствии или наличии автокорреляции применяют таблицы с критическими значениями коэффициента автокорреляции при разных уровнях значимости. Когда табличное значение коефициэнта автокорреляции больше фактического, то возможно утверждать, что автокорреляция устраняется или отсутствует, а означает, возможно применять формулы для возиожностной оценки значений, которые прогнозируются по этому и точками.
Для прогноза были выбраны такие функции, как логарифмическая, линейная, ступенчатая, полиномиальная и экспоненциальная.
Не все выбранные аналитические функции выравнивают хорошо динамический выходной ряд. Об этом говорит значение индекса (коэффициента) корреляции Для того, чтобы прогнозировать, то есть продолжать сформированные тенденции на ближайшую перспективу, можно использовать лишь те функции, для которых индекс (коэффициент) корреляции больше 0,7 К таковым относят линейную, экспоненциальную и полиномиальную функцию. Последняя имеет самый большой коэффициент корреляции, равен 0,847, и самую малую величину остаточной дисперсией.
Порой, само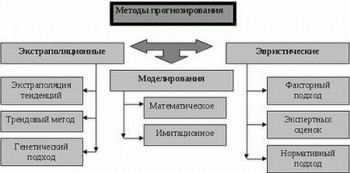 й приемлемой формой аналитической функции для прогнозирования является полиномиальная функция, которая представлена уравнением:
й приемлемой формой аналитической функции для прогнозирования является полиномиальная функция, которая представлена уравнением:
Подставив в полученное уравнение значения периодов предубеждения, определяем прогнозное значение объема товарооборота на такие три месяца: у25 = 654,83; у = 655,93; у ”- 657,07 тыс грн 26 27
Возможность того, что экономический прогнозируемый показатель в заданный момент времени будет равняться значению, которое отвечает точечной прогноза, почти равняться нулю. Потому к точечному прогнозу границы вероятного изменения прогнозируемого значения показателя.
Заметим, что в полученных при прогнозировании оценок доверительных интервалов необходимо отнестись с осторожностью Это связывается со спецификой динамических рядов Их специфичность заключена в том, что увеличение количества наблюдений в статической совокупности дает возможность получить точные характеристики данной совокупности, в то время как аналогичное удлинение ряда динамики приводит не всегда к похожим результатам, особенно в тех ситуациях, когда ряды динамик применяются для прогнозирования. Данное обстоятельство связывается с тем, что информационная ценность уровней потеряется по мере их удаления от периода предубеждение, то есть означает уровни ряда динамики при прогнозировании неравноценно. Потому параметры уравнений аппроксимирующих кривых роста могут обладать погрешности и изменять собственные оценки при исключении части членов ряда или Анне добавил новых членов ряда динамики, что отображается на точности расчетных значений уровней ряда динамики. Помимо этого, параметры моделей тренда, которые получены способом самых малых квадратов, остаются неизменным и в течение рассматриваемого периода. На практике зачастую встречаются случаи, когда параметры моделей изменяются, а процедуры, которые сглаживают при помощи способа самых малых квадратов не могут определить такие изменения.
Поэтому наиболее эффективными являются адаптивные способы, в которых значимость уровней ряда динамики снижается по мере их удаления от прогнозируемого периода. К ним относят: способ текучих средних, способ экспоненциального сглаживания, способ гармонических весов и прочие, включаются в класс адаптивных способов.
Зачастую несколько динамики характеризуются резкими колебаниями показателей по годам. Данные ряды обычно, имеют слабую связь со временем и не проявляют четкой тенденции к изменению. В данной ситуации способы аналитического выравнивания малоэффективен, потому что возможность расчетов резко уменьшается. Доверительные границы прогноза порой оказываются шире, чем колебания показателя в некоторых динамиках.
При прогнозировании на основании временных рядов, которые весьма колеблются, можно применять способ текучих средних, при помощи которого возможно исключить случайные колебания временного ряда.
Интервал, величина которого все еще постоянная, постепенно помещается на одно наблюдение. Когда наблюдается определенная цикличность изменений показателей, интервал текучести равняется длительности циклу. В ситуации отсутствия цикличности в изменении показателей советуется исполнять различный расчет при параметре сглаживания. Лучший вариант определяется на основании дальнейшей оценки и выровненных рядов.
По данным выровненных значений ряда динамики производится подбор формы кривой, которая отражает тенденции развития явления. Полученное уравнение регрессии применяется для определения прогнозного значения исследуемого показатель.
На основании выровненных значений товарных запасов предприятия имеются такие значения коэффициента корреляции. Приведенные данные говорят, что наилучшие итоги должны по данным, которые выровнены на основании уровней исследуемого ряда динамики
Метод экспоненциального сглаживания
Экспоненциальное сглаживание – это выравнивание динамических рядов, весьма колеблются, цели стабильного прогнозирования По данному способу возможно дать обоснованные прогнозы на основе рядов динамики, имеют умеренный связь во времени, и обеспечить больше учета показателей, которые достигнуты за последние годы. Сущность метода оформляется в сглаживании временного ряда при помощи взвешенной текучей средней, в которые и веса подчиняются экспоненциальному закону.
Всякое сглажено значение рассчитано при помощи объединения прошлого текущего значения сглаженного значения и временного ряда. В данной ситуации текущие значения временного ряда разрешаются, учитывая константы, сглаживает.
Мы коротко рассмотрели метод экстраполяции: методы, применение. Оставляйте свои комментарии или дополнения к материалу.
- Авторы
- Файлы
- Литература
Кузьменкова А.В.
1
1 Российский экономический университет имени Г.В. Плеханова
1. Гусарова О.М. Методы и модели прогнозирования деятельности корпоративных систем // Теоретические и прикладные вопросы образования и науки. Тамбов: Юком, 2014. С. 42-43.
2. Орлова И.В. Опыт использования компьютерных технологий при преподавании математического моделирования //Успехи современного естествознания. 2014. № 12-4. С. 433-435.
3. Орлова И.В. Экономико-математическое моделирование: Практическое пособие по решению задач. 2-е изд., испр. и доп. М.: Вузовский учебник: ИНФРА-М, 2012. 140 с.
4. Орлова И.В., Махвытов М.А. Прогнозирование выдачи ипотечных кредитов с помощью модели Брауна//Современные наукоемкие технологии. 2014. № 7-3. С. 22-24.
5. Орлова И.В., Половников В.А. Экономико-математические методы и модели: компьютерное моделирование: учебное пособие для студентов высших учебных заведений, обучающихся по специальности «Статистика» и другим экономическим специальностям / Москва, 2011. Сер. Вузовский учебник (3-е издание, переработанное и дополненное)
6. Орлова И.В., Турундаевский В.Б. Некоторые особенности, возникающие при изучении нелинейной регрессии с использованием Еxcel и других программ // Экономика, статистика и информатика. Вестник УМО. 2014. № 1. С. 158-161.
7. Эконометрика Орлова И.В., Половников В.А., Филонова Е.С., Гусарова О.М., Малашенко В.М., Дайитбегов Д.М. Учебно-методическое пособие / Москва, 2010.
8. Эконометрика Орлова И.В., Филонова Е.С., Агеев А.В. Компьютерный практикум для студентов третьего курса, обучающихся по специальностям 080105.65 «Финансы и кредит», 080109.65 «Бухгалтерский учет, анализ и аудит» / Москва, 2011.
9. http://eclib.net/14/index.html
10. http://www.rae.ru/monographs/10-168
Полученные при анализе динамических рядов экономических показателей характеристики используются для получения статистических прогнозов, под которыми понимаются статистические оценки состояния явления в будущих периодах.
Статистическое прогнозирование основано на предположении, что закономерность развития, основная тенденция, действующая в прошлом (внутри ряда динамики), сохранится и в будущем. Такое предположение называется экстраполяцией [5]. Теоретической основой распространения тенденции на будущее является инерционность социально-экономических явлений.
Следует иметь в виду, что экстраполяция в рядах динамики носит приближенный характер. Точность прогноза зависит от сроков прогнозирования: чем они короче, тем надежнее результат экстраполяции, так как за короткий период времени не успевают значительно измениться условия развития явления и характер его динамики [1].
Прогнозирование позволяет рассмотреть возможные альтернативы разработки финансовой стратегии, обеспечивающей достижение предприятием стабильного положения на рынке и прочной финансовой устойчивости.
С помощью метода экстраполяции получают два вида прогноза: точечные и интервальные. Точечный прогноз представляет собой конкретное численное значение уровня в прогнозируемый период (момент) времени. Интервальный прогноз – диапазон численных значений, предположительно содержащий прогнозируемое значение уровня.
В зависимости от того, какие принципы и исходные данные положены в основу прогноза, выделяют следующие методы экстраполяции (прогнозирования):
– на основе среднего абсолютного прироста  ,
,
– на основе среднего коэффициента роста  ,
,
– на основе аналитического выравнивания ряда.
Метод прогнозирования на основе среднего абсолютного прироста t1 применяется в том случае, если уровни изменяются равномерно (линейно).
Прогнозируемое значение уровня определяется по формуле:
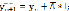
где 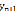 – экстраполируемый уровень; yn – конечный уровень ряда динамики; l – период упреждения прогноза (срок экстраполяции).
– экстраполируемый уровень; yn – конечный уровень ряда динамики; l – период упреждения прогноза (срок экстраполяции).
Прогнозирование по среднему коэффициенту роста  применяется, если общая тенденция характеризуется экспотенциальной кривой. В этом случае экстраполируемый уровень определяется по формуле:
применяется, если общая тенденция характеризуется экспотенциальной кривой. В этом случае экстраполируемый уровень определяется по формуле:
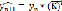
Прогнозирование на основе аналитического выравнивания является наиболее распространенным методом прогнозирования. Для получения прогноза используется аналитическое выражение тренда. Чтобы получить прогноз, достаточно в модели продолжить значение условного показателя времени от t1 до tn+1.
Интервальные прогнозы строятся на основе точечных прогнозов. Доверительным интервалом называется такой интервал, относительно которого можно с заранее выбранной вероятностью утверждать, что он содержит значение прогнозируемого показателя. Ширина интервала зависит от качества модели, т.е. степени ее близости к фактическим данным, числа наблюдений, горизонта прогнозирования и выбранного пользователем уровня вероятности и других факторов [5].
Интервальные прогнозы имеют значительные преимущества перед точечными – они учитывают вероятность свершения прогноза. Величина доверительного интервала определяется в общем виде так[5]:
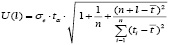 ,
,
где коэффициент tα является табличным значением t-статистики Стьюдента при заданном уровне значимости и числе наблюдений; σ – средняя квадратическая ошибка тренда, рассчитываемая по формуле:
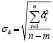 ,
,
где n – число уровней исходного ряда; m – число параметров трендового уравнения.
Для ряда динамики прогнозное значение Y принадлежит интервалу: 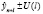 .
.
Если построенная модель адекватна, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадает в интервал, образованный верхней и нижней границей.
После получения прогнозных оценок необходимо убедиться в их разумности и непротиворечивости оценкам, полученным иным способом.
Применение метода экстраполяции для составления прогноза некоторых показателей компании ОАО «Ростелеком».
ОАО «Ростелеком» – одна из крупнейших в России и Европе телекоммуникационных компаний национального масштаба, присутствующая во всех сегментах рынка услуг связи и охватывающая более 34 млн домохозяйств в России.
Компания занимает лидирующее положение на российском рынке услуг широкополосного интернет-доступа (ШПД) и платного телевидения: количество абонентов услуг ШПД превышает 11,0 млн. а платного ТВ «Ростелекома» – более 7,8 млн пользователей, из которых свыше 2,5 миллиона смотрит уникальный федеральный продукт «Интерактивное ТВ».
Консолидированная выручка Группы компаний за 3 кв. 2014 г. составила 75,5 млрд. руб., чистая прибыль – 24,5 млрд. руб.
«Ростелеком» является безусловным лидером рынка телекоммуникационных услуг для российских органов государственной власти и корпоративных пользователей всех уровней.
Компания – признанный технологический лидер в инновационных решениях в области электронного правительства, облачных вычислений, здравоохранения, образования, безопасности, жилищно-коммунальных услуг.
В табл. 1 представлена динамика изменения ключевых показателей деятельности компании с 2008 по 2013 год.
Таблица 1
|
2008 |
2009 |
2010 |
2011 |
2012 |
2013 |
|
|
|
Выручка |
258 921 |
264 645 |
277 497 |
312 330 |
332 435 |
325 704 |
295 255 |
|
Чистая прибыль |
26 263 |
30 429 |
36 819 |
36 819 |
33 202 |
24 131 |
31 277 |
|
Активы |
414 603 |
403 180 |
449 229 |
513 381 |
567 190 |
560 972 |
484 759 |
|
Капитал и резервы |
198 133 |
217 411 |
221 498 |
231 198 |
238 832 |
199 756 |
217 805 |

Рис. 1
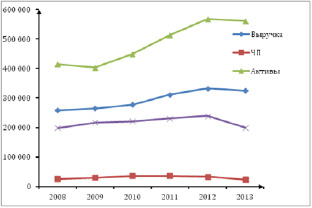
Построив тренды этих показателей (рис. 1), мы можем видеть, что в 2013 году все без исключения показатели, испытывавшие до этого рост, уменьшились.
Построим точечный прогноз на 1 год с помощью среднего абсолютного прироста  ,
,
1. Вычислим средний абсолютный прирост
|
|
|
|
Выручка |
13356,6 |
|
Чистая прибыль |
-426,4 |
|
Активы |
29273,8 |
|
Капитал и резервы |
324,6 |
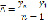
2. Вычислим прогнозные показатели по формуле  на 1год вперед
на 1год вперед
|
2008 |
2009 |
2010 |
2011 |
2012 |
2013 |
2014 |
|
|
Выручка |
258 921 |
264 645 |
277 497 |
312 330 |
332 435 |
325 704 |
339 061 |
|
ЧП |
26 263 |
30 429 |
36 819 |
36 819 |
33 202 |
24 131 |
23 776 |
|
Активы |
414 603 |
403180 |
449229 |
513 381 |
567 190 |
560 972 |
585 367 |
|
Капитал и резервы |
198 133 |
217 411 |
221 498 |
231 198 |
238 832 |
199 756 |
200 027 |
Теперь воспользуемся методами аналитического выравнивания ряда. В качестве инструмента будем использовать MS Excel [3], [6], [7], [8].
Построим модель регрессии Выручки (Y1)) от времени t (t =1, 2, …, 6). Рис. 2 и 3.
При прогнозировании целесообразно (по мере возможности) использование нескольких методов прогнозирования. Это повысит качество прогноза и позволит определить «подводные камни», которые могут быть не замечены при использовании только одного метода. Сравнивая полученные четыре модели, необходимо сделать выбор, учитывая не только количественные характеристики, но и содержательный смысл. Так, линейная модель является наилучшей с точки зрения адекватности и точности (значение критерия Дарбина-Уотсона, близкое к двум, свидетельствует об отсутствии автокорреляции остатков; средняя относительная ошибка аппроксимации меньше 3% свидетельствует о высокой точности модели). Однако прогноз по этой модели (рис. 1) не соответствует нашим представлениям о протекающем в данный момент времени процессе. Степенная модель и кубическая парабола больше отвечают нашим представлениям о будущем значении рассматриваемого показателя. Окончательный выбор модели всегда остаётся за специалистом, учитывающим не только числовые характеристики модели, но и влияние не учтённых в модели факторов, например, ожидаемый кризис экономики.
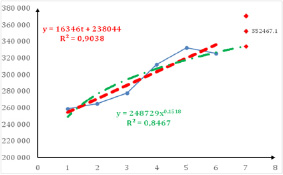
Рис. 2. Прогноз ВЫРУЧКИ по линейной и степенной моделям
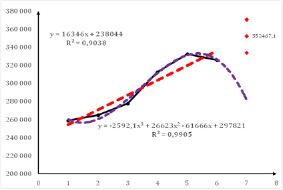
Рис. 3. Прогноз ВЫРУЧКИ по линейной модели (полином 1 степени) и по кубической параболе (полином 3 степени)
Библиографическая ссылка
Кузьменкова А.В. ПРИМЕНЕНИЕ МЕТОДА ЭКСТРАПОЛЯЦИИ ДЛЯ СОСТАВЛЕНИЯ ПРОГНОЗА КЛЮЧЕВЫХ ПОКАЗАТЕЛЕЙ ДЕЯТЕЛЬНОСТИ КОМПАНИИ ОАО «РОСТЕЛЕКОМ» // Международный студенческий научный вестник. – 2015. – № 4-2.
;
URL: https://eduherald.ru/ru/article/view?id=13524 (дата обращения: 28.05.2023).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)
Определение формулы экстраполяции
Формула экстраполяции — это формула, используемая для оценки значения зависимой переменной относительно независимой переменной, которая должна лежать в диапазоне за пределами данного набора данных. Например, точно известен расчет линейного исследования с использованием двух конечных точек (x1, y1) и (x2, y2) на линейном графике, когда значение экстраполируемой точки равно «x», формула, которую можно использовать представляется как y1+ [(x−x1) / (x2−x1)] *(у2-у1).
Оглавление
- Определение формулы экстраполяции
- Расчет линейной экстраполяции (шаг за шагом)
- Примеры
- Пример №1
- Пример #2
- Пример №3
- Актуальность и использование
- Рекомендуемые статьи
Y(x) = Y(1)+ (x-x(1)/x(2)-x(1)) * (Y(2) — Y(1))

Формулу линейной экстраполяции можно разделить на следующие шаги:
- Во-первых, необходимо проанализировать данные, чтобы определить, следуют ли данные за тенденцией и можно ли прогнозировать то же самое.
- Должно быть две переменные: одна должна быть зависимой переменной, а вторая должна быть независимой переменной.
- Числитель формулы начинается с предыдущего значения зависимой переменной. Затем нужно добавить долю независимой переменной при расчете среднего значения для интервалов классов.
- Наконец, умножьте значение, полученное на шаге 3, на разницу непосредственно заданных зависимых значений. Добавление шага 4 к значению зависимой переменной даст экстраполированное значение.
Примеры
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон формулы экстраполяции Excel здесь — Формула экстраполяции Шаблон Excel
Пример №1
Предположим, что значение некоторых переменных приведено ниже в виде (X, Y):
- (4, 5)
- (5, 6)
Основываясь на приведенной выше информации, вы должны найти значение Y(6), используя метод экстраполяции.
Решение
Используйте приведенные ниже данные для расчета.
- Х1: 4,00
- Y2: 6.00
- Y1: 5,00
- Х2: 5,00
Расчет Y(6) по формуле экстраполяции выглядит следующим образом:

Экстраполяция Y(x) = Y(1) + (x) – (x1) / (x2) – (x1) x {Y(2) – Y(1)}
Y(6) = 5 + 6 – 4 / 5 – 4 х (6 – 5)
Ответ будет —

- Y3 = 7
Следовательно, значение для Y, когда значение X равно 6, будет равно 7.
Пример #2
Г-н М и г-н Н являются учащимися 5-го стандарта, и в настоящее время они анализируют данные, предоставленные им их учителем математики. Учитель попросил их вычислить вес учеников, чей рост будет 5,90, и сообщил им, что приведенный ниже набор данных следует линейной экстраполяции.
ИксВысотаДМассаX15.00Y150X25.10Y252X35.20Y353X45.30Y455X55.40Y556X65.50Y657X75.60Y758X85.70Y859X95.80Y962
Предполагая, что эти данные следуют линейному ряду, вы должны рассчитать вес, который будет зависимой переменной Y в этом примере, когда независимая переменная x (рост) равна 5,90.
Решение
В этом примере нам теперь нужно узнать значение, или, другими словами, нам нужно спрогнозировать значение учащихся, чей рост равен 5,90, на основе тенденции, указанной в примере. Затем мы можем использовать приведенную ниже формулу экстраполяции в Excel для расчета веса, который является зависимой переменной для заданного роста и независимой переменной.
Расчет Y (5,90) выглядит следующим образом:

- Экстраполяция Y(5.90) = Y(8) + (x) – (x8) /(x9) – (x8) x [Y(9) – Y(8)]
- Y(5,90) = 59 + 5,90 – 5,70 / 5,80 – 5,70 х (62 – 59)
Ответ будет —

- = 65
Следовательно, значение Y, когда значение X равно 5,90, будет равно 65.
Пример №3
Г-н В. является исполнительным директором компании ABC. Он был обеспокоен продажами компании после тенденции к снижению. Поэтому он попросил свой исследовательский отдел произвести новый продукт, который будет соответствовать растущему спросу по мере увеличения производства. Через 2 года они разработали продукт, спрос на который рос.
Ниже приведены подробности за последние несколько месяцев:
Х (Производство)Произведено (единиц)Y (спрос)Спрос (единиц)X110.0Y120.00X220.00Y230.00X330.00Y340.00X440.00Y450.00X550.00Y560.00X660.00Y670.00X770.00Y780.00X880.00Y890.00X990.00Y9100.00
Они заметили, что, поскольку изначально это был новый и дешевый продукт, спрос на него будет линейным до определенного момента.
Следовательно, продвигаясь вперед, они сначала прогнозируют спрос, а затем сравнивают его с фактическим и производят соответственно, поскольку это потребовало от них огромных затрат.
Менеджер по маркетингу хочет знать, что будет требоваться, если они произведут 100 единиц. Основываясь на приведенной выше информации, вы должны рассчитать спрос в единицах, когда они производят 100 единиц.
Решение
Мы можем использовать приведенную ниже формулу для расчета потребности в единицах, которая является зависимой переменной для данных произведенных единиц, которая является независимой переменной.
Расчет Y(100) выглядит следующим образом:

- Экстраполяция Y(100) = Y(8) + (x) — (x8) / (x9) — (x8) x [ Y(9) – Y(8)]
- Y(100) = 90 + 100 – 80 / 90 – 80 х (100 – 90)
Ответ будет —

- = 110
Следовательно, значение для Y, когда значение X равно 100, будет равно 110.
Актуальность и использование
В основном используется для прогнозирования данных, выходящих за пределы текущего диапазона данных. В этом случае предполагается, что тенденция будет продолжаться для данных данных и даже за пределами этого диапазона, что не всегда так. Следовательно, следует осторожно использовать экстраполяцию. Вместо этого interpolationInterpolationInterpolation представляет собой математическую процедуру, применяемую для получения значения между двумя точками, имеющими заданное значение. Он аппроксимирует значение данной функции в заданном наборе дискретных точек. Его можно применять для оценки различных концепций стоимости, математики, статистики. Этот метод лучше подходит для того, чтобы сделать то же самое.
Рекомендуемые статьи
Эта статья была руководством по формуле экстраполяции. Здесь мы обсуждаем формулу для расчета значения зависимой переменной для независимой переменной, а также практические примеры и загружаемый шаблон Excel. Вы можете узнать больше об экономике из следующих статей:
- Revenue Run RateRevenue Run RateКомпании используют показатель выручки для прогнозирования годовой выручки на основе текущих уровней выручки, темпов роста, рыночного спроса и других соответствующих факторов, предполагая, что текущие доходы свободны от какой-либо сезонности или эффекта выбросов, а рыночные условия останутся неизменными. постоянный.Подробнее
- Формула скорости обращения денег
- Линия тренда ExcelЛиния тренда ExcelЛиния тренда, часто называемая линией наилучшего соответствия, отображает тренд данных. Он показывает общую тенденцию, закономерность или направление на основе доступных точек данных.Подробнее
- Формула множественной регрессииФормула множественной регрессииФормула множественной регрессии используется при анализе связи между зависимыми и многочисленными независимыми переменными. Формула = y = mx1 + mx2+ mx3+ хлеб больше
- Эффективная годовая ставкаЭффективная годовая ставкаЭффективная годовая ставка (EAR) — это ставка, фактически полученная от инвестиций или выплаченная по кредиту после начисления сложных процентов за определенный период времени, и используется для сравнения финансовых продуктов с различными периодами начисления сложных процентов, т. е. еженедельно, ежемесячно, ежегодно и т. д. По мере увеличения периодов начисления EAR увеличивается. Эффективная годовая ставка = (1 + i/n)n – 1Подробнее