Написание парсера с нуля: так ли страшен черт?
Время на прочтение
12 мин
Количество просмотров 92K
В прошлом топике я рассказывал о том, как мы с другом решили ради развлечения написать свой встраиваемый язык программирования для платформы .NET. У первой версии был серьезный недостаток — парсер был реализован на F# с помощью сторонней библиотеки. Из-за этого требовалась куча зависимостей, парсер работал медленно, а поддержка его была крайне муторным занятием.
Очевидно, что парсер нужно было переписать на C#, но при мысли о написании парсера с нуля вдруг находилась дюжина других срочных дел. Таким образом таск перекидывался и откладывался практически полгода и казался непосильным, а в итоге был сделан за 4 дня. Под катом я расскажу об удобном способе, позволившим реализовать парсер достаточно сложной грамматики без использования сторонних библиотек и не тронуться умом, а также о том, как это позволило улучшить язык LENS.
Но обо всем по порядку.
Первый блин
Как было сказано выше, в качестве ядра парсера мы использовали библиотеку FParsec. Причины данного выбора скорее исторические, нежели объективные: понравился легковесный синтаксис, хотелось поупражняться в использовании F#, и автор библиотеки очень оперативно отвечал на несколько вопросов по email.
Главным недостатком этой библиотеки для нашего проекта оказались внешние зависимости:
- Примерно десятимегабайтный F# Runtime
- 450 кб сборок самого FParsec
Кроме того, сам компилятор разбился на 3 сборки: парсер, синтаксическое дерево и точку входа. Сборка парсера занимала внушительные 130 кб. Для встраиваемого языка это абсолютно неприлично.
Другой проблемой было отображение ошибок. Лаконичная запись грамматики на местном DSL при некорректно введенной программе выдавала нечитаемую ошибку c перечислением ожидаемых лексем:
> let x =
> Ошибка: ожидается идентификатор
или число
или скобка
или вызов функции
или 'new'
или ...
Хотя кастомная обработка ошибок и возможна, DSL для нее явно не предназначен. Описание грамматики уродливо распухает и становится абсолютно неподдерживаемым.
Еще одним неприятным моментом была скорость работы. При «холодном старте» компиляция любого, даже самого простого скрипта занимала на моей машине примерно 350-380 миллисекунд. Судя по тому, что повторный запуск такого же скрипта занимал уже всего-то 5-10 миллисекунд, задержка была вызвана JIT-компиляцией.
Сразу оговорюсь — для большинства реальных задач время разработки куда критичнее, чем пара дополнительных библиотек или сотни миллисекунд, которые тратятся на разбор. С этой точки зрения написание рукопашного парсера является скорее учебным или эзотерическим упражнением.
Немного теории
Сферический парсер в вакууме представляет собой функцию, которая принимает исходный код, а возвращает некое промежуточное представление, по которому удобно будет сгенерировать код для используемой виртуальной машины или процессора. Чаще всего это представление имеет древовидную структуру и называется абстрактным синтаксическим деревом — АСД (в иностранной литературе — abstract syntactic tree, AST).
Древовидная структура особенно хороша тем, что ее обход в глубину отлично сочетается со стековой организацией, используемой во многих современных виртуальных машинах (например, JVM или .NET). Генерация кода в данной статье рассматриваться не будет, однако элементы синтаксического дерева, как результат работы парсера, будут время от времени упоминаться.
Итак, на входе мы имеем строку. Набор символов. Работать с ней в таком виде напрямую не слишком удобно — приходится учитывать пробелы, переносы строк и комментарии. Для упрощения себе жизни разработчики парсеров обычно разделяют разбор на несколько проходов, каждый из которых выполняет какую-то одну простую задачу и передает результат своей работы следующему:
- Лексический анализатор:
string -> IEnumerable<Lexem> - Синтаксический анализатор:
IEnumerable<Lexem> -> IEnumerable<Node> - Семантический анализатор:
IEnumerable<Node> -> ?
Поскольку семантический анализатор — штука сугубо индивидуальная, ее описание в данную статью не входит. Тем не менее, я поделюсь некоторыми полезными приемами для первых двух анализаторов.
Лексический анализатор
Требования:
- Скорость работы
- Легкость расширения
- Простота реализации
- Отслеживание положения в исходном тексте
Алгоритм лексера прост: он сканирует строку слева направо, пытаясь сопоставить текущее положение в строке с каждой известной ему лексемой. При удачном сопоставлении лексер сдвигается по строке направо на столько символов, сколько заняла предыдущая лексема, и продолжает поиск по новой до конца строки. Пробелы, табуляции и переводы строки для большинства грамматик можно просто игнорировать.
Все лексемы изначально стоит поделить на 2 типа — статические и динамические. К первым относятся те лексемы, которые можно выразить обычной строкой — ключевые слова и операторы. Лексемы типа идентификаторов, чисел или строк проще описать регулярным выражением.
Статические лексемы, в свою очередь, есть резон поделить на операторы и ключевые слова. Ключевые слова сопоставляются только в том случае, если следующий за ними символ не является допустимым для идентификатора (или дальше — конец строки). В противном случае возникнут проблемы с идентификаторами, чье начало совпадает с ключевым словом: например, "information" -> keyword(in), keyword(for), identifier(mation).
Пример реализации
enum LexemKind
{
Var,
Print,
Plus,
Minus,
Multiply,
Divide,
Assign,
Semicolon,
Identifier,
Number
}
class LocationEntity
{
public int Offset;
public int Length;
}
class Lexem : LocationEntity
{
public LexemKind Kind;
public string Value;
}
class LexemDefinition<T>
{
public LexemKind Kind { get; protected set; }
public T Representation { get; protected set; }
}
class StaticLexemDefinition : LexemDefinition<string>
{
public bool IsKeyword;
public StaticLexemDefinition(string rep, LexemKind kind, bool isKeyword = false)
{
Representation = rep;
Kind = kind;
IsKeyword = isKeyword;
}
}
class DynamicLexemDefinition : LexemDefinition<Regex>
{
public DynamicLexemDefinition(string rep, LexemKind kind)
{
Representation = new Regex(@"G" + rep, RegexOptions.Compiled);
Kind = kind;
}
}
static class LexemDefinitions
{
public static StaticLexemDefinition[] Statics = new []
{
new StaticLexemDefinition("var", LexemKind.Var, true),
new StaticLexemDefinition("print", LexemKind.Print, true),
new StaticLexemDefinition("=", LexemKind.Assign),
new StaticLexemDefinition("+", LexemKind.Plus),
new StaticLexemDefinition("-", LexemKind.Minus),
new StaticLexemDefinition("*", LexemKind.Multiply),
new StaticLexemDefinition("/", LexemKind.Divide),
new StaticLexemDefinition(";", LexemKind.Semicolon),
};
public static DynamicLexemDefinition[] Dynamics = new []
{
new DynamicLexemDefinition("[a-zA-Z_][a-zA-Z0-9_]*", LexemKind.Identifier),
new DynamicLexemDefinition("(0|[1-9][0-9]*)", LexemKind.Number),
};
}
class Lexer
{
private char[] SpaceChars = new [] { ' ', 'n', 'r', 't' };
private string Source;
private int Offset;
public IEnumerable<Lexem> Lexems { get; private set; }
public Lexer(string src)
{
Source = src;
Parse();
}
private void Parse()
{
var lexems = new List<Lexem>();
while(InBounds())
{
SkipSpaces();
if(!InBounds()) break;
var lex = ProcessStatic() ?? ProcessDynamic();
if(lex == null)
throw new Exception(string.Format("Unknown lexem at {0}", Offset));
lexems.Add(lex);
}
Lexems = lexems;
}
private void SkipSpaces()
{
while(InBounds() && Source[Offset].IsAnyOf(SpaceChars))
Offset++;
}
private Lexem ProcessStatic()
{
foreach(var def in LexemDefinitions.Statics)
{
var rep = def.Representation;
var len = rep.Length;
if(Offset + len > Source.Length || Source.Substring(Offset, len) != rep)
continue;
if(Offset + len < Source.Length && def.IsKeyword)
{
var nextChar = Source[Offset + len];
if(nextChar == '_' || char.IsLetterOrDigit(nextChar))
continue;
}
Offset += len;
return new Lexem { Kind = def.Kind, Offset = Offset, Length = len };
}
return null;
}
private Lexem ProcessDynamic()
{
foreach(var def in LexemDefinitions.Dynamics)
{
var match = def.Representation.Match(Source, Offset);
if(!match.Success)
continue;
Offset += match.Length;
return new Lexem { Kind = def.Kind, Offset = Offset, Length = match.Length, Value = match.Value };
}
return null;
}
private bool InBounds()
{
return Offset < Source.Length;
}
}
Преимущества:
- Работает быстро
- Элементарное устройство, можно написать за полчаса
- Новые лексемы добавляются очень просто
- Способ подходит для множества грамматик
Недостатки:
- Танцы с бубном при разборе языка со значимыми пробелами
- Порядок объявления лексем важен: желательно сортировать по длине
Синтаксический анализатор
Требования:
- Легкость расширения при изменении грамматики
- Возможность описывать подробные сообщения об ошибках
- Возможность заглядывать вперед на неограниченное количество позиций
- Автоматическое отслеживание положения в исходном коде
- Лаконичность, близость к исходной грамматике
Для того, чтобы упростить себе жизнь при написании парсера, следует оформить грамматику специальным образом. Никаких сложных конструкций! Все правила можно поделить на 3 типа:
- Описание — один конкретный узел:
(var_expr = "var" identifier "=" expr) - Повторение — один конкретный узел повторяется многократно, возможно с разделителем:
main = { stmt ";" } - Альтернатива — выбор из нескольких узлов
(stmt = var_expr | print_expr | assign_expr | other)
Правило-описание разбирается по шагам: проверили тип текущей лексемы, сдвинулись на следующую, и так до конца правила. С каждой проверенной лексемой можно сделать некоторое действие: выдать подробную ошибку в случае несовпадения, сохранить ее значение в узле и т.д.
Правило-перечисление — это цикл. Чтобы вернуть последовательность значений, в C# есть очень удобный функционал для создания генераторов с помощью yield return.
Правило-альтернатива по очереди вызывает правила-варианты с помощью специальной обертки, которая позволяет откатиться в исходное состояние. Правила просто вызываются по порядку, пока хотя бы одно из них не совпадет, связанные оператором coalesce (??).
Тут пытливый читатель спросит:
— Как это, просто вызываются по порядку? А как же опережающие проверки? Например, так:
if(CurrentLexem.Type == LexemType.Var) return parseVar();
if(CurrentLexem.Type == LexemType.For) return parseFor();
...
Признаюсь, свой первый серьезный парсер я написал именно так. Однако это плохая идея!
Во-первых, заглянуть можно только на фиксированное число символов. Для всяких for или var, конечно, подойдет. Но, допустим, у нас есть такие правила в грамматике:
assign = id_assign | member_assign | index_assign
id_assign = identifier "=" expr
member_assign = lvalue "." identifier "=" expr
index_assign = lvalue "[" expr "]" "=" expr
Если с id_assign еще все понятно, то оба других правила начинаются с нетерминала lvalue, под которым может скрываться километровое выражение. Очевидно, что никаких опережающих проверок тут не напасешься.
Другая проблема — смешение зон ответственности. Чтобы грамматика была расширяемой, правила должны быть как можно более независимы друг от друга. Данный подход требует, чтобы внешнее правило знало о составе внутренних, что увеличивает связность и осложняет поддержку при изменении грамматики.
Так зачем нам вообще опережающие проверки? Пусть каждое правило само знает о том, насколько далеко нужно заглянуть вперед, чтобы убедиться, что именно оно наиболее подходящее.
Рассмотрим на примере выше. Допустим, у нас есть текст: a.1 = 2:
- Первой вызывается альтернатива
id_assign. - Идентификатор
aуспешно совпадает. - Дальше идет точка, а ожидается знак «равно». Однако с идентификатора могут начинаться и другие правила, поэтому ошибка не выбрасывается.
- Правило assign откатывает состояние назад и пробует дальше.
- Вызывается альтернатива
member_assign. - Идентификатор и точка успешно совпадают. В грамматике нет других правил, которые начинаются с идентификатора и точки, поэтому дальнейшие ошибки не имеет смысл пытаться обработать откатыванием состояния.
- Число
1не является идентификатором, поэтому выкидывается ошибка.
Сначала напишем несколько полезных методов:
Скрытый текст
partial class Parser
{
private List<Lexem> Lexems;
private int LexemId;
#region Lexem handlers
[DebuggerStepThrough]
private bool Peek(params LexemType[] types)
{
var id = Math.Min(LexemId, Lexems.Length - 1);
var lex = Lexems[id];
return lex.Type.IsAnyOf(types);
}
[DebuggerStepThrough]
private Lexem Ensure(LexemType type, string msg, params object[] args)
{
var lex = Lexems[LexemId];
if(lex.Type != type)
error(msg, args);
Skip();
return lex;
}
[DebuggerStepThrough]
private bool Check(LexemType lexem)
{
var lex = Lexems[LexemId];
if (lex.Type != lexem)
return false;
Skip();
return true;
}
[DebuggerStepThrough]
private void Skip(int count = 1)
{
LexemId = Math.Min(LexemId + count, Lexems.Length - 1);
}
#endregion
#region Node handlers
[DebuggerStepThrough]
private T Attempt<T>(Func<T> getter) where T : LocationEntity
{
var backup = LexemId;
var result = Bind(getter);
if (result == null)
LexemId = backup;
return result;
}
[DebuggerStepThrough]
private T Ensure<T>(Func<T> getter, string msg) where T : LocationEntity
{
var result = Bind(getter);
if (result == null)
throw new Exception(msg);
return result;
}
[DebuggerStepThrough]
private T Bind<T>(Func<T> getter) where T : LocationEntity
{
var startId = LexemId;
var start = Lexems[LexemId];
var result = getter();
if (result != null)
{
result.StartLocation = start.StartLocation;
var endId = LexemId;
if (endId > startId && endId > 0)
result.EndLocation = Lexems[LexemId - 1].EndLocation;
}
return result;
}
#endregion
}
С их помощью реализация приведенной выше грамматики становится практически тривиальной:
partial class Parser
{
public Node ParseAssign()
{
return Attempt(ParseIdAssign)
?? Attempt(ParseMemberAssign)
?? Ensure(ParseIndexAssign, "Неизвестный тип выражения!");
}
public Node ParseIdAssign()
{
var id = TryGetValue(LexemType.Identifier);
if (id == null) return null;
if (!Check(LexemType.Assign)) return null;
var expr = Ensure(ParseExpr, "Ожидается присваиваемое выражение!");
return new IdAssignNode { Identifier = id, Expression = expr };
}
public Node ParseMemberAssign()
{
var lvalue = Attempt(ParseLvalue);
if (lvalue == null) return null;
if (!Check(LexemType.Dot)) return null;
var member = TryGetValue(LexemType.Identifier);
if (member == null) return null;
if (!Check(LexemType.Assign)) return null;
var expr = Ensure(ParseExpr, "Ожидается присваиваемое выражение!");
return new MemberAssignNode { Lvalue = lvalue, MemberName = member, Expression = expr };
}
public Node ParseIndexAssign()
{
var lvalue = Attempt(ParseLvalue);
if (lvalue == null) return null;
if (!Check(LexemType.SquareBraceOpen)) return null;
var index = Ensure(ParseExpr, "Ожидается выражение индекса!");
Ensure(LexemType.SquareBraceClose, "Не закрыта скобка!");
Ensure(LexemType.Assign, "Ожидается знак присваивания!");
var expr = Ensure(ParseExpr, "Ожидается присваиваемое выражение!");
return new IndexAssignNode { Lvalue = lvalue, Index = index, Expression = expr };
}
}
Атрибут DebuggerStepThrough сильно помогает при отладке. Поскольку все вызовы вложенных правил так или иначе проходят через Attempt и Ensure, без этого атрибута они будут постоянно бросаться в глаза при Step Into и забивать стек вызовов.
Преимущества данного метода:
- Откат состояния — очень дешевая операция
- Легко управлять тем, до куда можно откатываться
- Легко отображать детальные сообщения об ошибках
- Не требуются никакие внешние библиотеки
- Небольшой объем генерируемого кода
Недостатки:
- Реализация парсера вручную занимает время
- Сложность написания и оптимальность работы зависят от качества грамматики
- Леворекурсивные грамматики следует разруливать самостоятельно
Операторы и приоритеты
Неоднократно я видел в описаниях грамматик примерно следующие правила, показывающие приоритет операций:
expr = expr_1 { op_1 expr_1 }
expr_1 = exp2_2 { op_2 expr_2 }
expr_2 = exp2_3 { op_3 expr_3 }
expr_3 = int | float | identifier
op_1 = "+" | "-"
op_2 = "*" | "/" | "%"
op_3 = "**"
Теперь представим, что у нас есть еще булевы операторы, операторы сравнения, операторы сдвига, бинарные операторы, или какие-нибудь собственные. Сколько правил получается, и сколько всего придется поменять, если вдруг придется добавить новый оператор с приоритетом где-то в середине?
Вместо этого, можно убрать из грамматики вообще все описание приоритетов и закодить его декларативно.
Пример реализации
expr = sub_expr { op sub_expr }
sub_expr = int | float | identifier
partial class Parser
{
private static List<Dictionary<LexemType, Func<Node, Node, Node>>> Priorities =
new List<Dictionary<LexemType, Func<Node, Node, Node>>>
{
new Dictionary<LexemType, Func<Node, Node, Node>>
{
{ LexemType.Plus, (a, b) => new AddNode(a, b) },
{ LexemType.Minus, (a, b) => new SubtractNode(a, b) }
},
new Dictionary<LexemType, Func<Node, Node, Node>>
{
{ LexemType.Divide, (a, b) => new DivideNode(a, b) },
{ LexemType.Multiply, (a, b) => new MultiplyNode(a, b) },
{ LexemType.Remainder, (a, b) => new RemainderNode(a, b) }
},
new Dictionary<LexemType, Func<Node, Node, Node>>
{
{ LexemType.Power, (a, b) => new PowerNode(a, b) }
},
};
public NodeBase ProcessOperators(Func<Node> next, int priority = 0)
{
if (priority == Priorities.Count)
return getter();
var node = ProcessOperators(next, priority + 1);
var ops = Priorities[priority];
while (Lexems[LexemId].IsAnyOf(ops.Keys))
{
foreach (var curr in ops)
{
if (check(curr.Key))
{
node = curr.Value(
node,
ensure(() => ProcessOperators(next, priority + 1), "Ожидается выражение!")
);
}
}
}
return node;
}
}
Теперь для добавления нового оператора необходимо лишь дописать соответствующую строчку в инициализацию списка приоритетов.
Добавление поддержки унарных префиксных операторов оставляю в качестве тренировки для особо любопытных.
Что нам это дало?
Написанный вручную парсер, как ни странно, стало гораздо легче поддерживать. Добавил правило в грамматику, нашел соответствующее место в коде, дописал его использование. Backtracking hell, который частенько возникал при добавлении нового правила в старом парсере и вызывал внезапное падение целой кучи на первый взгляд не связанных тестов, остался в прошлом.
Итого, сравнительная таблица результатов:
| Параметр | FParsec Parser | Pure C# |
| Время парсинга при 1 прогоне | 220 ms | 90 ms |
| Время парсинга при дальнейших прогонах | 5 ms | 6 ms |
| Размер требуемых библиотек | 800 KB + F# Runtime | 260 KB |
Скорее всего, возможно провести оптимизации и выжать из синтаксического анализатора больше производительности, но пока и этот результат вполне устраивает.
Избавившись от головной боли с изменениями в грамматике, мы смогли запилить в LENS несколько приятных вещей:
Цикл for
Используется как для обхода последовательностей, так и для диапазонов:
var data = new [1; 2; 3; 4; 5]
for x in data do
println "value = {0}" x
for x in 1..5 do
println "square = {0}" x
Композиция функций
С помощью оператора :> можно создавать новые функции, «нанизывая» существующие:
let invConcat = (a:string b:string) -> b + a
let invParse = incConcat :> int::Parse
invParse "37" "13" // 1337
Частичное применение возможно с помощью анонимных функций:
fun add:int (x:int y:int) -> x + y
let addTwo = int::TryParse<string> :> (x:int -> add 2 x)
addTwo "40" // 42
Улучшения синтаксиса
- Однострочные комментарии:
somecode () // comment - Неинициализированные переменные:
var x : int - Скобки вокруг единственного аргумента лямбды опциональны:
var inc = x:int -> x + 1 - Скобки в управляющих конструкциях убраны:
if x then a () else b () while a < b do println "a = {0}" a a = a + 1 - Появился блок
try/finally - Скобки при передаче индекса или поля в функцию опциональны:
print "{0} = {1}" a[1] SomeType::b
Проект хоть и медленно, но развивается. Осталось еще много интересных задач. На следующую версию планируется:
- Объявление generic-типов и функций
- Возможность пометить функции или типы атрибутами
- Поддержку событий
Также можно скачать собранные демки под Windows.
Однажды мы рассказывали, как утащить что угодно с любого сайта, — написали свой парсер и забрали с чужого сайта заголовки статей. Теперь сделаем круче — покажем на примере нашего сайта, как можно спарсить вообще весь текст всех статей.
Парсинг — это когда вы забираете какую-то конкретную информацию с сайта в автоматическом режиме. Для этого пишется софт (скрипт или отдельная программа), софт настраивается под конкретный сайт, и дальше он ходит по нужным страницам и всё оттуда забирает.
После парсинга полученный текст можно передать в другие программы — например подстроить свои цены под цены конкурентов, обновить информацию на своём сайте, проанализировать текст постов или собрать бигдату для тренировки нейросетей.
Что делаем
Сегодня мы спарсим все статьи «Кода» кроме новостей и задач, причём сделаем всё так:
- Научимся обрабатывать одну страницу.
- Сделаем из этого удобную функцию для обработки.
- Найдём все адреса всех нужных страниц.
- Выберем нужные нам рубрики.
- Для каждой рубрики создадим отдельный файл, в который добавим всё текстовое содержимое всех статей в этой рубрике.
Чтобы потом можно было нормально работать с текстом, мы не будем парсить вставки с примерами кода, а ещё постараемся избавиться от титров, рекламных баннеров и плашек.
Будем работать поэтапно: сначала научимся разбирать контент на одной странице, а потом подгрузим в скрипт все остальные статьи.
Выбираем страницу для отладки
Технически самый простой парсинг делается двумя командами в Python, одна из которых — подключение сторонней библиотеки. Но этот код не слишком полезен для нашей задачи, сейчас объясним.
from urllib.request import urlopen
inner_html_code = str(urlopen('АДРЕС СТРАНИЦЫ').read(),'utf-8')Когда мы заберём таким образом страницу, мы получим сырой код, в котором будет всё: метаданные, шапка, подвал и т. д. А нам нужно не только достать информацию из самой статьи (а не всей страницы), а ещё и очистить её от ненужной информации.
Чтобы скрипт научился отбрасывать ненужное, придётся ему прописать, что именно отбрасывать. А для этого нужно знать, что нам не нужно. А значит, нам нужно взять какую-то старую статью, в которой будут все ненужные элементы, и на этой одной странице всё объяснить.
Для настройки скрипта мы возьмём нашу старую статью. В ней есть всё нужное для отладки:
- текст статьи,
- подзаголовки,
- боковые ссылки,
- кат с кодом,
- просто вставки кода в текст,
- титры,
- рекламный баннер.
Получаем сырой текст
Вот что мы сейчас сделаем:
- Подключим библиотеку urlopen для обработки адресов страниц.
- Подключим библиотеку BeautifulSoup для разбора исходного кода страницы на теги.
- Получим исходный код страницы по её адресу.
- Распарсим его по тегам.
- Выведем текстовое содержимое распарсенной страницы.
На языке Python это выглядит так:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSoup
from bs4 import BeautifulSoup
# получаем исходный код страницы
inner_html_code = str(urlopen('https://thecode.media/parsing/').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# выводим содержимое страницы
print(inner_soup.get_text())Если посмотреть на результат, то видно, что в вывод пошло всё: и программный код из примеров, и текст статьи, и служебные плашки, и баннер, и ссылки с рекомендациями. Такой мусорный текст не годится для дальнейшего анализа:
Чистим текст
Так как нам требуется только сама статья, найдём раздел, в котором она лежит. Для этого посмотрим исходный код страницы, нажав Ctrl+U или ⌘+⌥+U. Видно, что содержимое статьи лежит в блоке <div class="article-content line-numbers">, причём такой блок на странице один.

Чтобы из всего исходного кода оставить только этот блок, используем команду find() с параметром 'div', {"class": 'article-content'} — она найдёт нужный нам блок, у которого есть характерный признак класса.
Добавим эту команду перед выводом текста на экран:
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
Стало лучше: нет мусора до и после статьи, но в тексте всё ещё много лишнего — содержимое ката с кодом, преформатированный код (вот такой), вставки с кодом, титры и рекламный баннер.
Чтобы избавиться и от этого, нам нужно знать, в каких тегах или блоках это лежит. Для этого нам снова понадобится заглянуть в исходный код страницы. Логика будет такая: находим фрагмент текста → смотрим код, который за него отвечает, → удаляем этот код из нашей переменной.Например, если мы хотим убрать титры, то находим блок, где они лежат, а потом в цикле удаляем его командой decompose().

Сделаем функцию, которая очистит наш код от любых разделов и тегов, которые мы укажем в качестве параметра:
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()А теперь добавим такой код перед выводом содержимого:
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
Точно так же проанализируем исходный код и добавим циклы для удаления остального мусора:
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры, перебирая все их возможные индексы в цикле (потому что баннеры в коде имеют номера от 1 до 99)
for i in range(99):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')Теперь всё в порядке: у нас есть только текст статьи, без внешнего обвеса, лишнего кода и ссылок. Можно переходить к массовой обработке.
Собираем функцию
У нас есть скрипт, который берёт одну конкретную ссылку, идёт по ней, чистит контент и получает очищенный текст. Сделаем из этого функцию — на вход она будет получать адрес страницы, а на выходе будет давать обработанный и очищенный текст. Это нам пригодится на следующем шаге, когда будем обрабатывать сразу много ссылок.
Если запустить этот скрипт, получим тот же результат, что и в предыдущем разделе.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
print(clear_text('https://thecode.media/parsing/'))Получаем адреса всех страниц
Одна из самых сложных вещей в парсинге — получить список адресов всех нужных страниц. Для этого можно использовать:
- карту сайта,
- внутренние рубрикаторы,
- разделы на сайте,
- готовые страницы со всеми ссылками.
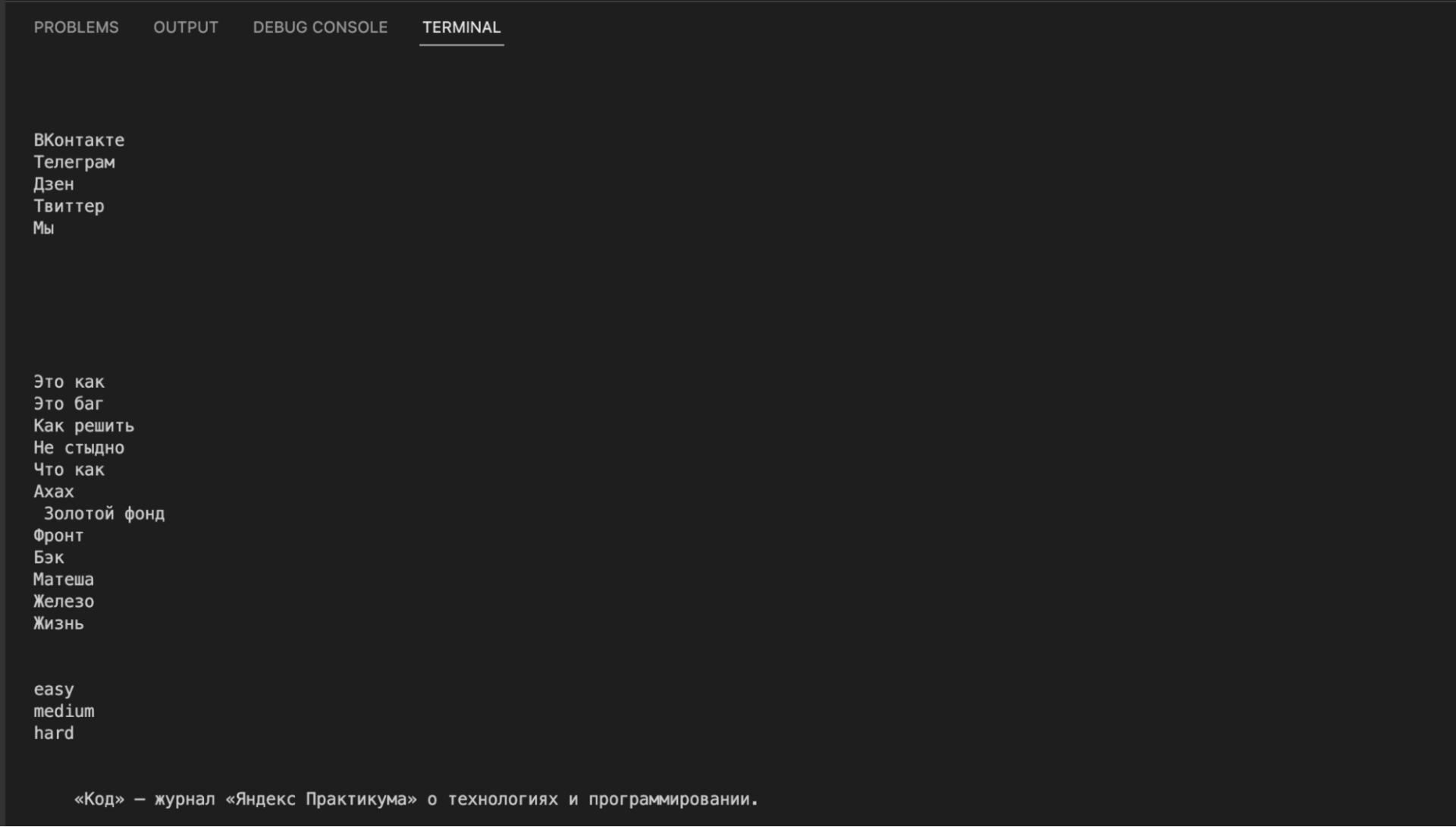
В нашем случае мы воспользуемся готовой страницей — там собраны все статьи с разбивкой по рубрикам: https://thecode.media/all. Но даже в этом случае нам нужно написать код, который обработает эту страницу и заберёт оттуда только адреса статей. Ещё нужно предусмотреть, что нам не нужны ссылки из новостей и задач.
Идём в исходный код общей страницы и видим, что все ссылки лежат внутри списка:

При этом каждая категория статей лежит в своём разделе — именно это мы и будем использовать, чтобы обработать только нужные нам категории. Например, вот как рубрика «Ахах» выглядит на странице:
А вот она же — но в исходном коде. По названию легко понять, какой блок за неё отвечает:
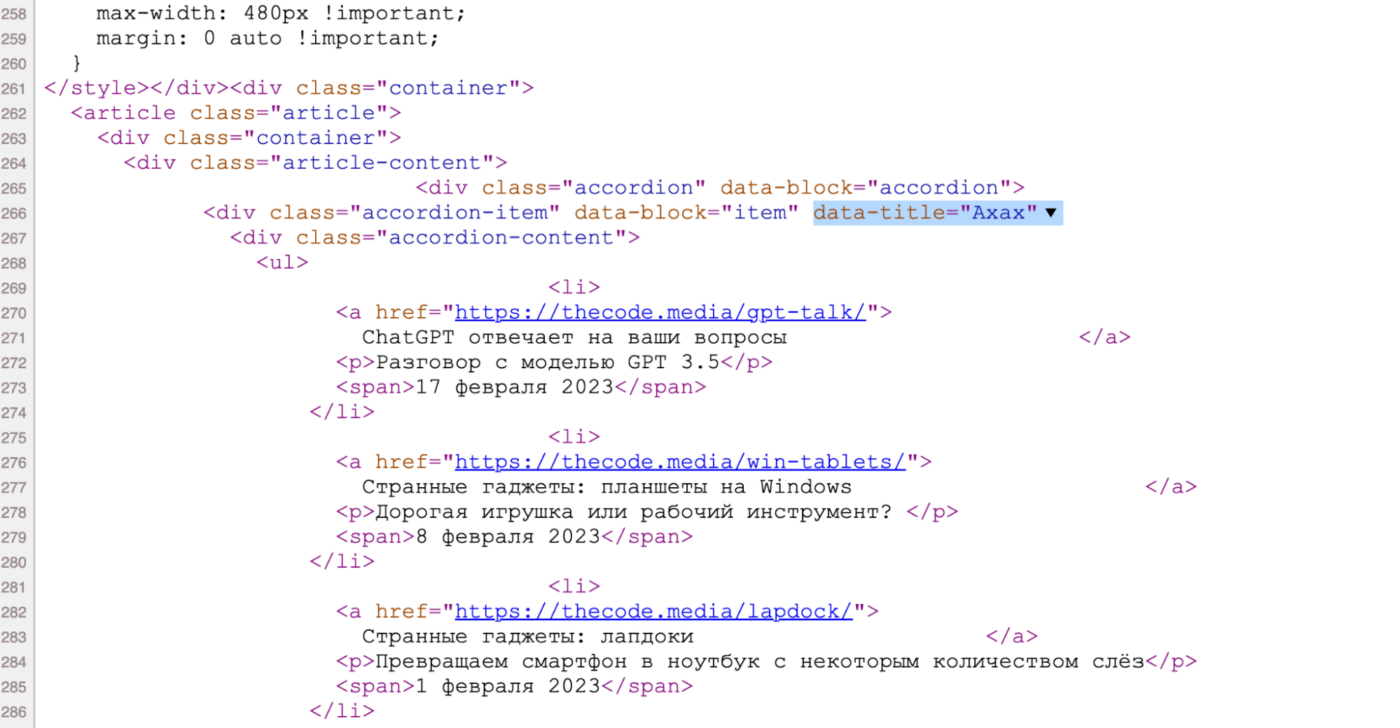
Чтобы найти раздел в коде по атрибуту, используем команду find() с параметром attrs — в нём мы укажем название рубрики. А чтобы найти адрес в ссылке — используем команду select(), в которой укажем, что ссылка должна лежать внутри элемента списка.
Теперь логика будет такая:
- Создаём список с названиями нужных нам рубрик.
- Делаем функцию, куда будем передавать эти названия.
- Внутри функции находим рубрику по атрибуту.
- Перебираем все элементы списка со ссылками.
- Находим там адреса и записываем в переменную.
- Для проверки — выводим переменную с адресами на экран.
def get_all_url(data_title):
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# выводим найденные адреса
print(url)
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)
На выходе у нас все адреса страниц из нужных рубрик. Теперь объединим обе функции и научим их сохранять текст в файл.
Сохраняем текст в файл
Единственное, чего нам сейчас не хватает, — это сохранения в файл. Чтобы каждая рубрика хранилась в своём файле, привяжем имя файла к названию рубрики. Дальше логика будет такая:
- Берём функцию get_all_url(), которая формирует список всех адресов для каждой рубрики.
- В конец этой функции добавляем команду создания файла с нужным названием.
- Открываем файл для записи.
- Перебираем в цикле все найденные адреса и тут же отправляем каждый адрес в функцию clear_text().
- Результат работы этой функции — готовый контент — записываем в файл и переходим к следующему.
Так у нас за один прогон сформируются адреса, и мы получим содержимое страницы, которые сразу запишем в файл. Читайте комментарии, чтобы разобраться в коде:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
# формируем список адресов для указанной рубрики
def get_all_url(data_title):
# считываем страницу со всеми адресами
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# имя файла для содержимого каждой рубрики
content_file_name = data_title + '_content.txt'
# открываем файл и стираем всё, что там было
file = open(content_file_name, "w")
# перебираем все адреса из списка
for x in url:
# сохраняем обработанный текст в файле и переносим курсор на новую строку
file.write(clear_text(x) + 'n')
# закрываем файл
file.close()
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)
Что дальше
Теперь у нас есть все тексты всех статей. Как-нибудь проанализируем частотность слов в них (как в проекте с текстами Льва Толстого) или научим нейросеть писать новые статьи на основе старых.
Вёрстка:
Кирилл Климентьев
Парсеры новостных сайтов достаточно востребованы, например, если у вас новостой агрегатор, или, к примеру, вам нужно собирать местные новости из различных ресурсов для показа на своем сайте с географическим таргетированием, то вам необходим парсер. Также данные новостных агенств и СМИ часто используются для проведения исследований, машинного обучения и анализа. Распарсить новостую ленту на большинстве ресурсов, как правило, несложно, именно поэтому мы возьмем один из простых сайтов, а именно РИА Новости и научим вас писать парсеры самостоятельно.
Мы будем использовать Google Chrome как наш основной инструмент для работы с сайтом, и для начала мы советуем вам поставить расширение для Google Chrome: Quick Javascript Switcher — оно позволит вам быстро выключать и включать Javascript для сайтов. Это используется для того, чтобы быстро определить как именно данные выводятся на страницу: на стороне сервера или с помошью Javascript (это могут быть данные, внедренные в JS на странице, скрытый блок на странице, который включается JS или же данные забираются дополнительным XHR запросом).
Давайте откроем страницу с лентой https://ria.ru/lenta/ в нашем браузере и отключим JS для сайта с помощью расширения которое мы поставили ранее:
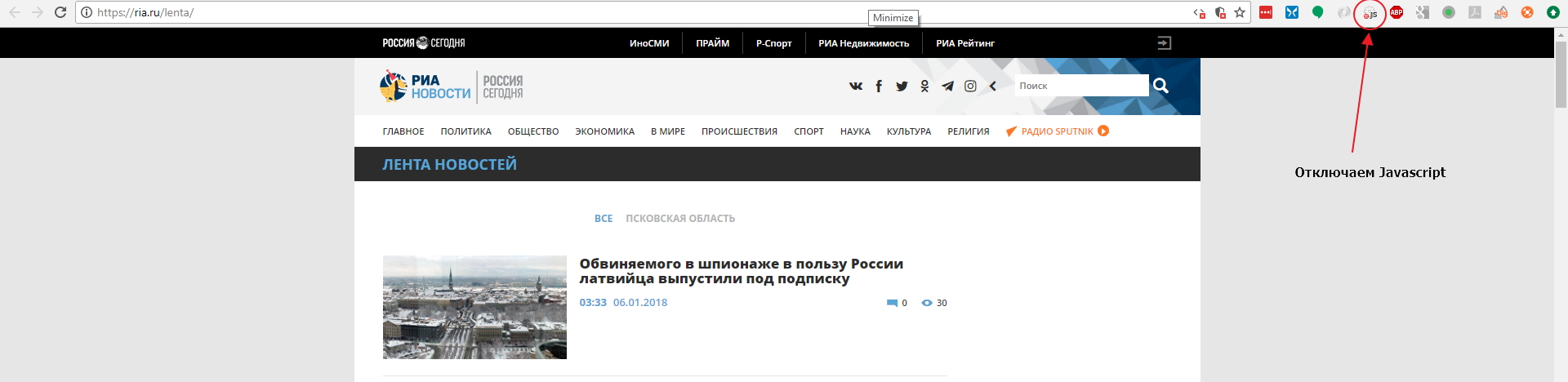
Мы увидим что данные ленты отображаются в браузере. Это означает, что новостная лента формируется на стороне сервера и мы сможем забрать данные просто загрузив страницу в парсер. Однако на странице показано только 20 последних заголовков и что же нам делать если нужно забирать 200 последних? Нам придется изучить механизм работы пагинатора. На разных сайтах пагинаторы работают по разному, поэтому не существует универсального решения и для каждого сайта вам придется разбираться в механизме его работы.
Откроем Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Показать код»:
После этого у вас откроется интерфейс разработчика:
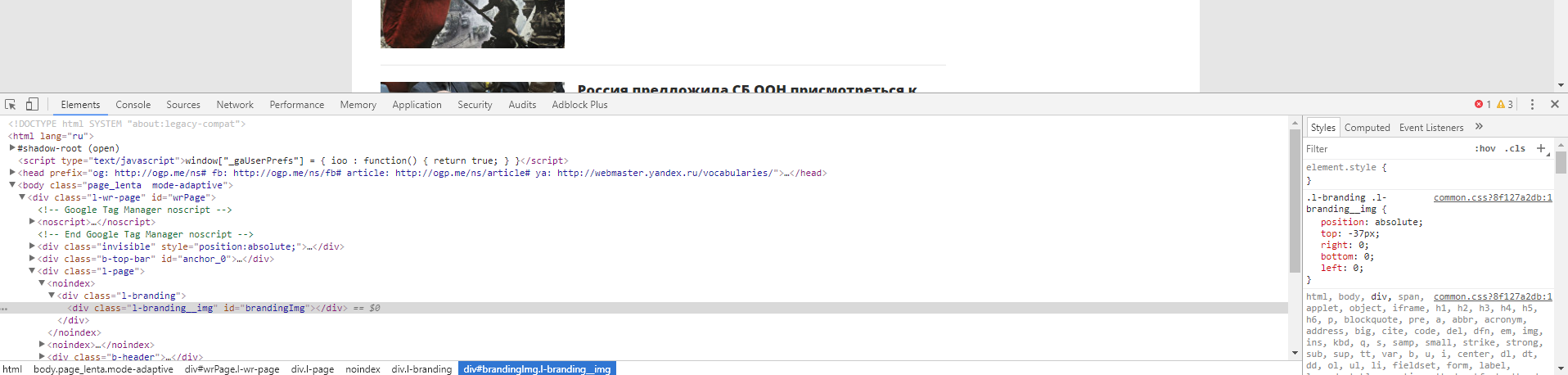
В основном мы будем взаимодействовать с вкладками Elements и Network. Elements — поможет нам работать с DOM структурой, находить элементы страницы, проверять CSS селекторы, искать CSS селекторы и содержимое, и так далее. Во вкладке Network мы можем изучать запросы, которые делает браузер к серверу. Это потребуется нам для нахождения XHR или JS запросов, или же если нам нужно изучить структуру какого-либо запроса (заголовки, куки и тд) для точной имитации его в парсере. Если вы незнакомы с инструментами для разработчика, мы рекомендуем вам посмотреть следующее обзорное видео: Chrome DevTools. Обзор основных возможностей веб-инспектора.
Сейчас нам нужно добраться до конца страницы и найти там пагинатор. Мы видим что здесь он организован как одна кнопка «ЗАГРУЗИТЬ ЕЩЕ», которая подгружает следующие 20 записей используя XHR (Ajax) запрос, то есть если вы кликните на кнопку, ничего не произойдет, поскольку мы выключили Javascript для этого сайта.
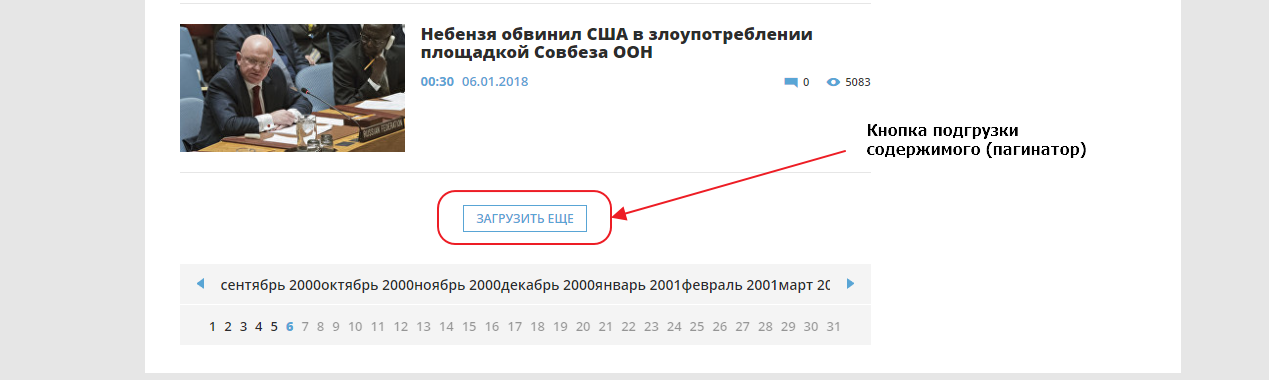
Первым делом найдем эту кнопку в элементах. Для того, чтобы это сделать быстро, можно воспользоваться специальным инструментом для выбора элемента на странице:
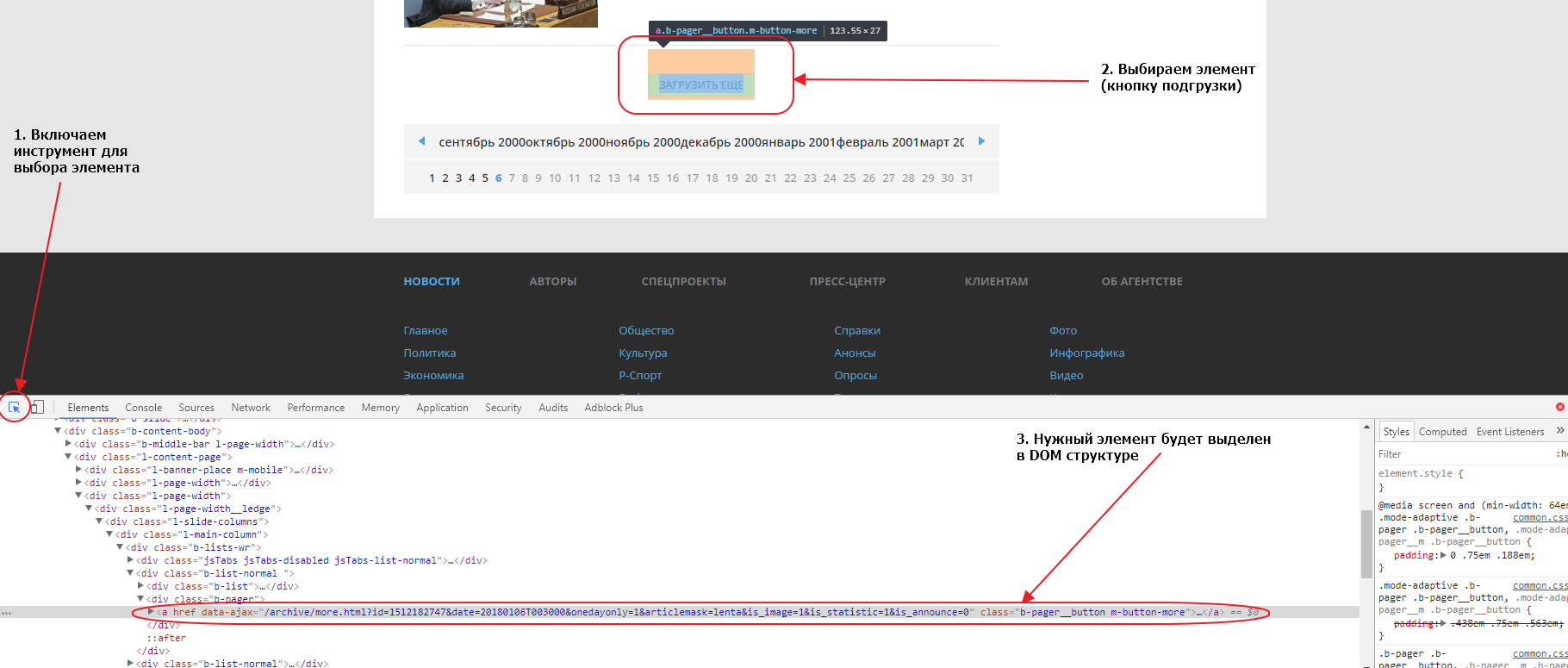
Если мы внимательно посмотрим на элемент, мы увидим что атрибут href у него пустой. Именно поэтому ничего не происходит при нажатии на линк, если отключен Javascript. Однако, мы видим что URL, используемый для подгрузки, указан в атрибуте data-ajax, именно этот URL и используется JS для подгрузки следующих 20 записей при нажатии на кнопку. Так как URL нам известен, нам совершенно не нужно анализировать запросы во вкладке Network. Соответсвенно, чтобы забрать следующие 20 записей, нам нужно забрать парсером этот URL:
https://ria.ru/archive/more.html?id=1512199556&date=20180106T154008&onedayonly=1&articlemask=lenta&is_image=1&is_statistic=1&is_announce=0.
Если загрузить в новой вкладке браузера этот URL мы получим следующие 20 записей и увидим что там тоже есть кнопка для загрузки следующих записей. Теперь нам нужно найти селектор (CSS селектор) для этого элемента. Сделаем это во второй вкладке, в которой у нас загружены вторые 20 записей. Также открываем в этой вкладке инструменты разработчика и выбираем элемент-ссылку «Загрузить еще», так, чтобы элемент выделился в DOM структуре. Теперь нужно кликнуть правой кнопкой мыши на элементе, затем выбрать опцию Copy и следом опцию Copy selector:
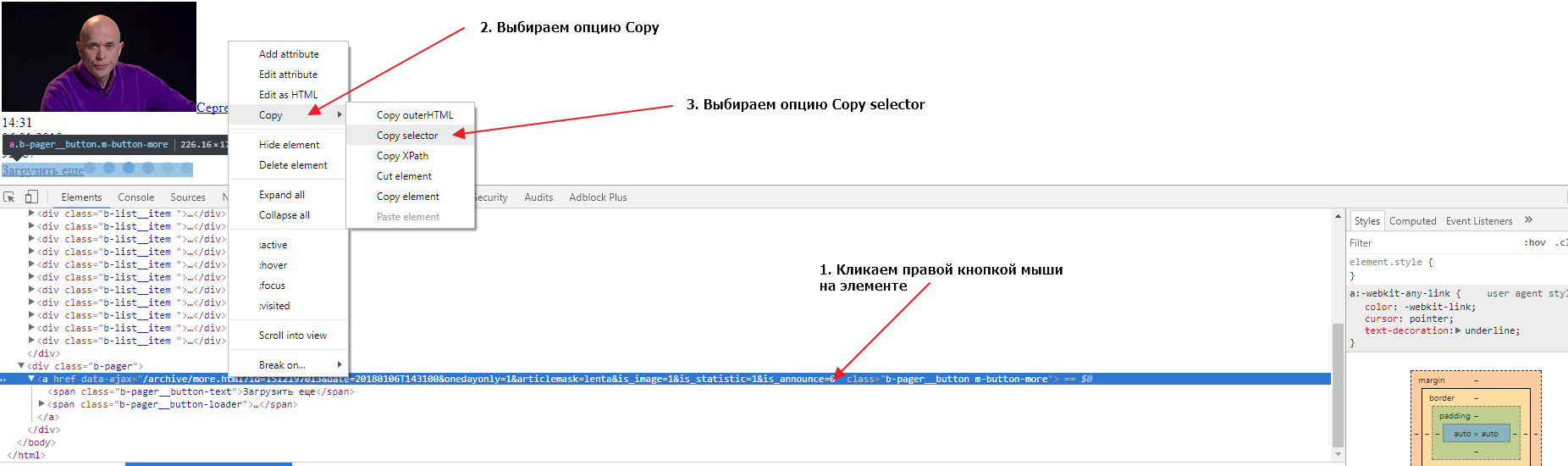
Давайте проверим, выбирает ли наш селектор ровно один элемент во второй и первой вкладке браузера. Для этого нужно в инструментах разработчика сделать активной вкладку Elements, нажать сочетание клавиш CTRL + F и в открывшуюся форму вставить наш селектор:

Мы видим, что селектор выбирает только один элемент, что очень хорошо. Если бы селектор выбирал несколько элементов, нам бы пришлось проверить все выбранные элементы и, либо подкорректировать селектор, так чтобы он выбирал только один элемент, либо в парсере брать срез найденных по селектору элементов, поскольку нам нужен только один элемент.
Тоже самое нужно сделать для другой вкладки, там где у нас открыта начальная страница. Сделать это нужно, чтобы удостовериться, что селекторы одинаковые на основной странице и на странице подгрузки. Иметь одну логику работы всегда лучше чем несколько, поэтому принцип унификации очень важен, в том числе и для подбора CSS селекторов. Если мы попробуем поискать наш селектор, мы обнаружим, что ничего не найдено. Дело в том, что элемент div.b-pager > a не находится в руте ноды body. Если мы уберем из пути body > и оставим только div.b-pager > a, то наш элемент будет найден в обеих вкладках и только один раз.
Мы определили, что для организации подгрузки данных в парсере, после загрузки страницы, мы должны найти элемент div.b-pager > a, забрать содержимое атрибута data-ajax и пройти по этому URL. Поскольку на страницах с подгрузкой структура элементов такая же, мы можем использовать единый логический блок. А для организации переходов по страницам мы можем использовать пул линков. Изначально мы поместим в пул только первый URL https://ria.ru/lenta/ и затем на каждой итерации мы будем добавлять в пул новый URL, который мы будем извлекать с загруженной страницы. Так мы организуем пагинацию в нашем парсере.
Теперь нам нужно определить как нам забирать новости со страниц, для этого нам нужно найти главный элемент блока в который обернута каждая новость. Сделать это мы можем точно так же, как мы делали это для кнопки подгрузки данных:
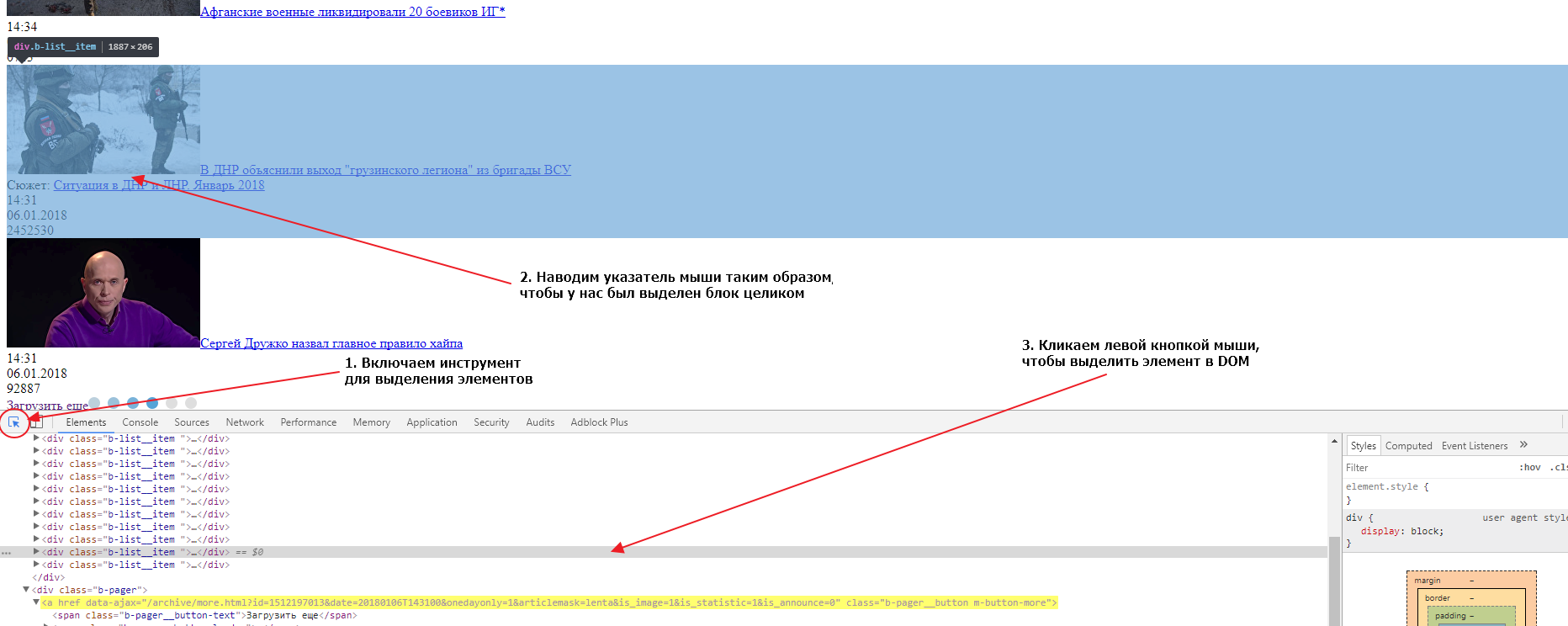
Если вы внимательно посмотрите на DOM структуру, вы увидите, что каждая новость обернута в элемент div с классом b-list__item. Таких элементов на странице ровно 20. Это и есть элемент, который нам нужен и CSS селектор для него будет div.b-list__item. Давайте сейчас проверим, насколько верно мы определили селектор для обеих вкладок (страницы с подгрузкой и основной страницы). Делаем мы это так же как мы проверяли валидность селектора для кнопки подгрузки. На обеих страницах селектор найдет по 20 элементов, значит наш селектор верен и мы можем его использовать.
Наш парсер на каждой странице должен находить этот селектор, и затем для каждого найденного элемента создавать новый объект данных, проходить в дочерние элементы, извлекать данные и записывать их в поля этого объекта данных, записывать объект данных в базу данных.
Давайте откроем один из элементов. Посмотрим какие у него есть дочерние элементы и какие данные нам нужны:

URL до страницы с новостью — находится просто в теге a, у этого тега нет класса или других атрибутов, кроме href. Поэтому единственный селектор, который мы можем использовать — a. Обратите внимание, что селекторы мы строим относительно родительского блока, поскольку мы в нем находимся, а не относительно всей страницы. Однако при таком селекторе если в блоке новости друг окажется еще один тег a в наших данных будет записан только последний, а нам нужен первый, поэтому мы можем брать срез элементов (элемент с номером 0) или же мы можем проверять в нашем a наличие дочернего элемента span с классом b-list__item-title. В последнем случае наш селектор будет выглядеть как a:haschild(span.b-list__item-title).
Изображение — нам нужно забрать URL до зображения, который находится в атрибуте src тега img. У этого тега есть атрибут itemprop=»associatedMedia», который выглядит достаточно надежным признаком для выборки нужного тега img. Поэтому мы можем использовать его в CSS селекторе: img[itemprop=»associatedMedia»].
Заголовок — здесь нет никаких подводных камней, наш заголовок находится в элементе span с классом b-list__item-title, поэтому CSS селектор будет таким: span.b-list__item-title.
Время и Дата — так же просто как и заголовок, получаем селекторы div.b-list__item-time и div.b-list__item-date соответственно.
Количество комментариев и Количество просмотров — находятся в элементах span с классом b-statistic__number, то так как в текущем блоке по такому селектору будут найдены оба элемента, то мы можем либо использовать срезы для выбора определенного элемента, либо использовать родительский элемент как часть селектора. В первом случае родительский элемент — это тег span с классом m-comments, и наш селектор получается таким span.m-comments > span.b-statistic__number. Во втором случае, родительский тег span с классом m-views формирует CSS селектор: span.m-views > span.b-statistic__number.
Вот мы и определили все селекторы для выбора полей которые нам надо собрать. Также давайте ограничим количество забираемых новостей, сделаем так чтобы парсер забирал 200 первых новостей (или 10 страниц). Мы можем организовать это с помощью счетчика, будем считать количество загруженных страниц и если счетчик примет значение более 9, просто не будем добавлять новый линк в пул. Займемся теперь написанием конфигурации парсера:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Устанавливаем счетчик страниц равным 1
- counter_set:
name: pages
value: 1
# Добавляем начальный URL в пул
- link_add:
url:
- https://ria.ru/lenta/
# Начинаем итерацию по пулу с последовательной загрузкой страниц из пула
- walk:
to: links
do:
# Делаем паузу 2 секунды для уменьшения нагрузки на сервер источника
- sleep: 2
# Находим кнопку подгрузки
- find:
path: div.b-pager > a
do:
# Считываем в регистр значение счетчика pages
- counter_get: pages
# проверяем если значение регистра больше 9
- if:
type: int
gt: 9
else:
# если значение меньше 9 - парсим значение аттрибута data-ajax текущего элемента в регистр
- parse:
attr: data-ajax
# делаем нормализацию значения в регистре, убираем лишние пробелы, унифицируем пробельные символы в ASCII пробелы
- space_dedupe
# удаляем все ведущие и завершающие пробелы значения в регистре, если они есть
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и добавляем линк в пул
- normalize:
routine: url
- link_add
# Находим все блоки с новостями и начинаем итерировать по найденным элементам
- find:
path: div.b-list__item
do:
# создаем новый объект данных с именем item
- object_new: item
# находим элемент с URL к странице с новостью
- find:
path: a:haschild(span.b-list__item-title)
do:
# парсим значение атрибута href в регистр
- parse:
attr: href
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле url объекта item
- normalize:
routine: url
- object_field_set:
object: item
field: url
# находим элемент с заголовком новости
- find:
path: span.b-list__item-title
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле headline объекта item
- object_field_set:
object: item
field: headline
# находим элемент с изображением
- find:
path: img[itemprop="associatedMedia"]
do:
# парсим значение атрибута src текущего элемента в регистр
- parse:
attr: src
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
- normalize:
routine: url
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле image объекта item
- object_field_set:
object: item
field: image
# находим элемент с временем
- find:
path: div.b-list__item-time
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле time объекта item
- object_field_set:
object: item
field: time
# находим элемент с датой
- find:
path: div.b-list__item-date
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле date объекта item
- object_field_set:
object: item
field: date
# находим элемент с количеством комментариев
- find:
path: span.m-comments > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле comments объекта item
- object_field_set:
object: item
field: comments
# находим элемент с количеством просмотров
- find:
path: span.m-views > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле views объекта item
- object_field_set:
object: item
field: views
# сохраняем объект данных item в базу данных
- object_save:
name: item
# увеличиваем значение счетчика pages на 1
- counter_increment:
name: pages
by: 1Вам осталось создать новый диггер на платформе Diggernaut, перенести в него этот сценарий и запустить. Надеемся что этот материал был полезен и помог вам в изучении нашего мета-языка.
Удачного парсинга!
Всем привет! В данном уроке мы займемся разработкой парсера каталога товаров.
Код будем писать на языке программирования Python в среде разработки Python IDLE. В рамках данной статьи не рассматривается установка и настройка последних. Для получения подробной информации вы можете посетить официальный сайт Python.
Собирать данные о товарах будем со специального сервиса на нашем сайте – тестового каталога, где к каждому полю подписан CSS-селектор, по которому можно найти элемент на странице – это нам пригодится в процессе парсинга. Сохранять результат будем в файл формата JSON.
Библиотеки, используемые в данной статье:
1. requests – официальную страница.
2. beautifulsoup4 – ссылка на документацию.
3. json – является частью стандартной библиотеки python.
По любым возникающим в ходе урока вопросам оставляйте комментарии ниже.
Ссылка на полный текст исходного кода находится в конце статьи.
Шаг 1. Подготовка
Предварительно проанализируем наш каталог товаров: видим 10 страниц, 117 товаров. Каждая карточка содержит поля: название, цена, артикул, таблица характеристик, изображение и описание. Выберем для парсинга название, цену и характеристики.
Алгоритм на поверхности:
1. Пройтись по страницам с 1 по 10 и собрать ссылки на страницы с товарами.
2. Зайти на страницу каждого из товаров и спарсить интересующие нас данные.
3. Сохранить полученные данные в файл формата JSON.
Шаг 2. Установка зависимостей
Использовать мы будем две сторонние библиотеки:
1. requests – для загрузки HTML-кода страниц по URL.
2. beautifulsoup4 – для парсинга данных с HTML, поиска элементов на странице.
Установим зависимости командами:
pip install requests
pip install beautifulsoup4Также мы будем использовать стандартную библиотеку json для записи результата в файл JSON формата.
Шаг 3. Программирование
Приступим к написанию кода – создадим основной скрипт main.py.
Объявим функцию crawl_products, которая будет принимать на вход количество страниц с карточками товаров, а на выходе возвращать список ссылок на товары с этих страниц.
Объявим вторую функцию parse_products, которая принимает список URL-адресов, парсит необходимую информацию по каждому товару и добавляет её в общий массив data, который и возвращает
Нам известно, что всего 10 страниц с карточками товаров, объявим глобальную переменную PAGES_COUNT – количество страниц.
# -*- coding: utf-8 -*-
PAGES_COUNT = 10
def crawl_products(pages_count):
urls = []
return urls
def parse_products(urls):
data = []
return data
def main():
urls = crawl_products(PAGES_COUNT)
data = parse_products(urls)
if __name__ == '__main__':
main()
Для парсинга страницы нам необходимо получить HTML-код страницы с помощью библиотеки requests и создать объект BeautifulSoup на основе этого кода.
Создадим метод get_soup, который принимает на вход URL-адрес страницы и возвращает объект BeautifulSoup, который мы будем использовать для поиска элементов на странице по CSS-селекторам. Если не удалось загрузить страницу по переданному URL, метод возвращает None.
def get_soup(url, **kwargs):
response = requests.get(url, **kwargs)
if response.status_code == 200:
soup = BeautifulSoup(response.text, features='html.parser')
else:
soup = None
return soup
Приступим к реализации функции crawl_products. Смотрим, как формируется URL-адрес конкретной страницы, на примере страницы с номером 2:
https://parsemachine.com/sandbox/catalog/?page=2Видим GET-параметр page=2, который является номером страницы. Объявим переменную fmt, которая будет шаблоном URL-адреса страницы с товарами. Пройдемся по страницам с 1 по pages_count.
Cформируем URL-адрес страницы с номером page_n и получим для него объект BeautifulSoup, используя метод get_soup. Если soup страницы является None, то произошла ошибка при получении HTML-кода страницы, поэтому мы прерываем обработку с помощью оператора break.
Если soup получен, то нас интересует элемент «Название товара», который является ссылкой на товар. Копируем CSS-селектор .product-card .title и передаем его аргументов в метод soup.select(), который вернет множество найденных на странице элементов. Для каждого из них мы получим атрибут href, а затем сформируем URL и добавим его в общий массив. Ниже приведен полный текст данной функции.
def crawl_products(pages_count):
urls = []
fmt = 'https://parsemachine.com/sandbox/catalog/?page={page}'
for page_n in range(1, 1 + pages_count):
print('page: {}'.format(page_n))
page_url = fmt.format(page=page_n)
soup = get_soup(page_url)
if soup is None:
break
for tag in soup.select('.product-card .title'):
href = tag.attrs['href']
url = 'https://parsemachine.com{}'.format(href)
urls.append(url)
return urls
Переходим к реализации parse_products. Пройдемся по каждому товару и получим soup аналогично предыдущей функции.
Первое поле, которое мы парсим – «Название товара». Вызываем метод select_one у объекта soup, который аналогичен методу select за исключением, что возвращает один элемент, найденный на странице. В качестве аргумента передаем CSS-селектор #product_name. Получаем видимый текст и очищаем от пробельных символов с обеих сторон.
Аналогично получаем поле «Цена» по CSS-селектору #product_amount.
Переходим к парсингу характеристик товара. Найдем строки по CSS-селектору #characteristics tbody tr и для каждой из них получим значения ячеек, которые сохраним в переменную techs. Данные по товару мы спарсили, теперь сохраним их в переменую item и добавим в массив data. Ниже представлен полный код функции.
def parse_products(urls):
data = []
for url in urls:
print('product: {}'.format(url))
soup = get_soup(url)
if soup is None:
break
name = soup.select_one('#product_name').text.strip()
amount = soup.select_one('#product_amount').text.strip()
techs = {}
for row in soup.select('#characteristics tbody tr'):
cols = row.select('td')
cols = [c.text.strip() for c in cols]
techs[cols[0]] = cols[1]
item = {
'name': name,
'amount': amount,
'techs': techs,
}
data.append(item)
return data
Осталось добавить запись в файл и парсер будет готов!
Импортируем библиотеку json для записи данных в JSON-файл. Объявляем глобальную переменную OUT_FILENAME – имя файла для записи результата.
Переходим к сохранению. Вызовем метод json.dump() с передачей аргументов:
1. Сохраняемый объект – у нас это data.
2. Файл.
Также передадим ensure_ascii=False, чтобы символы кириллицы не экранировались при записи в файл. И зададим отступ в 1 символ indent=1.
Итог
Все, сохранение в файл готово, и разработка парсера завершена!
import json
...
OUT_FILENAME = 'out.json'
...
def main():
urls = crawl_products(PAGES_COUNT)
data = parse_products(urls)
with open(OUT_FILENAME, 'w') as f:
json.dump(data, f, ensure_ascii=False, indent=1)
Ссылка на полный текст исходного кода – catalog.py
Если у вас возникли какие-то вопросы, можете задать их в комментариях к этой статье или под видео на YouTube. Предлагайте темы следующих уроков.
Спасибо за внимание!
Продолжаем наш небольшой курс по парсингу на Python. В предыдущем уроке, мы с вами ознакомились с тем как устроен парсер на python, и спарсили заголовок сайта wordpress.org. В этом уроке мы продолжим парсить тот же сайт, но теперь перейдем к более сложным операциям. Сегодня мы с вами разберемся с тем, как парсить, и сохранять данные в csv файл.
Содержание:
- Постановка задачи для парсинга
- Анализ html разметки страницы
- Создание парсера на Python
- Запись данных в csv
- Домашнее задание
- Заключение
Постановка задачи для парсинга
И так открываем сайт wordpress.org, и переходим в раздел «Плагины». В этом разделе мы видим четыре блока, в которых отображаются различные плагины.




Наша задача на этом уроке заключается в том, что бы получить:
- Название каждого плагина
- Ссылку на плагин
- Количество отзывов
- Сохранить полученные данные в csv файл
Для начала работы, нам необходимо подготовить свое рабочее окружение,для этого:
- Открываем свой Pycharm (Или редактор, который вы используете)
- Создаем новый проект
- Импортируем библиотеки, как и в предыдущем уроке
- Дополнительно импортируем библиотеку csv (import csv)
Отлично, с постановкой задачи мы почти разобрались, ниже у нас код, который является каркасом парсера. Быстро пробежимся по коду, и закрепим наши знания, полученные в прошлом уроке.
import requests
from bs4 import BeautifulSoup
LINK = 'https://wordpress.org'
def get_html(link):
response = requests.get(link)
return response.text
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
def main():
pass
if __name__=="__main__":
main()
- Функция get_html() — принимает адрес сайта, и возвращает свойство text объекта response
- Функция get_data() — принимает html код. Создаем экземпляр класса BS. Как и в первом уроке, мы передали два параметра (html, и lxml)
- Функция main() — пока пустая функция, если не знакомы с оператором pass, советую почитать про данный оператор
- Точка входа
Анализ html разметки страницы
Следующим шагом, нам необходимо провести анализ html разметки страницы. Переходим на сайт wordpress.org, и открываем инспектор кода в браузере (наводим мышью на нужную область, и кликаем правой кнопкой мыши, в появившемся меню, выбираем «Исследовать элемент«)
Как мы видим, у нас 4 блока с плагинами, и каждый блок заключен в тег section. Продолжим исследование html разметки страницы. Нам необходимо найти теги, внутри которых находятся необходимы нам данные.
- Ссылка на плагин
- Текст ссылки на плагин
- Количество отзывов
Отлично! Мы с вами проанализировали html код страницы, и выяснили в каких тегах хранятся наши данные. Ниже я описал структуру html страницы.

У нас есть структура html разметки, мы наглядно видим до каких тегов нам необходимо добраться, что бы получить нужные нам данные. Следующим шагом, мы напишем парсер, который будет собирать необходимые нам данные.
Ниже представлен листинг кода, который возвращает нам все найденные теги section.
import requests
from bs4 import BeautifulSoup
LINK = 'https://wordpress.org/plugins/'
def get_html(link):
response = requests.get(link)
return response.text
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
articles = soup.find_all('article')
return articles
def main():
link = LINK
print(get_data(get_html(link)))
if __name__=="__main__":
main()
Как видите в данном коде, появилось небольшое дополнение.
- В функции get_data() мы создали переменную articles
- Обратились к soup с помощью find_all, что бы найти все теги article, которые есть на странице
- Для того, что бы убедиться в том, что мы идем в правильном направлении, мы можем воспользоваться методом len()
- return len(article), в случае если все правильно, то функция вернет нам 16, так как у нас всего 16 плагинов на странице
- Если у вас возникает ошибка, опишите проблему в комментариях
Отлично, по сути наш парсер почти готов. Теперь, наша задача состоит в том, что бы в цикле получить нужные нам данные.
import requests
from bs4 import BeautifulSoup
def get_html(url):
r = requests.get(url)
return r.text
def refinde(str):
s = str.split(' ')[0]
return s.replace(',','')
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
articles = soup.find_all('article')
for article in articles:
h3 = article.find('h3', class_='entry-title').text
link = article.find('h3', class_='entry-title').find('a').get('href')
rating = article.find('div', class_="plugin-rating").find('span', class_="rating-count").find('a').text
print (h3,link,refinde(rating))
def main():
url ='https://wordpress.org/plugins'
print(get_data(get_html(url)))
if __name__ == '__main__':
main()
Как видите, с каждым разом к нашему коду добавляется новый функционал. Как вы понимаете основная операция происходит у нас в функции get_data(), и так же у нас появилась новая функция refinde().
- В функции get_data(), мы нашли все теги article, с помощью метода find_all. Данный метод возвращает нам все найденные элементы в виде списка.
- Запускаем цикл for, и перебираем полученный список.
- Сначала ищем теги h3, и забираем текст заключенный между ними. Это и есть заголовок нашего плагина
- Затем ищем ссылку на заголовок
- Далее ищем количество отзывов
Теперь немного поговорим про нашу новую функцию refinde(). Как видите данная функция применяется непосредственно к переменной rating. Все дело в том, что при парсинге «количества отзывов», у нас по мимо самого количества, парсится еще и остальная ненужная информация в виде текста и запятых между цифрами. Проще говоря, результат который мы получаем без функции, следующий:
- 1,985 total ratings (без функции refinde)
- 1985 с функцией refinde()
Сама функция работает достаточно просто.
- Функция принимает один аргумент в виде строки
- Для строки используем метод split(), который по пробелу разбивает строку, и возвращает нам ее в виде списка, из этого списка, мы забираем первый элемент.
- Первым элементом является число (количество скачиваний), но она содержит запятую, а так как мы хотим сохранить наши данные в csv, то лучше нам от нее избавиться
- Используем метод replace(), и заменяем запятую на пустой символ
И так друзья, подведем итоги этой главы. У нас с вами получилось спарсить все нужные данные, если вы все сделали правильно, то у вас должен получится следующий результат.
В случае если у вас возникают трудности в понимании материала, или у вас другие проблемы, пишите в комментариях, буду рад вам помочь.
Запись в csv
Вот мы и подошли в плотную к завершении этого большого урока. Мы получили все данные, которые нас интересовали, но нам теперь их надо как то сохранить. И так, для таких моментов Python предоставляет нам встроенный модуль csv, которым мы и воспользуемся.
import requests
from bs4 import BeautifulSoup
import csv
def get_html(url):
r = requests.get(url)
return r.text
def refinde(str):
s = str.split(' ')[0]
return s.replace(',','')
def write_csv(data):
with open('listplugins3.csv', 'a') as f:
recorder = csv.writer(f)
recorder.writerow((data['h3'],
data['link'],
data['rating']))
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
articles = soup.find_all('article')
for article in articles:
h3 = article.find('h3', class_='entry-title').text
link = article.find('h3', class_='entry-title').find('a').get('href')
rating = article.find('div', class_="plugin-rating").find('span', class_="rating-count").find('a').text
rating = refinde(rating)
data ={'h3':h3,
'link':link,
'rating':rating}
write_csv(data)
def main():
url ='https://wordpress.org/plugins'
print(get_data(get_html(url)))
if __name__ == '__main__':
main()
Как видите наш код код изменился, у нас появилась новая функция записи в csv. Поехали разбираться.
- Внутри функции get_data() мы создали словарь, куда внесли все полученные ранее нами значения
- Создали функцию write_csv()
- Функция работает довольно просто, создаем/открываем файл для записи
- Будьте внимательны с флагами, которые вы указываете. К примеру ‘w‘, всегда будет перезаписывать существующий файл, а флаг ‘a‘, это как append в списках, добавлять новые данные в конец файла
- Далее используем writerow() и передаем туда кортеж с нашими данными
- И в самом конце, в функции get_data() мы вызываем нашу новую функцию write_csv() и передаем туда наш словарь
После запуска нашего скрипта, у нас появится файл listplugins3.csv. Открыть данный файл можно как в Excel, так и в другом стороннем редакторе. Конечный результат сбора данных, вы можете увидеть ниже.

Домашнее задание
Друзья, в целом вы уже должны понимать, как работает парсер. Конечно, существует огромное количество разновидностей сайтов, и к каждому сайту должен быть свой подход. Но, на данном этапе, вы уже можете парсить, поэтому, в качестве домашнего задания, рекомендую вам спарсить данные со страницы с темами wordpress.org/themes.

Получите и сохраните, ссылку на тему оформления, и его название. Трудностей у вас возникнуть не должно, если все же они будут, добро пожаловать в комментарии.
Заключение
В этом уроке, я постарался насколько это возможно подробно объяснить как все устроено. В следующих уроках, такие подробности будут опущены. Сегодня нам удалось спарсить название/ссылку/рейтинг 16 плагинов. Конечно, это можно было бы сделать и в ручную, и не пришлось бы копаться в коде, и изучать что то. Но представьте себе, что у вас не 16 плагинов, а 10 000.Для таких случаев и создаются парсеры. Достаточно понять, как устроена структура страницы, и вы одним махом сможете собрать все данные подходящие под ваш шаблон.
На следующих уроках, мы будем рассматривать и другие виды сайтов, и в целом как правильно писать парсеры, что бы они не падали во время работы, будем использовать try…except конструкции, и прочие. Запомните, чем больше парсеров вы напишите, тем быстрее у вас появится опыт, и понимание того, как все устроено изнутри.