4.1. Сферы применения тестов и особенности интерпретации
тестовых результатов
Результаты тестирования
нуждаются в такой интерпретации, которая
соответствует цели тестирования (см.
табл. 4.1).
Таблица
4.1 — Сферы применения тестов, цель
тестирования и интерпретация его
результатов
|
Сфера применения тестов |
Цель |
Интерпретация результатов |
|
Профессиональный |
Отбор |
Ранжирование |
|
Вступительное |
Отбор |
Ранжирование |
|
Определение |
Определение |
Ранжирование |
|
Текущий |
Отслеживание |
Анализ |
|
Дистанционное обучение |
Стимулирование |
Ранжирование |
|
Самостоятельное |
Стимулирование |
Результаты |
Как следует из табл. 4.1, тест
надо рассматривать как единство: 1)
метода; 2) результатов, полученных
определённым методом; и 3) интерпретированных
результатов, полученных определённым
методом.
Интерпретация результатов
тестирования ведется преимущественно
с опорой на среднее арифметическое,
показатели вариации тестовых баллов и
на так называемые процентные нормы,
показывающие, сколько процентов
испытуемых имеют тестовый результат
худший, чем у интересующего испытуемого.
При вступительном тестировании,
профессиональном отборе или определении
рейтинга в группе основная задача при
интерпретации результатов заключается
в ранжировании испытуемых по уровню
подготовленности. При мониторинге или
текущем контроле более важной задачей
является анализ структуры и профиля
знаний. При самостоятельной работе
(дистанционное обучение, обучение с
помощью мультимедийных учебников и
т.п.) основное назначение тестов —
стимулировать познавательную деятельность
обучаемых, дать им возможность оценить
собственные успехи, выявить пробелы в
полученных знаниях.
Независимо от сферы применения
теста, результаты тестирования должны
подвергаться статистической обработке
с целью определения основных характеристик
заданий теста, проверки надежности
измерений и валидности тестовых
результатов.
Далее рассматриваются
особенности анализа тестовых результатов
и их интерпретации при вступительном
тестировании, текущем контроле
(мониторинге), самостоятельном и
дистанционном обучении.
Вступительное тестирование.
Первичная обработка результатов,
полученных при вступительном тестировании,
сводится к составлению таблицы (матрицы)
тестовых результатов по правилам,
описанным ранее (см. табл. 3.4). Это позволяет
не только наглядно оценить уровень и
структуру подготовленности испытуемых,
но и выделить наиболее «сильных» в
группе, проходившей тестирование.
Как отмечалось в главе 3,
распределение результатов тестирования
по хорошо составленным тестам в идеале
должно быть близким к нормальному закону
(в достаточно больших группах – не менее
20 чел.). На рис. 4.1 в качестве примера
показано распределение баллов, набранных
при вступительном тестировании в группе
из 80 человек. Задача состояла в отборе
из этой группы 50, наиболее подготовленных
человек. Тест содержал 24 задания, за
каждый правильный ответ выставлялся 1
балл. По сумме набранных баллов приемной
комиссией были выделены первые 50 человек,
набравшие наибольшее количество баллов
и определен проходной балл (в данном
примере — 11 баллов).
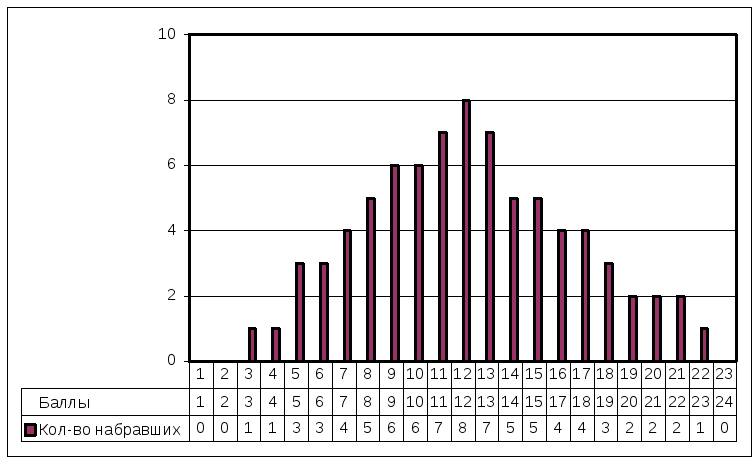
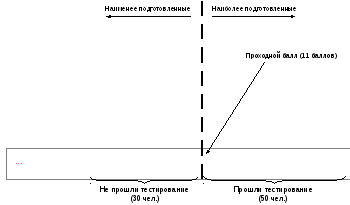
Рис.
4.1 — Определение проходного балла при
вступительном тестировании (пример).
Максимально
возможное количество баллов в данном
примере – 24.
Пример, показанный на рис.
4.1, является в некотором смысле «идеальным».
Так, если бы в этом же примере нужно было
отобрать не 50, а 52 человека (или например
47 человек), с установлением проходного
балла возникли бы определенные трудности
– при меньшем его значении (10 баллов)
прошедших тестирование было бы больше,
чем необходимо и наоборот. В этой ситуации
может быть предложен такой выход:
приемная комиссия устанавливает более
высокий проходной балл, при котором
число прошедших тест меньше необходимого.
Недостающее количество людей комиссия
добирает из числа тех, которые немного
«не дотянули» до проходного балла. При
этом предпочтение отдается тем, которые
в наибольшей степени соответствуют
требованиям (например, имеют стаж работы
по выбранной специальности, льготы при
поступлении, более высокий средний балл
по документам о базовом образовании и
т.п.). Этим же людям за дополнительную
плату может быть предложено пройти
подготовительные курсы и т.п.
При вступительном тестировании,
помимо определения проходного балла,
достаточно важен анализ структуры и
профиля знаний (будет рассмотрен далее).
Текущий контроль
(мониторинг). Тесты
для текущего контроля и мониторинга
создаются по тем же принципам, что и
тесты иного назначения. Но основной
целью тестирования в данном случае
является отслеживание хода образовательного
процесса, выявление пробелов в структуре
знаний, искажений профиля знаний у
каждого из испытуемых и выяснение
возможных причин их появления.
Под структурой
знаний в
общем случае следует понимать такую
степень полноты знаний и умений учащегося,
которая равномерно охватывает все
разделы дисциплины (или нескольких
дисциплин) и позволяет испытуемым
успешно выполнять задания теста вне
зависимости от того, к какому разделу
дисциплины они относятся.
Если испытуемый выполняет
задания (в том числе, достаточно трудные),
относящиеся к одному разделу дисциплины
и не может выполнить задания по другому
разделу (в т.ч. невысокой трудности), то
это говорит о нарушении (пробелах) в
структуре знаний. Вполне очевидно, что
такие нарушения могут быть как
индивидуальными, так и наблюдаться у
достаточно большого числа испытуемых.
В последнем случае необходимо
проанализировать причины появления
пробелов (неудачное изложение раздела
или отдельной дисциплины, нехватка или
отсутствие методического обеспечения
и т.п.) и принять меры к их устранению.
Необходимым условием,
обеспечивающим получение достоверной
информации о структуре знаний, является
репрезентативность заданий теста по
отношению к объему знаний, который
проверяется с его помощью. Другими
словами – задания, включаемые в состав
теста, должны достаточно полно и
равномерно охватывать все разделы
дисциплины, курса и т.п. При этом
желательно, чтобы каждый раздел дисциплины
был представлен несколькими заданиями
различного уровня сложности.
Для удобства анализа
структуры знаний тестовые результаты
в матрице желательно располагать так,
как показано в примере (табл. 4.2). В этом
примере каждый раздел дисциплины
представлен в тесте пятью заданиями
различного уровня сложности. Результаты
испытуемого №2, выполнявшего задания
теста по варианту №7, показали практически
полное отсутствие знаний раздела 2
дисциплины, в то время как с заданиями
по разделу 1 он более-менее справился.
В таких случаях говорят о пробелах в
структуре знаний.
Термин профиль
знаний, которым
тестологи называют совокупность баллов
в каждой строке таблицы тестовых
результатов, можно проиллюстрировать
на примере, приведенном в табл. 4.3
(фрагмент матрицы из табл. 3.4).
Таблица
4.2 – Анализ структуры знаний по матрице
тестовых результатов
|
№ пп |
№№ вариантов |
Оценки |
|||||||||||
|
Раздел |
Раздел |
||||||||||||
|
№1 |
№6 |
№11 |
№17 |
№23 |
№2 |
№7 |
№12 |
№18 |
№24 |
№3 |
|||
|
1 |
4 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
|
|
2 |
7 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
|
Таблица
4.3 – Искаженный (строка №6) и неискаженные
(строки №5 и №7) профили знаний
|
№ пп |
№№ вариантов |
Оценки за тестовые |
Суммарный |
|||||||||
|
№1 |
№2 |
№3 |
№4 |
№5 |
№6 |
№7 |
№8 |
№9 |
№10 |
|||
|
5 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
5 |
|
6 |
3 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
5 |
|
7 |
7 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
4 |
Как видно из примера,
испытуемые, результаты которых находятся
в строках 5 и 6, набрали одинаковое
количество баллов по тесту, однако,
испытуемый №5 справился с первыми 5-ю,
наиболее легкими заданиями, не справившись
с остальными. Результаты же испытуемого
№6 несколько нелогичны – не справившись
с относительно легкими заданиями в
начале теста, он сумел выполнить более
трудные задания. В таких случаях говорят
об искаженном (инвертированном) профиле
знаний.
Причины искажений профиля
знаний могут быть самыми разными
–некачественно составленный тест,
индивидуальные психологические
особенности тестируемого, низкое
качество преподавания, отсутствие
методического обеспечения и литературы
и др. По мнению проф. В.С. Аванесова и
других специалистов-тестологов, задача
хорошего образования – порождать
правильные (неискаженные) профили
знаний.
Анализ структуры и профиля
знаний при вступительном тестировании
и текущем контроле (мониторинге) позволяет
педагогам получить общее представление
об уровне подготовленности испытуемых,
своевременно выявить пробелы в знаниях,
ошибки в методике преподавания и принять
соответствующие меры. В учебных
заведениях, внедряющих системы менеджмента
качества, постоянный мониторинг процесса
обучения с использованием тестовых
технологий должен быть одним из основных
инструментов постоянной корректировки
(улучшения) образовательного процесса.
Дистанционное обучение.
В существующих системах дистанционного
обучения (СДО «Прометей», «Web-класс ХПИ»,
Lotus Learning Space и др.), как правило, предусмотрен
текущий и итоговый контроль усвоения
учебного материала. Контроль может
осуществляться с помощью отдельной
программы для тестирования или же модули
(программы) для тестирования встраиваются
непосредственно в дистанционные
курсы.*15
В последнем случае дистанционный курс
может использоваться для самостоятельной
работы, без участия преподавателя.
Системы дистанционного
обучения или же собственно дистанционные
курсы, должны снабжаться такими
программами, которые «умеют» не только
сохранять тестовые результаты каждого
испытуемого, но и дают возможность
преподавателю (тьютору) или разработчику
курса с минимальными затратами времени
производить их статистическую обработку
с целью определения надежности
педагогического измерения и валидности
тестовых результатов. К сожалению,
далеко не все из используемых систем
дистанционного обучения предоставляют
такую возможность.
К тестам, разрабатываемым
для использования в дистанционном
обучении, предъявляются те же требования,
что и к тестам для текущего контроля
(мониторинга).
Самостоятельная работа.
Как отмечают специалисты, качественно
разработанные тесты имеют высокий
обучающий потенциал, позволяющий
существенно повысить мотивацию к
обучению и соответственно повысить его
эффективность. В последнее время в
учебном процессе все чаще используются
такие средства обучения как обучающие
курсы, мультимедийные учебники,
электронные тренажеры и т.п., которые
можно назвать обучающими электронными
изданиями (ОЭИ). Основным их достоинством
является возможность самостоятельного
обучения с минимальным вмешательством
преподавателя. ОЭИ обязательно должны
снабжаться тестами для текущего и
итогового контроля, и желательно такими,
которые позволили бы обучаемому не
только увидеть, что именно он не знает,
но и «объясняли», почему тот или иной
ответ является неправильным и
«рекомендовали» вернуться к соответствующему
разделу для повторного изучения.
Тесты для ОЭИ, также как и
тесты другого назначения, должны быть
репрезентативны по отношению к
совокупности проверяемых знаний и
навыков. Не менее важна и предварительная
апробация заданий, включаемых в эти
тесты, с целью определения их трудности
и других характеристик. Имея информацию
о трудности каждого задания, разработчик
ОЭИ может сделать так, чтобы при
тестировании программа «выдавала» их
испытуемому по принципу «от наиболее
легкого — к наиболее трудному». При этом
желательно иметь достаточно большое
количество параллельных заданий, чтобы
при повторном тестировании испытуемому
выдавались новые задания, которых он
не выполнял ранее.
В мультимедийных учебниках
и других ОЭИ, как правило, нет необходимости
сохранять результаты тестирования и,
тем более, производить их статистическую
обработку. Основная задача тестов,
используемых в ОЭИ — стимулирование
познавательной деятельности обучаемого
и корректировка его индивидуальной
«траектории обучения».
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Система тестирования собирает и хранит различную информацию о самом тестировании и результатах участников. В ней доступны как итоговые результаты участников, так и их детальные ответы на каждое из заданий, а также сводная информация по тестовым заданиям, позволяющая оценить их качество. Рассмотрим как работать с результатами тестирования.
Сеансы тестирования
Результаты участников тестирования собираются в соответствии с анкетой персональных данных, которая была создана в системе. На основе данных, вводимых участниками тестирования, можно идентифицировать их результаты и использовать для анализа.
После получения ссылки на тест (например, http://app.startexam.com/Center/Web/kosmos) и выбора теста, участник тестирования вводит свои персональные данные в анкету и нажимает кнопку Далее.

После этого участник тестирования начинает знакомиться с вопросами и проходить тест.
Одновременно с этим инициатору тестирования уже доступна информация об участниках принимающих участие в тестировании, но без наличия результатов, т.к. тест ими еще не завершен. Администратор тестирования может посмотреть начатые сеансы тестирования, кликнув по ссылке Сеансы в центрах тестирования.

Перед Вами откроется окно с запущенными сеансами тестирования.

На этой странице доступна информация обо всех участниках, принимающих участие в тестировании. По каждому сеансу доступны следующие данные:
- Центр – название центра тестирования, под которым запущен тест
- Тест – название теста, которые решает участник
- Имя участника — фамилия, имя и отчество участника тестирования
- Дата начала сеанса тестирования
- Состояние сеанса тестирования (завершен/не завершен)
- и результаты тестирования
Как видно на изображении результаты еще недоступны, т.к. сеансы не завершены и информация по ответам участников не получена. По мере завершения сеансов их состояние будет меняться, но уже сейчас можно ознакомиться с персональными данными участников, кликнув на состояние сеанса.

Будет открыта страница с подробной информацией о сеансе участника тестирования и его персональных данных.

По мере выполнения теста участниками состояние сеансов будет меняться.

Как только участники тестирования завершат тестирование, состояние всех сеансов примет статус Завершен и результаты будут доступны в системе.
Результаты тестирования
Теперь рассмотрим более подробно какие результаты собираются и какие средства для работы с ними имеются в системе тестирования. На странице с сеансами тестирования доступна следующая информация:
- Время, которое было затрачено на тестирование
- Макс — максимальный балл, который можно было набрать по тесту
- Балл – набранный участником балл
- (%) – результат участника в процентах
- Уровень, показанный участником в соответствии с созданной шкалой оценки
- Отзывы, оставленные участниками на задания, если такая опция была включена в тесте

Сеансы тестирования могут быть отфильтрованы в соответствии с Вашими предпочтениями. В системе можно вывести результаты за определенный период времени:
- последний час
- сегодня
- вчера
- на этой неделе
- на прошлой неделе
- в этом месяце
- в прошлом месяце
- в этом году
- в прошлом году
- за все время
Кроме того, можно показать нужное количество результатов на одной странице: 10, 50, 100 или все сразу.

Ненужные результаты могут быть удалены – для этого есть соответствующая кнопка Удалить, для удаления нужно предварительно отметить нужные результаты чекбоксами.

Результаты тестирования могут быть экспортированы в различные форматы:
- формат электронных таблиц Excel
- формат языка разметки XML
- результаты, упакованные в zip-архив

Результаты экспортируются в соответствии с выбранными Вами фильтрами. Если Вы выберите результаты только за неделю, то и экспортированы будут результаты, полученные на неделе. Кроме того, Вы можете отметить нужные Вам результаты для экспорта чекбоксами и только эти результаты будут представлены в выдаче.

При экспорте в Excel в таблицу будут добавлены не только результаты, но и персональная информация, указанная участником тестирования.
Результаты тестирования по определенному тесту
В системе тестирования можно посмотреть результаты тестирования как по всем тестам сразу, так и по каждому тесту в отдельности. Просмотр результатов по тестам имеет дополнительные возможности для работы с результатами.
Для просмотра результатов по определенному тесту, Вам необходимо перейти в проект и открыть вкладку Тесты.

Здесь будут доступны все тесты проекта. Возле каждого теста имеется ссылка Сеансы, нажав на которую можно посмотреть сеансы тестирования именно по этому тесту. Набор функций в целом аналогичен результатам в центрах тестирования, но имеются некоторые полезные дополнения.
Матрица ответов
Первое отличие – здесь доступен еще один вид отчетов – Матрица ответов. В матрице ответов представлены все задания теста и ответы участников по каждому заданию.

С помощью этого вида отчета Вы можете экспортировать результаты в таблицу Excel и посмотреть на какие задания участники отвечали правильно, а где давали неправильные ответы.

По вертикальной оси представлены задания, которые входили в тест, по горизонтальной – имена участников, на пересечении представлены ответы участников. Единица означает, что участник дал правильный ответ на задание, ноль – ошибся. Если значения не будет, значит задание не попалось в окончательный набор заданий участника тестирования.
Детальные ответы участников тестирования
В сеансах тестирования по определенному тесту доступна статистика по ответам каждого участника. Для ее просмотра кликаем по состоянию сеанса тестирования.

Открывается страница с персональными данными, которые можно было посмотреть и в центрах тестирования, но здесь присутствует еще одна вкладка – Ответы.

На странице отображаются результаты ответов участника на каждое задание теста, аналогичные тем, что были представлены в матрице ответов.
Здесь можно посмотреть ответ, который дал участник тестирования на определенное задание. Например, нам хочется узнать какой вариант ответа выбрал участник на вопрос, в котором допустил ошибку. Кликаем по тесту вопроса и получаем результат.

Представлено задание теста и ошибочный вариант ответа, данный участником. Неправильно решенное задание отображается на красном фоне.
Аналогичным образом можно посмотреть задание, в котором участник ответил верно.

Оно отображается на зеленом фоне.
Статистика тестовых заданий
При детальном просмотре результатов участников тестирования доступна также статистика по каждому тестовому заданию. Кликнув по вкладке Статистика можно посмотреть информацию о задании и оценить его качество.

Здесь доступна информация о задании:
- дата создания тестового задания
- автор задания
- статус
- тип
- метод оценки
А также доступна статистика по нему:
- Кол-во результатов – количество решений задания участниками тестирования
- Выполнено – количество завершенных результатов (на задание был дан ответ)
- Пропущено – количество неоконченных результатов (на задание не был дан ответ)
- Средний балл – отношение количества правильных ответов на задание к общему количеству завершенных результатов
- Правильных ответов – процент правильных ответов на задание
Статистика тестового задания позволяет сделать вывод о его качестве. Хорошие задания должны попадать в интервал правильных ответов от 20% до 80%. Подробнее вопросы качества тестовых заданий рассмотрены на уроке Мастерство создания тестов.
Мы рассмотрели основные возможности использования результатов тестирования в системе OpenTest, которая включает в себя весь спектр процессов тестирования от создания задания до проведения тестирования и анализа результатов.
Узнайте больше о системе тестирования
Результаты тестирования могут быть представлены в различном виде, в зависимости от направления исследования. Так, тесты на психологию личности и акцентуации характера могут иметь как вид процентного соотношения, так и полноценную словесную характеристику. Исходя из полученного результата, тест позволяет определить соотношение изучаемых личностных и психологических качеств в человеке, а также отношение результатов к вариантам нормы, что в определенных случаях, позволяет выбрать направление корректирующей работы над личностными качествами.
63. Проективная техника
Проективная техника — это группа методик, предназначенных для диагностики личности, для которых характерен в большей мере глобальный подход к оценке личности, а не выявление отдельных ее черт. Наиболее существенным признаком проективных методик является использование в них неопределенных стимулов, которые испытуемый должен сам дополнять, интерпретировать, развивать и т. д.
Так, испытуемым предлагается интерпретировать содержание сюжетных картинок, завершать незаконченные предложения, давать Толкование неопределенных очертаний и т. п. В этой группе методик ответы на задания также не могут быть правильными или неправильными; возможен широкий диапазон разнообразных решений. При этом предполагается, что характер ответов обследуемого определяется особенностями его личности, которые «проецируются» в его ответах. Цель проективных методик относительно замаскирована, что уменьшает возможность испытуемого давать желательные ответы, чтобы произвести впечатление.
Эти методики носят в основном индивидуальный характер, и в большей своей части это предметные или бланковые методики.
Принято различать следующие группы проективных методик:
— методики структурирования: формирование стимулов, придание им смысла;
— методики конструирования: создание из деталей осмысленного целого;
— методики интерпретации: истолкование какого-либо события, ситуации;
— методики дополнения: завершение предложения, рассказа, истории;
— методики катарсиса: осуществление игровой деятельности в особо организованных условиях;
— методики изучения экспрессии: рисование на свободную или заданную тему;
— методики изучения импрессии: предпочтение одних стимулов (как наиболее желательных) другим.
64. Тесты на выявление личностных диспозиций
Диспозиция личности — это фиксированная в ее социальном опыте предрасположенность воспринимать и оценивать условия деятельности, собственную активность и действия других, а также предуготовлен-ность действовать в определенных условиях определенным образом. Этим понятием объединяют разнообразные по треб ностно-мотив ацио иные структуры субъекта, которые так или иначе регулируют его социальное поведение.
Можно предположить, что личностные диспозиции образуют иерархически организованную систему39, вершину которой составляет общая направленность интересов и система ценностных ориентации, средние уровни — система обобщенных социальных установок («ат-титюдов») на многообразные социальные объекты и ситуации, а нижний — поведенческие готовности к действию в максимально конкретизированных социальных ситуациях (т. е. поведенческие установки).
39 Такое предположение, основанное на работах Д. Н. Узнадзе, В. Н. Мясищева, В. Г. Ананьева, А. Н. Леонтьева, И. Макгайра, М. Роки-ча, М. Абельсова, Ч. Осгуда и многих других в области изучения социальных установок (аттитюдов), последовательно проверялось нами в длительном и многоплановом изучении взаимосвязи социальных и социально-психологических факторов, регулирующих поведение личности. Излагаемый здесь подход опирается на выводы из этого исследования [306, 235].
Диспозиции высшего уровня — продукт воздействия социально-культурных условий и реализуемых в этих условиях высших социальных потребностей личности (обобщенная потребность включения в общности), диспозиции средних уровней — результат «столкновения» потребностей освоения определенных видов и форм деятельности и соответствующих социальных условий, в которых эти потребности реализуются, диспозиции нижнего уровня иерархии фиксируются как готовность к оценке ситуации и действию на основе предшествующего опыта, реализации потребностей включения в группы и организации, адаптации в данной предметной среде, т. е. в «микросоциальных» условиях деятельности.
Экспериментально показано (А. А. Горбатков), что в диспозиционной системе имеет место позитивно-негативная асимметрия: на стадии адаптации к новым условиям ведущую роль в регуляции поведения принимают на себя диспозиции, связанные со стремлением не уклоняться от принятой субъектом социальной нормы, в дальнейшем же лидируют позитивные диспозиции как готовность к реализации интервализованных (усвоенных) субъектом ценностей и социальных установок. Осознанные диспозиции преимущественно доминируют в регуляции социального поведения в таких ситуациях, которые требуют активного напряжения усилий субъекта. В привычной же ситуации на первый план выдвигаются полуосознаваемые или неосознаваемые диспозции (В. С. Магун).
Итак, регистрируя в социологическом и социально-психологическом исследовании диспозиции личности, мы тем самым получаем информацию о возможной направленности поведения людей в определенных условиях. Однако крайне важно иметь в виду, что разные диспозиционные образования обладают различной «прогностической силой» в отношении возможного поведения.
Система ценностных ориентации (именно система, их целостность, а не отдельные ориентации) указывает на направленность интересов личности в восприятии наиболее важных (в субъективном смысле) сторон жизни и отношения к общим условиям деятельности, нравственные принципы человека. Знание о ценностной системе — неплохой показатель для прогноза общей направленности поведения как целеустремленного или Же сравнительно нецелеустремленного, как относительно конформного и неконформного (т. е. как относительно самостоятельного и относительно несамостоятельного).
Методики для выявления системы ценностных ориентации многообразны. Одна из них, предложенная М. Рокичем и адаптированная к нашим условиям40, состоит в том, что обследуемым предлагается последовательно ранжировать 18 наименований терминальных ценностей — целей жизни и 18 наименований инструментальных ценностей, т. е. ориентации на основные средства достижения жизненных целей.
40 Адаптация выполнена А. Гоштаутасом, А. А. Семеновым, В.А.Ядовым [235. С. 208—209].

Список терминальных ценностей включает следующие: активная, деятельная жизнь; жизненная мудрость (зрелость суждений и здравый смысл, достигаемые жизненным опытом); здоровье (физическое и психическое здоровье); интересная работа; красота природы и искусства (переживание прекрасного в природе и искусстве); любовь (духовная и физическая близость с любимым человеком); материально обеспеченная жизнь (отсутствие материальных затруднений); наличие хороших и верных друзей; общая хорошая обстановка в стране, в нашем обществе, сохранение мира между народами (как условие благополучия каждого); общественное признание (уважение окружающих, коллектива, товарищей по работе); познание (возможность расширения своего образования, кругозора, общей культуры, интеллектуальное развитие); равенство (равные возможности для всех); самостоятельность как независимость в суждениях и оценках; свобода как независимость в поступках и действиях; счастливая семейная жизнь; творчество (возможность творческой деятельности): уверенность в себе (свобода от внутренних противоречий, сомнений); удовольствия (жизнь, полная удовольствий, развлечений, приятного проведения времени).
Список инструментальных ценностей: аккуратность (чистоплотность, умение содержать в порядке свои вещи, порядок в делах); воспитанность (хорошие манеры, вежливость); высокие запросы (высокие притязания); жизнерадостность (чувство юмора); исполнительность (дисциплинированность); независимость (способность действовать самостоятельно, решительно); непримиримость к недостаткам в себе и в других; образованность (широта знаний, высокая общая культура); ответственность (чувство долга, умение держать слово); рационализм (умение здраво и логично мыслить, принимать обдуманные, рациональные решения); самоконтроль (сдержанность, самодисциплина); смелость в отстаивании своего мнения, своих взглядов; твердая воля (умение настоять на своем, не отступать перед трудностями); терпимость (к взглядам и мнениям других, умение прощать другим их ошибки и заблуждения); широта взглядов (умение понять чужую точку зрения, уважать иные вкусы, обычаи, привычки); честность (правдивость, искренность); эффективность в делах (трудолюбие, продуктивность в работе); чуткость (заботливость).
Наименования ценностей предлагаются в виде отдельных карточек для ранжирования от наиболее значимой до наименее значимой, и в итоге мы получаем ранговые порядки всей структуры.
Устойчивость процедуры при повторном опросе через две недели для списка терминальных ценностей составляет 82,3%, инструментальных — 78,7%. При укрупнении рангов ценностей из 18-членной шкалы в 6-членную устойчивость повышается соответственно до 88,3% и 86,3%. Укрупнение производится с учетом различной устойчивости первых, последних и «срединных» рангов (наименее устойчивых) таким образом:
Исходные ранги
1
2
3,4
5—8
9—16
17,18
Укрупненные ранги
1
2
3
4
5
6
Итоговые показатели по этой процедуре: (а) средние ранги ценностей, (б) типологические структуры (их можно получить многомерным анализом, включая факторный, таксономию, распознавание образов — см. с. 218—220; 206—208) и (в) выделение в системе ранжированных ценностей тех из них, которые представляют особый интерес для данного исследования (например, можно выделить ценности, относящиеся к политической жизни). Средние ранги таких «ценностных синдромов» указывают на соотносительную значимость данной сферы деятельности или данных способов деятельности в ряду других. Понятно, что эти операции можно производить не только в индивидуальном разрезе (в психологических и социально-психологических исследованиях), но и в групповых разработках, т. е. по разным социально-профессиональным, социально-демографическим и иным подвыборкам обследуемых.
Имеются и другие приемы выявления системы ценностей: путем глубокого интервью, предложением развернутых «портретов» неких воображаемых лиц, в каждом из которых описываются интересы и наклонности неких условных персонажей (надо выбрать наиболее «симпатичный» и отвергнуть «несимпатичный» образ) [192], путем ранжирования более краткого спиа са ценностей или предложений, имеющих ценностно-мотивационную окраску [171, 67].
Методики для регистрации обобщенных социальных установок предназначены для предсказания характерных черт реального поведения личности в тех условиях, к которым эти установки относятся. К числу таких методик относятся — описанный выше «кафетерий» из многих установочных суждений (см. с. 170), шкалограмма (с. 168—173), техника Тёрстоуна (с. 175—180) и различные проективные техники (например, описанная на с. 30—305 этой книги). Последние, однако, обладают удовлетворительной прогностической «силой» при оценке общих характеристик поведения в определенной сфере деятельности, но плохо согласуются с фактическими поступками в четко очерченных, конкретных условиях.
Для прогноза конкретных поступков следует прибегнуть к фиксированию ситуативных социальных установок. В нашем собственном опыте лучше всего такие предсказания реализовались при использовании простой техники, называемой «предсказание по реакции на одно суждение».
В международном исследовании Всемирной организации здравоохранения следовало добиться уверенного предсказания, обратится ли данный человек к врачу, если ему адресуют приглашение из поликлиники для профилактического обследования. Мы применили разные варианты методик: ценностно-ориентационные (где, конечно, фигурировало здоровье как ценность жизни), методики на обобщенные социальные установки к своему здоровью, к современной медицине и более конкретно — к возможностям системы медицинского обслуживания в данной местности и т.п. Но наибольшую прогностическую силу обнаружил простейший прямой вопрос: «Как бы Вы отнеслись к предложению обследоваться у врача?» — с тремя вариантами *ответов: безусловно позитивным, позитивным «при определенных условиях» и безусловно негативным. Спустя несколько недель респонденту посылалось официальное Приглашение из клиники. И в Каунасе, где проводилось обследование, и в Роттердаме (Нидерланды) положительный ответ на указанный вопрос дал наибольшую корреляцию с фактическим приходом опрошенных в клинику [369. С. 25—44].
К числу методик диспозиционного плана относятся и специальные тесты на систему основных интересов личности (каждый из частных интересов, например, в области знания, искусства, досуга и др., сопровождается индикаторами конкретных занятий или конкретных увлечений) [213. С. 305—309], интересов в рамках свободного времени и досуга, а также общей направленности поведения на досуге [235. С. 201—208], тесты на отношение к различным элементам производственной ситуации, о которых уже говорилось, ценностно-ориента-ционные методики, предназначенные для определения направленности интересов в сфере образования, в трудовой деятельности [248. С. 113—124], тесты на изучение преступных наклонностей [143] и установок в области политики.
Широкое использование такого рода методик социологами подтверждает их практическую полезность в теоретике-прикладных исследованиях.
65. Эксперимент как метод исследования
Эксперимент — специфический метод, основанный на контролируемом взаимодействии исследователя с исследуемым объектом в заранее заданных условиях. В эксперименте можно получить информацию в искусственно созданной обстановке, что отличает этот метод от обычного наблюдения.
Социологический эксперимент в корне отличается от естественно-научного. Особенностью последнего является то, что объектом выступает материальный мир, исследуемый с помощью определенного прибора или инструмента, т.е. экспериментатор, говоря словами Г. Гегеля, «действует против природы с помощью самой природы», тогда как социологический эксперимент — это совместная деятельность испытуемых и социолога, направленная на исследование какой-либо особенности личности, группы.
Данный метод применяется при проверке гипотез относительно причинных связей между социальными явлениями. При этом сравниваются два сложных явления, различающиеся тем, что в первом присутствует некоторая гипотетическая причина, а во втором она отсутствует. Если под воздействием экспериментатора в первом наблюдается изменение, а во втором — нет, то гипотеза считается доказанной. Экспериментальное исследование в социологии отличается от методов других наук тем, что экспериментатор активно манипулирует независимой переменной. Если в применении неэкспериментальных методов, как правило, все группы для исследователя равноценны, то в эксперименте обычно участвуютосновная иконтрольная группы испытуемых.
Вследствие разного уровня разработанности той или иной научной проблемы и недостатка информации о связи зависимой и независимой переменных выделяют два основных типа экспериментов:
- исследовательский, который проводится в том случае, когда неясна причинная связь между зависимой и независимой переменными и эксперимент направлен на проверку гипотезы о наличии причинной связи между двумя явлениями;
- подтверждающий, который проводится, если связь выяснена заранее и выдвигается гипотеза о содержании связи. Тогда в эксперименте эта связь раскрывается и уточняется.
Так, при выяснении причин социальной напряженности в определенном городе выдвигаются такие возможные гипотезы: низкие доходы населения, социальная поляризация, непрофессионализм администрации, коррупция, негативное воздействие СМИ и т.д. Каждая из них требует проверки, хотя и представляется вполне обоснованной.
Экспериментатор обязан располагать необходимой информацией по изучаемой проблеме. После формулировки проблемы определяются ключевые понятия, содержащиеся в специальной научной литературе и социологических словарях. При работе с литературой не только уточняется проблема, но и вырисовывается план исследования, возникают новые гипотезы. Далее определяются переменные в терминах экспериментальной процедуры; в первую очередь выделяются внешние переменные, которые могут существенно повлиять на зависимую переменную.
Отбор испытуемых должен отвечать требованию репрезентативности, т.е. производиться с учетом характеристики генеральной совокупности, иначе говоря, состав экспериментальной группы должен моделировать эту совокупность, поскольку выводы, получаемые в результате экспериментов, распространяются на население в целом.
Кроме того, испытуемые должны быть распределены по экспериментальной и контрольной подгруппам так, чтобы они были эквивалентными.
Исследователь экспериментально воздействует на первую группу, а в контрольной группе воздействие отсутствует. В результате полученное различие можно отнести к независимой переменной.
Предположим, исследователь выдвинул гипотезу, что в данном городе воздействие СМИ приводит к росту социальной напряженности. Но что является причиной, а что следствием? Возможно, социальная напряженность сама влияет на характер передач телевидения и публикаций «тревожащих» статей в местной печати. В данном случае социолог может провести эксперимент с целью выяснить эту причинно-следственную связь.
Так, для экспериментальной группы можно контролировать (уменьшать или увеличивать) число передач с избыточной «негативной» информацией, менять факторы воздействия с тем, чтобы узнать, как эти факторы раздельно или в совокупности влияют на людей, т.е. исследователь манипулирует одной или двумя независимыми переменными, стараясь сохранить все остальные неизменными (рис. 1.3).
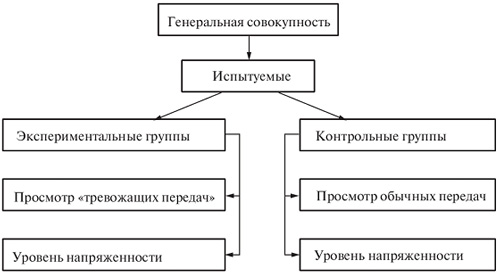
Рис. 1.3. Воздействие СМИ на рост социальной напряженности
В качествеобъектов социологических экспериментов выступают различные социальные группы — потребителей и производителей, управляющих и управляемых, верующих и атеистов, студентов и преподавателей, производственные и научные коллективы и т.д., и любые характеристики этих групп носят в основном психологический характер. Поэтому эксперименты такого рода зачастую являются социально-психологическими. Заметим, что основное различие чисто психологическою и социологического экспериментов состоит в акценте исследовательских программ и методов, а также в целях, поставленных перед исследователем. Так, при социологическом эксперименте изучаются конкретные проявления поведения людей, где психологические факторы играют значительную роль. В. Биркенбил описывает невербальный (бессловесный) конфликтный эксперимент, участниками которого были всего двое (малая группа).
Этот эксперимент был проведен за столом ресторана, за которым напротив друг друга сидели два приятеля. Один из них — психиатр — повел себя несколько необычно: взял пачку сигарет, закурил и, продолжая говорить, положил пачку рядом с тарелкой собеседника. Тот чувствовал себя несколько неуютно, хотя и не мог понять причины. Чувство дискомфорта усилилось, когда психиатр, пододвинув свою тарелку к пачке сигарет, перегнулся через стол и стал что-то с жаром доказывать. Наконец он сжалился над собеседником и сказал:
— Я только что продемонстрировал с помощью так называемого языка тела основные черты неязыковой коммуникации.
— Пораженный друг спросил:
— Какие основные черты?
— Я агрессивно тебе угрожал и через это воздействовал на тебя. Я привел тебя в состояние, в котором ты мог быть побежден, и это тебя беспокоило.
— Но как? Что ты делал?
— Сначала я передвинул в твою сторону свою пачку сигарет, — объяснил он. — По неписаному закону стол делится пополам: одна половина стола моя, а другая твоя.
— Но я ведь не устанавливал никаких разграничений.
— Конечно, нет. Но, несмотря на это, такое правило существует. Каждый из нас мысленно «маркирует» свою часть, и обычно мы «делим» стол согласно этому правилу. Однако я, поместив свою пачку сигарет на другую половину, нарушил эту неписаную договоренность. Хотя ты и не осознавал того, что происходит, но почувствовал дискомфорт… Потом последовало следующее вторжение: я подвинул к тебе свою тарелку. Наконец, вслед за ней последовало мое тело, когда я навис над твоей стороной… Ты чувствовал себя всс более и более скверно, вот только не понимал, почему собственно.
Если вы будете проводить такой эксперимент, то убедитесь, что сначала ваш собеседник, еще бессознательно, будет отодвигать обратно предметы, которые вы расположите в его зоне.
Вы снова сдвигаете их к нему, а он упорно отодвигает их назад. Это может продолжаться до тех пор, пока ваш собеседник не осознает, что происходит. Тогда он вступит «на тропу войны», например агрессивно заявив: «Прекрати это!», или подчеркнуто резко швырнет эти предметы на вашу сторону.
Более рисковыми являются попытки изучения причин и динамики конфликта с применением насилия. Исследователь может использовать стимулирующие или подавляющие меры (независимые переменные), например, если воздействовать на группу испытуемых, то можно обнаружить усиление или ослабление агрессии, фиксируя различные ее проявления (крики, угрозы и т.д.).
М.Б. Харрис с коллегами в 1970-х гг. провели остроумный эксперимент, когда испытуемые, оказавшиеся в магазинах, супермаркетах, ресторанах, аэропортах и проч., подвергались прямому и сильному подстрекательству к агрессии. С этой целью применялось несколько различных процедур. Например, водном из вариантов помощники и помощницы экспериментатора намеренно толкали людей сзади. Реакция испытуемых на этот неожиданный поступок классифицировалась по категориям: вежливая, безразличная, несколько агрессивная (например, краткий протест либо взгляд) и очень агрессивная (долгие сердитые выговоры или ответный толчок). В нескольких других опытах ассистенты экспериментатора вставали перед человеком, стоящим в очереди (в магазине, ресторане, банке). В одних случаях ассистенты говорили «извините», а в других не говорили вообще ничего. Вербальные реакции классифицировались как вежливые, безразличные, несколько агрессивные (краткие замечания типа «здесь я стою») и очень агрессивные (угрозы или брань). Невербальные реакции классифицировались как дружелюбные (улыбка), безразличные взгляды, враждебные или угрожающие жесты, толчки и выпихивание. Эти процедуры применялись для изучения фрустрации и агрессии.
Таким образом, подсоциологическим экспериментом следует понимать метод сбора и анализа данных, позволяющий осуществить проверку гипотез о наличии или отсутствии причинных связей между социальными явлениями. Для этого исследователь активно вмешивается в естественный ход событий: создает в изучаемой группе искусственные условия и планомерно контролирует их. Полученная в ходе эксперимента информация об изменении показателей изучаемого объекта способствует уточнению, опровержению или подтверждению исходной гипотезы исследования. Экспериментальный метод позволяет получать достоверные результаты, которые можно успешно применять в практической деятельности, например для повышения эффективности функционирования социальных групп, организаций, институтов. Однако в процессе применения экспериментального метода важно учитывать не только достоверность данных, но и моральные и правовые нормы, а также интересы и стремления людей, участвующих в исследовании.
66.Метод контент-анализа
· Контент-анализ (от англ. contens содержание) — метод качественно-количественного анализа содержания документов с целью выявления или измерения различных фактов и тенденций, отраженных в этих документах. Особенность контент-анализа состоит в том, что он изучает документы в их социальном контексте. Может использоваться как основной метод исследования (например, контент-анализ текста при исследовании политической направленности газеты), параллельный, т.е. в сочетании с другими методами (напр., в исследовании эффективности функционирования средств массовой информации), вспомогательный или контрольный (напр., при классификации ответов на открытые вопросы анкет).
· Не все документы могут стать объектом контент-анализа. Необходимо, чтобы исследуемое содержание позволило задать однозначное правило для надежного фиксирования нужных характеристик (принцип формализации), а также, чтобы интересующие исследователя элементы содержания встречались с достаточной частотой (принцип статистической значимости). Чаще всего в качестве объектов исследования контент-анализа выступают сообщения печати, радио, телевидения, протоколы собраний, письма, приказы, распоряжения и т.д., а также данные свободных интервью и открытые вопросы анкет. Основные направления применения контент-анализа: выявление того, что существовало до текста и что тем или иным образом получило в нем отражение (текст как индикатор определенных сторон изучаемого объекта — окружающей действительности, автора или адресата); определение того, что существует только в тексте как таковом (различные характеристики формы — язык, структура, жанр сообщения, ритм и тон речи); выявление того, что будет существовать после текста, т.е. после его восприятия адресатом (оценка различных эффектов воздействия).
В разработке и практическом применении контент-анализа выделяют несколько стадий. После того, как сформулированы тема, задачи и гипотезы исследования, определяются категории анализа — наиболее общие, ключевые понятия, соответствующие исследовательским задачам. Система категорий играет роль вопросов в анкете и указывает, какие ответы должны быть найдены в тексте. В практике отечественного контент-анализа сложилась довольно устойчивая система категорий — знак, цели, ценности, тема, герой, автор, жанр и др. Все более широко распространяется контент-анализ сообщений средств массовой информации, основанный на парадигматическом подходе, в соответствии с которым изучаемые признаки текстов (содержание проблемы, причины ее возникновения, проблемообразующий субъект, степень напряженности проблемы, пути ее решения и др.) рассматриваются как определенным образом организованная структура.
· Категории контент-анализа должны быть исчерпывающими (охватывать все части содержания, определяемые задачами данного исследования), взаимоисключающими (одни и те же части не должны принадлежать различным категориям), надежными (между кодировщиками не должно быть разногласий по поводу того, какие части содержания следует относить к той или иной категории) и уместными (соответствовать поставленной задаче и исследуемому содержанию). При выборе категорий для контент-анализа следует избегать крайностей: выбора слишком многочисленных и дробных категорий, почти повторяющих текст, и выбора слишком крупных категорий, т.к. это может привести к упрощенному, поверхностному анализу. Иногда необходимо принимать во внимание и отсутствующие элементы текста, которые могут быть значимыми для контент-анализа.
· После того, как категории сформулированы, необходимо выбрать соответствующую единицу анализа — лингвистическую единицу речи или элемент содержания, служащие в тексте индикатором интересующих исследователя явления. В практике отечественных контент-аналитических исследований наиболее, употребительными единицами анализа являются слово, простое предложение, суждение, тема, автор, герой, социальная ситуация, сообщение в целом и др. Сложные виды контент-анализа обычно оперируют не одной, а несколькими единицами анализа. Единицы анализа, взятые изолировано, могут быть не всегда правильно истолкованы, поэтому они рассматриваются на фоне более широких лингвистических или содержательных структур, указывающих на характер членения текста, в пределах которого идентифицируется присутствие или отсутствие единиц анализа — контекстуальных единиц. Например, для единицы анализа «слово» контекстуальная единица — «предложение». Наконец, необходимо установить единицу счета — количественную меру взаимосвязи текстовых и внетекстовых явлений. Наиболее употребительны такие единицы счета, как время-пространство (число строк, площадь в квадратных сантиметрах, минуты, время вещания и т.п.), появление признаков в тексте, частота их появления (интенсивность).
Важен выбор необходимых источников, подвергаемых контент-анализу. Проблема выборки содержит в себе выбор источника, количества сообщений, даты сообщения и исследуемого содержания. Все эти параметры выборки определяются задачами и масштабами исследования. Чаше всего контент-анализ проводится на годичной выборке: если это изучение протоколов собраний, то достаточно 12 протоколов (по числу месяцев), если изучение сообщений средств массовой информации — 12—16 номеров газеты или теле-, радиодней. Обычно выборка сообщений средств массовой информации составляет 200—600 текстов.
· Необходимым условием является разработка таблицы контент-анализа — основного рабочего документа, с помощью которого проводится исследование. Тип таблицы определяется этапом исследования. Например разрабатывая категориальный аппарат, аналитик составляет таблицу, представляющую собой систему скоординированных и субординированных категорий анализа. Такая таблица внешне напоминает анкету: каждая категория (вопрос) предполагает ряд признаков (ответов), по которым квантифицируется содержание текста. Для регистрации единиц анализа составляется другая таблица — кодировальная матрица. Если объем выборки достаточно велик (свыше 100 единиц), то кодировщик, как правило, работает с тетрадью таких матричных листов. Если выборка невелика (до 100 единиц), то можно проводить двумерный или многомерный анализ. В этом случае для каждого текста должна быть своя кодировальная матрица. Эта работа трудоемка и кропотлива, поэтому при больших объемах выборки сопоставление интересующих исследователя признаков осуществляется на компьютере.
· Важным условием контент-анализа является разработка инструкции кодировщику — системы правил и пояснений для того, кто будет собирать эмпирическую информацию, кодируя (регистрируя) заданные единицы анализа. В инструкции точно и однозначно излагается алгоритм действий кодировщика, дается операциональное определение категорий и единиц анализа, правила их кодирования, приводятся конкретные примеры из текстов, являющихся объектом исследования, оговаривается, как следует поступать в спорных случаях, и т.д. Процедура подсчета при количественном контент-анализе в общем виде аналогична стандартным приемам классификации по выделенным группировкам ранжирования и измерения ассоциации. Существуют также специальные процедуры подсчета применительно к контент-анализу, напр., формула коэффициента Яниса, предназначенного для вычисления соотношения положительных и отрицательных (относительно избранной позиции) оценок, суждений, аргументов. В случае, когда число положительных оценок превышает число отрицательных,
· 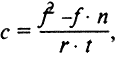
· где f — число положительных оценок; n — число отрицательных оценок; r — объем содержания текста, имеющего прямое отношение к изучаемой проблеме; t — общий объем анализируемого текста. В случае, когда число положительных оценок меньше, чем отрицательных,
· 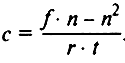
· Есть и более простые способы измерения. Удельный вес той или иной категории можно вычислить с помощью формулы К = число единиц анализа, фиксирующих данную категорию/общее число единиц анализа.
67. Типы единиц контент-анализа
4.1. Сферы применения тестов и особенности интерпретации
тестовых результатов
Результаты тестирования
нуждаются в такой интерпретации, которая
соответствует цели тестирования (см.
табл. 4.1).
Таблица
4.1 — Сферы применения тестов, цель
тестирования и интерпретация его
результатов
|
Сфера применения тестов |
Цель |
Интерпретация результатов |
|
Профессиональный |
Отбор |
Ранжирование |
|
Вступительное |
Отбор |
Ранжирование |
|
Определение |
Определение |
Ранжирование |
|
Текущий |
Отслеживание |
Анализ |
|
Дистанционное обучение |
Стимулирование |
Ранжирование |
|
Самостоятельное |
Стимулирование |
Результаты |
Как следует из табл. 4.1, тест
надо рассматривать как единство: 1)
метода; 2) результатов, полученных
определённым методом; и 3) интерпретированных
результатов, полученных определённым
методом.
Интерпретация результатов
тестирования ведется преимущественно
с опорой на среднее арифметическое,
показатели вариации тестовых баллов и
на так называемые процентные нормы,
показывающие, сколько процентов
испытуемых имеют тестовый результат
худший, чем у интересующего испытуемого.
При вступительном тестировании,
профессиональном отборе или определении
рейтинга в группе основная задача при
интерпретации результатов заключается
в ранжировании испытуемых по уровню
подготовленности. При мониторинге или
текущем контроле более важной задачей
является анализ структуры и профиля
знаний. При самостоятельной работе
(дистанционное обучение, обучение с
помощью мультимедийных учебников и
т.п.) основное назначение тестов —
стимулировать познавательную деятельность
обучаемых, дать им возможность оценить
собственные успехи, выявить пробелы в
полученных знаниях.
Независимо от сферы применения
теста, результаты тестирования должны
подвергаться статистической обработке
с целью определения основных характеристик
заданий теста, проверки надежности
измерений и валидности тестовых
результатов.
Далее рассматриваются
особенности анализа тестовых результатов
и их интерпретации при вступительном
тестировании, текущем контроле
(мониторинге), самостоятельном и
дистанционном обучении.
Вступительное тестирование.
Первичная обработка результатов,
полученных при вступительном тестировании,
сводится к составлению таблицы (матрицы)
тестовых результатов по правилам,
описанным ранее (см. табл. 3.4). Это позволяет
не только наглядно оценить уровень и
структуру подготовленности испытуемых,
но и выделить наиболее «сильных» в
группе, проходившей тестирование.
Как отмечалось в главе 3,
распределение результатов тестирования
по хорошо составленным тестам в идеале
должно быть близким к нормальному закону
(в достаточно больших группах – не менее
20 чел.). На рис. 4.1 в качестве примера
показано распределение баллов, набранных
при вступительном тестировании в группе
из 80 человек. Задача состояла в отборе
из этой группы 50, наиболее подготовленных
человек. Тест содержал 24 задания, за
каждый правильный ответ выставлялся 1
балл. По сумме набранных баллов приемной
комиссией были выделены первые 50 человек,
набравшие наибольшее количество баллов
и определен проходной балл (в данном
примере — 11 баллов).
Рис.
4.1 — Определение проходного балла при
вступительном тестировании (пример).
Максимально
возможное количество баллов в данном
примере – 24.
Пример, показанный на рис.
4.1, является в некотором смысле «идеальным».
Так, если бы в этом же примере нужно было
отобрать не 50, а 52 человека (или например
47 человек), с установлением проходного
балла возникли бы определенные трудности
– при меньшем его значении (10 баллов)
прошедших тестирование было бы больше,
чем необходимо и наоборот. В этой ситуации
может быть предложен такой выход:
приемная комиссия устанавливает более
высокий проходной балл, при котором
число прошедших тест меньше необходимого.
Недостающее количество людей комиссия
добирает из числа тех, которые немного
«не дотянули» до проходного балла. При
этом предпочтение отдается тем, которые
в наибольшей степени соответствуют
требованиям (например, имеют стаж работы
по выбранной специальности, льготы при
поступлении, более высокий средний балл
по документам о базовом образовании и
т.п.). Этим же людям за дополнительную
плату может быть предложено пройти
подготовительные курсы и т.п.
При вступительном тестировании,
помимо определения проходного балла,
достаточно важен анализ структуры и
профиля знаний (будет рассмотрен далее).
Текущий контроль
(мониторинг). Тесты
для текущего контроля и мониторинга
создаются по тем же принципам, что и
тесты иного назначения. Но основной
целью тестирования в данном случае
является отслеживание хода образовательного
процесса, выявление пробелов в структуре
знаний, искажений профиля знаний у
каждого из испытуемых и выяснение
возможных причин их появления.
Под структурой
знаний в
общем случае следует понимать такую
степень полноты знаний и умений учащегося,
которая равномерно охватывает все
разделы дисциплины (или нескольких
дисциплин) и позволяет испытуемым
успешно выполнять задания теста вне
зависимости от того, к какому разделу
дисциплины они относятся.
Если испытуемый выполняет
задания (в том числе, достаточно трудные),
относящиеся к одному разделу дисциплины
и не может выполнить задания по другому
разделу (в т.ч. невысокой трудности), то
это говорит о нарушении (пробелах) в
структуре знаний. Вполне очевидно, что
такие нарушения могут быть как
индивидуальными, так и наблюдаться у
достаточно большого числа испытуемых.
В последнем случае необходимо
проанализировать причины появления
пробелов (неудачное изложение раздела
или отдельной дисциплины, нехватка или
отсутствие методического обеспечения
и т.п.) и принять меры к их устранению.
Необходимым условием,
обеспечивающим получение достоверной
информации о структуре знаний, является
репрезентативность заданий теста по
отношению к объему знаний, который
проверяется с его помощью. Другими
словами – задания, включаемые в состав
теста, должны достаточно полно и
равномерно охватывать все разделы
дисциплины, курса и т.п. При этом
желательно, чтобы каждый раздел дисциплины
был представлен несколькими заданиями
различного уровня сложности.
Для удобства анализа
структуры знаний тестовые результаты
в матрице желательно располагать так,
как показано в примере (табл. 4.2). В этом
примере каждый раздел дисциплины
представлен в тесте пятью заданиями
различного уровня сложности. Результаты
испытуемого №2, выполнявшего задания
теста по варианту №7, показали практически
полное отсутствие знаний раздела 2
дисциплины, в то время как с заданиями
по разделу 1 он более-менее справился.
В таких случаях говорят о пробелах в
структуре знаний.
Термин профиль
знаний, которым
тестологи называют совокупность баллов
в каждой строке таблицы тестовых
результатов, можно проиллюстрировать
на примере, приведенном в табл. 4.3
(фрагмент матрицы из табл. 3.4).
Таблица
4.2 – Анализ структуры знаний по матрице
тестовых результатов
|
№ пп |
№№ вариантов |
Оценки |
|||||||||||
|
Раздел |
Раздел |
||||||||||||
|
№1 |
№6 |
№11 |
№17 |
№23 |
№2 |
№7 |
№12 |
№18 |
№24 |
№3 |
|||
|
1 |
4 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|||||
|
2 |
7 |
1 |
1 |
1 |
1 |
1 |
|||||||
Таблица
4.3 – Искаженный (строка №6) и неискаженные
(строки №5 и №7) профили знаний
|
№ пп |
№№ вариантов |
Оценки за тестовые |
Суммарный |
|||||||||
|
№1 |
№2 |
№3 |
№4 |
№5 |
№6 |
№7 |
№8 |
№9 |
№10 |
|||
|
5 |
1 |
1 |
1 |
1 |
1 |
1 |
5 |
|||||
|
6 |
3 |
1 |
1 |
1 |
1 |
1 |
5 |
|||||
|
7 |
7 |
1 |
1 |
1 |
1 |
4 |
||||||
Как видно из примера,
испытуемые, результаты которых находятся
в строках 5 и 6, набрали одинаковое
количество баллов по тесту, однако,
испытуемый №5 справился с первыми 5-ю,
наиболее легкими заданиями, не справившись
с остальными. Результаты же испытуемого
№6 несколько нелогичны – не справившись
с относительно легкими заданиями в
начале теста, он сумел выполнить более
трудные задания. В таких случаях говорят
об искаженном (инвертированном) профиле
знаний.
Причины искажений профиля
знаний могут быть самыми разными
–некачественно составленный тест,
индивидуальные психологические
особенности тестируемого, низкое
качество преподавания, отсутствие
методического обеспечения и литературы
и др. По мнению проф. В.С. Аванесова и
других специалистов-тестологов, задача
хорошего образования – порождать
правильные (неискаженные) профили
знаний.
Анализ структуры и профиля
знаний при вступительном тестировании
и текущем контроле (мониторинге) позволяет
педагогам получить общее представление
об уровне подготовленности испытуемых,
своевременно выявить пробелы в знаниях,
ошибки в методике преподавания и принять
соответствующие меры. В учебных
заведениях, внедряющих системы менеджмента
качества, постоянный мониторинг процесса
обучения с использованием тестовых
технологий должен быть одним из основных
инструментов постоянной корректировки
(улучшения) образовательного процесса.
Дистанционное обучение.
В существующих системах дистанционного
обучения (СДО «Прометей», «Web-класс ХПИ»,
Lotus Learning Space и др.), как правило, предусмотрен
текущий и итоговый контроль усвоения
учебного материала. Контроль может
осуществляться с помощью отдельной
программы для тестирования или же модули
(программы) для тестирования встраиваются
непосредственно в дистанционные
курсы.*15
В последнем случае дистанционный курс
может использоваться для самостоятельной
работы, без участия преподавателя.
Системы дистанционного
обучения или же собственно дистанционные
курсы, должны снабжаться такими
программами, которые «умеют» не только
сохранять тестовые результаты каждого
испытуемого, но и дают возможность
преподавателю (тьютору) или разработчику
курса с минимальными затратами времени
производить их статистическую обработку
с целью определения надежности
педагогического измерения и валидности
тестовых результатов. К сожалению,
далеко не все из используемых систем
дистанционного обучения предоставляют
такую возможность.
К тестам, разрабатываемым
для использования в дистанционном
обучении, предъявляются те же требования,
что и к тестам для текущего контроля
(мониторинга).
Самостоятельная работа.
Как отмечают специалисты, качественно
разработанные тесты имеют высокий
обучающий потенциал, позволяющий
существенно повысить мотивацию к
обучению и соответственно повысить его
эффективность. В последнее время в
учебном процессе все чаще используются
такие средства обучения как обучающие
курсы, мультимедийные учебники,
электронные тренажеры и т.п., которые
можно назвать обучающими электронными
изданиями (ОЭИ). Основным их достоинством
является возможность самостоятельного
обучения с минимальным вмешательством
преподавателя. ОЭИ обязательно должны
снабжаться тестами для текущего и
итогового контроля, и желательно такими,
которые позволили бы обучаемому не
только увидеть, что именно он не знает,
но и «объясняли», почему тот или иной
ответ является неправильным и
«рекомендовали» вернуться к соответствующему
разделу для повторного изучения.
Тесты для ОЭИ, также как и
тесты другого назначения, должны быть
репрезентативны по отношению к
совокупности проверяемых знаний и
навыков. Не менее важна и предварительная
апробация заданий, включаемых в эти
тесты, с целью определения их трудности
и других характеристик. Имея информацию
о трудности каждого задания, разработчик
ОЭИ может сделать так, чтобы при
тестировании программа «выдавала» их
испытуемому по принципу «от наиболее
легкого — к наиболее трудному». При этом
желательно иметь достаточно большое
количество параллельных заданий, чтобы
при повторном тестировании испытуемому
выдавались новые задания, которых он
не выполнял ранее.
В мультимедийных учебниках
и других ОЭИ, как правило, нет необходимости
сохранять результаты тестирования и,
тем более, производить их статистическую
обработку. Основная задача тестов,
используемых в ОЭИ — стимулирование
познавательной деятельности обучаемого
и корректировка его индивидуальной
«траектории обучения».
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Тест-анализ
⇒ Правильное написание:
тест-анализ
⇒ Гласные буквы в слове:
тест-анализ
гласные выделены красным
гласными являются: е, а, а, и
общее количество гласных: 4 (четыре)
• ударная гласная:
тест-ана́лиз
ударная гласная выделена знаком ударения « ́»
ударение падает на букву: а
• безударные гласные:
тест-анализ
безударные гласные выделены пунктирным подчеркиванием « »
безударными гласными являются: е, а, и
общее количество безударных гласных: 3 (три)
⇒ Согласные буквы в слове:
тест-анализ
согласные выделены зеленым
согласными являются: т, с, т, н, л, з
общее количество согласных: 6 (шесть)
• звонкие согласные:
тест-анализ
звонкие согласные выделены одинарным подчеркиванием « »
звонкими согласными являются: н, л, з
общее количество звонких согласных: 3 (три)
• глухие согласные:
тест-анализ
глухие согласные выделены двойным подчеркиванием « »
глухими согласными являются: т, с, т
общее количество глухих согласных: 3 (три)
⇒ Формы слова:
тест-ана́лиз, -а
⇒ Количество букв и слогов:
гласных букв: 4 (четыре)
согласных букв: 6 (шесть)
всего букв: 10 (десять)
всего слогов: 4 (четыре)
Анализ тестов — это выкидывание лишнего из вашего чек-листа. Работа из серии «сесть и подумать»:
-
какие проверки можно объединить?
-
какие и вовсе выкинуть?
Было бы здорово дать некий алгоритм, который поможет всегда и везде, но нет, увы. Универсальная фраза здесь только «сесть и ПОДУМАТЬ». А самое главное: «вместе с водой не выплеснуть ребенка». Убирайте тесты аккуратно, особенно в первые годы работы. Возможно, выкинутое было отнюдь не лишним…

Но общий принцип анализа примерно такой:
-
Объединить позитивные тесты.
-
Выкинуть одинаковые классы эквивалентности.
-
Не тестировать один функционал 10 раз: проверять его в одном месте, а в остальных лишь то, что он в принципе работает.
Рассмотрим каждый пункт по отдельности.
Содержание
-
1. Объединить позитивные тесты
-
1.1. Разные поля
-
1.2. Одно поле
-
1.3. Разные параметры
-
1.4. Итого по объединению
-
-
2. Выкинуть дубли
-
2.1. Фантазия разгулялась
-
2.2. Я это уже проверял
-
-
3. Не тестировать один функционал 10 раз
-
Где схлопывать тесты НЕ надо
-
Итого
1. Объединить позитивные тесты
За одну проверку можно многое успеть. И если мы хотим ужать количество тестов, то можно проверить несколько позитивных за один раз. Проще всего это сделать, когда надо проверить сразу несколько полей. Но мы рассмотрим разные варианты.
1.1. Разные поля
Возьмем для примера форму регистрации. Предположим, на ней три поля поля: имя, email, пароль.

Для каждого поля мы расписываем проверки, которые надо провести. Например:
|
Имя |
|
Пароль |
|
1. Мужское 2. Женское 3. Унисекс 4. Редкое 5. Распространенное 6. Длинное 7. Короткое 8. … |
1. Свой email 2. Email с точкой 3. Email с цифрами в имени аккаунта 4. Цифры в домене 5. Тире в имени аккаунта 6. Тире в домене 7. Email 10-минутный 8. … |
1. Простой 2. Сложный (защищенный) 3. Среднесложный 4. С пробелами 5. Русские и английские символы 6. Спецсимволы 7. Разный регистр 8. … |
Вот у нас есть по 7 проверок на каждое поле. Проверки можно проводить по-разному:
1. Сосредоточиться на одном параметре и варьировать именно его. Остальные оставлять неизменными (чтобы не напрягать мозг, как бы еще их проверить).
Например, регистрируем свой емейл и пароль «12345», так как точно уверены в их валидности. Меняем только имя. Потом фиксируем имя и пароль, меняем емейл. И, наконец, меняем только пароль.
Получается 7 + 7 + 7 = 21 тест
Хинт для регистрации
Чтобы регистрация прошла успешно на один и тот же емейл, используйте хинт gmail — берёте свою почту и добавляете к ней часть с плюсиком. См также статью «Регистрация по EMAIL».
Например, myMail@gmail.com — это моя почта, так вот
— myMail+1@gmail.com
— myMail+2@gmail.com
— myMail+10@gmail.com
— myMail+test@gmail.com
будет приходит на myMail@gmail.com.
2. Объединить проверки. Все равно всю форму заполнять, так будем заполнять ее по разному:
-
Мужское имя + свой email + простой пароль
-
Женское имя + email с точкой + сложный пароль
-
…
Итого получается 7 тестов вместо 21.

Важно не перестараться — если напихивать в один тест кучу всего, баг по нему локализовать будет сложно. Да и покрытие тестами оценить тоже не очень.
1.2. Одно поле
В рамках тестирования одного поля тоже можно совместить разные проверки. Например, длину поля + регистр + алфавит.
-
Длинное имя + CamelCase (Ольга → начинается с заглавной, потом нижний регистр) + русский алфавит
-
Короткое на английском в КАПСЛОКЕ
-
…
1.3. Разные параметры
Мне очень не хочется, чтобы вы думали, что объединять тесты можно только в больших формах ввода на N полей и больше это нигде работать не будет. Будет!
Мы можем объединять проверки на разные состояния объектов или разные параметры:
-
Файл: размер, количество строк, столбцов, формат.
-
Картинка (аватарка или фоточка в инстаграмм): расширение, размер, высота, ширина.
-
Покупка вещей в интернет-магазине: категория, цвет, размер, фасон… (Зеленое платье в пол 44 размера, желтое короткое 42, голубое миди 50-ого…)
-
SOAP-запрос: разные параметры идут как разные поля на форме ввода.
-
…
Например, в Дадате есть возможность загружать файлы в систему. На форме указаны ограничения: «Поддерживаются файлы Excel и CSV до 20 Мб».

Одним тестом мы можем проверить формат Excel и небольшой размер файла (несколько кб), другим — CSV и граничное значение 20 Мб. А потом поварьировать другие величины, скажем, проверить загрузку одной строки данных, а формат выбрать CSV с другим разделителем.
1.4. Итого по объединению
Объединение проверок — это здорово в условиях ограниченного времени. Они сильно помогают, когда на выполнение одного теста тратится много времени по тем или иным причинам (приходится подключаться к дохлой виртуалке, где все тормозит; проходить длинную процедуру регистрации на сайте итд).
Однако у них есть и минусы. Например, если что-то где-то пошло не так и программа сломалась, сложно сделать вывод: а где именно? Когда у нас всегда одинаковое имя и пароль, меняется только эл адрес, то все понятно: случился баг, проблема в емейле. А вот если мы в один тест запихали 10 разных проверок, придется потратить время на локализацию.
Плюсы
+ Меньше тестов, больше покрытия!
Минусы
— Сложно составить тесты
— Сложно красиво это описать
— Сложно держать в голове
— А если вдруг баг? Сложнее локализовывать
Это не значит, что теперь вообще нельзя объединять тесты, вовсе нет! Просто помните о минусах. И в каждом случае думайте, что принесет больше выгоды: объединить проверки или оставить как есть. Если «сложно красиво описать» кажется вам надуманной проблемой, то вам просто повезло не сталкиваться с последствиями)
При этом учтите, что объединять надо только позитив. Если объединить негативные проверки, нельзя четко ответить на вопрос, правда ли система умеет реагировать на каждую ошибку в отдельности. Может, она обрабатывает лишь одну из двух и вам просто повезло её увидеть. Объединяйте позитив, а негатив проверяйте отдельно, оставляя другие параметры «точно хорошими».
2. Выкинуть дубли
Тут может быть два варианта:
-
Пока писал проверки, фантазия разгуглялась, увлекся. Теперь убираем лишнее.
-
Смотрим на разные группы и видим, что «эй, я это уже проверял».
Но чтобы что-то выкидывать, надо сделать пример «откуда выкидывать»
Пример для выкидывания
На сайте Дадаты есть подсказки по ФИО:

Они же подключены во время регистрации:
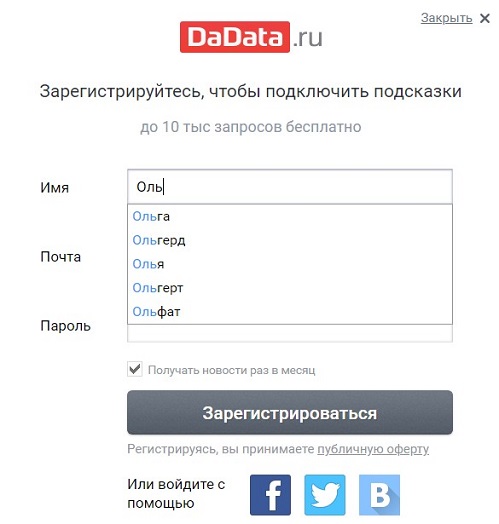
Вот как раз для поля «Имя» при регистрации мы и напишем чек-лист.
Что важно в подсказках? Они помогают вводить данные быстрее и без ошибок — в длинном имени опечататься очень легко, а уж пока запишешь адрес… Итак, важно проверить:
-
С какой буквы подсказки начинаются — толку от подсказки, которая вылезает после того, как я уже все ввела вручную?
-
Релевантность — подскажут ли они мне «Ольга» или начнут сначала предлагать «Ольгерд»? Тогда снова мне придется вводить имя самой, смысл подсказок теряется.
-
Возможность выбора — если у меня редкое имя, я хочу ввести его сама, игнорируя все подсказки. Очень плохо, когда на форму прикручивают логику «Не нашли в подсказках, не дали оформить заказ, высвечивая поле о неправильном ФИО или адресе».
Итак, начнем! Не знаю, какое ограничение на имя будет в дадате, когда вы будете читать эту статью. Поэтому предположим, что оно ограничено 15 символами. Пишем чек-лист:
ЧЛ 1.1. Чек-лист для поля «Имя» при регистрации
|
Проверка |
Пример |
Результат |
|
С какой буквы начинаются подсказки |
||
|
Имена на такую букву есть, распространенная |
О |
Подсказки выпадают с первой буквы. В первой пятерке есть: · Ольга · Олег · Оксана |
|
Имена на такую букву есть, редкая |
Ц |
Подсказки есть, но на фамилии (имен распространенных нет). В первой пятерке есть: · Царев · Цветкова |
|
Имен на такую букву нет |
Ъ |
Подсказок нет |
|
Подсказки или свое |
||
|
Выбрать имя, выпавшее в подсказках |
Ольга |
Регистрация успешная |
|
Проигнорироваь подсказки, сохранить свою версию |
Тумбочка |
Регистрация успешная, ограничений на «строго по нашему справочнику» нет |
|
Имена |
||
|
Мужское |
Иван |
Успешная регистрация, в подсказках имя есть |
|
Женское |
Ольга |
|
|
Унисекс |
Саша |
|
|
Распространенное |
Иван |
|
|
Редкое |
Лёва |
|
|
Имя, с которого может начинаться фамилия и/или отчество |
Александр(ов) |
|
|
Имя, с которого НЕ может начинаться фамилия |
Михаил (И перейдет в Й) |
|
|
Имена, у которых возможны разные варианты написания |
Наталья / Наталия Алена / Алёна |
|
|
Имя, которое бывает и полной формой, и краткой одновременно |
Лана, Ася (Светлана, Анастасия) |
|
|
Имя, которое в мужском и женском варианте отличается только окончанием — оба варианта подсказки покажут или только один? |
Александр / Александра |
Оба имени есть в подсказка, регистрация успешна |
|
Алфавит |
||
|
Русское имя |
Ольга |
Успешная регистрация, ограничений на имя нет |
|
Буква Ё |
Пётр |
|
|
Имя на английском |
Alex |
|
|
Имя на транслите |
Aleksei |
|
|
Забыли сменить раскладку |
Jkmuf |
|
|
Спецсимволы |
!@#$%^&*()~{}”:><? |
|
|
Регистр |
||
|
CamelCase |
Ольга |
Успешная регистрация |
|
Lower case |
ольга |
|
|
UPPER CASE |
ОЛЬГА |
|
|
Смешанный |
оЛьГа |
|
|
Длина строки |
||
|
Имя нормальной длины |
Ольга |
Подсказки выпали, регистрация успешна |
|
Пустое поле (ноль, логическая граница) |
Регистрация успешная, имя необязательное |
|
|
Один символ (пограничное) |
Я |
Регистрация успешная |
|
15 символов (произвольная граница) |
Антуаннетта123 |
Регистрация успешная |
|
16 символов (пограничное значение) |
Антуаннетта1234 |
В поле ввелось только 15 символов. При копипасте последний символ отсекается |
|
10 млн символов (поиск технологической) |
counterstring 10000000 |
Система обрезает все лишнее, не зависает, регистрация успешная |
Чек-лист накидали, а теперь выкинем лишнее!
2.1. Фантазия разгулялась
На тему разгулявшейся фантазии обратимся к той части чек-листа, где мы перечисляли разные варианты тестирования имен:
ЧЛ 1. Чек-лист для поля «Имя» при регистрации
|
Проверка |
Пример |
Результат |
|
Имена |
||
|
Мужское |
Иван |
Успешная регистрация |
|
Женское |
Мария |
|
|
Унисекс |
Саша |
|
|
Распространенное |
Иван |
|
|
Редкое |
Лёва |
|
|
Имя, с которого может начинаться фамилия и/или отчество |
Александр(ов) |
|
|
Имя, с которого НЕ может начинаться фамилия |
Михаил (И перейдет в Й) |
|
|
Имена, у которых возможны разные варианты написания |
Наталья / Наталия Алена / Алёна |
|
|
Имя, которое бывает и полной формой, и краткой одновременно |
Лана, Ася (Светлана, Анастасия) |
|
|
Имя, которое в мужском и женском варианте отличается только окончанием — оба варианта подсказки покажут или только один? |
Александр / Александра |
Если мы тестируем подсказки, то это все очень правильные тесты. Но что, если мы тестируем обычную систему, где разработчик просто добавил текстовое поле, без каких-либо ограничений? Так то разных имен можно придумать хоть сотню, но на самом деле нам не надо это все проверять.
И если мы тестируем просто поле, то все лишнее можно смело выкидывать.

При тестировании регистра тоже можно сократить количество проверок:
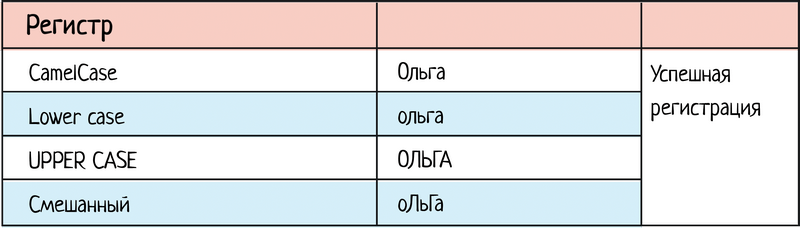
Что мы хотим реально проверить? Что система не зависит от регистра. Поэтому на самом деле обычно хватает смешанной проверки: оЛьГа проверили и норм. А чистый КАПС или нижний уже не нужны:

При этом проверка зависимости от регистра очень важна. Особенно когда речь идет про поиск. Зависит ли поиск от регистра или надо вводить «четко как хранится в системе»? Проверить надо, писать десяток тестов — нет.
2.2. Я это уже проверял
Когда мы накидываем варианты проверок, то даем волю фантазии. А потом смотрим на итоговый чек-лист и видим, что часть тестов повторяется.
Вот, например, свое имя «Ольга» я проверяю несколько раз в разных блоках:
-
Выбор из подсказок;
-
Женское имя;
-
Русский алфавит;
-
CamelCase;
-
Средняя длина;
ЧЛ 1. Чек-лист для поля «Имя» при регистрации

Что это значит? Что можно оставить только один тест, а остальные — выкинуть!

И это на самом деле самое простое, но самое приятное, что мы можем сделать при анализе тестов. На это способен любой новичок. Причем начинающие некоторые дубли видят заранее. Вот, например, мои студенты обычно еще до лекции с анализом тестов задаются вопросом:
— Зачем в разделе «длина строки» проверять нормальную длину? Мы же ее уже тестировали ранее, не получается ли дубля?

Получается! И здорово, когда ребята это сразу подмечают. Но в школе я их прошу пока оставить дубли, потому что следующая лекция про анализ и домашнее задание как раз «возьмите свой чек-лист и выкиньте лишнее». Мы работаем в Ситечке и в рамках анализа просим не удалять проверки физически, а поставить ненужным самый низкий приоритет. Сразу видно, сколько тестов выкинуто — это правда круто!
Почему я прошу оставлять дубли? Все очень просто:
-
Учимся начинать с позитива — ВСЕГДА сначала позитив, потом негатив. А если выкинуть «имя нормальной длины», то группа тестов начинается с «пустая строка». Это вроде и логично выглядит, но на начальном этапе надо прям ставить мозги на «сначала позитив», чтобы аж в подкорке было. Чтобы на тестировании НЕ длины он тоже в приоритете стоял.
-
Так проще — если сразу думать о дублях, генерировать идеи тяжело. Почитайте про практики мозгового штурма.
Фактически набросать первую версию чек-листа — это тот же брейншторм (Brainstorm — мозговой штурм), только на одного человека.

Вы сидите и генерите идеи. И если после каждой мысли останавливаться и думать «а это адекватный тест? А не проверял ли я это раньше?», то никакого полета фантазии не будет. На этапе генерации идей важно не ограничивать себя:
— Выбор из подсказок? Можно выбрать. А что, если выбрать, потом стереть и ввести повторно и снова выбрать? Или стереть и ввести свое? Или выбрать и заменить потом окончание?
— Алфавит? Русский, английский, русский, забыв переключить раскладку, иероглифы какие-нить…
— Длина? Так, нормальная, ноль, один, граница произвольная, пограничное, поиск технологической…
— Регистр? Обычный, верхний, нижний, перемешали…
— …
Вот что приходит в голову, то и записываем. А уже потом начинаем отсеивать. Так, это я уже проверил, это проверил, и это. А это вообще космолет, сначала позитивные тесты.
Начинайте именно так! Это очень важно особенно на начальных стадиях, пока вы в тестировании недавно, нет накопленного опыта, где вообще бывают баги, мало идей… Если еще и их контролировать, совсем ничего не придумаете.
И опять же по опыту студентов, дублирование замечают заранее только в длине строки. Хотя в их чек-листах есть и другие =)))
Поэтому сначала записываем, потом вычеркиваем.

Сделаете так 5 раз, 10 — уже поймете, где тесты обычно дублируются и исходно будете НЕ писать заведомо лишние проверки.

Пример: длина строки для разных алфавитов
Ещё из опыта студентов. Самый частый кейс дублей — 15 млн символов русских, повторить для английских, для цифр, для спецсимволов и т.д. Когда технологическую границу ищем. А иногда вообще блок с длиной дублируется:
-
Русские символы: 0, 1, 10, 20, 21, 1 млн (если в 20 стоит граница)
-
Английские: 0, 1, 10, 20, 21, 1 млн
-
Цифры: 0, 1, 10, 20, 21, 1 млн
-
Спецсимволы: 0, 1, 10, 20, 21, 1 млн
В целом, тут есть здравое зерно. Если у нас ограничение на 20 символов, то вполне может быть такое, что разработчик поставил ограничение в байтах. В итоге у нас 20 символов латиницей или цифр пройдут, а вот 20 русских символов не сохранятся…
Сколько байт занимает русский символ?
В зависимости от кодировки ответ разный. Например, «cp1251» — 1 байт, в «utf-8» — 2 байта (хотя латинский — 1 байт), и т.п.
Тут важно что? Важно понимание того, что такое кодировки, какие они бывают… Но для уровня новичка можно ориентироваться примерно так:
-
1 латинский символ — 1 байт
-
1 символ кириллицы — 2 байта
Цифры как латиница, тестировать и то, и другое явно смысла нет. Проверить произвольную границу 20 можно дважды: на русском и английском языке (вдруг они правда отличаются?). А вот все остальные проверки дублировать не надо.

0 символов — оно и в Африке ноль символов. Пограничное один — проверьте позитивным тестом, какие символы или цифры вводит пользователь, не пытающийся сломать систему?
А поиск технологической… Если вы знаете четко, что кириллица занимает больше места, то ищем границу через русские символы. Дублировать тесты под цифры или латиницу уже не надо. Если разницы в произвольной границе не было, то пофиг, на чем конкретно вводить 100 млн данных.
Помните — длина строки и разные алфавиты: разные классы эквивалентности, разные группы тестов. Не надо их дублировать один внутри другого. Максимум, что стоит проверить — это произвольную границу по ТЗ. На русском и английском.
3. Не тестировать один функционал 10 раз
Когда вы тыкаете на кнопочки в интерфейсе, внутри программы задействуются те или иные участки кода. Хороший код — с грамотной структурой и переиспользованием вместо копипасты. Это значит, что разработчик пишет функционал в одном месте, а потом просто дергает вызов этого функционала из разных мест интерфейса.
Вот, допустим, поиск по каком-то сайте. Вы открываете главную — справа вверху есть строка с поиском. Вы переходите на карточку красного платьюшка — вверху осталась та же строка. Вы переходите на карточку синих брючек — строка поиска все еще есть.
Внимание, вопрос — нужно ли тестировать эту строку на каждой странице отдельно, снова и снова?

Разумеется, нет. Мы понимаем, что это один и тот же функционал, который просто привязали к кнопке с лупой. Тыкаешь на лупу — запускается код поиска. И неважно, где эта лупа была, на главной, в результатах прошлого поиска или на карточке конкретного товара.
Мы помним про тест-дизайн, про классы эквивалентности. Про пример с калькулятором, где можно писать сотни миллионов тестов только на одно лишь сложение, если не использовать классы эквивалентности. Так и тут: если на сайте 10 000 товаров, то тестировать раздел навигации на каждой странице будет стоить дорого, а толку не принесет.
Это простой пример. Мы видим, что на каждой странице у нас форма выглядит одинаково, никуда не пропадает, не меняется → так мы понимаем, что это один и тот же функционал, который не надо тестировать заново.
Но ведь бывают и случаи сложнее. Когда функционал один, но выглядит по-разному. И тут начинается ступор и попытки протестировать одно и то же несколько раз. Хотите примеров?
Подсказки при регистрации
Вернемся к нашему чек-листу регистрации в Дадате. В разделе разгулявшейся фантазии мы говорили о том, что чек-лист хорош для тестирования подсказок, но для простого поля с именем это слишком много.
Но ведь у нас есть подсказки! Когда начинаем вбивать имя, мы видим список подсказок. Значит, их надо тестировать. Да? Или нет?
Нет, не надо. Подсказки — это отдельный функционал, который просто привязывается к конкретной формочке графического интерфейса. Поэтому при тестировании разделяем функционал. В чек-лист подсказок по ФИО вносим все наши мудрые идеи про «А если на такое имя может начинаться отчество? А если у имени возможны два написания, увижу ли оба? А если унисекс, какие увижу фамилии?…».
А вот в чек-листе регистрации нам сам функционал подсказок исследовать уже НЕ нужно, мы предполагаем, что он уже проверен. Наша задача состоит лишь в том, чтобы проверить, что подсказки к имени подключены. И всё! Если начинаем ввод и подсказка выпадает — всё ок. Дальше тестируем как простую строку.
По крайней мере, это работает, когда и подсказки, и регистрация — это всё функционал вашей системы. Тогда подразумевается, что вы или ваш коллега уже проверил подсказки. И именно поэтому тестировать их ещё раз — дублировать чужую работу.
А вот если вы подключаете сторонний продукт, то его проверить стоит. Мало ли, какого уровня тестирование «на той стороне»?
Итого после выкидывания всего лишнего что же у нас остается?

Перепишем результат
ЧЛ 1.2. Чек-лист для поля «Имя» при регистрации
|
Проверка |
Пример |
Результат |
|
С какой буквы начинаются подсказки |
||
|
Имена на такую букву есть, распространенная |
О |
Подсказки выпадают с первой буквы. В первой пятерке есть: · Ольга · Олег · Оксана |
|
Подсказки или свое |
||
|
Выбрать имя, выпавшее в подсказках |
Ольга |
Регистрация успешная |
|
Проигнорироваь подсказки, сохранить свою версию |
Тумбочка |
Регистрация успешная, ограничений на «строго по нашему справочнику» нет |
|
Имена |
||
|
Мужское |
Иван |
Успешная регистрация |
|
Унисекс |
Саша |
|
|
Алфавит |
||
|
Буква Ё |
Пётр |
Успешная регистрация |
|
Имя на английском |
Alex |
|
|
Спецсимволы |
!@#$%^&*()~{}”:><? |
|
|
Регистр |
||
|
Смешанный |
оЛьГа |
Успешная регистрация |
|
Длина строки |
||
|
Пустое поле (ноль, логическая граница) |
Регистрация успешная, имя необязательное |
|
|
Один символ (пограничное) |
Я |
Регистрация успешная |
|
15 символов (произвольная граница) |
Антуаннетта123 |
Регистрация успешная |
|
16 символов (пограничное значение) |
Антуаннетта1234 |
В поле ввелось только 15 символов. При копипасте последний символ отсекается |
|
10 млн символов (поиск технологической) |
counterstring 10000000 |
Система обрезает все лишнее, не зависает, регистрация успешная |
Сильно меньше тестов, не правда ли? Зная, что поле с именем — простая строка без доп проверок, к которой прикручены подсказки, мы проверяем:
-
Что подсказки в принципе работают (так как скорее всего пользователь будет использовать именно их)
-
Что их можно проигнорировать;
-
Общие проверки для простой строки с уклоном в то, что это все-таки имя
Конечно, бывают такие разработчики, которые все делают тяп-ляп и вместо переиспользования функционала они его дублируют. Что приводит к внезапным для нас ошибкам. Обычно такое встречается на фрилансе, там не заморачиваются на чистоте кода, а просто делают по ТЗ.
У меня была такая ситуация: в системе можно создать карточку товара из двух мест: на главной странице и в разделе товаров. Выглядят эти кнопки одинаково и одинаково же работают. Казалось бы, проверили одну → вторая тоже будет работать. Но я сталкивалась с багами типа «на главной работает, в разделе товаров эксепшен (ошибка)».
И тут есть два варианта этой ошибки:
-
Разработчик не переиспользовал код, а переписал его снова (например, он забыл, что уже делал такое, или код прошлой кнопки писал другой разработчик, а этот еще не знае всего кода, ну или просто лентяй) — тогда придется дублировать все проверки и проверять один функционал несколько раз.
-
Разработчик код переиспользовал, он на каждую кнопку повесил вызов одного функционала, просто на второй кнопке опечатался — вот она и падает с ошибкой. Исправит опечатку и все будет норм. В этом случае нам достаточно проверить функционал кнопки целиком один раз, а для второй кнопки просто один раз тыкнуть и убедиться, что открылось нужное окно. Всё, это значит, что глупых опечаток нет, метод вызвался. Полный ретест не нужен.
По умолчанию мы считаем своих разработчиков адекватными людьми, за которыми не надо перетестировать одно и то же 10 раз подряд. Если в ТЗ написано, что «вот тут тот же самый функционал», то принимаем это на веру: нам нужно буквально 1-2 теста, убедиться, что функционал сюда подключен, и все.
Но во избежание эффекта пестицида мы каждый прогон ручных тестов немного варьируем свои проверки. А заодно можем тестировать чек-лист одного функционала сначала в одном месте, потом в другом. И если замечаем разницу и понимаем, что разработчик у нас «косячный», тогда уже придется увеличивать скоуп работ. Но по умолчанию один функционал мы проверяем один раз.

Интерфейс и API
Самый распространенный пример переиспользования функционала — это когда его можно проверить вручную, потыкав на кнопочки в интерфейсе + есть некий API-метод (SOAP, REST…)
На самом деле, если заглянуть под капот, то мы поймем, что в интерфейсе на самом деле дергается тот же самый код, зачастую тот самый API-метод. Что делаем в таких случаях, уже понятно:
-
Основной функционал проверяем в одном месте, где проще;
-
Во втором месте смотрим только особенности.

Например, в одной из моих систем пользователь может выполнять действия вручную (искать, изменять данные и тд) + все операции продублированы через SOAP-методы. Вызовы методов описаны в документации, потому что их используют внешние системы. То есть изменение данных идет двумя разными сценариями:
-
Операционист банка изменяет что-то в своей банковской системе — эта система составляет SOAP-запрос и оправляет к нам (хранилище данных).
-
Пользователь нашей системы меняет данные сразу в ней, используя интерфейс.
Методы вроде одинаковые, но всякие плюшки интерфейса настраиваются в API с помощью параметров. Поэтому через API мы сам функционал проверяем один раз, что он в принципе работает, а потом рассматриваем особенно именно API, проходим по ТЗ, тестируем его параметры.
Посмотреть, как это выглядит в требованиях, можно на примере Folks (чтобы увидеть ТЗ, надо авторизоваться, данные тут) — это бесплатное тестовое приложение, куда из реальной системы вынесена логика поиска. Можно искать через интерфейс, можно через SOAP-запрос.
В Folks нет графического интерфейса (по крайней мере, пока нет, но я пока и не планирую его туда добавлять), но уже есть работоспособный код. И даже фреймворк под автотесты!
Как происходит тестирование в системе, по аналогии с которой сделан Folks?
-
Есть отдельные тесты на поиск — они имитируют работу пользователя. Очень простые, просто запрос и список клиентов, которые вернет система. Запрос — это тот текст, который пользователь будет вводить в строку поиска в системе. Тут мы тестируем логику поиска.
-
Есть тесты на soap и отдельная документация на этот метод — по документации мы видим, что в SOAP появляется дополнительная логика отображения результата. Список клиентов, которые вернет система (логика поиска), остается неизменным. Но мы можем варьировать результат: верни мне все данные по клиенту, только реквиты, только атрибуты… И в тестах на SOAP мы проверяем именно эту дополнительную логику, сделанную специально для интеграций с разными системами. Мы не дублируем все тесты на поиск, мы тестируем особенности SOAP-вызовов.
Можете попробовать сами, почитайте документацию, посмотрите обучающие видеоролики, которые я сделала специально под Folks, сравните, как выглядят тесты на поиск и тесты на SOAP-метод search.
3. Где схлопывать тесты НЕ надо
Не надо объединять тесты на функционал и тесты на данные. Посмотрим на примере поиска и фильтрации. Вот, например, фильтры в интернет-магазине:
-
Платья / шорты / топики
-
Платья: вечерние, повседневные..
-
Цвет
-
Материал
-
Размер
-
…

Можно установить один фильтр, а можно несколько сразу. Получается поиск с разными параметрами! Где-то там, под пользовательским интерфейсом скрывается некий API-метод, который умеет возвращать результат под разные входные условия.
Как мы начинаем тестировать? Какой будет первый тест? Сразу же понеслись «а вот выберу платья, цвет серый, материал плюш, размер 42…»? Нет, это уже комплексное тестирование. Оно тоже важно и нужно, но начинаем с простого.
См также:
В тестировании всегда начинаем с простого! — подробнее о том, зачем так делать
Берем каждый фильтр и тестируем по отдельности. Вроде кажется, что тестов будет over дофига, в базе магазина ведь целая куча данных! Но тут надо разделять тесты на функционал и тесты на данные.
Тесты на функционал
Вот, допустим, цвет. У нас есть 7 цветов: синий, розовый, красный, зеленый, белый, черный, голубой. Нам надо проверить, как каждый цвет работает в отдельности + комплексные тесты (а что, если я выбрала не один цвет, а два? А что, если вообще все?).
При этом не надо упарываться на то, что в магазине есть 10 000 платьев синего цвета, «неужели мне все их проверять?». Нет, это уже будут тесты на данные. А нас сейчас интересует функционал. Возвращаются ли в принципе синие вещи?
Если мы тестируем своё приложение, у нас есть доступ или к коду, или к разработчикам. Мы можем выяснить сам механизм. И вряд ли разработчик каждую вещь добавляет в код через IF id = 101 THEN… Нет, скорее он делает набор меток типа color (цвет). Вот по значению метки и возвращает ответ.
И когда я в интерфейсе нажимаю «покажи мне синие вещи», на самом деле внутри отправляется запрос с параметром color = blue. Если цвет красный, то color = red. Если несколько, то перечислением, если цвет не указан — в запросе параметра тоже нет. И все эти ситуации надо проверить:
-
Создаем вещи с метками blue и red — у тестировщика системы обычно есть такая возможность. Или прямо в базу добавить, или через админку, или в автотесте.
-
Выбираем в интерфейсе фильтр «синий» или отправляем напрямую запрос с блоком color = blue → проверяем, что вернулась только одна из вещей, с правильной меткой.
-
Выбираем фильтр «красный»
-
Выбираем сразу оба фильтра
-
Оставляем фильтрацию пустой
Вы сейчас можете сказать: стоп, стоп! А как же тест-анализ? Зачем тестировать каждый цвет? Достаточно проверить один, если функционал с метками работает — значит, всё норм.
Не совсем. Да, разработчик не пишет обработку для каждой вещи. Но он пишет обработку для каждой метки:
-
if параметр в запросе color = blue → возьми все вещи, у которых цвет blue
-
if параметр в запросе color = red → возьми все вещи, у которых цвет red
И вот тут он может ошибиться. Например, скопипастить результат и в обоих случаях выводить синие вещи. Или случайно опечатался и усе, синий работает, розовый, белый, черный — все работает, а вот на красном упадет! Причем с ужасной ошибкой, если разработчик не предусмотрел такой исход и не обернул эксепшен.
Возможно, вы точно знаете, что код более умный и работает через параметры. If param = $param_1 then took thing with color = $param_1. Тут да, что красный, что синий — пофигу, один класс эквивалентности. Казалось бы.
Но стоит задуматься, откуда берутся значения параметров. Наверное, где-то в коде есть класс, в котором перечислены допустимые величины — BLUE, RED, GREEN… И если разработчик опечатался в том классе, написав blie вместо blue, то хоть вы 100500 меток «синий» в админке на вещи повесите, поиск их никогда не найдет.
Поэтому проверить все цвета — надо. Другое дело — как. Если у нас есть доступ к коду, то достаточно один раз вычитать файл с переменными и убедиться, что они написаны без опечаток. А в интерфейсе или автотестах проверить сам функционал:
-
1 метка выбрана — только её и вернули
-
Несколько меток выбрано (класс «один — не один») — их вернули
-
Ничего не выбрано (тестируем ноль) — всё вернули
Тесты на данные
А тут мы уже проверяем сами данные. Правильно ли человек, отвечающий за наполнение базы, разместил метки. Это когда ты выбираешь «синее платье», а получаешь желтые шорты → это ошибка не в функционале, а в самих данных.

Нет, всё бывает, конечно, может быть и ошибкой функционала. Но, если мы уже провели тесты на функционал и знаем, что сами по себе метки работают, значит, такой баг является багом данных. Для исправления которого нужен не разработчик, а любой человек, имеющий доступ к админке.
И вот тут уже тестирование — это трудоемкий процесс. Потому что надо проверить на адекватность все 100500 наименований в базе. А времени то обычно мало, релиз нужен «еще вчера», все как обычно =)
Именно поэтому, когда ищешь что-то на сайте типа https://www.wildberries.ru/, порой поражаешься результатам поиска. Но виноваты в этом не разработчики, функционал есть и он работает. Баги допустили те, кто наполняет данные.
Это как если вы заметите ошибку в блог-посте, допустил ее автор поста. А сам блоггер или другая платформа, на которой поднят сайт, тут ни при чем.
Комплексные тесты
Комплексные тесты тоже нужны. Потому что иногда по отдельности фильтры работают, а вот вместе увы, никак. Но чтобы проверить, как что-то работает в связке, нужно сначала проверить каждый элемент по отдельности. Иначе как понять, из-за чего сломалось?

Итого
Когда мы пишем чек-лист, то сначала можем просто генерировать идеи, без оглядки на дубли. А потом присматриваемся к чек-листу и сокращаем:
-
Объединяем позитивные тесты
-
Выкидываем дубли
-
Выкидываем тестирование другого функционала
Сократить чек-лист можно довольно сильно, посмотрите ещё раз на наш пример:

Главное — делать это осознанно и с умом, не выплеснув ценное в попытках сократить количество проверок =)
А вот тесты на функционал и на данные путать не стоит. Их надо разносить в проверках. Сначала проверяем функционал, а потом уже смотрим на реальные данные (если эта задача ставится перед тестировщиком, но обычно это уже задача операторов качества данных).
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
← Предыдущий урок
(Перед вами перевод бесплатного курса по A/B тестированию от компании Dynamic Yield. Если вы здесь впервые, то лучше начните сначала)
Автор английской версии: Шана Пилевски, директор по маркетингу, Dynamic Yield
На большинстве платформ для проведения экспериментов есть встроенная функция аналитики, чтобы отслеживать нужные метрики и KPI. Но прежде чем смотреть в отчеты и начинать что-то анализировать, важно понять суть двух ключевых метрик:
- Рост (аплифт, uplift): разница (в процентах) между показателями вариации и базовой (контрольной) версии. К примеру, если для вариации доход на пользователя составил 5$, а для контрольной версии — 4$, значит рост составил 25%.
- Вероятность того, что одна версия лучше другой (P2BB, Probability to Be Best): показывает, каковы шансы, что конкретная вариация будет более эффективной в долгосрочной перспективе. Эта метрика самая полезная во всем отчете с практической точки зрения — ее используют для определения победителя A/B теста. Если рост (аплифт) может варьироваться в зависимости от размера выборки, то показатель P2BB (вероятность, что одна версия лучше) учитывает размер выборки (основываясь на байесовском подходе). P2BB не начинает вычисляться, пока выборка не достигнет 1000 или не наберется 30 конверсий. Проще говоря, показатель P2BB отвечает на вопрос “Какая версия лучше?”, а рост показывает “Насколько?”
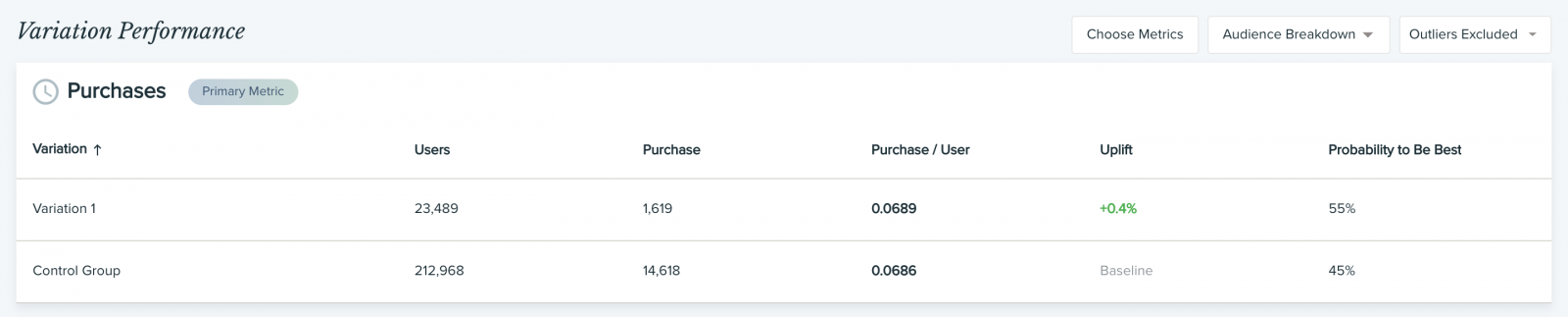
Базовый анализ
Начните с проверки результатов A/B теста: возможно, уже выделился конкретный победитель или хотя бы есть информация, какая вариация побеждает на данный момент. Если ваша платформа для тестирования не рассчитывает метрику P2BB (вероятность, что одна версия лучше другой), можете воспользоваться нашим байесовским калькулятором для A/B тестирования, чтобы обработать данные и выявить статистически значимые результаты.
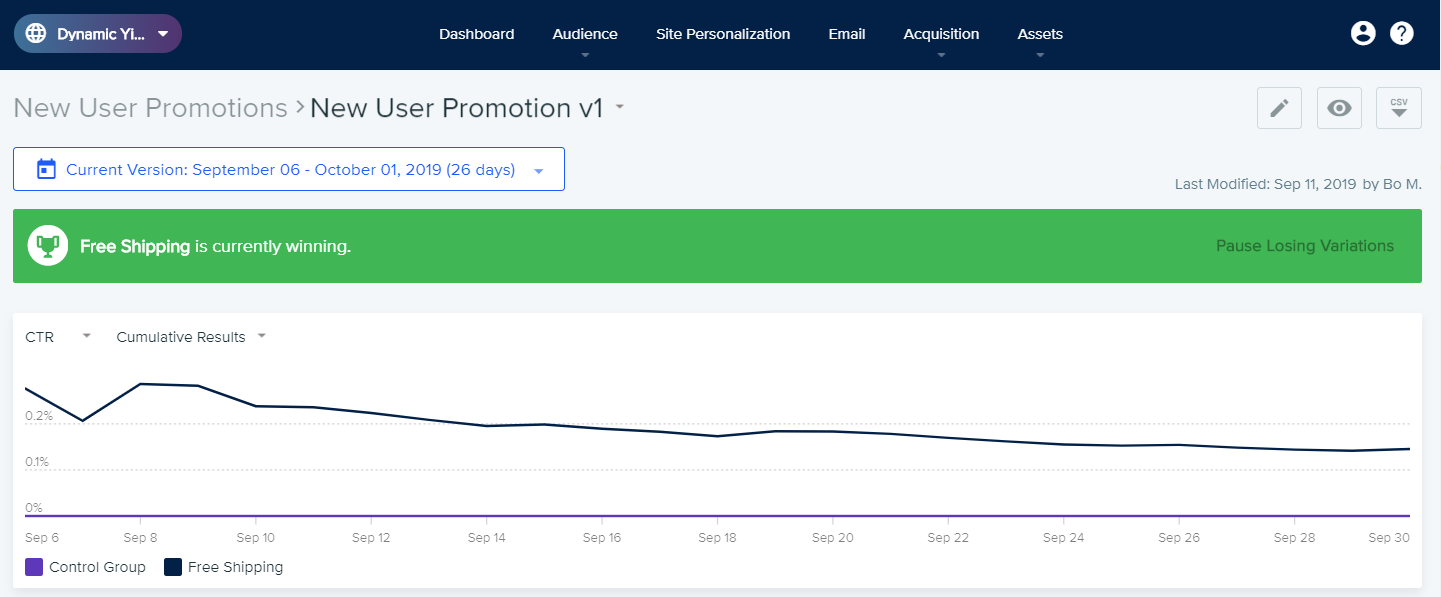
Обычно, победитель объявляется, когда соблюдены следующие условия:
- Для одной из вариаций показатель P2BB превысил 95% (некоторые платформы позволяют менять порог этого показателя через настройку уровня значимости победителя).
- Прошло минимальное время тестирования (по умолчанию это 2 недели). Это делается, чтобы застраховать результаты от влияния сезонных колебаний.
Анализ вторичных метрик
Обычно победитель тестирования определяется на основании одной ключевой метрики. Однако некоторые платформы (и Dynamic Yield в их числе) также отслеживают и дополнительные, так называемые вторичные метрики. Прежде чем вы завершите эксперимент и начнете масштабировать вариацию-победителя на всю аудиторию, рекомендуем всегда анализировать вторичные метрики, и вот почему:
- Перестраховаться от ошибки (например, победившая вариация обеспечила рост вашей ключевой метрики CTR, но повлекла падение количества покупок, объема дохода или средней стоимости заказа (AOV)).
- Раскопать ценную информацию (например, доля покупок на пользователя сократилась, но средняя стоимость заказа выроста, из чего следует, что пользователи делают покупки реже, но приобретают более дорогие товары — следовательно, генерируют больше прибыли).
По каждой вторичной метрике мы рекомендуем отслеживать рост (аплифт) и P2BB, чтобы отслеживать эффективность вариаций в сравнении.
После такого анализа будет понятно, стоит ли выкатывать одну победившую вариацию на весь трафик или лучше скорректировать распределение на основании новых данных.
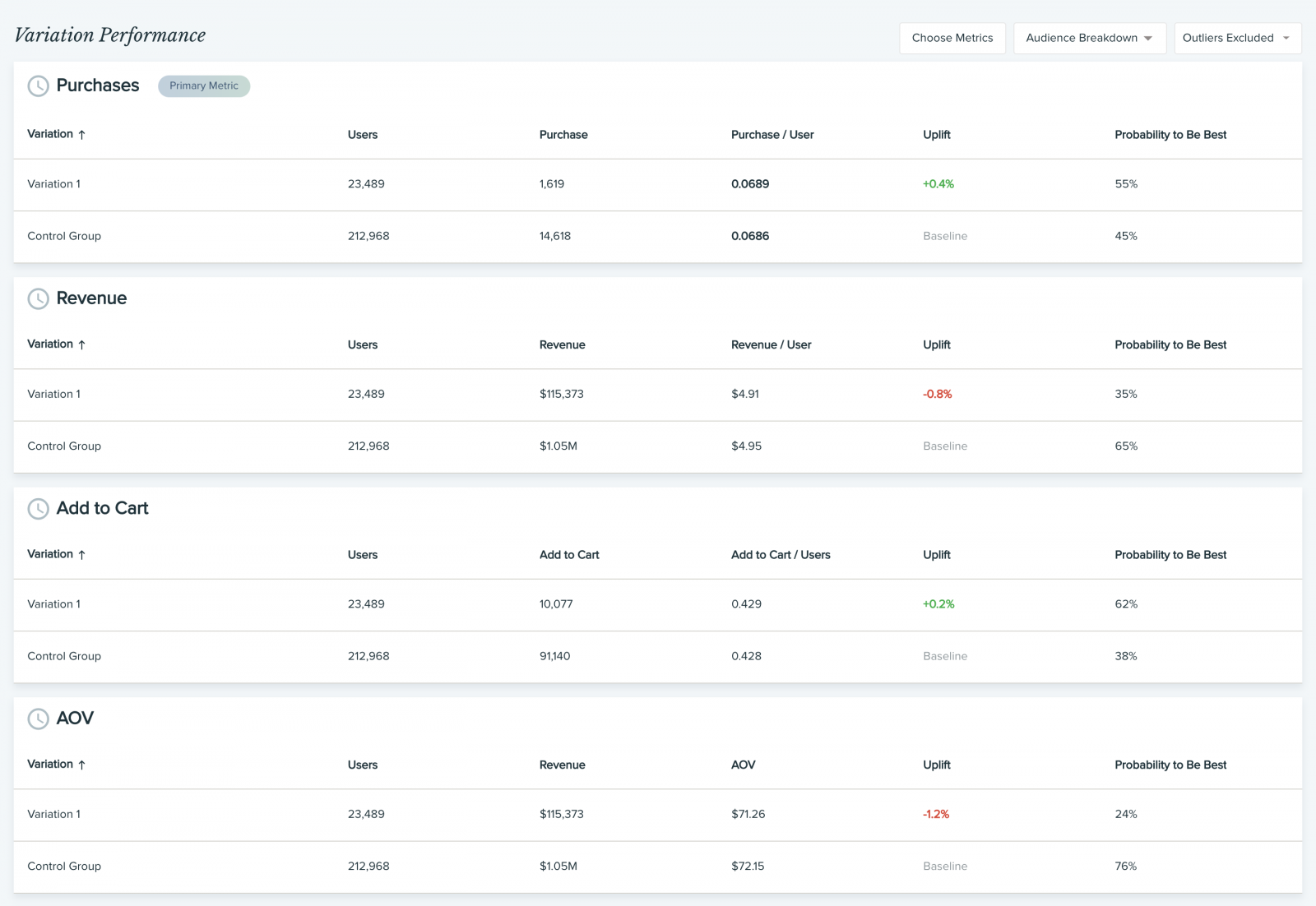
Анализ состава аудитории
Еще одно направление, в которое стоит углубиться — это разбивка результатов по сегментам аудитории. Это поможет ответить на следующие вопросы:
- Как вел себя трафик из разных источников в процессе эксперимента?
- Какая вариация победила среди мобильных пользователей/ пользователей десктопов?
- Какая вариация лучше сработала для новых пользователей?
Рекомендую выделить пользователей, наиболее значимых для бизнеса, в отдельный сегмент, а также сгруппировать тех пользователей, чье поведение отличается от общей аудитории.
Опять же, по каждой аудитории нужно отслеживать рост (аплифт) и P2BB, чтобы оценить эффективность каждой вариации. Это тоже поможет определиться, стоит ли выкатывать изменения сразу на всю аудиторию.
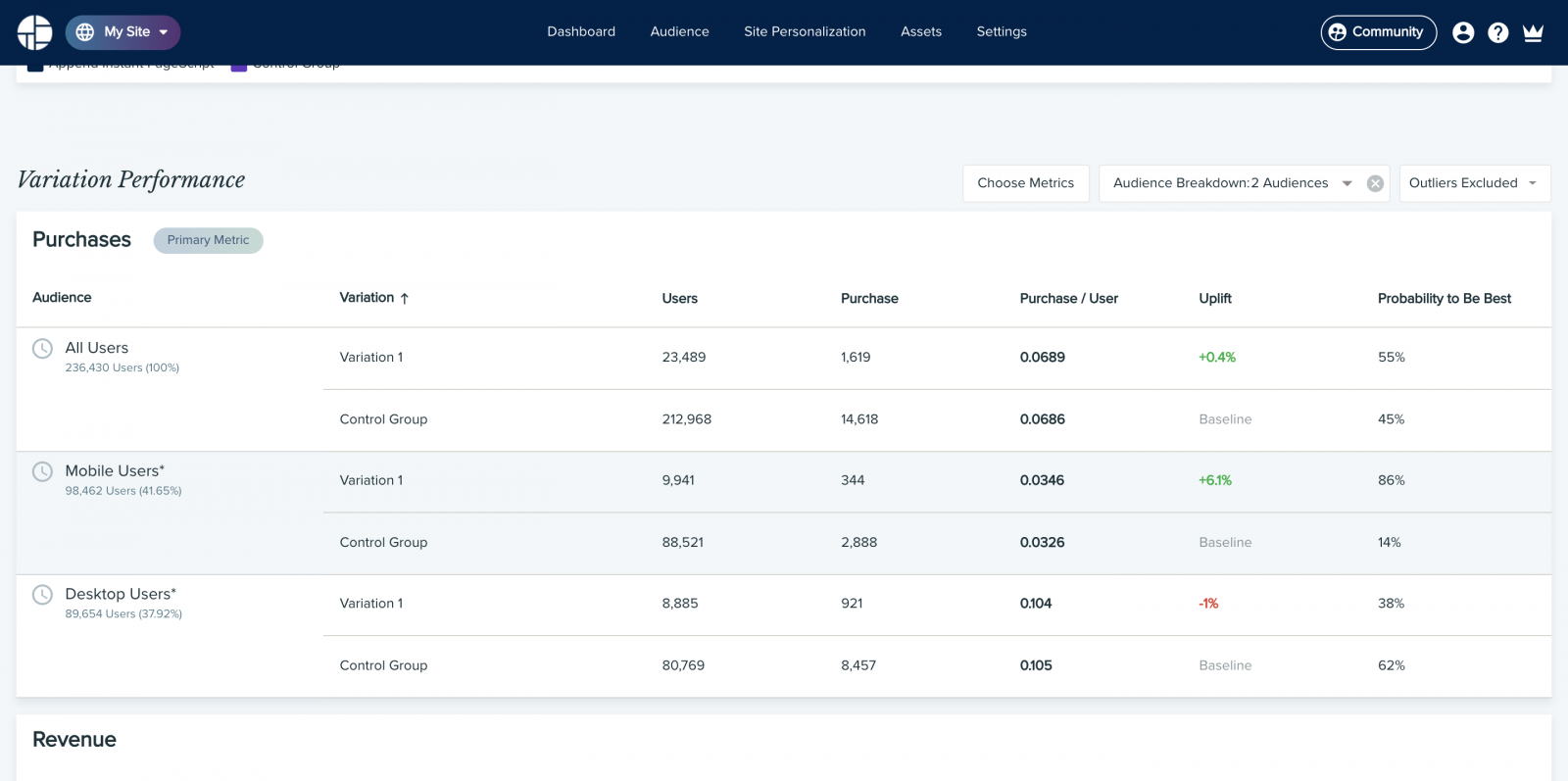
Но иногда проигрыш в A/B тесте — это на самом деле победа!
Нет никаких сомнений, что оптимизация конверсии (CRO) и A/B тестирование работают. Они всегда помогали маркетологам, которые находятся в контакте с аудиторией и в целом знают, чего хотят посетители, выбирать максимально эффективные варианты подачи контента и существенно поднимать конверсию и доход. Однако сегодня в игру вступает персонализация. По мере того, как пользовательский опыт становится все более персонализированным, результаты экспериментов, которые не учитывают индивидуальные особенности пользователей, уже нельзя назвать однозначными; кроме того, становится все сложнее добиваться статистической значимости.
В этом сложном новом мире персонализации, где “среднестатистические пользователи” уже не могут говорить за “всех пользователей”. Это означает, что старый подход, когда мы искали некий “лучший” опыт и пытались масштабировать его на всю аудиторию, больше не работает, хотя мы и пытаемся выжать из него максимум: вычисляем нужный размер выборки, совершенствуем гипотезы и оптимизируем KPI.Сегодня мы уже не можем просто положиться на успешный эксперимент и использовать вариацию-победителя для всех. Нужно понимать, что в этом случае мы все равно игнорируем интересы определенного процента пользователей, для которых наша “лучшая” вариация таковой не является — а такой процент всегда будет. Если принять как данность эту особенность A/B тестов, становится очевидно, что даже проигрыш в A/B тесте может обернуться победой. Неудачный тест иногда помогает выявить скрытые возможности, которые при должном (персонализированном) подходе могут принести блестящие результаты. Ниже приведены результаты настоящего эксперимента, который длился порядка 30 дней. На первый взгляд тут почти ничья, и контрольная версия даже кажется эффективнее экспериментальной.
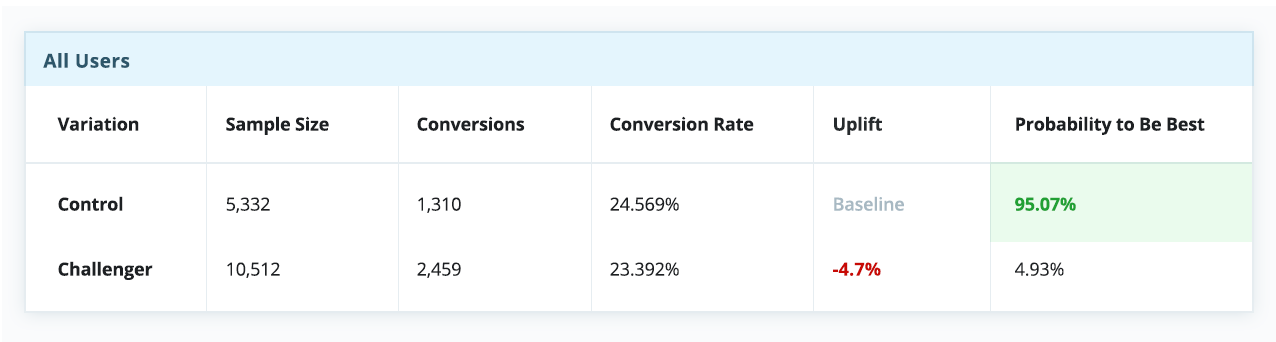
Однако если разбить эксперимент на сегменты по типам устройства — а это довольно простой и распространенный тип сегментации — история в корне меняется. Очевидно, что контрольная версия побеждает для десктопов, но сильно проигрывает среди пользователей телефонов и планшетов.
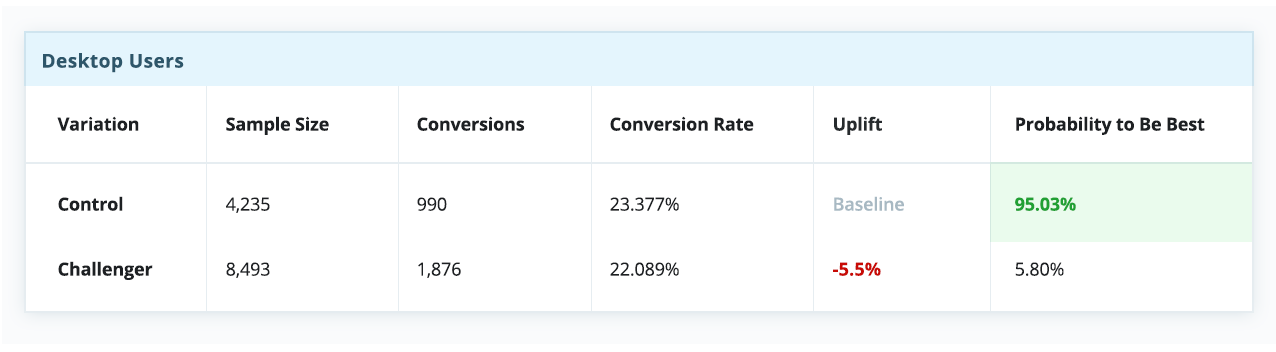
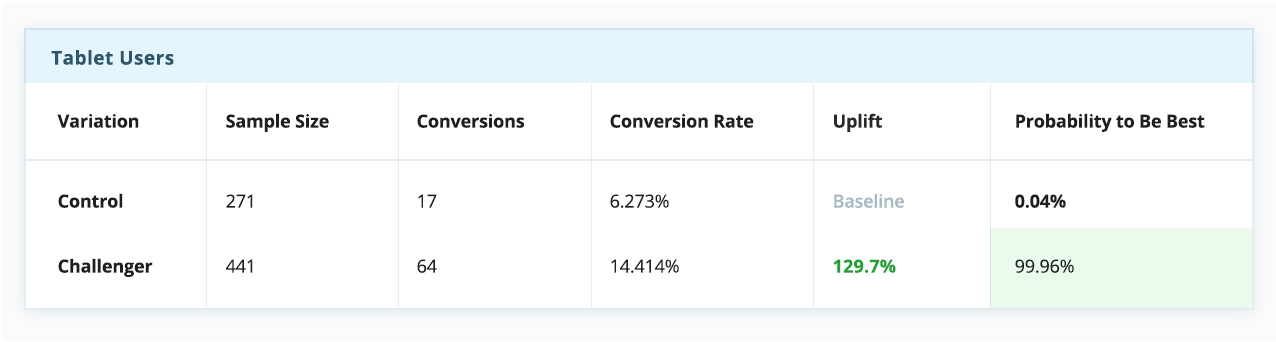
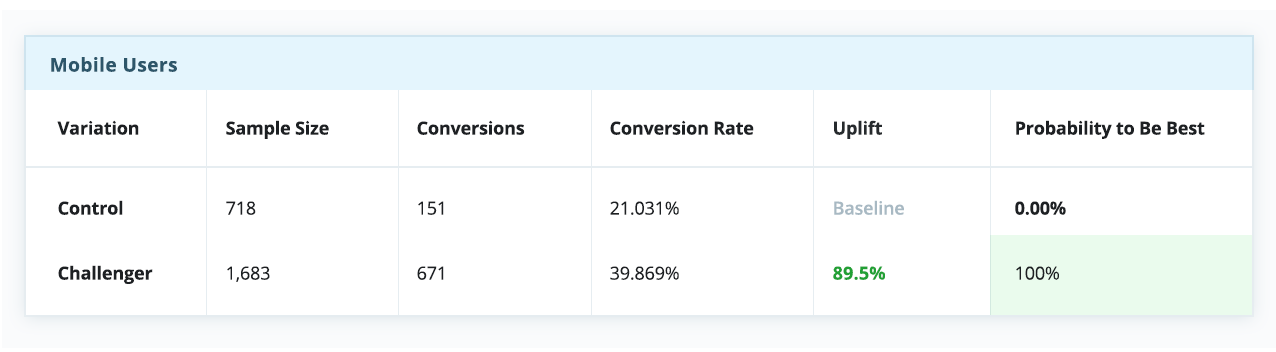
В контексте этого примера, если бы мы выбрали стратегию “winner takes all” (а многие так и делают), всей аудитории пришлось бы довольствоваться единым пользовательским опытом, якобы оптимизированным под среднестатистического пользователя — несмотря на то, что пользователи мобильных устройств явно предпочли экспериментальную вариацию.
А вот еще один пример, в котором контрольная вариация, казалось бы, проигрывает по результатам эксперимента в масштабе всей аудитории. Однако дальнейший анализ показал, что эффективнее будет показывать победившую вариацию (v2) наиболее многочисленному сегменту “прямого трафика”, а остальным пользователям продолжать показывать контрольную вариацию.
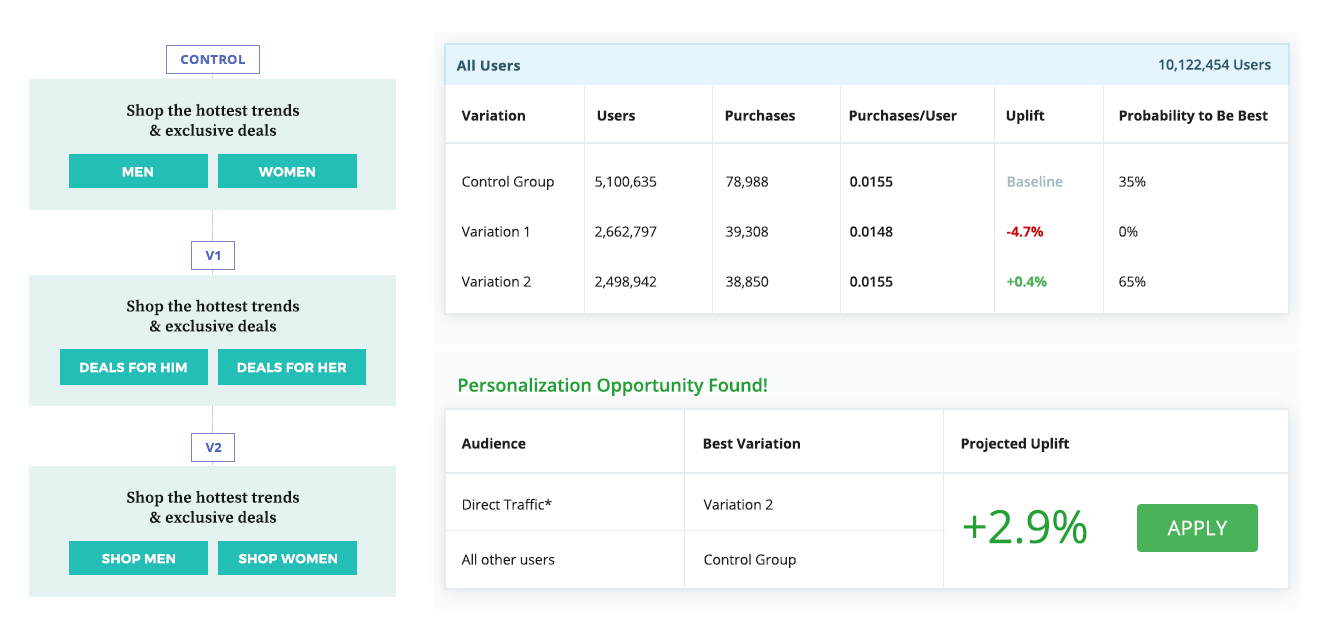
Эти примеры подчеркивают важность исследования и тщательного анализа результатов тестирования в разрезе разных сегментов аудитории. Только так вы сможете выявить скрытые возможности для оптимизации даже в тех экспериментах, где тестирование с ориентацией на среднестатистического пользователя (такого, кстати, не существует) не принесло ожидаемых результатов.
В большинстве ситуаций бывает достаточно быстрого анализа, но когда циклы тестирования идут один за другим, а приоритеты постоянно меняются бывает трудно выкроить время даже на это. Однако с ростом количества тестов, вариаций и сегментов проблема лишь усугубляется, и в результате анализ становится очень объемной задачей. Ну что, с этими знаниями, все еще хочется и дальше сохранять статус кво, читать результаты поверхностно и не делать ни шагу в сторону?
← Назад | Продолжение (Глава 15) →
Тест-анализ и тест дизайн
latest update of the page: 01-03-2023, 21:31 UTC
Тест-анализ
Тест-анализ = процесс поиска и рассмотрения информации, необходимой для тестирования. Обычно она есть у людей с хорошими знаниями о системе и способах её использования, в документации (требования, спецификации, описания архитектуры и интеграции и т.п).
Такая информация нужна для составления тест-кейсов.
Исполняющему роль тест-аналитика необходимо (в общем случае):
-
Знать, кто является причастными сторонами (т.н. стейкхолдерами): кто владелец проекта, владелец продукта, заказчики/клиенты, исполнители работ по проектированию, разработке, тестированию и сопровождению системы.
Ибо крайне важно понимать, кто будет поставщиком информации (например, архитекторы, аналитики, разработчики, админы/девопс), а кто будет потребителем наших информационных артефактов (например, проектные/продуктовые менеджеры и тестировщики). - Держать в голове для каких целей создан Продукт/Система, кто и каким образом будет его использовать.
- Выяснять суть реализации (общесистемной или конкретного инкремента): какова архитектура, какие компоненты дорабатываются.
- Определять необходимое и возможное тестовое покрытие (что будем тестировать и на какую «глубину»), необходимые виды тестирования.
- (опционально) Определить риски тестирования. Они способны серьёзно повлиять на оценку сроков тестирования.
- (опционально) Составить Матрицу трассировки требований
Тестовое покрытие
Тестовое покрытие = покрытие тестами требований к продукту/системе, выраженное в численном либо процентном соотношении. Тестовое покрытие является одной из основных метрик качества продукта.
Иногда под тестовым покрытием имеют в виду покрытие критериев приёмки, покрытие кода. Кто-то считает покрытие только автотестами.
Тестовое покрытие говорит о добротности тестирования, о степени доверия к производимому продукту, о наличие и масштабах «белых пятен», где выше риск пропуска ошибок.
Процесс определения покрытия кратко картинкой:

скачать схему в формате diagrams.net (бывший draw.io)
Итак, мы прошли этап определения причастных сторон, ознакомились с документацией, держим в голове архитектуру, требования к системе, критерии приёмки доработок.
Теперь надо определиться с объёмом тестирования и видами тестирования.
Проводим логическую декомпозицию Системы, определяя:
- сущности (задействованные чаще всего, самые важные), связи сущностей, модель их статусов/состояний, возможные действия с сущностями (CRUD, фильтрация, сортировка, поиск, экспорт, импорт, валидация, парсинг, копирование).
- бизнес-процессы, use cases (user scenarios, system scenarios), проходящие в продукте.
- входящую и исходящую интеграции, каким способом она происходит (ETL, RPC, REST API, file, MQ и т.д.) и с чем.
- ролевая модель — какие роли с какими правами; на какие бизнес-процессы, use cases и на работу с какими сущностями она распространяется.
- UI как те или иные виды экранных форм в web-, desktop-, mobile-приложении. Или даже TUI.
- CLI (command-line interface) и возможные команды приложению посредством командной строки.
- Варианты конфигурации приложения.
Теперь прикидываем какими видами тестирования с какими тест-сценариями это счастье можно покрыть:
| Вид тестирования | Примеры тестов |
|---|---|
| Функциональное позитивное (в т.ч. безопасности) |
|
| Функциональное негативное (в т.ч. безопасности) |
|
Нефункциональное:
|
|
В итоге получаем своего рода наброски (drafts) тест-кейсов, которые дальше уже далее потребуется детализировать по шагам.
Уже становится ПРИМЕРНО виден объём возможного тестирования, можно ПРИМЕРНО прикинуть сколько времени займёт как тест-дизайн по этим черновикам (детализация тест-кейсов), так и время прохождения всех этих тестов.
Заодно можно прикинуть какие из этих тест-кейсов целесообразно пустить потом в автоматизацию.
Трассировка требований и тест-кейсов
Матрица трассируемости требований (Requirement Traceability Matrix) = двумерная таблица, содержащая соответствие требований (user/business requirements, software requirements) и подготовленных тест-кейсов (test cases).
Основное её предназначение в отображении степени покрытия требований тест-кейсами.
Матрица может включать в себя параметры в зависимости от ваших нужд на проекте
- ID Бизнес-Требования (BR, Business Requirement) или Бизнес Варианта Использования (Business Use Case);
- суть Бизнес-Требования;
- (опционально) приоритет Бизнес-Требования;
- (опционально) приёмочный критерий Требования (acceptance criteria);
- (опционально) ID Функционального требования (FR, functional requirement) из Спецификации к Требованиям ПО (SRS) или ID Варианта Использования (UC, Use Case);
- (опционально) описание Функционального требования или Варианта Использования;
- ID тестового артефакта (Тест-кейса);
- (опционально) ожидаемый результат Тест-кейса (expected result);
- (опционально) номер Задачи на разработку из таск-трекера + её описание;
- (опционально) логический блок / модуль, к которому принадлежит Задача/Требование;
Примеры Матриц Трассировки:
-
# Block of feature Issue for development Acceptance criteria Priority Test-case 1 Create Creating User should be able to create new document High Test #1: Create document 2 User should not be able to create new document, if he has role = «Reviewer» High Test #14: Reviewer should not be able to create new doc 3 Print Document printing User should be able to print a document High Test #2: Print a document 4 .doc, .pdf, .docx, .rtf formats of a document should be able to be printed High Test #4: Check-list for doc formats N … … … Low / Medium / High link to TC -

(скачать таблицу в формате XLSX)

Для каждого Бизнес-Требования будет одно или несколько Функциональных (Системных) Требований, его реализующих. Соответственно, каждое системное требование должно иметь критерии приёмки, которые должны быть покрыты тестами.
Пример рабочего процесса, в котором присутствует создание Матрицы Трассировки:

скачать схему в формате diagrams.net (бывший draw.io)
Если вы используете таск-трекер Jira (и её плагины Zephyr Scale (Zephyr Squad) — Test Management for Jira) для тестовой документации и систему управления требованиями Сonfluence, то JIRA-таски и Confluence-страницы можно привязывать к тест-кейсам, в JIRA-тасках создавать связи с тестовыми прогонами, и такая трассируемость позволяет:
- визуализировать актуальное состояние реализации;
- разбивать требования на более атомарные и структурировать их;
- отслеживать, есть ли требования, на которые еще не запланирована разработка (пропуск реализации);
- отслеживать, реализовано ли требование в данный момент;
- отслеживать, покрыто ли требование тест-кейсом (пропуск тестирования);
- наглядно отображать приоритизацию требований.
Соотношение привязки Требования и Тест-кейса может быть:
- 1 к 1 (атомарное требование, которое покрывается одним тест-кейсом, данный тест-кейс покрывает только это требование);
-
1 к n (требование, которое покрывается несколькими тест-кейсами, данные тест-кейсы покрывают только это требование);
когда одно требование в матрице трассируемости покрывается несколькими тестами, это может говорить об избыточности тестирования. В таком случае надо проанализировать, насколько требование атомарно. - n к n (требование, которое покрывается несколькими тест-кейсами, данные тест-кейсы покрывают это и другие требования).
Программные комплексы для управления требованиями:
- (очень платное) IBM Rational DOORS
- (платное)(есть trial на 14 дней) Cradle
- (платное) DevProm Requirements. Один из функциональных блоков программного продукта Devprom ALM
- (платный) плагин RMsis для Atlassian JIRA
- (платный) плагин R4J для Atlassian JIRA
Риски качества
Риск качества (Quality risk) — потенциальный вид ошибки, способ поведения системы, при котором она, вероятно, не соответствует обоснованным ожиданиям качества системы, имеющимся у пользователя или заказчика. Это потенциальный, а не обязательный результат.
| Общие категории рисков качества | |
|---|---|
| Функциональность | Проблемы, в результате которых не работают конкретные функции |
| Нагрузка, производительность, объём | Проблемы обработки ожидаемых пиковых нагрузок при параллельной работе нескольких пользователей |
| Надёжность, стабильность работы | Проблемы, при которых система слишком часто зависает или долго не восстанавливается |
| Перегрузки, обработка ошибок и восстановление | Проблемы, возникающие ввиду превышения допустимых пиковых нагрузок или из-за обработки недопустимых условий (например, побочный эффект от сознательного внесения ошибок) |
| Обработка времени и дат | Ошибки в математических действиях с датами и временем, в их форматировании, в планируемых событиях и других операциях, зависящих от времени |
| Качество данных | Ошибки в обработке, извлечении и хранении данных |
| Производительность | проблемы с временем завершения задач при ожидаемой нагрузке |
| Локализация | проблемы, связанные с локализацией продукта, в том числе в обработке страницы символов, языковой поддержке, в использовании грамматики, словаря, а также в сообщениях об ошибках и файлах помощи |
| Безопасность | проблемы в защите системы и охраняемых данных от мошеннического и злонамеренного использования |
| Установка/перенос | ошибки, которые препятствуют поставке системы |
| Документирование | ошибки в руководствах по установке и работе с системой для пользователей и системных администраторов |
Из этого также следует вывод о том, насколько важно изучить требования заказчика, придерживаться их и здравого смысла (заказчик не всегда прав, иногда полезно намекнуть ему о потенциальных рисках в результате реализации какого-либо из его легкомысленных требований).
Риски тестирования
Основные риски тестирования:
-
Проектные — связанные с коммуникациями участников команды, инфраструктурой:
— изменение скоупа тестирования после проверки основных тест-кейсов
… -
Продуктовые — связанные только с тестируемыми функциями и тестовыми средам:
— отсутствие тестовых зон с заданной конфигурацей (медленные БД, (не)обезличенные БД, отсутствие каких-то тестовых данных)
— недопустимое время на ожидание подготовки тестовых зон со стороны Администраторов / DevOps
…
Тест дизайн
Проектирование тестов (test design) = процесс проектирования и создания тест-кейсов (тестовых случаев/сценариев/дел, case — юр. «дело»), в соответствии с определёнными ранее критериями качества, целями тестирования, критериями приёмки.
Тест-кейс
Тестовый случай (Test Case) = артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Этимология слова case восходит к юридиспруденции. Case — дело, случай.
В тестировании мы, по-сути, с помощью тест-кейсов, предоставляющих нам свидетельства и факты, поддерживаем аргументы, обосновывая ими заявления о том, что проверяемая Система/ПО/Продукт соответствуют требованиям.

скачать схему в формате diagrams.net (бывший draw.io)
Исчерпывающий формат тест-кейса
- Название (subject)
- Описание (description) — что проверяем, некие важные подробности
- Трассировка (tracing) — ссылки на таск и страницу с требованиями к проверяемой тест-кейсом функциональности, юзкейс, юзерстори ссылки на бегрепорты по тест-кейсу
-
Предусловия (preconditions), например:
- Учётные записи и настройки ролей: имеется такая-то учётная запись, JWT, так-то настроена аутентификация и авторизация, учётной записи назначены такие-то права/роли.
-
Развёрнуто и настроено: развёрнуто A,B,C, перечисление критически важных для теста атрибутов конфигурации.
Возможно, ссылка на репозиторий, регистр с контейнерами скрипты деплоя и инструкции при наличии - Данные: в Системах A,B,C (их БД) созданы такие-то экземпляры сущностей / имеются такие-то данные, которые понадобятся в процессе теста.
-
«Тело» тест-кейса, обычно в виде таблицы такого вида:
№ п/п Действие Ожидаемый результат Результат 1 Делаем вот это Видим вот это, это и это <успех / неудача, комментарий с подробностями фактического результата при неудаче> N … … …
Методы разработки тестов
В общем случае нам требуется протестировать некую функцию системы. Часто, данные для функции и сам путь исполнения функции подразумевают некоторую вариативность. Нижеперечисленные техники как раз помогают определиться с тем, как именно подступиться к тестированию вариативности всего этого добра.
Причина / Следствие (Cause/Effect)
Простая проверка действий и их результата. Как правило, ввод комбинаций условий (Причин) для получения ответа от системы (Следствие).
Например, вы проверяете возможность добавлять клиента, используя определённую экранную форму. Пользователю необходимо заполнить несколько полей — «Имя», «Адрес», «Номер Телефона» — а затем нажать кнопку «Добавить». Это Причина. После нажатия кнопки «Добавить» система добавляет клиента в БД и показывает его номер на экране — это Следствие.
Примерный алгоритм:
- Выискиваем и связываем причины и следствия в спецификации
- Учитываем «невозможные» сочетания причин и следствий
- Составляем «таблицу решений», где в каждом столбце указана комбинация входов и выходов, т.е. каждый столбец это готовый тестовый сценарий
- Приоритизируем решения.
Тестирование смены состояний (State Transition Testing)
Когда в Системе есть сущности (объекты), которые могут принимать различные состояния, то неплохо бы проверить, что предусмотренные требованиями переходы возможны к осуществлению, а непредусмотренные — невозможны.
Пример:
")
скачать схему в формате diagrams.net (бывший draw.io)
Подробнее: Тестирование на основе диаграмм состояний сущности (2015).
Таблица решений (Decision Table Testing)
Способ компактного представления модели со сложной логикой. Устанавливает связь между условиями (входными параметрами) и результатом (действиями Системы). Определить/записать все условия. Просчитать возможное количество комбинаций условий. Заполнить комбинации. Записать действия. Убрать лишние комбинации.
Например:
")
Тестирование путей (Path Testing)
Часто под ним имеется в виду метод тестирования белого ящика Control Flow Testing (тестирование управляемого потока), в котором тест-кейсами покрываются все логические потоки ПО. Подробнее можно прочитать здесь:
- Path Testing & Basis Path Testing with EXAMPLES
- Control Flow Testing
Однако, его же можно использовать для покрытия тестами логики тестируемой системы, если у нас имеются BPMN-диаграммы и UML activity-диаграммы, описывающие процессы, проходящие в ней.
Количество сценариев будет зависеть от количества логических узлов ветвлений. Если условия ветвлений зависят от значений каких-то данных, то скорее всего, для каждого тест-сценария необходимо, опираясь на диаграмму, определить набор входных данных.
Очень упрощённо:

Посмотреть/послушать о такого рода применении метода можно здесь Где логика?! История тестирования одного микросервиса (Денис Кудряшов, Leroy Merlin, 2020), где докладчик скомбинировал этот метод с вышеупомянутой таблицей решений (Decision Table Testing).
Определение классов эквивалентности (Equivalence Partitioning)
и Анализ Граничных Значений (Boundary Value Analysis)
- Если область определения параметра — диапазон каких-то упорядоченных данных, то имеет смысл выделение трёх т.н. классов эквивалентности: «слева» от диапазона (невалидные значения), «внутри» диапазона (валидные значения) и «справа» от диапазона (снова невалидные). При выделении классов нужно использовать включающие границы с целью однозначности и точности: одно и то же значение не может относиться к двум классам одновременно.
Анализ граничных значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения. - Если область определения это набор неупорядоченных данных, то всегда можно выделить как минимум два класса — валидные и невалидные значения.
Полученное разбиение можно «дробить» дальше. Например, множество латинских букв можно разбить на два подмножества: латинница в верхнем и нижнем регистре.
Пример:

Попарное тестирование (Pairwise Testing)
Метод, основывающийся на тестировании комбинаций, с учётом того, чтобы каждое значение всех параметров хотя бы единожды сочеталось в проверках с другими значениями остальных параметров. Метод сильно уменьшает объём тестирования, но увеличивает вероятность пропуска дефекта.
Пример оптимизации количества тестов этим методом:
")
Подробнее: ПОПАРНОЕ ТЕСТИРОВАНИЕ (PAIRWISE TESTING) (2018).
Предугадывание ошибки (Error Guessing)
Это когда тест-аналитик/тестировщик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «здесь пользователь должен ввести код». Тест-аналитик выдвигает предположения: «Что, если я не введу код?», «Что, если я введу неправильный код?» и так далее. Это и есть предугадывание ошибки.
Иногда, под этим методом имеется в виду своеобразная «чуйка» у хорошо знающего систему тест-аналитика/тестировщика, когда при проверке функциональности X он даже неосознанно (опыт!) решает «на всякий случай» проверить дополнительно ещё функциональность Y, где могут «всплывать» ошибки.
Тесно связано с понятием импакт-анализа.
Исчерпывающее тестирование (Exhaustive Testing)
Бескомпромиссный случай — в пределах этой техники вы должны проверить реакцию Системы на все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода часто не представляется возможным, из-за огромного количества входных значений.