Распознать объекты на изображении онлайн бесплатно
Обнаруживает объекты на изображениях бесплатно на любом устройстве, с помощью современного браузера, такого как Chrome, Opera или Firefox
При поддержке aspose.com и aspose.cloud
Добавить метки
Добавить баллы
Порог: %
Цвет:
Допустимые метки:
Заблокированные метки:
Aspose.Imaging Распознавание позволяет легко обнаруживать и классифицировать объекты на растровых и векторных изображениях.
Распознавание — это бесплатное приложение, основанное на Aspose.Imaging, профессиональном .NET / Java API, предлагающее расширенные функции обработки изображений на месте и готовое для использования на стороне клиента и сервера.
Требуется облачное решение? Aspose.Imaging Cloud предоставляет SDK для популярных языков программирования, таких как C#, Python, PHP, Java, Android, Node.js, Ruby, которые созданы на основе Cloud REST API и постоянно развиваются.
Aspose.Imaging Распознавание
- Обнаруживает объекты на изображении с помощью метода Single Shot Detection(SSD)
- Обнаруженные объекты обводятся прямоугольниками и могут быть подписаны
- Полный список поддерживаемых объектов содержит более 180 элементов
Как распознать объекты на изображении
- Кликните внутри области перетаскивания файла, чтобы выбрать и загрузить файл изображения, или перетащите файл туда
- Нажмите кнопку Старт, чтобы начать процесс обнаружения объектов.
- После запуска процесса на странице появляется индикатор, отображающий ход его выполнения. После того, как все объекты будут обнаружены, изображение с результатами появится на странице.
- Обратите внимание, что исходные и получившиеся изображения не хранятся на наших серверах
Часто задаваемые вопросы
-
❓ Как я могу обнаружить объекты на изображении?
Во-первых, вам нужно добавить файл изображения: перетащить его на форму или по ней чтобы выбрать файл. Затем задайте настройки и нажмите кнопку «Старт». КАк только процесс распознавания будет завершен, полученное изображение будет отображено.
-
⏱️ Сколько времени требуется для распознавания объектов на изображении?
Это зависит от размера входного изображения. Обычно это занимает всего несколько секунд
-
❓ Какой метод обнаружения объектов вы используете?
В настоящее время мы используем только метод Single Show Detection (SSD)
-
❓ Какие объекты вы можете обнаружить на изображениях?
-
💻 Какие форматы изображений вы поддерживаете?
Мы поддерживаем изображения форматов JPG (JPEG), J2K (JPEG-2000), BMP, TIF (TIFF), TGA, WEBP, CDR, CMX, DICOM, DJVU, DNG, EMF, GIF, ODG, OTG, PNG, SVG и WMF.
-
🛡️ Безопасно ли обнаруживать объекты с помощью бесплатного приложения Aspose.Imaging Object Detection?
Да, мы удаляем загруженные файлы сразу после завершения операции обнаружения объектов. Никто не имеет доступа к вашим файлам. Обнаружение объектов абсолютно безопасно.
Когда пользователь загружает свои файлы из сторонних сервисов, они обрабатываются таким же образом.
Единственное исключение из вышеуказанных политик возможно, когда пользователь решает поделиться своими файлами через форум, запросив бесплатную поддержку, в этом случае только наши разработчики имеют доступ к ним для анализа и решения проблемы.
При работе с электронными офисными документами иногда приходится вставлять в текст символы, которых нет ни на одной из существующих типов клавиатур. В этом случае, при условии, что вы работаете в Microsoft Word, приходится открывать окошко «Символ» и выискивать в обеих списках нужный значок. Но есть и более быстрый способ отыскать требуемый символ — в последней версии Word имеется функция, позволяющая найти его печатную версию, нарисовав мышкой, стилусом или пальцем.
Переключитесь в Word на вкладку «Вставка», откройте меню элемента «Уравнение» и выберите «Рукописное уравнение».
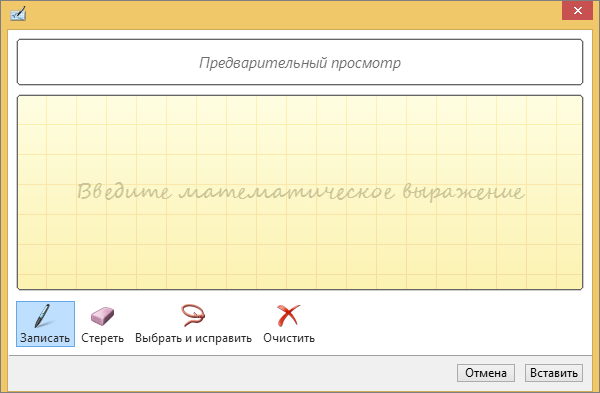
В открывшемся окошке вам будет предложено нарисовать символ и если таковой будет найден, то он отобразится в поле чуть выше области рукописного ввода. Сразу отметим, что этот способ не лишён недостатков. И хотя он и позволяет вводить по нескольку символов сразу, при этом не даётся ни намёка на то, что за значок появился на экране.
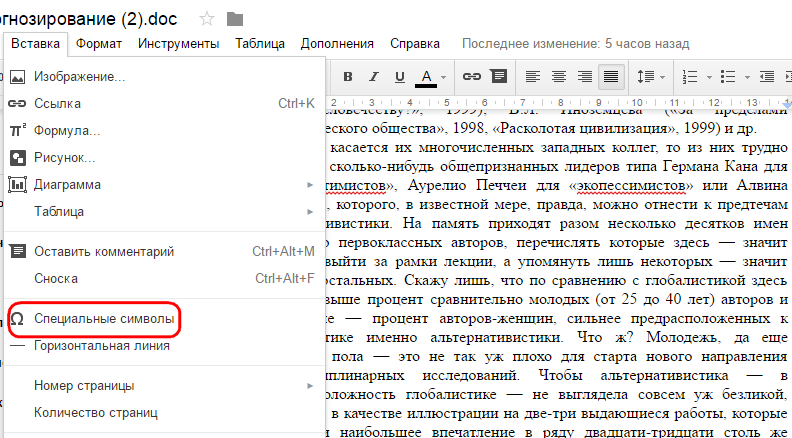
Спецсимволы в Google Docs
Ещё большими возможностями в этом плане обладает веб-приложение Google Docs. Оно не только умеет распознавать введённые от руки спецсимволы, но и предоставляет их краткое описание. Точность распознавания символов в Google Docs немного выше, заодно поддерживается кодировка в UTF. Кроме того, пиктограмм здесь намного больше. Воспользоваться функцией можно, перейдя в раздел Вставка -> Специальные символы.

 Специальные символы в сервисе Mausr
Специальные символы в сервисе Mausr
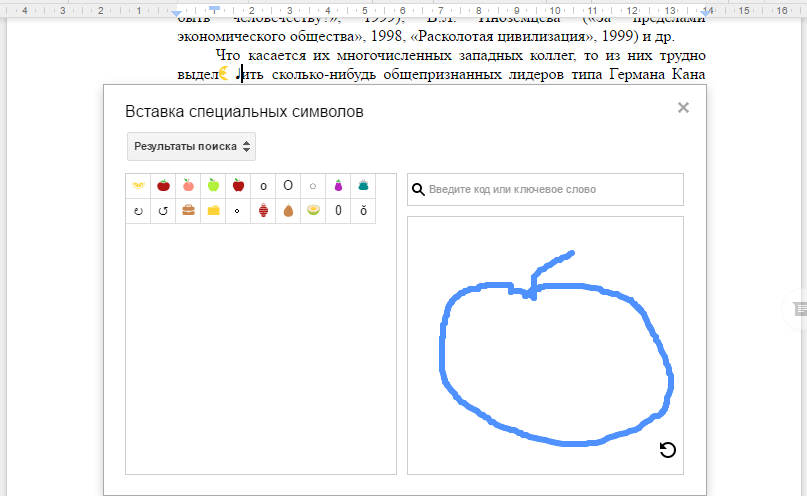 Специальные символы в сервисе Mausr
Специальные символы в сервисе MausrЭтот расположенный по адресу www.mausr.com веб-инструмент не столь точен как Google Docs, но своё предназначение он вполне оправдывает. Принцип тот же самый — в специальной области от руки рисуем символ, печатную версию которого хотим получить, а Mausr ищет его в своей базе и выдаёт близкие результаты с кратким описанием.
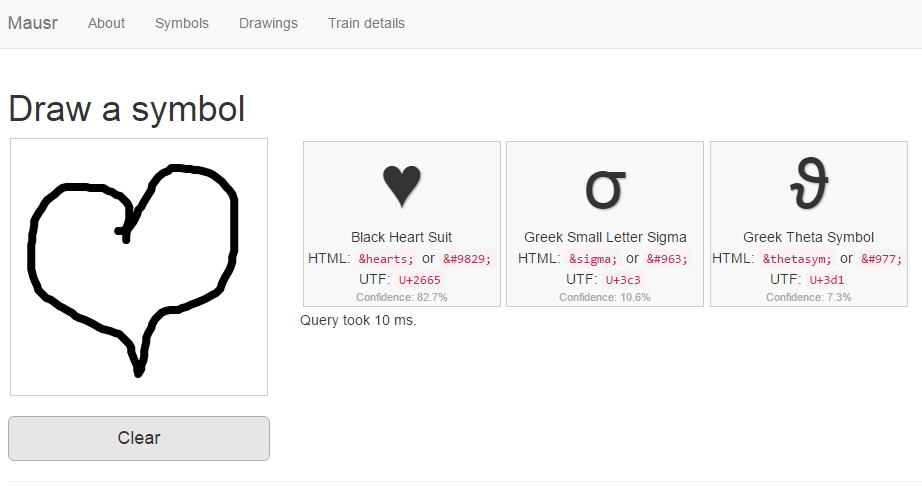
Нарисованный символ должен быть как можно более точным, в противном случае сервис покажет совсем не то, что вы ожидали.
![]() Загрузка…
Загрузка…
Математические, статистические и алгебраические символы трудно запомнить по имени, и поскольку день, когда какая-либо из этих дисциплин спасет вашу жизнь, еще не наступил для большинства людей, еще труднее вспомнить имя с помощью строчных или заглавных греческих букв или любых других такие символы. Shapecatcher — это веб-приложение, которое может помочь вам найти определенные символы Юникода, просто набросав их форму. В настоящее время приложение содержит около 10877 важных символов Unicode в своей базе данных, которые сравниваются с вашим рисунком и анализируются на предмет сходства. Приложение основано на простом механизме распознавания символов, который сравнивает ваш эскиз с его базой данных символов и отображает все возможные совпадения. Приложение в большинстве случаев найдет искомый символ, но в зависимости от того, насколько хорошо вы его нарисовали и сколько похожих символов существует в базе данных, правильный результат может не оказаться в верхней части списка результатов. .
Нарисуйте что-нибудь в поле слева, нажмите Распознавать и позвольте Shapecatcher помочь вам найти наиболее похожие символы Unicode из его постоянно растущей базы данных. Список результатов будет отображаться под ящиком для рисования со всеми возможными совпадениями, которые Shapecatcher смог найти в своей базе данных. Он также предоставляет информацию о символах, включая символ, имя, его шестнадцатеричное значение и язык происхождения.
Список результатов будет отображаться под ящиком для рисования со всеми возможными совпадениями, которые Shapecatcher смог найти в своей базе данных. Он также предоставляет информацию о символах, включая символ, имя, его шестнадцатеричное значение и язык происхождения.
Приложение также просит вас оценить предложенные символы, чтобы определить, насколько хорошо они сочетаются с тем, что вы нарисовали. Это необязательно, но было бы неплохо оценить правильный символ и помочь улучшить работу других пользователей. Shapecatcher также имеет опцию Unicode List, отображаемую в верхней части страницы, но сейчас она все еще дорабатывается из-за того, что веб-приложение находится на стадии бета-тестирования. По словам разработчика, по завершении он покажет наборы символов, поддерживаемые Shapecatcher. Японские, корейские и китайские символы в настоящее время не поддерживаются, но, надеюсь, они будут добавлены в базу данных.
При рисовании символов лучше не оставлять линии, которые должны быть соединены (например, ноги символа Пи), отключенными. Если вы не нашли нужный символ, попробуйте нарисовать его еще раз. Хотя у вас может не получиться нарисовать идеальные круги, попробуйте рисовать хорошие линии. Это удобное веб-приложение может вызвать особый интерес у студентов и учителей.
Посетить Shapecatcher
Во время серфинга в Интернете (или даже в автономном режиме) вы, вероятно, сталкивались с множеством символов. Некоторые из них являются общими, но для других вам, вероятно, нужна помощь в определении символа.
В Интернете есть ресурсы, чтобы помочь. Мы покажем вам, как узнать, что означает символ, используя различные методы.
1. Посетите сайт Symbols.com

Удачно названный Symbols.com — отличное место для начала поиска. Наряду с избранными подборками и категориями на главной странице, вы можете использовать поисковую систему по символам, чтобы найти то, что вы ищете. Просто введите запрос вверху, и вы увидите символы, которые ему соответствуют.
Прекрасно, если вы хотите найти символ по тексту (например, ищите символ «кошерный»). Но во многих случаях вы увидите символ и удивитесь его значению. К счастью, сайт предлагает другие способы идентификации символа.
В нижнем левом углу страницы вы увидите раздел Графический указатель . Это позволяет вам искать символ на основе его характеристик. Он предоставляет несколько простых раскрывающихся списков, позволяющих указать, является ли фигура открытой или закрытой, имеет ли она цвета, являются ли линии изогнутыми или прямыми и т. П.
Введите столько информации, сколько вы знаете, затем нажмите « Поиск», чтобы найти символы, соответствующие вашим критериям. Если это не поможет вам найти то, что вы ищете, вы можете использовать категории Символов для просмотра по группам, таким как знаки валюты , символы предупреждения и другие.
В противном случае вы можете искать в алфавитном порядке, используя буквы в верхней части экрана. Если вы не ищете что-то конкретное, кнопка Случайный может помочь вам узнать что-то новое.
2. Нарисуйте символ, чтобы узнать его значение

Если вы озадачены тем, что вы видели в автономном режиме, имеет смысл найти символ на картинке. Вы найдете несколько сайтов, которые предлагают эту функциональность.
Одним из них является Shapecatcher . Просто нарисуйте символ, который хотите найти, с помощью мыши или сенсорного экрана и нажмите кнопку « Распознать» . Сервис вернет символы, соответствующие вашему рисунку.
Если вы не видите совпадения, нарисуйте его еще раз и попробуйте еще раз. На сайте используются только бесплатные шрифты Unicode, поэтому он может содержать не все возможные символы. Попробуйте Mausr для аналогичной альтернативы, если эта не работает для вас.
3. Поиск символов с помощью Google

Если во время работы в Интернете вы встретите незнакомый значок, вам не нужно беспокоиться о его поиске на сайте с символьным идентификатором. Просто запустите поиск по символам в Google, и вы получите ответ в течение нескольких секунд.
В Chrome, наряду с большинством других браузеров, вы можете легко найти в Google любой текст. Просто выделите его на странице, щелкните правой кнопкой мыши и выберите « Поиск в Google» для «[term]» . Откроется новая вкладка с поиском в Google по этому термину. Если в вашем браузере по какой-то причине этого нет, вы можете просто скопировать символ, как любой другой текст, и вставить его в Google.
В любом случае, Google должен указать вам правильное направление, чтобы найти значение этого символа.
4. Просмотрите список символов

Unicode (стандарт для кодирования текста) поддерживает ряд общих символов, как они могут выглядеть как стандартный текст. Хотя они не имеют специальных клавиш на стандартной клавиатуре, вы можете использовать ALT-коды для ввода символов. вместо этого.
Если вы не можете найти символ, который вы ищете, используя любой из вышеперечисленных методов, вы можете найти его, просматривая все символы, которые поддерживает Unicode. Посмотрите на список Compart «других символов» символов Unicode, и вы можете найти тот, который вас интересует. Если вы предпочитаете альтернативу, посмотрите таблицу символов Unicode .
Конечно, не все символы поддерживаются в Юникоде. Дорожные знаки, религиозные символы и повседневные потребительские символы не являются частью этого. Возможно, вам придется покопаться в странице со списком символов Википедии для таких иконок.
5. Изучите символы эмодзи

Хотя вы можете утверждать, что они не являются технически символами, смайлики часто вводят людей в заблуждение. В конце концов, есть сотни смайликов, которые нужно отслеживать, плюс изменения в дизайне и новые постоянно появляющиеся.
Во-первых, мы рекомендуем ознакомиться с нашим руководством по значениям смайликов для лица Это поможет вам освоить некоторые наиболее распространенные из них.
Если у вас все еще есть вопросы по поводу символов эмодзи, загляните в Emojipedia . Здесь вы можете искать определенные эмодзи, просматривать по категориям и читать новости эмодзи. Страница каждого смайлика рассказывает вам не только о его официальном значении, но и о том, для чего он часто используется.
6. Используйте инструмент поиска символов на бирже

Мы завершаем наше обсуждение открытия значений символов, упоминая финансовые символы. Они явно отличаются от символов, упомянутых выше, но они все еще являются типом символов, которые вы, возможно, захотите найти.
MarketWatch , один из наших любимых финансовых сайтов, чтобы не отставать от рынка , предлагает удобный инструмент поиска символов. Если вы знаете интересующий вас символ, введите его, чтобы узнать подробности об этой компании. Если вы не уверены, что это, введите название компании, и вы увидите совпадения для него.
После того как вы попали на страницу компании, вы можете увидеть все виды данных, такие как тренды, новости и конкуренты.
Знание значения любого символа
Теперь вы знаете, куда обращаться, когда сталкиваетесь с незнакомым символом. Будь то быстрый поиск в Google или поиск чего-то, что вы видели в автономном режиме, вам не нужно догадываться, что означают эти значки.
У Facebook есть свой набор символов, которые вы можете не понять. Если это так, взгляните на наш справочник по многим символам
Распознавание символов
Время на прочтение
9 мин
Количество просмотров 6.3K

Работа с изображениями — одна из самых распространенных задач в машинном обучении. Мы покажем пример обработки изображения, получение матриц (тензоров) чисел, подготовку данных обучающего множества, пример архитектуры нейронной сети.
Работа с изображениями является одной из самых распространенных задач в машинном обучении. Обычная картинка, воспринимаемая человеком однозначно, для компьютера не имеет никакого смысла и интерпретации, только если нет предварительно обученной нейронной сети, которая способна отнести изображение к одному определенному классу. Для работы такой нейронной сети необходимо ее обучение на тренировочных данных, изображениях предварительно обработанных и поданных на вход нейронной сети в виде матрицы чисел, характеризующих определенный тон (цвет) на определенной позиции в изображении. В этой статье приводится пример обработки изображения, получение матриц (тензоров) чисел, подготовка данных обучающего множества, пример архитектуры нейронной сети.
Постановка задачи: имеются цветные изображения букв и цифр (CAPTCHA). Необходимо распознать буквы и цифры, находящиеся на изображениях. Последовательность решения задачи:
-
анализ изображений;
-
подготовка данных;
-
генерация данных;
-
тренировка нейронной сети, предсказание ответов.
")
Проводим предварительный анализ 100 изображений в формате «.png». Изображения состоят из 29 уникальных символов «12345789абвгдежзиклмнопрстуфя». Символы могут быть повернуты на определенный угол (от -1° –+15°), могут быть смещены по горизонтали и вертикали, символы могут накладываться друг на друга. Символы представлены в цвете, все три символа могут иметь различные цвета. На фоне имеются более мелкие символы в светлых оттенках (шум на изображении). Для анализа, вывода и обработки изображений понадобятся библиотеки языка python 3 opencv, matplotlib, pillow. Определим положение символов на изображении путем подбора разделяющих линий:
import cv2 # импортируем библиотеку для раб.с графикой
image = cv2.imread('.Captcha.png') # читаем изоб. Результат numpy array
# рисуем линию (img, (x1, y1), (x2, y2), (255, 255, 255), 4) –
# изображение на котором рисуем, точка начала линии, точка конца линии,
# цвет линии цветовая модель BGR, толщина линии.
image = cv2.line(image, (14, 0), (14, 50), (0, 0, 255), 1)
…
# для вывода можно задать функцию, параметры прочитанное иозбр., имя окна
def view_image(image, name_wind='default'):
cv2.namedWindow(name_wind, cv2.WINDOW_NORMAL) # # создаем окно вывода
cv2.imshow(name_wind, image) # # в окно передаем изображение image
cv2.waitKey(0) # # ждем нажатия любой клавиши, 0 нет таймера.
cv2.destroyAllWindows() # # уничтожение (закрытие) всех окон
view_image(image) # # вызов функции вывода с передачей прочитанного файла
Так же для вывода удобно использовать matplotlib, особенность библиотеки в работе с моделью RGB: передав данные модели BGR вывод будет отличаться, интенсивный красный станет интенсивным синим и наоборот, зеленый не изменится. Для корректного вывода в matplotlib (если цвета имеют значения) необходимо поменять местами матрицы цветов синего и красного.
Перебором изображений с расстановкой разделяющих линий, определим место положение символов. На изображениях каждый символ находится в своем диапазоне. Для всех символов верхняя граница находится на 3 строке, нижняя на 47. Вертикальные границы (за которые символы не выходят): для первого символа 14–44 колонка, для второго символа: 32–62 колонка, для третьего символа: 48 –72. Изображение при чтении библиотекой opencv представляется в виде тензора numpy array, размерностью (50, 100, 3). Изображение представлено в 3 массивах, состоящих из 50 строк и 100 столбцов. Каждый из трех массивов отвечает за свой цвет BGR (blue синий, green зеленый, red красный), каждый из 3-х массивов находится в диапазоне от 0-255.

Данные такого вида не совсем удобны для дальнейшей обработки цветов. Так как символ имеет не четкий цвет, а сумму цветов, к краям более светлый тон, сумма цветов меняет свои значения. Для выделения символа определенного цвета необходимо будет указывать диапазоны для трех цветов B(n-m) G(k-l) R(y-z). Вместо этого проще представить изображение в другой цветовой модели HSV (Hue, Saturation, Value — тон, насыщенность, яркость). В библиотеке opencv единицы измерения Heu 0 – 179, S 0 – 255, V 0 –255. При данной цветовой модели достаточно указать сектор цвета Heu и для всех символов указать постоянные значения S 10 – 255, V 0 – 234, отсекая тем самым фон и шумовые изображения, представленные в более светлых тонах.
 и HSV")
# # преобразование из BGR цветовой модели в HSV
image = cv2.imread('.captcha_png')
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)HSV представляет собой тензор (50, 100, 3) (3 матрицы numpy array размерностью (50, 100), 50 одномерных массивов, содержащие 100 значений). Индексы матриц — [:, :, 0] Hue, [:, :, 1] Saturation, [:, :, 2] Value.

Отобразим матрицы в градиентах серого (0 – черный 255 – белый).

[:,:, 0] Тон, отсутствует белый т.к. диапазон до 179, приблизительный разброс цветов 160 – 179 и 0~30 красный цвет, 60 ~ 100 зеленый, 110 ~ 150 синий. На первом изображении цифра 9 более светлая т.к. оттенок красного попал в диапазон от 160, на втором изображении буква «м» черная т.к. оттенок попал в диапазон 0~30

[:,:, 1] Насыщенность, фон и шум на изображении представлен в светлых, пастельных тонах значения 0~10, символы имеют более выраженный цвет >10

[:,:, 2] Яркость, изображение светлое следовательно яркость фона 240 ~ 255, символы более темнее имеют значения < 240.
На основании матриц S и V (насыщенность и яркость), можно получить фильтры для отделения символов от фона и от шума в матрице Hue (тон).
mask_S = image[:, :, 1]< 10; mask_V = image[:, :, 1] > 240Результат: две матрицы булевых значений (50, 100) [[True, False, ..,], …, [..]]. Значению истина соответствует фон и шум. Если применить эти фильтры к матрице тон (Hue) и придать значениям, соответствующим истина 255, матрица будет содержать значения 0-179, 255 – удобно для дальнейшей фильтрации (дальнейшая работа только с матрицей тон, Hue).
# значение 255 не попадает в диапазон матрицы 0 - 179
image[:, :, 0][mask_S] = 255 ; image[:, :, 0][mask_V] = 255
Следующий этап — отделение символов друг от друга. Задаем диапазон, в котором находится символ.

img_char1 = image[3: 47, 14: 44, 0].copy()
img_char2 = image[3: 47, 32: 62, 0].copy()
img_char3 = image[3: 47, 48: 78, 0].copy()Для выделения каждого символа и удаления части соседнего символа, отсекаем область нахождения соседнего символа, находим количество значений соответствующих тонам в матрице (максимальное количество значений имеет число 255 фон (500 – 800 значений в матрице), следующее по количеству значений будет основной тон символа, единичные значения будет иметь оставшийся не отфильтрованный шум). На основании основного тона символа находим диапазон оттенков N -10, N + 10.

Оставляем часть 1 и 3 символа не попадающее в область 2 символа. Получаем матрицы, отвечающие за тон.
# преобразуем матрицу в массив значений, посчитаем количество значений
val_count_1 = img_char1[3: 47, 14: 32, 0].copy().reshape(-1)
val_color_hue_1 = pd.Series(val_count_1).value_counts()
# val_color_hue_1 ->255 – 741, 106 – 11, 104 – 11, 20 – 1, 99 – 1.
val_color_hue_1 = pd.Series(val_count_1).value_counts().index[1]
# числа тонов являются индексами, устанавливаем сектор тона Hue -10, +10.
val_color_char_hue_1_min = val_base_hue_1 – 10 = 106 - 10 = 96
val_color_char_hue_1_max = val_base_hue_1 + 10 = 106+ 10 = 116На матрицы Hue для символов 1, 3 накладываем фильтр, значения где тон попадает в указанный диапазон равны 0, иначе 255.
mask_char1 = (img_char1> 96) & (img_char1<116)
img_char1[~mask_char1] = 255 # где не символ (полная область определения) img_char1[mask_char1] = 0 # где символ
Необходимо привести значения к 0 и 1 и инвертировать матрицу.
img_char1[img_char1 == 0] = 1; img_char1[img_char1 == 255] = 0Из 2-го символа, находящегося в центре изображения, удаляем части 1 и 3 символа путем определения частей матриц, пересекающих 2-й символ и приравнивании к 255 тех значений матрицы 2, где матрицы 1 и 3 не равны нулю.

Проводим аналогичные преобразования матрицы символа 2. Результат матрицы символов 1, 2, 3 – со значениями 0, 1. При выводе изображения имеют пропуски, остатки шума. Проводим фильтрацию, дополнительное преобразование инструментами opencv, указываем ядро (окно матрицы) которое проходит по матрице символов и при нахождении рядом заполненных пикселей и пропусков, заполняет пропуски
kernel = np.ones((3, 3), np.uint8)
closing = cv2.morphologyEx(np_matrix, cv2.MORPH_CLOSE, kernel)
Определяем центры символов, перемещаем символы в центр массива добавляя и удаляя строки, столбцы, заполненные нулями.

Разработан алгоритм выделения символов из изображения. Для дальнейшего определения значения символа построим и обучим нейронную сеть. Для обучения нейронной сети скачиваем ~100 экземпляров картинок выделяем из них символы, размечаем картинки вручную. Получаем 300 экземпляров размеченных данных (массивы 44×30 содержащие числа 0 и 1). Этого количества данных недостаточно. Определяем и скачиваем шрифт, которым отображаются символы на картинках. Воспользовавшись библиотекой pillow языка python, размещаем символы шрифта на изображении 44×30, задаем смещение и поворот символов случайным выбором из заданных значений, преобразуем в массив nympy array. Формируем выборку данных из сгенерированных данных и данных размеченных вручную.
shift_x = [1, 1, -1, -1, -2, 2, 0, 0, 0]
shift_y = [1, 1, -1, -1, -2, 2, 0, 0, 0]
rotor_char = [15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, -1]
char = '12345789абвгдежзиклмнопрстуфя'
# в цикле генерируем данные – ~10_000 – 60_000
shift _x_r = random.choice(shift_x)
shift _y_r = random.choice(shift_y)
rotor_r = random.choice(rotor_char)
char_r = random.choice(char)
train_x = []
train_x.append(char)
train_x = np.array(train_x)
train_x = train_x.reshape(train_x.shape[0], train_x[1], train_x[2], 1)
Тренировочный набор данных представляет собой тензор размерностью (50000, 44, 30, 1), дополнительная размерность (1) для нейронной сети.
Каждому экземпляру тренировочной выборки соответствует экземпляр из массива ответов: char_y = [0, 4, …, 29] – 50_000 (цифры 0-29 ключи словаря символов
char = '12345789абвгдежзиклмнопрстуфя' # 29 позиций
dict_char = {char[i]: i for i in range(len(char))}
dict_char_reverse = {i[1]: i[0] for i in dict_char.items()}
Приведем данные предсказания к виду унитарный код (one-hot encoding). Преобразуем численные значения в массив, имеющий длину 29. Массив состоит из нулей и одной единицы. Позиция единицы соответствует кодируемому символу. Например, буква «а» будет иметь вид ‘000000000100000000000000000000’.
Img_y = utils.to_categorical(Img_y)
# пример 1 -> (array( [1, 0, 0, 0, …, 0, 0], dtype=float32)
# пример 2 -> (array( [0, 1, 0, 0, …, 0, 0], dtype=float32)
Разбиваем полученные данные на тренировочный набор и тестовый.
x_train, x_test, y_train, y_test = sklearn.train_test_split(
out_train_x_rsh, out_train_y_sh,
test_size=0.1, shuffle=True)
Для распознавания символов необходимо построить нейронную сеть, так как данные похожи на учебный набор mnist (рукописные цифры 28×28) на ресурсе kaggle находим примеры архитектуры нейронной сети дающие хороший результат. Архитектура нейронной сети:
# Определим простую модель
Import tensorflow as tf
def model_detection():
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(input_shape=(44,30, 1), filters=32,
kernel_size=(5, 5), padding='same', activation='relu'),
tf.keras.layers.Conv2D( filters=32, kernel_size=(5, 5),
padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv2D( filters=64, kernel_size=(3, 3),
padding='same', activation='relu'),
tf.keras.layers.Conv2D( filters=64, kernel_size=(3, 3),
padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(29, activation=tf.nn.softmax)])
model.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
returnmodel
# создадим экземпляр модели
model = model_detection()
Зададим параметр, при улучшении которого модель сохраняется (valaccuracy).
checkpoint = ModelCheckpoint('captcha_1.hdf5', monitor='val_accuracy',
save_best_only=True, verbose=1)
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test),
verbose=1, callbacks=[checkpoint])
После тренировки сохраняются веса модели с наилучшими показателями valaccuracy, доли верных ответов. Дальнейшая работа программы: на вход подается изображение, которое обрабатывается ранее описанным алгоритмом. Результат обработки — numpy array (массив). Далее инициализируется модель, загружаются веса ранее обученной модели. На вход модели подают данные (1, 2, 3 символ). В результате модель выдает вероятность того или иного символа. Приняв за верный ответ позицию с наибольшей вероятностью из словаря «значение – символ» получаем символьное предсказание модели.
model2 = model_detection() # инициализируем
model2.load_weights('captcha_1.hdf5') # загружаем веса
prediction_ch_1 = model2.predict(char_1) # массив 29 значений вероятностей
# позиция на которой наибольшая вероятность, ключ к словарю ответов
prediction_ch_1 = np.argmax(prediction_ch_1, axis=1)
# из словаря ключ число, значение цифра или буква получаем ответ
dict_char_reverse[prediction_ch_1]
Данный алгоритм обрабатывает цветные изображения, на которых находятся символы букв и цифр, результат распознавания символов нейронной сетью 95% (точность), распознавание каптчи 82% (точность). На примере разбора алгоритма распознавания символов можно заметить, что основную долю разработки занимает подготовка, обработка и генерация данных. Выбор архитектуры и обучение нейронной сети является важней частью задачи, но не самой затратной по времени. Вариантов решения задачи распознавания цифр, букв, изображений предметов и т.п. множество, в данной статье приведен лишь один из примеров решения, показаны этапы решения, трудности, с которыми можно столкнуться в результате работы и примеры их преодоления. А как Вы работаете с каптчами?