Автоопределение кодировки текста
Время на прочтение
6 мин
Количество просмотров 51K

Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandiacpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
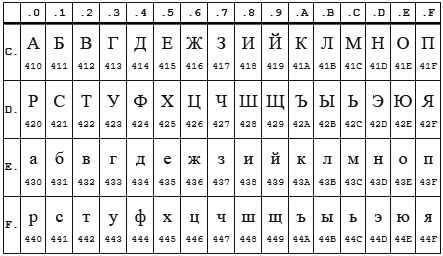
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
//test input interfase
if r == nil {
return ASCII, nil
}
//make slice of byte from input reader
buf, err := bufio.NewReader(r).Peek(ReadBufSize)
if (err != nil) && (err != io.EOF) {
return ASCII, err
}
...вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File
res, err := CodePageDetect(data)В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Yes is a most frequent question, and this matter is vague for me and since I don’t know much about it.
But i would like a very precise way to find a files Encoding.
So precise as Notepad++ is.
![]()
Cœur
36.8k25 gold badges192 silver badges262 bronze badges
asked Sep 29, 2010 at 20:02
![]()
Fábio AntunesFábio Antunes
16.9k17 gold badges73 silver badges96 bronze badges
7
The StreamReader.CurrentEncoding property rarely returns the correct text file encoding for me. I’ve had greater success determining a file’s endianness, by analyzing its byte order mark (BOM). If the file does not have a BOM, this cannot determine the file’s encoding.
*UPDATED 4/08/2020 to include UTF-32LE detection and return correct encoding for UTF-32BE
/// <summary>
/// Determines a text file's encoding by analyzing its byte order mark (BOM).
/// Defaults to ASCII when detection of the text file's endianness fails.
/// </summary>
/// <param name="filename">The text file to analyze.</param>
/// <returns>The detected encoding.</returns>
public static Encoding GetEncoding(string filename)
{
// Read the BOM
var bom = new byte[4];
using (var file = new FileStream(filename, FileMode.Open, FileAccess.Read))
{
file.Read(bom, 0, 4);
}
// Analyze the BOM
if (bom[0] == 0x2b && bom[1] == 0x2f && bom[2] == 0x76) return Encoding.UTF7;
if (bom[0] == 0xef && bom[1] == 0xbb && bom[2] == 0xbf) return Encoding.UTF8;
if (bom[0] == 0xff && bom[1] == 0xfe && bom[2] == 0 && bom[3] == 0) return Encoding.UTF32; //UTF-32LE
if (bom[0] == 0xff && bom[1] == 0xfe) return Encoding.Unicode; //UTF-16LE
if (bom[0] == 0xfe && bom[1] == 0xff) return Encoding.BigEndianUnicode; //UTF-16BE
if (bom[0] == 0 && bom[1] == 0 && bom[2] == 0xfe && bom[3] == 0xff) return new UTF32Encoding(true, true); //UTF-32BE
// We actually have no idea what the encoding is if we reach this point, so
// you may wish to return null instead of defaulting to ASCII
return Encoding.ASCII;
}
answered Oct 9, 2013 at 22:30
![]()
17
The following code works fine for me, using the StreamReader class:
using (var reader = new StreamReader(fileName, defaultEncodingIfNoBom, true))
{
reader.Peek(); // you need this!
var encoding = reader.CurrentEncoding;
}
The trick is to use the Peek call, otherwise, .NET has not done anything (and it hasn’t read the preamble, the BOM). Of course, if you use any other ReadXXX call before checking the encoding, it works too.
If the file has no BOM, then the defaultEncodingIfNoBom encoding will be used. There is also a StreamReader constructor overload without this argument (in this case, the encoding will by default be set to UTF8 before any read), but I recommend to define what you consider the default encoding in your context.
I have tested this successfully with files with BOM for UTF8, UTF16/Unicode (LE & BE) and UTF32 (LE & BE). It does not work for UTF7.
answered May 22, 2015 at 9:59
![]()
Simon MourierSimon Mourier
130k21 gold badges245 silver badges295 bronze badges
13
Providing the implementation details for the steps proposed by @CodesInChaos:
1) Check if there is a Byte Order Mark
2) Check if the file is valid UTF8
3) Use the local «ANSI» codepage (ANSI as Microsoft defines it)
Step 2 works because most non ASCII sequences in codepages other that UTF8 are not valid UTF8. https://stackoverflow.com/a/4522251/867248 explains the tactic in more details.
using System; using System.IO; using System.Text;
// Using encoding from BOM or UTF8 if no BOM found,
// check if the file is valid, by reading all lines
// If decoding fails, use the local "ANSI" codepage
public string DetectFileEncoding(Stream fileStream)
{
var Utf8EncodingVerifier = Encoding.GetEncoding("utf-8", new EncoderExceptionFallback(), new DecoderExceptionFallback());
using (var reader = new StreamReader(fileStream, Utf8EncodingVerifier,
detectEncodingFromByteOrderMarks: true, leaveOpen: true, bufferSize: 1024))
{
string detectedEncoding;
try
{
while (!reader.EndOfStream)
{
var line = reader.ReadLine();
}
detectedEncoding = reader.CurrentEncoding.BodyName;
}
catch (Exception e)
{
// Failed to decode the file using the BOM/UT8.
// Assume it's local ANSI
detectedEncoding = "ISO-8859-1";
}
// Rewind the stream
fileStream.Seek(0, SeekOrigin.Begin);
return detectedEncoding;
}
}
[Test]
public void Test1()
{
Stream fs = File.OpenRead(@".TestDataTextFile_ansi.csv");
var detectedEncoding = DetectFileEncoding(fs);
using (var reader = new StreamReader(fs, Encoding.GetEncoding(detectedEncoding)))
{
// Consume your file
var line = reader.ReadLine();
...
answered Sep 7, 2018 at 18:09
![]()
Berthier LemieuxBerthier Lemieux
3,6651 gold badge24 silver badges25 bronze badges
5
Check this.
UDE
This is a port of Mozilla Universal Charset Detector and you can use it like this…
public static void Main(String[] args)
{
string filename = args[0];
using (FileStream fs = File.OpenRead(filename)) {
Ude.CharsetDetector cdet = new Ude.CharsetDetector();
cdet.Feed(fs);
cdet.DataEnd();
if (cdet.Charset != null) {
Console.WriteLine("Charset: {0}, confidence: {1}",
cdet.Charset, cdet.Confidence);
} else {
Console.WriteLine("Detection failed.");
}
}
}
answered Oct 9, 2017 at 12:03
![]()
6
I’d try the following steps:
1) Check if there is a Byte Order Mark
2) Check if the file is valid UTF8
3) Use the local «ANSI» codepage (ANSI as Microsoft defines it)
Step 2 works because most non ASCII sequences in codepages other that UTF8 are not valid UTF8.
answered Sep 29, 2010 at 20:26
![]()
CodesInChaosCodesInChaos
106k23 gold badges216 silver badges261 bronze badges
8
.NET is not very helpful, but you can try the following algorithm:
- try to find the encoding by BOM(byte order mark) … very likely not to be found
- try parsing into different encodings
Here is the call:
var encoding = FileHelper.GetEncoding(filePath);
if (encoding == null)
throw new Exception("The file encoding is not supported. Please choose one of the following encodings: UTF8/UTF7/iso-8859-1");
Here is the code:
public class FileHelper
{
/// <summary>
/// Determines a text file's encoding by analyzing its byte order mark (BOM) and if not found try parsing into diferent encodings
/// Defaults to UTF8 when detection of the text file's endianness fails.
/// </summary>
/// <param name="filename">The text file to analyze.</param>
/// <returns>The detected encoding or null.</returns>
public static Encoding GetEncoding(string filename)
{
var encodingByBOM = GetEncodingByBOM(filename);
if (encodingByBOM != null)
return encodingByBOM;
// BOM not found :(, so try to parse characters into several encodings
var encodingByParsingUTF8 = GetEncodingByParsing(filename, Encoding.UTF8);
if (encodingByParsingUTF8 != null)
return encodingByParsingUTF8;
var encodingByParsingLatin1 = GetEncodingByParsing(filename, Encoding.GetEncoding("iso-8859-1"));
if (encodingByParsingLatin1 != null)
return encodingByParsingLatin1;
var encodingByParsingUTF7 = GetEncodingByParsing(filename, Encoding.UTF7);
if (encodingByParsingUTF7 != null)
return encodingByParsingUTF7;
return null; // no encoding found
}
/// <summary>
/// Determines a text file's encoding by analyzing its byte order mark (BOM)
/// </summary>
/// <param name="filename">The text file to analyze.</param>
/// <returns>The detected encoding.</returns>
private static Encoding GetEncodingByBOM(string filename)
{
// Read the BOM
var byteOrderMark = new byte[4];
using (var file = new FileStream(filename, FileMode.Open, FileAccess.Read))
{
file.Read(byteOrderMark, 0, 4);
}
// Analyze the BOM
if (byteOrderMark[0] == 0x2b && byteOrderMark[1] == 0x2f && byteOrderMark[2] == 0x76) return Encoding.UTF7;
if (byteOrderMark[0] == 0xef && byteOrderMark[1] == 0xbb && byteOrderMark[2] == 0xbf) return Encoding.UTF8;
if (byteOrderMark[0] == 0xff && byteOrderMark[1] == 0xfe) return Encoding.Unicode; //UTF-16LE
if (byteOrderMark[0] == 0xfe && byteOrderMark[1] == 0xff) return Encoding.BigEndianUnicode; //UTF-16BE
if (byteOrderMark[0] == 0 && byteOrderMark[1] == 0 && byteOrderMark[2] == 0xfe && byteOrderMark[3] == 0xff) return Encoding.UTF32;
return null; // no BOM found
}
private static Encoding GetEncodingByParsing(string filename, Encoding encoding)
{
var encodingVerifier = Encoding.GetEncoding(encoding.BodyName, new EncoderExceptionFallback(), new DecoderExceptionFallback());
try
{
using (var textReader = new StreamReader(filename, encodingVerifier, detectEncodingFromByteOrderMarks: true))
{
while (!textReader.EndOfStream)
{
textReader.ReadLine(); // in order to increment the stream position
}
// all text parsed ok
return textReader.CurrentEncoding;
}
}
catch (Exception ex) { }
return null; //
}
}
answered Jul 9, 2019 at 12:04
![]()
Look here for c#
https://msdn.microsoft.com/en-us/library/system.io.streamreader.currentencoding%28v=vs.110%29.aspx
string path = @"pathtoyourfile.ext";
using (StreamReader sr = new StreamReader(path, true))
{
while (sr.Peek() >= 0)
{
Console.Write((char)sr.Read());
}
//Test for the encoding after reading, or at least
//after the first read.
Console.WriteLine("The encoding used was {0}.", sr.CurrentEncoding);
Console.ReadLine();
Console.WriteLine();
}
answered Jun 28, 2016 at 13:31
![]()
SedJ601SedJ601
11.9k3 gold badges41 silver badges57 bronze badges
This seems to work well.
First create a helper method:
private static Encoding TestCodePage(Encoding testCode, byte[] byteArray)
{
try
{
var encoding = Encoding.GetEncoding(testCode.CodePage, EncoderFallback.ExceptionFallback, DecoderFallback.ExceptionFallback);
var a = encoding.GetCharCount(byteArray);
return testCode;
}
catch (Exception e)
{
return null;
}
}
Then create code to test the source. In this case, I’ve got a byte array I need to get the encoding of:
public static Encoding DetectCodePage(byte[] contents)
{
if (contents == null || contents.Length == 0)
{
return Encoding.Default;
}
return TestCodePage(Encoding.UTF8, contents)
?? TestCodePage(Encoding.Unicode, contents)
?? TestCodePage(Encoding.BigEndianUnicode, contents)
?? TestCodePage(Encoding.GetEncoding(1252), contents) // Western European
?? TestCodePage(Encoding.GetEncoding(28591), contents) // ISO Western European
?? TestCodePage(Encoding.ASCII, contents)
?? TestCodePage(Encoding.Default, contents); // likely Unicode
}
answered Apr 18, 2021 at 22:33
![]()
Glen LittleGlen Little
6,8934 gold badges46 silver badges68 bronze badges
2
The solution proposed by @nonoandy is really interesting, I have succesfully tested it and seems to be working perfectly.
The nuget package needed is Microsoft.ProgramSynthesis.Detection (version 8.17.0 at the moment)
I suggest to use the EncodingTypeUtils.GetDotNetName instead of using a switch for getting the Encoding instance:
using System.Text;
using Microsoft.ProgramSynthesis.Detection.Encoding;
...
public Encoding? DetectEncoding(Stream stream)
{
try
{
if (stream.CanSeek)
{
// Read from the beginning if possible
stream.Seek(0, SeekOrigin.Begin);
}
// Detect encoding type (enum)
var encodingType = EncodingIdentifier.IdentifyEncoding(stream);
// Get the corresponding encoding name to be passed to System.Text.Encoding.GetEncoding
var encodingDotNetName = EncodingTypeUtils.GetDotNetName(encodingType);
if (!string.IsNullOrEmpty(encodingDotNetName))
{
return Encoding.GetEncoding(encodingDotNetName);
}
}
catch (Exception e)
{
// Handle exception (log, throw, etc...)
}
// In case of error return null or a default value
return null;
}
answered Dec 27, 2022 at 12:57
![]()
The following codes are my Powershell codes to determinate if some cpp or h or ml files are encodeding with ISO-8859-1(Latin-1) or UTF-8 without BOM, if neither then suppose it to be GB18030. I am a Chinese working in France and MSVC saves as Latin-1 on french computer and saves as GB on Chinese computer so this helps me avoid encoding problem when do source file exchanges between my system and my colleagues.
The way is simple, if all characters are between x00-x7E, ASCII, UTF-8 and Latin-1 are all the same, but if I read a non ASCII file by UTF-8, we will find the special character � show up, so try to read with Latin-1. In Latin-1, between x7F and xAF is empty, while GB uses full between x00-xFF so if I got any between the two, it’s not Latin-1
The code is written in PowerShell, but uses .net so it’s easy to be translated into C# or F#
$Utf8NoBomEncoding = New-Object System.Text.UTF8Encoding($False)
foreach($i in Get-ChildItem . -Recurse -include *.cpp,*.h, *.ml) {
$openUTF = New-Object System.IO.StreamReader -ArgumentList ($i, [Text.Encoding]::UTF8)
$contentUTF = $openUTF.ReadToEnd()
[regex]$regex = '�'
$c=$regex.Matches($contentUTF).count
$openUTF.Close()
if ($c -ne 0) {
$openLatin1 = New-Object System.IO.StreamReader -ArgumentList ($i, [Text.Encoding]::GetEncoding('ISO-8859-1'))
$contentLatin1 = $openLatin1.ReadToEnd()
$openLatin1.Close()
[regex]$regex = '[x7F-xAF]'
$c=$regex.Matches($contentLatin1).count
if ($c -eq 0) {
[System.IO.File]::WriteAllLines($i, $contentLatin1, $Utf8NoBomEncoding)
$i.FullName
}
else {
$openGB = New-Object System.IO.StreamReader -ArgumentList ($i, [Text.Encoding]::GetEncoding('GB18030'))
$contentGB = $openGB.ReadToEnd()
$openGB.Close()
[System.IO.File]::WriteAllLines($i, $contentGB, $Utf8NoBomEncoding)
$i.FullName
}
}
}
Write-Host -NoNewLine 'Press any key to continue...';
$null = $Host.UI.RawUI.ReadKey('NoEcho,IncludeKeyDown');
answered Jun 15, 2017 at 14:21
![]()
EnzojzEnzojz
8552 gold badges9 silver badges15 bronze badges
I have tried a few different ways to detect encoding and hit issues with most of them.
I made the following leveraging a Microsoft Nuget Package and it seems to work for me so far but needs tested a lot more.
Most of my testing has been on UTF8, UTF8 with BOM and ASNI.
static void Main(string[] args)
{
var path = Directory.GetCurrentDirectory() + "\TextFile2.txt";
List<string> contents = File.ReadLines(path, GetEncoding(path)).Where(w => !string.IsNullOrWhiteSpace(w)).ToList();
int i = 0;
foreach (var line in contents)
{
i++;
Console.WriteLine(line);
if (i > 100)
break;
}
}
public static Encoding GetEncoding(string filename)
{
using (var file = new FileStream(filename, FileMode.Open, FileAccess.Read))
{
var detectedEncoding = Microsoft.ProgramSynthesis.Detection.Encoding.EncodingIdentifier.IdentifyEncoding(file);
switch (detectedEncoding)
{
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Utf8:
return Encoding.UTF8;
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Utf16Be:
return Encoding.BigEndianUnicode;
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Utf16Le:
return Encoding.Unicode;
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Utf32Le:
return Encoding.UTF32;
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Ascii:
return Encoding.ASCII;
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Iso88591:
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Unknown:
case Microsoft.ProgramSynthesis.Detection.Encoding.EncodingType.Windows1252:
default:
return Encoding.Default;
}
}
}
answered Jun 18, 2022 at 3:30
![]()
It may be useful
string path = @"address/to/the/file.extension";
using (StreamReader sr = new StreamReader(path))
{
Console.WriteLine(sr.CurrentEncoding);
}
![]()
deHaar
17.5k10 gold badges37 silver badges50 bronze badges
answered Jun 11, 2019 at 19:48
![]()
1
Простая на первый взгляд задача, но выполнить её оказывается не просто. С++ обладает достаточной гибкостью, как язык среднего уровня, поэтому требуется исчерпывающее знание вопроса для эффективной реализации задачи. Поделюсь тем что выяснил.
Чтобы правильно прочесть файл нужно сначала посмотреть, есть ли в начале файла Маркер последовательности (тут точнее). Если есть маркер, его нужно определить. Если маркера нет, как выше уже было сказано, нужно искать другой алгоритм определения кодировки.
Я тут целиком и полностью полагаюсь на IsTextUnicode, если маркера нет:
BYTE *pBuf;
size_t szRead, szBOM; // к-во прочитанных в файле байт и к-во байт маркера
enum Unicode eUnicode;
LPTSTR pszText;
...
// определяю, есть ли в тексте маркер (ручная работа)
szBOM = IsUnicodeRaw(pBuf, szRead, &eUnicode);
// вызов библиотечной ф-ции IsTextUnicode после собственной проверки
if(eUnicode != utf_16LE && ((szRead - szBOM) % 2 || !IsTextUnicode(pBuf + szBOM, (int) (szRead - szBOM), NULL)))
{
BYTE *pb = new BYTE[(szRead - szBOM + 1) * sizeof(wchar_t)];
unsigned int nCP = (eUnicode == utf_8) ? CP_UTF8 : (eUnicode == utf_7) ? CP_UTF7 : CP_ACP;
if (!MultiByteToWideChar(nCP, (nCP == CP_ACP) ? MB_PRECOMPOSED : 0, (LPCSTR) (pBuf + szBOM), (int) (szRead - szBOM), (LPWSTR) pb, (int) (szRead - szBOM)))
{
// ошибка...
}
delete[] pBuf;
pszText = (LPTSTR) (pszBuf = pb)
}
else
pszText = (LPTSTR) (pszBuf + szBOM);После того как выяснил наличие маркера в ф-ции IsUnicodeRaw, обращаюсь к IsTextUnicode без маркера. Работает с UTF-8, с UTF-7 нужно разбираться — там последние 2 бита маркера являются частью следующего за маркером символа. ANSI-текст так же нормально кодирует в двухбайтовый.
Wind’а предпочитает UTF-8 и UTF-16LE. Перед тем как записать текст, его нужно либо перекодировать в ANSI ф-цией WideCharToMultibyte, либо в начало файла записать маркер кодировки UTF-8 или UTF-16LE, чтобы потом также прочесть.
Как определить кодировку текстового файла
Кодировкой текста в файлах цифровых документов называют способ сопоставления последовательностей байт символам языка. Существует множество различных кодировок для разных языков. Определить кодировку текстового файла можно при помощи ряда программных средств.

Вам понадобится
- — Microsoft Office Word;
- — KWrite;
- — Mozilla Firefox;
- — enca.
Инструкция
Используйте редактор Microsoft Office Word, если он установлен на компьютере, для определения кодировки текстового файла. Запустите данное приложение. В главном меню последовательно выберите пункты «Файл» и «Открыть…» или нажмите сочетание клавиш Ctrl+O. В отобразившемся диалоге перейдите к нужному каталогу и выделите файл. Нажмите кнопку «Открыть». Если кодировка текста отличается от CP1251, автоматически откроется диалог «Преобразование файла». Активируйте в нем опцию «Другая» и подберите кодировку, используя список, находящийся справа. При выборе правильной кодировки в поле «Образец» будет выведен читаемый текст.
Примените текстовые редакторы, допускающие выбор кодировки текста источника. Хорошим примером подобного приложения является KWrite (работает в среде KDE в UNIX-подобных системах). Загрузите текстовый файл в редактор. Затем просто перебирайте кодировки, пока не отобразится читаемый текст (в KWrite для этого используется раздел Encoding меню Tools).
Аналогично текстовому редактору для определения кодировки файла можно использовать и браузер. Воспользуйтесь Mozilla Firefox. Запустите данное приложение. Если оно не установлено, загрузите подходящий дистрибутив с сайта mozilla.org и инсталлируйте его. Откройте в браузере текстовый файл. Для этого выберите в главном меню пункты «Файл» и «Открыть файл…» или нажмите Ctrl+O. Если загруженный текст отобразился корректно, разверните раздел «Кодировка» меню «Вид» и узнайте кодировку из названия пункта, на котором установлена отметка. В противном случае подберите данный параметр путем выбора различных пунктов того же меню, а также его раздела «Дополнительные».
Примените специализированные утилиты для определения кодировок текстовых файлов. В UNIX-подобных системах можно использовать enca. При необходимости установите эту программу при помощи доступных менеджеров пакетов. Выведите список доступных языков, выполнив команду:
enca —list languages
Определите кодировку текстового файла, указав его имя при помощи опции -g и язык документа при помощи опции -L. Например:
enca -L russian -g /home/vic/tmp/aaa.txt.
Источники:
- Кодировка текста ASCII
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Кодировка файлов
Как определить в какой кодировке записан файл?
Анализировать мы будем содержимое файлов с осмысленным текстом, а не просто с
набором символов. Нас, естественно, будут интересовать только кодировки, относящиеся
к Русскому языку. Таких кодировок семь, все они используются, понимаются броузерами,
покажем какие символы используют эти кодировки. За основную кодировку примем windows-1251.
Смысл данной странички задать вопрос, а можно ли нам исследовав файл на наличие
символов, чётко сказать в какой кодировке сохранён данный файл.
Итак, наш алфавит в разных кодировках:
Посмотрим, как будут смотреться разные кодировки в Win:
| Win | а | б | в | г | д | е | ё | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
| Koi | Б | В | Ч | З | Д | Е | ? | Ц | Ъ | Й | К | Л | М | Н | О | П | Р | Т | У | Ф | Х | Ж | И | Г | Ю | Ы | Э | Я | Щ | Ш | Ь | А | С |
| Iso | Р | С | Т | У | Ф | Х | с | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Mac | а | б | в | г | д | е | Ю | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | Я |
| Ibm866 | Ў | ў | ? | ¤ | ? | с | ¦ | § | Ё | c | Є | < | ¬ | — | R | Ї | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | |
| Ibm855 | ў | л | ¬ | ¦ | Ё | « | й | у | · | ? | Ж | Р | Т | Ф | Ц | Ш | б | г | е | з | Є | ч | ¤ | ы | х | щ | ? | с | н | ч | ? | Ю | |
| Utf-8 | Р° | Р+ | Р? | Р? | Р? | Рч | С’ | Р¶ | Р· | Рё | Р№ | Рє | Р> | Р? | Р? | Р? | Рї | С? | С? | С’ | С? | С» | С: | С+ | С+ | С? | С% | С? | С< | С? | С? | С? | С? |
В тексте мы
будем искать эти символы, кодировку будем определять по количеству найденных символов.
Здесь, представлены только маленькие буквы русского языка.
После анализа символов можно сделать такой вывод:
-
кодировка Koi8-r (iso-ir-111), совпадает с
Windows-1251, только все символы становятся в
большом регистре. Наоборот, все Большие
буквы становятся маленькими в Koi8-r. Пусть
символы не совпадают друг с другом, но для
поиска нам достаточно того, что мы знаем,
кроме буквы ‘ё’, чётко сказать, что файл
сохранён в кодировке Koi8-r или Windows-1251
нельзя, потому что их символы совпадают.
Можно попробовать искать маленькие
русские буквы в файле, если их будет
больше, чем символов в Большом регистре,
можно предположить, что файл сохранён в
Windows-1251. - В кодировке Iso-8859-5 есть абвгдежзийклмноп, то есть 16 букв из Windows-1251.
- В кодировке X-mac-cyrillic (X-mac-ukrainian) есть
все маленькие символы из Windows-1251,
кроме ‘ё’ и ‘я’, буква ‘я’
переходит в верхний регистр. Этот факт не
даёт нам возможности со 100% гарантией
сказать, что файл сохранён в кодировке
Windows-1251 или X-mac-cyrillic. - В кодировке Ibm866 есть абвгдежзийклмноп,
то есть 16 букв из Windows-1251, что совпадает с
кодировкой Iso-8859-5, что для нас плохо,
значит надо добавить поиск символов в
большом регистре, чтобы получить отличие.
Зато, с Windows-1251 есть приличное различие. - В кодировке Ibm855 есть бгезйлнсущы, то есть 11 букв из Windows-1251.
- В кодировке Utf-8 нет символов
из Windows-1251, то есть мы четко сможем сказать
, что файл, например, сохранён в Utf-8.
Вывод: проверяя файл на наличие в нём тех или иных символов, нельзя точно
сказать в какой кодировке сохранён файл. Тем не менее, всё — таки, приведём небольшую
функцию по определению кодировки в файле.
// функция, выводящая кодировку файла
function search_file_kod ($path){
$charsets = array ( 'w' => 0, 'k' => 0, 'i' => 0, 'm' => 0, 'a' => 0, 'c' => 0, 'u' => 0 );
$fp = fopen ($path, "rb");
if (!$fp){ return 'error'; }
$content = fread ($fp , '1024');
fclose ($fp);
// Windows-1251
$search_l_w = "~([270])|([340-347])|([350-357])|([360-367])|([370-377])~s";
$search_U_w = "~([250])|([300-307])|([310-317])|([320-327])|([330-337])~s";
// Koi8-r
$search_l_k = "~([243])|([300-307])|([310-317])|([320-327])|([330-337])~s";
$search_U_k = "~([263])|([340-347])|([350-357])|([360-367])|([370-377])~s";
// Iso-8859-5
$search_l_i = "~([361])|([320-327])|([330-337])|([340-347])|([350-357])~s";
$search_U_i = "~([241])|([260-267])|([270-277])|([300-307])|([310-317])~s";
// X-mac-cyrillic
$search_l_m = "~([336])|([340-347])|([350-357])|([360-367])|([370-370])|([337])~s";
$search_U_m = "~([335])|([200-207])|([210-217])|([220-227])|([230-237])~s";
// Ibm866
$search_l_a = "~([361])|([240-247])|([250-257])|([340-347])|([350-357])~s";
$search_U_a = "~([360])|([200-207])|([210-217])|([220-227])|([230-237])~s";
// Ibm855
$search_l_c = "~([204])|([234])|([236])|([240])|([242])|([244])|([246])|([250])|".
"([252])|([254])|([265])|([267])|([275])|([306])|([320])|([322])|".
"([324])|([326])|([330])|([340])|([341])|([343])|([345])|([347])|".
"([351])|([353])|([355])|([361])|([363])|([365])|([367])|([371])|([373])~s";
$search_U_c = "~([205])|([235])|([237])|([241])|([243])|([245])|([247])|([251])|".
"([253])|([255])|([266])|([270])|([276])|([307])|([321])|([323])|".
"([325])|([327])|([335])|([336])|([342])|([344])|([346])|([350])|".
"([352])|([354])|([356])|([362])|([364])|([366])|([370])|([372])|([374])~s";
// Utf-8
$search_l_u = "~([xD1x91])|([xD1x80-x8F])|([xD0xB0-xBF])~s";
$search_U_u = "~([xD0x81])|([xD0x90-x9F])|([xD0xA0-xAF])~s";
if ( preg_match_all ($search_l_w, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['w'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_w, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['w'] += count ($arr[0]); }
if ( preg_match_all ($search_l_k, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['k'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_k, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['k'] += count ($arr[0]); }
if ( preg_match_all ($search_l_i, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['i'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_i, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['i'] += count ($arr[0]); }
if ( preg_match_all ($search_l_m, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['m'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_m, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['m'] += count ($arr[0]); }
if ( preg_match_all ($search_l_a, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['a'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_a, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['a'] += count ($arr[0]); }
if ( preg_match_all ($search_l_c, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['c'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_c, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['c'] += count ($arr[0]); }
if ( preg_match_all ($search_l_u, $content, $arr, PREG_PATTERN_ORDER)) { $charsets['u'] += count ($arr[0]) * 3; }
if ( preg_match_all ($search_U_u, $content, $arr, PREG_PATTERN_ORDER)){ $charsets['u'] += count ($arr[0]); }
arsort ($charsets);
$key = key($charsets);
if ( max ($charsets)==0 ){ return 'unknown'; }
elseif ( $key == 'w' ){ return 'win'; }
elseif ( $key == 'k' ){ return 'koi'; }
elseif ( $key == 'i' ){ return 'iso'; }
elseif ( $key == 'm' ){ return 'mac'; }
elseif ( $key == 'a' ){ return 'ibm866';}
elseif ( $key == 'c' ){ return 'ibm855';}
elseif ( $key == 'u' ){ return 'utf8'; }
}
// выведем кодировку файла file.txt
print search_file_kod ('file.txt');