Маркетинг – та сфера, где больше всего любят работать с большими данными (англ. big data), однако излюбленный инструмент маркетологов – A/B-тестирование – предполагает использование малых данных (англ. small data). При этом какие бы цифры ни были получены по итогам теста, все сводится к анализу статистической выборки и определению статистической значимости результатов эксперимента. Неотъемлемой частью данного исследования является P-значение, о котором мы хотим рассказать в этой статье.
Что такое P-значение
P-value или p-значение – одна из ключевых величин, используемых в статистике при тестировании гипотез. Она показывает вероятность получения наблюдаемых результатов при условии, что нулевая гипотеза верна, или вероятность ошибки в случае отклонения нулевой гипотезы.
Этот термин первым упомянул в своих работах К. А. Браунли в 1960 году. Он описал p-уровень значимости как показатель, который находится в обратной зависимости от истинности результатов. Чем выше р-value, тем ниже степень доверия в выборке зависимости между переменными.
Другими словами, в статистике p-значение – это наименьшее значение уровня значимости, при котором полученная проверочная статистика ведет к отказу от основной (нулевой) гипотезы.
Значение p-уровня чаще всего соответствует статистической значимости, равной 0,05. Если значение р меньше 0,05, нулевую гипотезу отклоняют. При этом чем меньше это значение, тем лучше, т. к. растет предполагаемая значимость альтернативной гипотезы и «сила» отвержения нулевой.
Часто p-значение понимают неправильно. Например, если значение р = 0,05, можно сказать о том, что существует 5% вероятности, что результат получен случайно и не соответствует действительности.

Кратко о главном
- Р-значение показывает вероятность того, что наблюдаемая разница в результатах могла быть случайной.
- Значение p применяется как альтернатива выбранным уровням достоверности для тестирования идей или в дополнение к ним.
- Со снижением p-значения повышается статистическая значимость разницы, полученной в ходе исследования.
Статистическая значимость
Эксперимент начинается с формулирования нулевой гипотезы. Она показывает, что два исследуемых явления никаким образом не связаны друг с другом.
Эксперимент проводится с целью выявить или показать какое-либо влияние или тип взаимодействия рассматриваемых явлений. Если в итоге анализа подтверждается нулевая гипотеза, значит, тест провалился.

Чтобы правильно интерпретировать результаты, рассчитывают показатель статистической значимости.
Статистическая значимость – это критерий, с помощью которого можно определить, необходимо ли отвергнуть или принять ту или иную гипотезу.
Перед началом тестирования следует установить порог значимости (альфа). Если значение р меньше альфа, можно говорить о том, что наш результат является статистически значимым. Это говорит о том, что наблюдаемое явление действительно имело место, и нулевую гипотезу нужно отклонить.
Порог значимости альфа устанавливается обычно на уровне 0,05 или 0,01. Выбор значения определяется поставленной задачей.
Порог значимости равен 0,05, а p-значение – 0,02. Т. к. установленное значение альфа больше p-уровня, делаем вывод, что это статистически значимый результат.
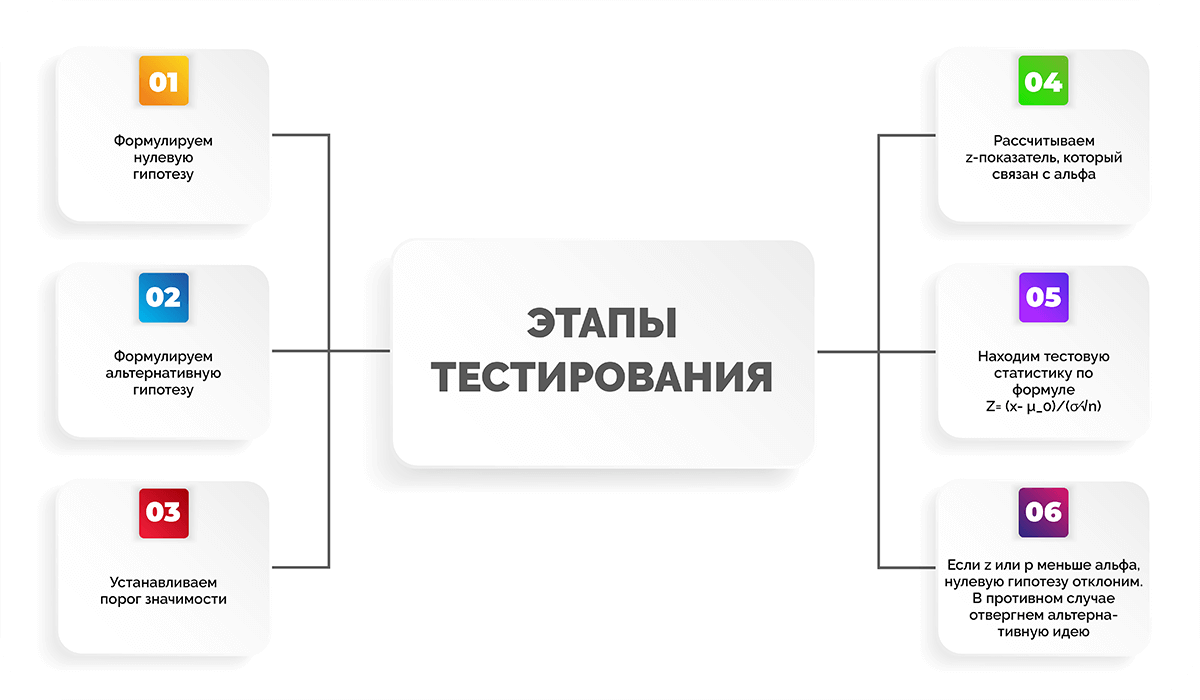
Все тестирование можно разделить на несколько этапов:
- Формулируем нулевую гипотезу.
- Формулируем альтернативную гипотезу.
- Устанавливаем порог значимости.
- Рассчитываем z-показатель, который связан с альфа.
- Находим тестовую статистику по формуле
 .
. - Если z-показатель или p-значение меньше уровня альфа, нулевую гипотезу отклоним. В противном случае отвергнем альтернативную идею.
 .
.Если идет речь о явлениях, которые управляются случайными процессами, обычно это приводит к нормальному распределению значений. В этом случае нулевую гипотезу представляют в виде кривой Гаусса, которая отражает распределение ожидаемых наблюдений. Это распределение актуально в случае, если одна переменная в эксперименте не зависит от другой.
Порог вероятности
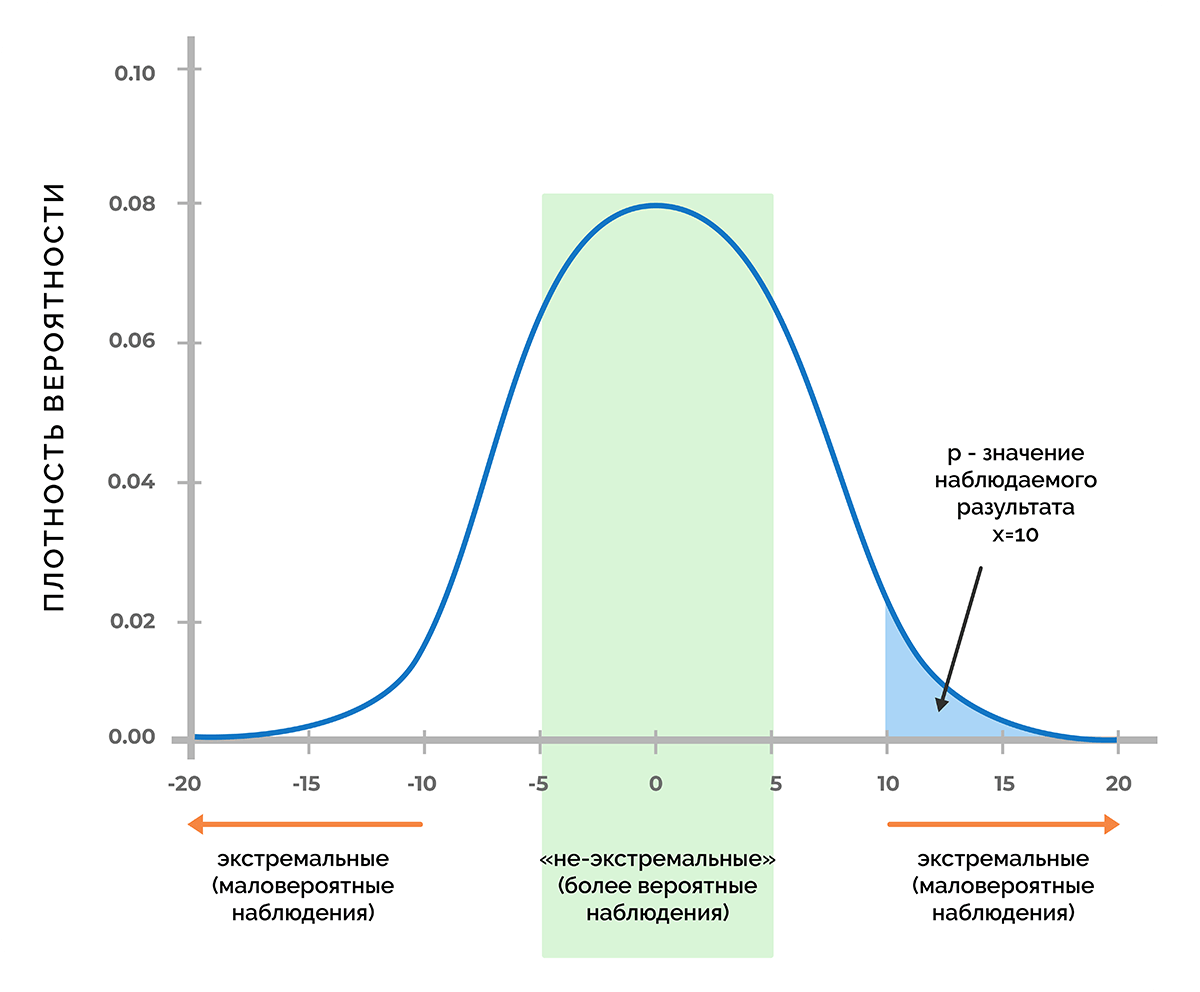
В основе статистической значимости лежит вероятность получения определенного результата при верности нулевой гипотезы. Чтобы разобрать смысл этого определения, предположим, что в процессе тестирования получили некое число х. Это может быть любая метрика, например, прибыль от продаж, величина конверсии, количество довольных покупателей и т. д.
Используя функцию плотности вероятности, которая связана с нулевой гипотезой, можно выяснить, удастся ли получить число х (или любое другое значение, которое маловероятнее, чем х) с вероятностью менее 5% (p < 0,05) или менее 1% (p < 0,01), или другого порога, при котором p меньше заданного уровня значимости.
Таким образом, p-критерий отражает вероятность получения результата, который равен или является более экстремальным, чем фактически наблюдаемый результат, в случае отсутствия взаимосвязи между исследуемыми переменными.
Доверительные уровни
Доверительный уровень значимости выбирается перед запуском статистического эксперимента. Чаще всего используются значения 90%, 95% или 99%.
Ниже в таблице приводим критические p-значения, а также z-оценки для разных доверительных уровней.
|
Доверительный уровень |
Стандартное отклонение (z-оценка) |
Вероятность (p-уровень) |
|
90% |
< -1,65 или > +1,65 |
< 0,10 |
|
95% |
< -1,96 или > +1,96 |
< 0,05 |
|
99% |
< -2,58 или > +2,58 |
< 0,01 |
Значения, которые находятся в пределах области нормального распределения z-оценки (стандартного отклонения), представляют ожидаемый результат.
Проверка статистических гипотез
Проверка гипотезы – это статистическое исследование, которое проводится, чтобы подтвердить или опровергнуть какую-либо гипотезу (простую или сложную).
Можно предположить, что посадочная страница с красной кнопкой CTA даст больше конверсий, чем текущая версия лендинга с синей. Проверить это можно путем тестирования, в котором будут участвовать нулевая и альтернативная гипотезы.

Нулевая гипотеза – первоначальное условие, при котором нет никакой разницы между текущей и новой версиями лендинга в плане конверсии
Альтернативная гипотеза – подразумевает, что изменение цвета кнопки на странице является причиной роста конверсии.
В статистике применяется рандомизация и нормализация нулевой гипотезы.
Рандомизация нулевой гипотезы – пространственная модель данных, которую мы наблюдаем, является одним из многих вариантов пространственных организаций данных. При этом все другие варианты не будут заметно отличаться от наблюдаемых.
Нормализация нулевой гипотезы подразумевает, что наблюдаемые значения являются одним из многих случайных вариантов выборок. При этом ни пространственное расположение данных, ни их значения не установлены.
Благодаря значению p можно увидеть, насколько нулевая гипотеза правдоподобна с учетом данных выборки. Таким образом, если нулевая гипотеза подтвердится, p-значение будет свидетельствовать об отсутствии увеличения конверсии вследствие изменения цвета кнопки.
Подход p-value к проверке гипотез
Значение р может использоваться для выявления доказательства для отклонения нулевой (первоначальной) гипотезы в ходе эксперимента.
Мы уже упоминали выше о том, что уровень значимости обозначается до начала исследования, чтобы определить, насколько малое значение p нужно получить для опровержения нулевой гипотезы. Однако в разных случаях разные люди могут использовать разные уровни значимости, поэтому при интерпретации итогов двух разных тестирований другими людьми могут возникать трудности. Решить эту проблему помогает p-value.
Рассмотрим пример, в котором в компании провели исследование, в ходе него сравнили доходность двух активов. Тест и анализ проводили два специалиста, которые брали за основу одни и те же самые исходные данные, но использовали разные уровни значимости. Есть вероятность, что эти люди сделают противоположные выводы о различии активов. Предположим, что один специалист для отклонения нулевой гипотезы взял уровень достоверности 90%, а другой – 95%. При этом среднее значение p наблюдаемой разницы между результатами равнялось 0,08, что отвечает уровню достоверности 92%. В таком случае первый специалист выявит значимое различие между двумя доходами, а второй статистически значимой разницы не обнаружит.
Чтобы избежать подобной ситуации, можно сообщить значение p-value эксперимента и дать возможность независимым наблюдателям самостоятельно оценивать статистическую значимость итоговых данных. Данный подход к проверке утверждений стали называть «подход p-value».
Как рассчитать P-value
Чаще всего p-значения определяют с помощью таблиц p-value или специализированного статистического ПО. Также помогает в этом калькулятор на тематических сайтах. Подобные расчеты основываются на известном или предполагаемом распределении вероятностей определенной статистики. Определение среднего значения р зависит от отклонения между выбранным эталонным и тестовым значением. При этом учитывается нормальное распределение вероятностей статистики.
Что касается ручного математического расчета значения р, существуют разные способы, которые рассмотрим далее в статье.
Как рассчитать p-значение, используя тестовую статистику
Распределение тестовой статистики происходит с предполагаемым условием, что верна нулевая гипотеза. Чтобы выразить вероятность того, что статистика эксперимента будет такой же экстремальной, как значение x для выборки, используется кумулятивная функция распределения.
Левосторонний эксперимент:
P-value = cdf (x)
Правосторонний эксперимент:
P-value = 1 – cdf (x)
Двусторонний эксперимент:
P-value = 2 × мин {{cdf (x), 1 – cdf (x)}}
Ручной расчет значения p затрудняют распространенные распределения вероятностей, которыми характеризуется проверка гипотез. Для расчета примерных показателей cdf удобнее использовать статистическую таблицу или ПК.
Пошаговый алгоритм расчета p-значения
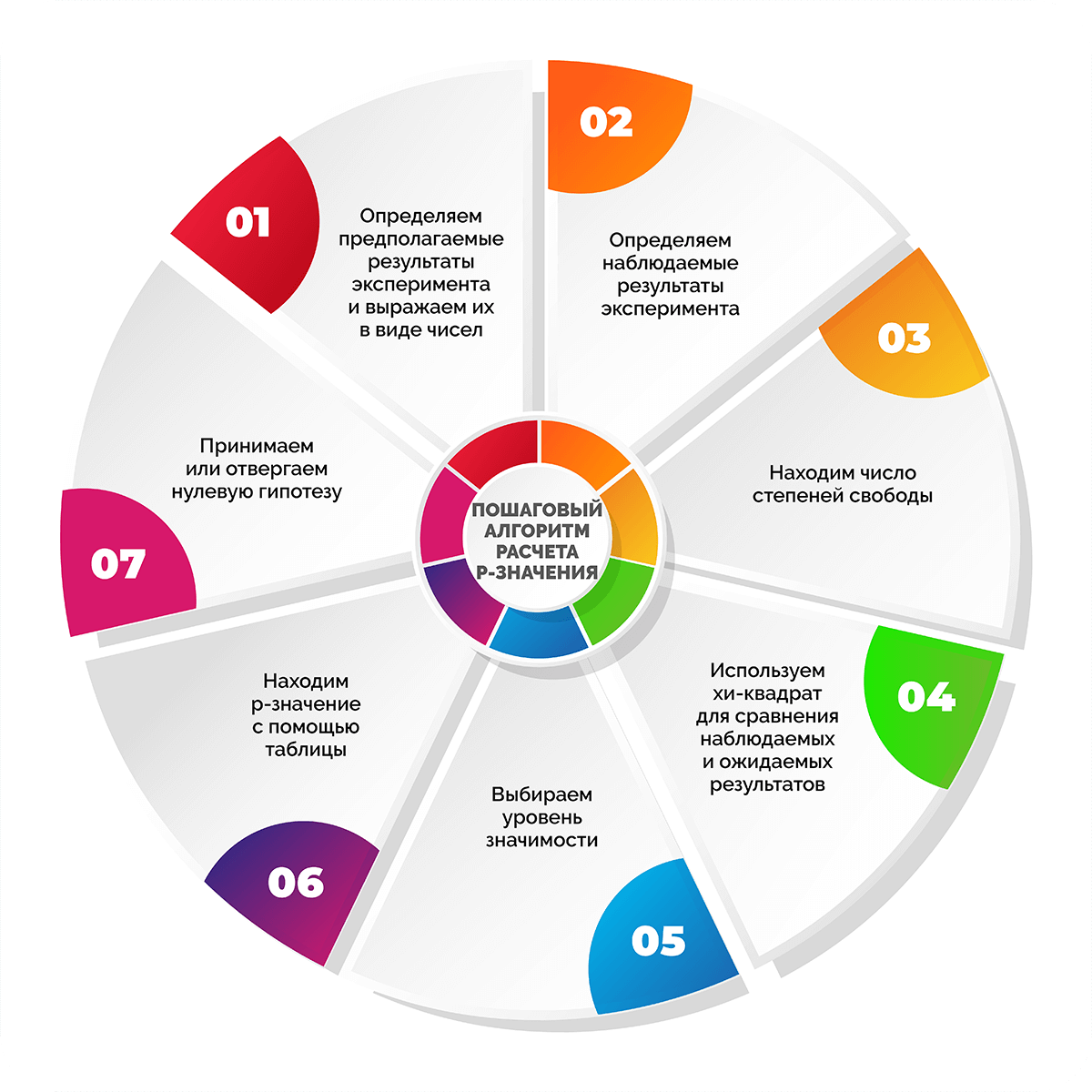
Шаг 1. Определяем предполагаемые результаты эксперимента и выражаем их в виде чисел
Как правило, на начало исследования уже есть видение того, какие числа можно считать приемлемыми. Выводы могут быть основаны на опыте проведения предыдущих экспериментов, наборах достоверных данных или общих сведеньях из научной литературы и других источников.
Опыт работы с лендингами показывает, что посадочные страницы с CTA-кнопкой на первом экране приводят примерно вдвое больше покупателей, чем версии без таких кнопок. Необходимо определить, действительно ли наличие кнопки влияет на посетителей сайта. Для этого будем анализировать конверсии в покупку. Если взять условные 300 конверсий, то предполагается, что 200 из них произойдут благодаря лендингам с CTA-кнопкой, а 100 – сайтам без кнопки при условии, что пользователи требовательны к наличию кнопок.
Шаг 2. Определяем наблюдаемые результаты эксперимента
Теперь нужно провести тест и получить реальные, т. е. наблюдаемые значения, которые таже будут выражаться в числовом формате. Если в экспериментальных условиях реальные цифры не совпадут с ожидаемыми, то будет два варианта – или это обусловлено действиями в ходе эксперимента, или получилось случайно. В данном случае цель определения p-value – понять, действительно ли наблюдаемые значения отличаются от ожидаемых настолько, что нулевая гипотеза не будет опровергнута.
Предположим, что мы выбрали 300 случайных конверсий с наших сайтов, на которых либо была кнопка на первом экране, либо ее не было. Определили, что 220 конверсий произошли благодаря лендингам с кнопкой и 80 – без нее. Результаты отличаются от ожидаемых, которые составляли 200 и 100 соответственно. Теперь предстоит узнать, действительно ли к изменению в значениях привел наш тест (добавление кнопки на первый экран) или это случайное отклонение. Определить это поможет p-значение.
Шаг 3. Находим число степеней свободы
Число степеней свободы показывает, насколько может измениться эксперимент. При этом степень изменяемости зависит от количества исследуемых категорий.
Число степеней свободы = n – 1, где n – количество анализируемых переменных или категорий.
В нашем эксперименте 2 условия и, соответственно, две категории результатов: для лендингов без кнопки на первом экране и для лендингов с ней.
Число степеней свободы = 2 – 1 = 1.
Если бы в эксперименте мы сравнивали посадочные станицы с CTA-кнопкой, без кнопки и с pop-up окном, то получили бы 2 степени свободы и т. д.
Шаг 4. Используем хи-квадрат для сравнения наблюдаемых и ожидаемых результатов
Хи-квадрат (х2) – числовое отражение разницы между наблюдаемыми (фактическими) и ожидаемыми значениями тестирования.

где:
о – наблюдаемое значение;
е – ожидаемое значение.
Подставляем наши цифры в уравнение и учитываем, что  нужно подсчитать дважды – для двух видов лендинга.
нужно подсчитать дважды – для двух видов лендинга.
х2 = ((220 – 200)2/200) + ((80 – 100)2/100) = ((20)2/200)) + ((-20)2/100) = (400/200) + (400/100) = 2 + 4 = 6.
Шаг 5. Выбираем уровень значимости
Уровень значимости отражает степень уверенности в полученных результатах. Если статистическая значимость низкая, это говорит о низкой вероятности случайного получения экспериментальных результатов.
Для большинства тестов достаточно статистической значимости, равной 0,05 или 5%. При этом будет вероятность 95%, что исследователь получил значимый результат вследствие проведенных мероприятий, а не случайно.
В нашем случае примем статистическую значимость, равную 0,05.
Шаг 6. Находим p-значение с помощью таблицы
Для облегчения расчетов статисты применяют специализированные таблицы. Они довольно простые и позволяют легко найти значение р, зная число степеней свободы и хи-значение. Слева по вертикали располагаются значения числа степеней свободы. Вверху по горизонтали находятся p-значения. По данным таблицы сначала находят нужное число степеней свободы, затем в соответствующем ему ряду выбирают первое значение, которое превышает расчетное значение хи-квадрата. Число в верхней горизонтальной строке будет соответствовать p-значению. При этом нужное значение р находится в диапазоне чисел между найденным и следующим за ним слева.
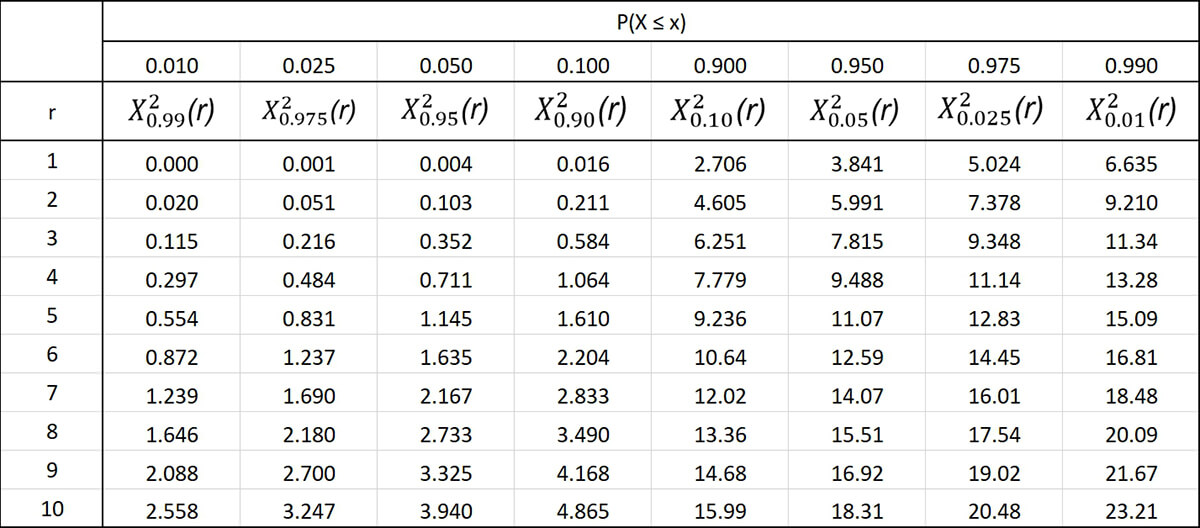
В нашем примере всего одна степень свободы, а хи-квадрат равен 6. Поэтому в таблице выбираем первую строку и движемся по ней слева направо до тех пор, пока не увидим первое значение больше 6 – это число 6,635. Оно соответствует p-значению 0,01, а значит, наше p-значение находится в диапазоне между 0,01 и 0,025.
Шаг 7. Принимаем или отвергаем нулевую гипотезу
Если найденное приблизительное значение p меньше уровня значимости, можно заключить, что вероятна связь между экспериментальными переменными и полученными результатами. В противном случае нельзя утверждать с уверенностью, связаны ли результаты с манипуляцией переменными или стали случайностью.
В нашем эксперименте диапазон значений р 0,01-0,025 определенно меньше установленной статистической значимости 0,05, что позволяет отклонить нулевую гипотезу. А значит, можно сделать вывод, что посадочные страницы с CTA-кнопкой на 1-м экране конвертируют лучше, чем аналогичные версии без такой кнопки. Вероятность того, что рост конверсий на лендингах с кнопкой является случайностью, составляет не больше 1-2,5%.
Как интерпретировать P-значение
P-уровень тесно связан с уровнем статистической значимости. Последний таже определяет исход эксперимента.
- Если p-значение меньше уровня значимости, то нулевую гипотезу можно смело отклонить и считать истинной альтернативную гипотезу.
- Если p-значение больше уровня значимости, это означает, что в ходе эксперимента выявили недостаточно оснований для отклонения нулевой гипотезы.
Отвержение нулевой гипотезы говорит о том, что в процессе исследования была обнаружена закономерная связь между тестируемыми переменными.
P-значение – это…
- вероятность того, что в ходе исследования наблюдения были случайными. То есть, если p = 0,05, есть 5% вероятности того, что наблюдаемое явление случайно и 95% вероятности того, что результат является следствием созданных условий;
- вероятность того, что будет сделан неверный вывод о взаимосвязи переменных. Если р = 0,05, то на каждые 100 экспериментов, где наблюдалась взаимосвязь, 95 их них действительно была, а 5 – нет.
Что нужно помнить о P-значениях
- «Неожиданность» определяет тот, кто проводит эксперимент. Подводит итоги теста по факту тот, кто его проводит. Чем выше значение р, тем чаще вы будете получать неожиданные результаты.
- Применение p-значения имеет довольно извилистую логику. Чтобы оценить аргументы в пользу отклонения нулевой гипотезы, необходимо изначально считать, что она верна. Именно это является причиной путаницы.
- По значению p невозможно оценить вероятность того, что один исследуемый вариант лучше другого. Также по этому показателю нельзя понять, какая вероятность того, что предпочтение одного варианта другому ошибочно. На самом деле, p-значение показывает лишь вероятность того, что при верности нулевой гипотезы удастся вычислить результат, отличный от нуля.
- Значимость p-значения при подведении итогов сплит-тестов – тема неутихающих споров в научном сообществе. Большинство маркетологов остаются приверженцами классической проверки на статистическую значимость и отстаивают ее как «золотой стандарт». При этом специалисты по статистике приводят аргументы в пользу других методов проверки, что провоцирует жаркие дебаты.
- Всегда можно получить существенное (высшее) значение p. Есть типичная ошибка, которая зависит с одной стороны от объема выборки, с другой – от изменений генеральной совокупности данных. Если во втором случае повлиять на изменения никак нельзя, то собирать и накапливать данные ничто не мешает. Но есть ли польза от такого количества сведений? Сам факт того, что у полученного параметра высокое p-значение, практического значения не имеет.
- Не стоит волноваться раньше времени. В первую очередь нужно собрать данные, которые помогут сформировать рабочую идею. Всегда трудно делать выбор между вариантами, которые почти не отличаются друг от друга. Если выделить предпочтительный вариант проблематично из-за похожих результатов, можно просто выбрать один из них и не беспокоиться о том, правильный ли это выбор.
- P-значение не повод прекращать тест. Для получения достоверных результатов, которые позволят интерпретировать p-значение, необходимо вычислить размер выборки, затем провести эксперимент. В процессе тестирования предстоит выбрать время, когда пора его закончить. При этом оно не должно быть связано с достижением статистической значимости или высокого показателя p-значения. Главное – получить реальные результаты в конце теста, например, обеспечить рост прибыли, оптимизировать конверсию и т. д.
Примеры интерпретации P-значений
На нескольких примерах рассмотрим, как правильно интерпретировать p-значения при проверке разных идей.
По мнению интернет-провайдера, 90% пользователей довольны качеством предоставляемых услуг. Чтобы это проверить, была собрана простая выборка, куда вошли 500 случайных абонентов. 85% дали утвердительный ответ на вопрос об удовлетворенности услугами провайдера. По данным выборки удалось вычислить p-значение, равное 0,018.
Если выдвинуть гипотезу о том, что 90% пользователей действительно довольны обслуживанием провайдера, получим реальную наблюдаемую разницу или более экстремальную разницу, которая составит 1,8% потребителей услуг вследствие ошибки случайной выборки.
Ресторан вводит услугу доставки еды и утверждает, что время доставки составляет около 30 минут или меньше. Однако есть мнение, что реальный срок доставки превышает заявленное время. Для проверки этих вариантов были отобраны случайные заказы еды с доставкой и проведены расчеты. По результатам выяснили, что среднее время доставки составляет 40 минут (больше на 10 минут, чем заявляет ресторан), а p-значение равно 0,03.
Результаты показывают, что в случае, когда нулевая гипотеза верна, т. е. доставка еды занимает 30 минут или меньше, есть вероятность 3%, что среднее время доставки будет как минимум на 10 минут больше из-за эффекта случайности.
Отдел маркетинга разрабатывает новый скрипт продаж для менеджеров. Предполагается, что с его помощью компания будет продавать минимум на 30% больше, чем со старым скриптом. Чтобы это проверить, собирается простая случайная выборка из 100 контактов с клиентами по новому скрипту и 100 – по старому. В результате эксперимента новый скрипт привел 60 покупателей, а старый – 45. Вычислили среднее значение p, равное 0,011.
Если взять за основу мнение, что новый скрипт приводит столько же клиентов, сколько и старый, или меньше, будет получена крайняя разница в 1,1% тестирований вследствие случайной ошибки выборки.
Часто задаваемые вопросы
P-значение – вероятность того, что исследуемая статистика удовлетворит конкретным условиям. Поскольку вероятности отрицательными не бывают, отрицательного значения p тоже быть не может.
Если p-значение высокое, это свидетельствует о том, что статистика эксперимента для другой выборки будет иметь столь же экстремальное значение, как и в тестируемой выборке. При высоком p-значении отвергнуть нулевую гипотезу нельзя.
Если получено низкое p-значение, это значит, что вероятность получить такое же критическое значение, как и наблюдаемое в текущей выборке, в тестовой статистике для другой выборки окажется очень низкой. При низком p-значении нулевую гипотезу отвергают и принимают альтернативную.
Некоторые считают, что p-значения показывают вероятность совершить ошибку при отклонении истинной нулевой гипотезы (ошибка первого типа) – это заблуждение. P-значения не свидетельствуют о частоте вероятных ошибок по двум причинам:
- При расчете p-значения в основе утверждение, что верна нулевая гипотеза, а разница в итоговых данных обусловлена случайностью. То есть величина p-значения не отражает вероятность того, что ноль будет ложным или истинным, т. к. с учетом изначального предположения он полностью верен.
- Несмотря на то, что при низком p-значении при условии истинности нулевого значения выборочные данные маловероятны, p-значение все еще не может четко показать, какой из вариантов имеет большую вероятность стать истиной: когда нуль действительно является ложным или когда нуль является верным, но выборка нечеткая.
Заключение
Несмотря на то, что при интерпретации результатов исследований часто допускают ошибки, неправильно используя статистическую значимость, она продолжает оставаться важным методом в экспериментах. P-значение или p-value является одной из обязательных составляющих при оценке результатов тестирования. Именно этот показатель дает возможность понять, с какой вероятностью полученные итоги удовлетворяют определенным значениям.

Олег Вершинин
Специалист по продукту
Все статьи автора
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
Statistics is all about drawing conclusions in the face of uncertainty. Whenever you take a sample, you can’t be completely certain that your sample truly reflects the population it’s drawn from. Statisticians deal with this uncertainty by taking the factors that could impact the estimate into account, quantifying their uncertainty and performing statistical tests to draw conclusions from this uncertain data.
Statisticians use confidence intervals to specify a range of values that is likely to contain the “true” population mean on the basis of a sample, and express their level of certainty in this through confidence levels. While calculating confidence levels isn’t often useful, calculating confidence intervals for a given confidence level is a very useful skill.
TL;DR (Too Long; Didn’t Read)
Calculate a confidence interval for a given confidence level by multiplying the standard error by the Z score for your chosen confidence level. Subtract this result from your sample mean to get the lower bound, and add it to the sample mean to find the upper bound. (See Resources)
Repeat the same process but with the t score in place of the Z score for smaller samples (n < 30).
Find a confidence level for a data set by taking half of the size of the confidence interval, multiplying it by the square root of the sample size and then dividing by the sample standard deviation. Look up the resulting Z or t score in a table to find the level.
The Difference between Confidence Level vs. Confidence Interval
When you see a statistic quoted, there is sometimes a range given after it, with the abbreviation “CI” (for “confidence interval”) or simply a plus-minus symbol followed by a figure. For instance, “the mean weight of an adult male is 180 pounds (CI: 178.14 to 181.86)” or “the mean weight of an adult male is 180 ± 1.86 pounds.” These both tell you the same information: based on the sample used, the mean weight of a man probably falls within a certain range. The range itself is called the confidence interval.
If you want to be as sure as possible that the range contains the true value, then you can widen the range. This would increase your “confidence level” in the estimate, but the range would cover more potential weights. Most statistics (including the one quoted above) are given as 95 percent confidence intervals, which mean that there is a 95 percent chance that the true mean value is within the range. You can also use a 99 percent confidence level or a 90 percent confidence level, depending on your needs.
Calculating Confidence Intervals or Levels for Large Samples
When you use a confidence level in statistics, you usually need it to calculate a confidence interval. This is a bit easier to do if you have a large sample, for example, over 30 people, because you can use Z score for your estimate rather than more complicated t scores.
Take your raw data and calculate the sample mean (simply add up the individual results and divide by the number of results). Calculate the standard deviation by subtracting the mean from each individual result to find the difference and then square this difference. Add up all of these differences and then divide the result by the sample size minus 1. Take the square root of this result to find the sample standard deviation (See Resources).
Determine the confidence interval by first finding the standard error:
SE=frac{s}{sqrt{n}}
Where s is your sample standard deviation and n is your sample size. For example, if you took a sample of 1,000 men to figure the average weight of a man, and got a sample standard deviation of 30, this would give:
SE=frac{30}{sqrt{1000}}=0.95
To find the confidence interval from this, look up the confidence level you want to calculate the interval for in a Z-score table and multiply this value by the Z score. For a 95 percent confidence level, the Z-score is 1.96. Using the example, this means:
text{mean }pm Ztimes SE=180text{ pounds }pm1.96times 0.95=180pm1.86text{ pounds}
Here, ± 1.86 pounds is the 95 percent confidence interval.
If you have this bit of information instead, along with the sample size and the standard deviation, you can calculate the confidence level by using the following formula:
Z=0.5times{ size of confidence interval }timesfrac{sqrt{n}}{s}
The size of the confidence interval is just twice the ± value, so in the example above, we know 0.5 times this is 1.86. This gives:
Z=1.86timesfrac{sqrt{1000}}{30}=1.96
This gives us a value for Z, which you can look up in a Z-score table to find the corresponding confidence level.
Calculating Confidence Intervals for Small Samples
For small samples, there is a similar process for calculating the confidence interval. First, subtract 1 from your sample size to find your “degrees of freedom.” In symbols:
df=n-1
For a sample n = 10, this gives df = 9.
Find your alpha value by subtracting the decimal version of the confidence level (i.e. your percentage confidence level divided by 100) from 1 and dividing the result by 2, or in symbols:
alpha=frac{(1-text{ decimal confidence level})}{2}
So for a 95 percent (0.95) confidence level:
alpha=frac{(1-0.95)}{2}=0.025
Look up your alpha value and degrees of freedom in a (one tail) t distribution table and make note of the result. Alternatively, omit the division by 2 above and use a two-tail t value. In this example, the result is 2.262.
As in the previous step, calculate the confidence interval by multiplying this number by the standard error, which is determined using your sample standard deviation and sample size in the same way. The only difference is that in place of the Z score, you use the t score.
В практической и научно-практической работе
врачи обобщают результаты, полученные как правило на выборочных
совокупностях.
Для более широкого распространения и применения полученных при изучении
репрезентативной выборочной совокупности данных и выводов
надо уметь по части явления судить о явлении и его закономерностях в
целом.
Учитывая, что врачи, как правило, проводят исследования на
выборочных совокупностях, теория статистики позволяет с помощью
математического аппарата (формул) переносить данные с выборочного
исследования на генеральную совокупность. При этом врач должен
уметь не только воспользоваться математической формулой, но сделать
вывод, соответствующий каждому способу оценки достоверности
полученных данных. С этой целью врач должен знать способы оценки
достоверности.
Применяя метод оценки достоверности результатов исследования для изучения общественного здоровья и деятельности учреждений
здравоохранения, а также в своей научной деятельности, исследователь должен уметь правильно выбрать способ данного метода.
Среди методов оценки достоверности различают параметрические и непараметрические.
Параметрическими называют количественные методы статистической обработки данных, применение которых требует обязательного
знания закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Непараметрическими являются количественные методы статистической обработки данных, применение которых не требует знания
закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Как параметрические, так и непараметрические методы, используемые
для сравнения результатов исследований, т.е. для сравнения
выборочных совокупностей, заключаются в применении определенных формул и
расчете определенных показателей в соответствии с
предписанными алгоритмами. В конечном результате высчитывается
определенная числовая величина, которую сравнивают с табличными
пороговыми значениями. Критерием достоверности будет результат сравнения
полученной величины и табличного значения при данном числе
наблюдений (или степеней свободы) и при заданном уровне безошибочного
прогноза.
Таким образом, в статистической процедуре оценки основное
значение имеет полученный критерий достоверности, поэтому сам способ
оценки достоверности в целом иногда называют тем или иным критерием по
фамилии автора, предложившего его в качестве основы метода.
Применение параметрических методов
При проведении выборочных исследований полученный результат не обязательно совпадает с результатом, который мог бы быть получен
при исследовании всей генеральной совокупности. Между этими величинами существует определенная разница, называемая ошибкой
репрезентативности, т.е. это погрешность, обусловленная переносом результатов выборочного исследования на всю генеральную
совокупность.
Определение доверительных границ средних
и относительных величин
Формулы определения доверительных границ представлены следующим образом:
- для средних величин (М): Мген = Мвыб ± tm
- для относительных показателей (Р): Рген = Рвыб ± tm
где Мген и Рген — соответственно, значения средней величины и относительного показателя генеральной
совокупности;
Мвы6 и Рвы6 — значения средней величины и относительного показателя выборочной совокупности;
m — ошибка репрезентативности;
t — критерий достоверности (доверительный коэффициент).
Данный способ применяется в тех случаях, когда по результатам выборочной совокупности необходимо судить о размерах изучаемого
явления (или признака) в генеральной совокупности.
Обязательным условием для применения способа является репрезентативность выборочной совокупности. Для переноса результатов,
полученных при выборочных исследованиях, на генеральную совокупность необходима степень вероятности безошибочного прогноза (Р),
показывающая, в каком проценте случаев результаты выборочных исследований по изучаемому признаку (явлению) будут иметь место в
генеральной совокупности.
При определении доверительных границ средней величины или относительного показателя генеральной совокупности, исследователь сам
задает определенную (необходимую) степень вероятности безошибочного прогноза (Р).
Для большинства медико-биологических исследований считается
достаточной степень вероятности безошибочного прогноза, равная 95%,
а число случаев генеральной совокупности, в котором могут наблюдаться
отклонения от закономерностей, установленных при выборочном
исследовании, не будут превышать 5%. При ряде исследований, связанных,
например, с применением высокотоксичных веществ, вакцин,
оперативного лечения и т.п., в результате чего возможны тяжелые
заболевания, осложнения, летальные исходы, применяется степень
вероятности Р = 99,7%, т.е. не более чем у 1% случаев генеральной
совокупности возможны отклонения от закономерностей,
установленных в выборочной совокупности.
Заданной степени вероятности (Р) безошибочного прогноза соответствует определенное, подставляемое в формулу, значение критерия
t, зависящее также и от числа наблюдений.
При n>30 степени вероятности безошибочного прогноза Р = 99,7% — соответствует значение t = 3, а при Р = 95,5% — значение
t = 2.
При п<30 величина t при соответствующей степени вероятности безошибочного прогноза определяется по специальной таблице
(Н.А. Плохинского).
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген)
при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80
ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной
совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m):
m = σ / √n =
6 / √36 =
±1 удар в минуту - Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t,
определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2
удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р =
95%, что средняя частота пульса в генеральной совокупности,
т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в
аналогичных условиях будет находиться в пределах от 78 до 82
ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в
минуту возможна не более, чем у 5% случаев генеральной
совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности
(Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18%
случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя
генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя:
m = √P x q / n =
√18 x (100 — 18) / 164 =
± 3% - Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2).
Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у
детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
Оценка достоверности разности результатов исследования
Данный способ применяется в тех случаях, когда необходимо определить, случайны или достоверны (существенны), т.е. обусловлены
какой-то причиной, различия между двумя средними величинами или относительными показателями.
Обязательным условием для применения данного способа является репрезентативность выборочных совокупностей, а также наличие
причинно-следственной связи между сравниваемыми величинами (показателями) и факторами, влияющими на них.
Формулы определения достоверности разности представлены следующим образом:
Если вычисленный критерий t более или равен 2 (t ≥ 2), что соответствует вероятности безошибочного прогноза Р равном или
более 95% (Р ≥ 95%), то разность следует считать достоверной (существенной), т.е. обусловленной влиянием какого-то фактора, что
будет иметь место и в генеральной совокупности.
При t < 2, вероятность безошибочного прогноза Р < 95%, это означает, что разность недостоверна, случайна, т.е. не
обусловлена какой-то закономерностью (не обусловлена влиянием какого-то фактора).
Поэтому полученный критерий должен всегда оцениваться по отношению к конкретной цели исследования.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума
и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у водителей сельскохозяйственных
машин через 1 ч после начала работы составила 80 ударов в
минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы
водителей до начала работы равнялась 75 ударам в минуту;
m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч
работы.
Решение.
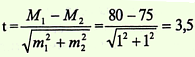
Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно
утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а
достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение
осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24%
(m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.
![]()
Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в
частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено
влиянием возраста детей.
Типичные ошибки, допускаемые исследователями при
применении способа оценки достоверности разности результатов исследования
- При оценке достоверности разности результатов исследования по критерию t часто делается вывод о достоверности (или
недостоверности) самих результатов исследования. В действительности же этот способ позволяет судить только о достоверности
(существенности) или случайности различий между результатами исследования. - При полученном значении критерия t<2 часто делается вывод о необходимости увеличения числа наблюдений. Если же
выборочные совокупности репрезентативны, то нельзя делать вывод о необходимости увеличения числа наблюдений, т.к. в данном
случае значение критерия t<2 свидетельствует о случайности, недостоверности различия между двумя сравниваемыми результатами
исследования.
Применение методов статистического анализа для изучения общественного здоровья и здравоохранения.
Под ред. чл.-корр. РАМН, проф. В.З.Кучеренко. М., «Гэотар-Медиа», 2007, учебное пособие для вузов
- Власов В.В. Эпидемиология. — М.: ГЭОТАР-МЕД, 2004. — 464 с.
- Лисицын Ю.П. Общественное здоровье и здравоохранение. Учебник для вузов. — М.: ГЭОТАР-МЕД, 2007. — 512 с.
- Медик В.А., Юрьев В.К. Курс лекций по общественному здоровью
и здравоохранению: Часть 1. Общественное здоровье. — М.: Медицина,
2003. — 368 с. - Миняев В.А., Вишняков Н.И. и др. Социальная медицина и организация здравоохранения (Руководство в 2 томах). — СПб, 1998. -528 с.
- Кучеренко В.З., Агарков Н.М. и др.Социальная гигиена и организация здравоохранения (Учебное пособие) — Москва, 2000. — 432 с.
- С. Гланц. Медико-биологическая статистика. Пер с англ. — М., Практика, 1998. — 459 с.
Тот или иной вывод
с некоторой вероятностью может оказаться
ошибочным, причем эта вероятность тем
меньше, чем больше имеется данных для
обоснования этого вывода. Таким образом,
чем больше получено результатов, тем в
большей степени по различиям между
двумя выборками можно судить о том, что
действительно имеет место в той популяции,
из которой взяты эти выборки.
Однако
обычно используемые выборки относительно
невелики, и в этих случаях вероятность
ошибки может быть значительной. В
гуманитарных науках принято считать,
что разница между двумя выборками
отражает действительную разницу между
соответствующими популяциями лишь в
том случае, если вероятность ошибки для
этого утверждения не превышает 5%, т.е.
имеется лишь 5 шансов из 100 ошибиться,
выдвигая такое утверждение. Это так
называемый уровень
достоверности (уровень
надежности, доверительный уровень)
различия. Если этот уровень не превышен,
то можно считать вероятным,
что
выявленная нами разница действительно
отражает положение дел в популяции
(отсюда еще одно название этого критерия
— порог вероятности).
Для
каждого статистического метода этот
уровень можно узнать из таблиц
распределения критических значений
соответствующих критериев (t,
2
и т.д.); в этих таблицах приведены цифры
для уровней 5% (0,05), 1% (0,01) или еще более
высоких. Если значение критерия для
данного числа степеней свободы (см.
дополнение Б.4) оказывается ниже
критического уровня, соответствующего
порогу вероятности 5%, то нулевая гипотеза
не может считаться опровергнутой, и это
означает, что выявленная разница
недостоверна.
Параметрические
методы
Метод Стьюдента (f-тест)
Это параметрический
метод, используемый для проверки гипотез
о достоверности разницы средних при
анализе количественных данных о
популяциях с нормальным распределением
и с одинаковой вариансой*.
* К сожалению, метод
Стьюдента слишком часто используют для
малых выборок, не убедившись предварительно
в том, что данные в соответствующих
популяциях подчиняются закону нормального
распределения (например, результаты
выполнения слишком легкого задания, с
которым справились все испытуемые, или
же, наоборот, слишком трудного задания
не дают нормального распределения).
Метод Стьюдента
различен для независимых и зависимых
выборок. Независимые выборки получаются
при исследовании двух различных

групп испытуемых (в
нашем эксперименте это контрольная и
опытная : группы). В случае независимых
выборок для анализа разницы средних
применяют формулу

где
1—
средняя
первой выборки;
2-средняя
второй выборки;
s1—
стандартное
отклонение
для
первой выборки;
s2
— стандартное
отклонение для второй выборки;
n1
и
п2
— число
элементов в первой
и
второй выборках.
Теперь
осталось лишь найти в таблице значений
t
(см.
дополнение Б.5) величину, соответствующую
п
— 2
степеням
свободы, где п
— общее число испытуемых в обеих
выборках
(см. дополнение Б.4), и сравнить эту
величину с результатом расчета по
формуле.
Если
наш результат больше, чем значение для
уровня достоверности 0,05 (вероятность
5%), найденное в таблице, то можно отбросить
нулевую гипотезу (Н0)
и принять альтернативную гипотезу (Н1)
т.е. считать разницу средних достоверной.
Если
же, напротив, полученный при вычислении
результат меньше, чем табличный (для п
— 2
степеней
свободы), то нулевую гипотезу нельзя
отбросить и, следовательно, разница
средних недостоверна.
В нашем эксперименте
с помощью метода Стьюдента для независимых
выборок можно было бы, например, проверить,
существует ли достоверная разница между
фоновыми уровнями (значениями, полученными
до воздействия независимой переменной)
для двух групп. При этом мы получим:

Сверившись
с таблицей значений t,
мы
можем прийти к следующим выводам:
полученное нами значение t
= 0,53 меньше того, которое соответствует
уровню достоверности 0,05 для 26 степеней
свободы (
= 28);
следовательно, уровень вероятности для
такого t
будет
выше 0,05 и нулевую гипотезу нельзя
отбросить; таким образом, разница между
двумя выборками недостоверна, т. е. они
вполне могут принадлежать к одной
популяции.
Сокращенно этот
вывод записывается следующим образом:
t
=
0,53;
=
28; р
> 0,05;
недостоверно.
Однако
наиболее полезным г-тест окажется для
нас при проверке
гипотезы
о достоверности разницы средней между
результатами опытной и контрольной
групп после воздействия 1. Попробуйте
сами найти для этих выборок значения и
сделать соответствующие выводы:
* Как
уже говорилось, поскольку объем выборок
в данном случае невелик, а результаты
опытной группы после воздействия не
соответствуют нормальному распределению,
лучше использовать непараметрический
метод, например U-тест
Манна — Уитни.
![]()
Значение
t
…..,
чем табличное для 0,05 (….. степеней
свободы). Следовательно, ему соответствует
порог вероятности ….., чем 0,05.
В
связи с этим нулевая гипотеза может (не
может) быть отвергнута. Разница между
выборками достоверная (недостоверна?):
t
=…..;
=…..; Р…..(<,
=, > ?) 0,05;…..
Доверительный уровень и доверительный интервал: в чем разница?
17 авг. 2022 г.
читать 2 мин
Часто в статистике нас интересует измерение параметров совокупности — чисел, описывающих некоторые характеристики всей совокупности .
Например, нас может заинтересовать измерение среднего роста мужчин в определенной стране.
Поскольку сбор данных о росте каждого мужчины в стране требует слишком больших затрат и времени, вместо этого мы будем собирать данные по простой случайной выборке мужчин. Затем мы использовали бы средний рост мужчин в этой выборке для оценки среднего роста всех мужчин в стране.
К сожалению, средний рост мужчин в выборке не обязательно точно соответствует среднему росту мужчин во всей популяции. Например, мы можем случайно выбрать выборку, полную более низких мужчин, или, возможно, выборку, полную более высоких мужчин.
Чтобы зафиксировать нашу неопределенность вокруг нашей оценки истинного среднего значения генеральной совокупности, мы можем создать доверительный интервал.
Доверительный интервал: диапазон значений, который может содержать параметр генеральной совокупности с определенным уровнем достоверности.
Доверительный интервал рассчитывается по следующей общей формуле:
Доверительный интервал = (точечная оценка) +/- (критическое значение) * (стандартная ошибка)
Например, формула для расчета доверительного интервала для среднего значения генеральной совокупности выглядит следующим образом:
Доверительный интервал = x +/- z*(s/ √n )
куда:
- x : выборочное среднее
- z: критическое значение z
- s: стандартное отклонение выборки
- n: размер выборки
Критическое значение z, которое вы будете использовать в формуле, зависит от выбранного вами уровня достоверности .
Уровень уверенности: процент всех возможных выборок, которые, как ожидается, будут включать истинный параметр генеральной совокупности.
Наиболее распространенные уровни достоверности включают 90%, 95% и 99%.
В следующей таблице показано критическое значение z, которое соответствует этим популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z критическое значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, предположим, что мы измерили рост 25 мужчин и нашли следующее:
- Размер выборки n = 25
- Средняя высота образца x = 70 дюймов
- Стандартное отклонение выборки s = 1,2 дюйма
Вот как найти вычислить доверительный интервал для истинного среднего роста населения, используя уровень достоверности 90% :
90% доверительный интервал: 70 +/- 1,645*(1,2/√25) = [69,6052, 70,3948]
Это означает, что если бы мы использовали один и тот же метод выборки для выбора разных выборок и рассчитали доверительный интервал для каждой выборки, мы ожидали бы, что истинный средний рост населения попадет в интервал в 90% случаев.
Теперь предположим, что вместо этого мы вычисляем доверительный интервал, используя уровень достоверности 95%:
95% доверительный интервал: 70 +/- 1,96*(1,2/√25) = [69,5296, 70,4704]
Обратите внимание, что этот доверительный интервал шире, чем предыдущий. Это связано с тем, что чем выше уровень достоверности, тем шире доверительный интервал.
Чем выше уровень достоверности, тем шире доверительный интервал.
Это должно иметь смысл интуитивно: более широкий уровень достоверности имеет более высокую вероятность содержать истинный параметр генеральной совокупности.
Резюме
В итоге:
Доверительный интервал — это диапазон значений, который может содержать параметр генеральной совокупности с определенным уровнем достоверности. Он использует следующую основную формулу:
Доверительный интервал = (точечная оценка) +/- (критическое значение) * (стандартная ошибка)
Уровень достоверности определяет критическое значение для использования в этой формуле. Чем выше уровень достоверности, тем больше критическое значение и, следовательно, тем шире доверительный интервал.
Дополнительные ресурсы
Введение в доверительные интервалы
Введение в проверку гипотез
Что такое точечная оценка?