
Чем опасны дубли страниц
Во всех поисковых системах дублированные страниц негативно влияют на продвижение, так как поисковики видят несколько полностью релевантных страниц для одного и того же запроса, и в результаты органической выдачи будут добавляться постоянно разные страницы. Известно, что из-за дубликатов позиции проседают на 10-30 пунктов буквально за 2-3 недели. Чтобы избежать этого, советуем хотя бы 1 раз в месяц проверять контент и мета-теги. Как найти дубли страниц сайта — читайте в этой статье.
Поиск дубликатов страниц
1. Фразы в кавычках
Простой и доступный способ найти дубли страниц в Яндексе, хотя далеко не самый эффективный.
— выделяем 5-7 слов без знаков препинаний и заглавных букв;;
— включаем расширенный поиск по сайту;
— ставим весь текст в кавычки и копируем в адресную строку Яндекса.
В результатах выдачи получаем страницы, где есть точное вхождение данной фразы. Если есть 2 или более страниц — верный сигнал того, что у нас есть дублированный контент.
2. Сервер для проверки уникальности текста
На наш взгляд, наиболее эффективный способ поиска дублированного контента. Копируем текст и заливаем его на проверку уникальности в любой автоматический сервер. На выходе имеем полную картину о дубликатах.
— какие именно куски текста имеют дубликаты;
— адреса одинаковых страниц;
Чтобы не попасть под различные фильтры поисковых систем, делаем такую проверку для продвигаемых страниц ежемесячно. Для небольшого сайта поиск дубликатов таким образом занимает не много времени, но позволяет избежать неприятностей.
3. Программы-пауки
Бесплатные программы-пауки, которые определяют на каждой странице (даже те, которые не в индексе) мета-теги и теги h1.Вбиваем УРЛ сайта, и программа начинает парсить данные. В зависимости от количества страниц, процесс занимает до нескольких часов. В результатах получаем таблицу с множеством столбцов. Нас интересуют только мета-теги: title, description, keyword, тег h1 и адреса страниц:
Проверяем глазами – на одинаковые значения и устраняем ошибки. Этот способ хорош тем, что позволяет найти не только дублированный контент, но и одинаковые мета-теги. А как говорилось в предыдущих статьях, за идентичные мета-теги вырастает вероятность наложения фильтра, особенно это касается Google.
4. Гугл Вебмастер: оптимизация HTML
Полезный инструмент для поиска дублей находится в панели Гугл-вебмастер. Заходим в панель для веб-мастеров Google и переходим в раздел – “Вид в поиске”, там выбираем вкладку – “Оптимизация HTML”. Гугл сообщает нам о дубликатах мета-тегов и предоставляет рекомендации по их устранению.
5. Ручная проверка выдачи
Длительный и затруднительный способ, который требует много внимания. Но если есть желания и силы, то можно и воспользоваться. Данный метод позволяет найти дубли страниц, которые существуют из-за технических проблем с сайтом. Например, распространенная ошибка — сайт доступен по адресам www. site.com ww.site.com site.com. Довольно редко, но вероятность есть.
Как убрать дубли страниц
1. Если дублируется контент, то достаточно переписать текст, через некоторое время поисковики проиндексируют сайт, и дублированный контент исчезнет из основного поиска.
2. При наличие одинаковых мета-тегов, находим причину (возможно, происходит автоматическая генерация) и устраняем неполадки.
3. Если дубли страниц образуются вследствие действия фильтров, то закрываем подобные страницы в файле robots.txt. Особенно характерно для интернет-магазинов.
А теперь рассмотрим типичные дубли для наиболее популярных CMS: Joomla и Openstat.
Joomla — дубли страниц
Для любых версий этой CMS наиболее характерны 2 типа дубликатов. Давайте рассмотрим подробнее, как убрать дубли страниц Joomla.
1. Дубли главной страницы
В следствии технических ошибок сайта, на Joomla появляются дубликаты или полу-дубликаты главной страницы. Обязательно проверяем “морду” любым из предложенных способов и устраняем проблемы. Чаще всего необходимо закрыть дубли в файле robots.txt
2. Дубли модуля статей
Для Joomla существуют много модулей для статей, которые дублируют контент новых статей на одну страницу – Статьи. То есть на одной страницы мы получаем сразу все материалы. В более современных версиях такого уже не встретишь.
Чтобы устранить проблему – просто закрываем общую страницу статей от индексации.
Дубли страниц Opencart
Для данного CMS характерно наличие множества фильтров, которые создают дублированный контент. Чтобы решить проблему – закрываем все подобные фильтры от индикации.
Дублированные страницы – характерная проблема абсолютно для всех сайтов без исключения. Используйте вышеприведенные методы для поиска дубликатов, ежемесячно делайте мониторинг сайта и устраняйте проблемы, тогда степень доверия поисковых система к вашему ресурсу останется на высоком уровне.
Я расскажу, как быстро найти дубли страниц и обезопасить себя от негативных последствий, к которым они могут привести.
Материал в первую очередь будет полезен как практикующим SEO-специалистам, так и владельцам сайтов. Но для начала давайте совсем быстро пробежимся по теории.
Немного теории
Наверняка многие слышали, что дубли страниц — это плохо. Подробно останавливаться на данном вопросе не буду, так как тема популярная, и качественной информации в интернете, даже появившейся в последнее время, много. Отмечу только неприятности, которые могут появиться у сайта при наличии дублей:
- проблемы с индексацией (особенно актуально для крупных сайтов);
- размытие релевантности и ранжирование нецелевых страниц;
- потеря естественных ссылок, которые могут появляться на страницах дублей;
- общая пессимизация проекта и санкции поисковых систем.
Поэтому в процессе продвижения проектов этому вопросу должно уделяться особое внимание.
Также стоит вкратце остановится на двух разновидностях дублей:
- Полные дубли — это когда один и тот же контент доступен по разным URL. Например: http://www.foxtrot.com.ua/ и https://www.foxtrot.com.ua/.
- Частичные дубли — когда страницы имеют общую семантику, решают одни и те же задачи пользователей и имеют похожий контент, но не являются полными дублями. Да, получилось достаточно запутанно, поэтому предлагаю рассмотреть пример: https://vc.ru/category/телеграм и https://vc.ru/category/telegram.
Обе страницы имеют общую семантику, похожий контент и решают одни и те же задачи пользователей, но при этом не являются полными дублями, так как содержимое страниц разное.
Выявить полные дубли намного проще, да и проблем они могут привести куда больше из-за своей массовости, а вот с неполными дублями нужно работать точечно и избавляться от них при формировании правильной структуры сайта. Далее в этой статье под дублями будут подразумеваться полные дубли.
Итак, мы определились, что проект не должен содержать дубли. Точка. Особенно критично, когда дубли начинают индексироваться поисковыми системами. И чтобы этого не случилось, а также для предотвращения других негативных последствий, их нужно выявлять и устранять. О том, как с ними бороться, можно найти много материалов, но если в комментариях будут просьбы рассказать подробнее, то я обязательно это сделаю в одной из следующих статей.
Чтобы никого не запутать, сейчас опустим момент с формированием нужных дублей (например, страниц с UTM-метками).
Выявление полных дублей
Обычно специалисты проверяют у продвигаемого проекта наличие следующих дублей:
1. Дубли страниц с разными протоколами: http и https.
2. С www и без www.
3. Со слешем на конце URL и без него.
При этом каждая страница содержит canonical на себя.
4. Строчные и прописные буквы во вложенностях URL.
Это пример того, как на разных типах страниц один и тот же принцип формирования дублей обрабатывается по-разному.
5. Добавления в конце URL:
index.php
home.php
index.html
home.html
index.htm
home.htm
Как видно, оба URL проиндексированы в «Яндексе»:
А разве это все возможные дубли?
В своей практике я сталкивался с огромным количеством примеров формирования дублей, и самые популярные, которые встречались не единожды, я укажу ниже:
6. Множественное добавление ////////////////// в конце URL.
7. Множественное добавление ////////////////// между вложенностями.
Очень часто встречающаяся ошибка.
8. Добавление произвольных символов в конец URL, формируя новую вложенность.
9. Добавление произвольных символов в существующую вложенность.
10. Добавление вложенности с произвольными символами.
Не совсем дубль, но страница отдаёт 200-й код ответа сервера, что позволит ей попасть в индекс.
11. Добавление * в конце URL.
12. Замена нижнего подчеркивания на тире и наоборот.
13. Добавление произвольных цифр в конце URL, формируя новую вложенность.
Такие дубли часто формируются со страниц публикаций на WordPress.
14. Замена вложенностей местами.
15. Отсутствие внутренней вложенности.
Пункты 14 и 15 опять же не являются полными дублями, но аналогично пункту 10 отдают 200 код ответа сервера.
16. Копирование первой вложенности и добавление её в конец URL.
17. Дубли .html, .htm или .php для страниц, которые заканчиваются на один из этих расширений.
Например:
- http://sad-i-ogorod.ru/shop/11041.php;
- http://sad-i-ogorod.ru/shop/11041.htm;
- http://sad-i-ogorod.ru/shop/11041.html.
Все приведённые выше типы дублей были выявлены в индексе поисковых систем более чем у нескольких проектов. Хотите ли вы рисковать появлением такого огромного количества дублей? Думаю, нет. Поэтому и важно выявить те дубли, которые формируются и обезопасить себя от попадания их в индекс поисковых систем. А практика показывает, что рано или поздно они находят и индексируют такие страницы, хотя ни внутренних, ни внешних ссылок на данные страницы нет.
Проверять вручную все эти дубли очень долго. К тому же важно проверять каждый тип страниц на наличие дублей. Почему? Да потому, что страницы категории товаров и страница определённого товара могут иметь разные дубли. Пример уже был ранее рассмотрен.
Также в большинстве сайтов могут использоваться разные CMS для разного типа контента. Нормальная практика, когда, например, интернет-магазин на OpenCart подключает блог на WordPress. Соответственно и дубли страниц этих CMS будут кардинально отличаться.
Поэтому мы и разработали сервис, который формирует все возможные страницы дублей и указывает их ответ сервера. В первую очередь сервис делали для своих нужд, ведь он экономит огромное количество времени специалистов, но с радостью готовы с ним поделиться.
Как с ним работать и как читать его результаты — сейчас будем разбираться.
Онлайн-сервис поиска дублей страниц
1. Для начала перейдите по ссылке.
2. Подготовьте разные типы страниц сайта, у которого хотите выявить возможные дубли.
Рекомендуемые к анализу типы страниц и их примеры:
- главная страница: http://www.foxtrot.com.ua/;
- страница категории: http://www.foxtrot.com.ua/ru/shop/noutbuki.html;
- целевая страница: http://www.foxtrot.com.ua/ru/shop/noutbuki_asus.html;
- страница товаров: http://www.foxtrot.com.ua/ru/shop/noutbuki_asus_f541nc-go054t.html;
- служебная страница: http://www.foxtrot.com.ua/ru/stores.
Для новостных и информационных ресурсов это могут быть:
- главная страница: https://www.maximonline.ru/;
- страница раздела: https://www.maximonline.ru/skills/lifehacking/;
- страница публикации или новости: https://www.maximonline.ru/guide/maximir/_article/myi-byili-v-55-sekundah-ot-strashnogo-pozora-ne-o/;
- страница тегов: https://www.maximonline.ru/tags/luchshie-lajfxaki-nedeli/;
- служебная страница: https://www.maximonline.ru/zhurnal/reklamnyj-otdel/_article/reklama-vmaxim/.
3. Вбиваем данные страницы в форму ввода и нажимаем кнопку «Отправить запрос»:
4. Запускается процесс обработки скрипта:
Немного ожидаем и получаем результат его работы по всем внедрённым страницам:
5. Анализируем результаты и подготавливаем рекомендации веб-программисту по устранению дублей.
Например, из вышеуказанного примера можно сделать следующие выводы:
- наличие дублей страниц с протоколами http и https;
- редирект со страницы без www на www происходит с помощью 302 редиректа (временный редирект);
- наличие дублей с добавление множественных слешей.
Соответственно, необходимо подготовить следующие рекомендации веб-разработчику:
1. Определиться, какой протокол всё же основной, и на страницы с этим протоколом настроить 301 редирект.
2. Изменить 302 редирект на 301 при перенаправлении страниц без www на аналогичные с www.
3. Настроить 301 редирект страниц со множественным добавлением слешей в конце URL на целевые страницы.
Важно понимать, что помимо шаблонных формирований дублей, указанных в данной статье, у вашего проекта могут формироваться уникальные дубли. Поэтому не забывайте мониторить страницы, которые попадают в индекс поисковых систем. Помогут в этом «Яндекс.Вебмастер» и Google Search Console.
Update
Сервис будет дорабатываться и дополняться полезными функциями. Так, выкатили обновление, позволяющее перед публикацией статьи определить изменения URL от исходного значения:
Если материал вам был полезен, прошу оценить его стрелкой вверх.
До скорых встреч и берегите ваши проекты.
Как обнаружить дубли страниц на сайте
Дубли — это страницы сайта с одинаковым или практически полностью совпадающим контентом. Наличие таких страниц может негативно сказаться на взаимодействии сайта с поисковой системой.
Чем вредны дубли?
Негативные последствия от дублей могут быть такими:
- Замедление индексирования нужных страниц. Если на сайте много одинаковых страниц, робот будет посещать их все отдельно друг от друга. Это может повлиять на скорость обхода нужных страниц, ведь потребуется больше времени, чтобы посетить именно нужные страницы.
- Затруднение интерпретации данных веб-аналитики. Страница из группы дублей выбирается поисковой системой автоматически, и этот выбор может меняться. Это значит, что адрес страницы-дубля в поиске может меняться с обновлениями поисковой базы, что может повлиять на страницу в поиске (например, узнаваемость ссылки пользователями) и затруднит сбор статистики.
Если на сайте есть одинаковые страницы, они признаются дублями, и в поиске тогда будет показываться по запросу только одна страница. Но адрес этой страницы в выдаче может меняться по очень большому числу факторов. Данные изменения могут затруднить сбор аналитики и повлиять на поисковую выдачу.
Как могут появиться дубли?
Дубли могут появиться на сайт в результате:
- Автоматической генерации. Например, CMS сайта создает ссылки не только с ЧПУ, но и техническим адресом: https://site.ru/noviy-tovar и https://site.ru/id279382.
- Некорректных настроек. К примеру, при неправильно настроенных относительных ссылках на сайте могут появляться ссылки по адресам, которых физически не существует, и они отдают такой же контент, как и нужные страницы сайта. Или на сайте не настроена отдача HTTP-кода ответа 404 для недоступных страниц — от них приходит «заглушка» с сообщением об ошибке, но они остаются доступными для индексирования.
- Ссылок с незначащими GET-параметрами. Зачастую GET-параметры не добавляют никакого контента на страницу, а используются, к примеру, для подсчета статистики по переходам — из какой-нибудь определенной социальной сети. Такие ссылки тоже могут быть признаны дублями (и недавно мы добавили специальное уведомление для таких ссылок, подробнее посмотреть можно тут).
- Ссылок со слешем на конце и без. Для поисковой системы сайты https://site.ru/page и https://site.ru/pages/ — это разные страницы (исключение составляет только главная страница, между https://site.ru/ и https://site.ru разницы нет).
Как обнаружить дубли
Теперь находить одинаковые страницы стало проще: в разделе «Диагностика» появилось специальное уведомление, которое расскажет про большую долю дублей на вашем сайте. Алерт появляется с небольшой задержкой в 2-3 дня — это обусловлено тем, что на сбор достаточного количества данных и их обработку требуется время. С этим может быть связано появление в нем исправленных страниц. Подписываться на оповещения не нужно, уведомление появится само.
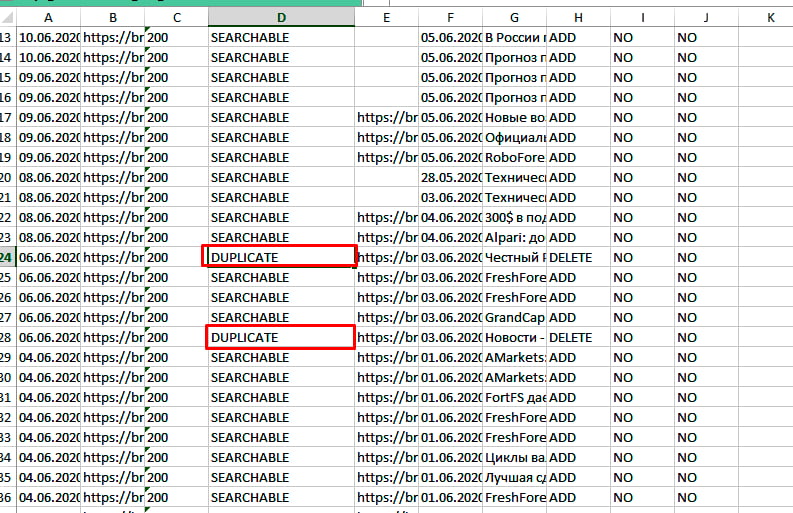
А если вы хотите найти дубли вручную, перейдите в Вебмастер, во вкладке «Индексирование» откройте «Страницы в поиске», нажмите на «Исключённые» в правой части страницы. Прокрутите вниз, в правом нижнем углу вы увидите опцию «Скачать таблицу». Выберите подходящий формат и загрузите архив. Откройте скачанный файл: у страниц-дублей будет статус DUPLICATE.
Обратите внимание, что ссылки на сайте с одинаковым контентом не всегда признаются дублирующими. Это может быть связано с тем, что поисковая система еще не успела проиндексировать дубли, или на момент их индексирования содержимое несколько различалось. Такое бывает, если страницы, к примеру, динамически обновляют часть контента, из-за чего поисковая система каждый раз получает немного разные версии, хотя по факту содержимое очень похоже. Например, когда на странице есть лента похожих товаров, которая постоянно обновляется. Если вы точно знаете, что такие страницы являются дублями, то необходимо оставить в поиске только нужные страницы.
Как оставить в поиске нужную страницу в зависимости от ситуации

В случае с «мусорными» страницами воспользуйтесь одним из способов:
- Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы-дубля;
- Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода;
- Если такой возможности нет, можно настроить HTTP-код ответа 403/404/410. Данный метод менее предпочтителен, так как показатели недоступных страниц не будут учитываться, и если где-то на сайте или в поиске еще есть ссылки на такие страницы, пользователь попадет на недоступную ссылку.
В случае со страницами-дублями воспользуйтесь одним из способов:
- Для дублей с незначащими GET-параметрами рекомендуем добавить в файл robots.txt директиву Clean-param. Директива Clean-param — межсекционная. Это означает, что она будет обрабатываться в любом месте файла robots.txt. Указывать ее для роботов Яндекса при помощи User-Agent: Yandex не требуется. Но если вы хотите указать директивы именно для наших роботов, убедитесь, что для User-Agent: Yandex указаны и все остальные директивы — Disallow и Allow. Если в robots.txt будет указана директива User-Agent: Yandex, наш робот будет следовать указаниям только для этой директивы, а User-Agent: * будет проигнорирован;
- Вы можете установить редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа. Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске;
- Также можно использовать атрибут rel=«canonical». При работе с атрибутом rel=«canonical» стоит учитывать, что если содержимое дублей имеет некоторые отличия или очень часто обновляется, то такие страницы все равно могут попасть в поиск из-за различий в этом содержимом. В этом случае рекомендуем использовать другие предложенные варианты.
Для страниц со слешем на конце и без рекомендуем использовать редирект 301. Можно выбрать в качестве доступной как ссылку со слешем, так и без него — для индексирования разницы никакой нет.
В случае с важными контентыми страницами для их индексирования и представления в поиске важно использовать:
- Файлы Sitemap;
- Метрику;
- Установку счётчика;
- Настройку обхода страниц роботами.
Подробные рекомендации о работе со страницами-дублями читайте в Справке.
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен
В статье рассказывается:
- Что такое дубли страниц на сайте
- Почему нужно избавляться от дублей страниц на сайте
- Виды дублей страниц на сайте
- Как найти дубли страниц на сайте
- Рабочие способы, как удалить дубли страниц на сайте
- Онлайн-сервисы проверки сайта на дубли страниц
- Поиск дублей страниц сайта на примерах
- Часто задаваемые вопросы про дубли страниц на сайте
Появление копий на сайте связано с разными причинами, но поисковик в них разбираться не будет. Он просто отметит для себя данный сайт как некорректный и снизит его позиции в поиске. А вот владельцу интернет-ресурса знать об этом необходимо: он должен как можно быстрее удалить дубли страниц на сайте и постараться не допустить их появления в будущем. Читая далее, вы поймете, как это сделать.
Что такое дубли страниц на сайте
Дубли — это разделы, в которых размещена одна и та же информация. Появиться они могут случайно, из-за того, что администратор изменил структуру сайта или некорректно разделил его на кластеры, из-за неправильной настройки или при автогенерации.
Продублированные элементы отрицательно сказываются на SEO-продвижении, потому что поисковики распознают их как неуникальные. Соответственно, из-за малосодержательных элементов снижается оценка всего сайта. Если вы хотите видеть своё детище в топе, то дубликаты надо постоянно отслеживать и быстро устранять.

Причины возникновения дублей страниц на сайте:
-
Системой управления контентом (CMS) пользуются многие разработчики, хотя именно она может стать причиной появления дублирующих разделов. К примеру, статья была написана для нескольких рубрик на ресурсе, но их домены входят в адрес сайта, где была размещена запись. В итоге образовались аналоги такого вида:
-
wiki.site.ru/blog1/info/
-
wiki.site.ru/blog2/info/
-
-
Технические разделы. Больше всего подобных ситуаций возникает при работе с Bitrix и Joomla. Например, когда разрабатываются функции сайта — поиск, фильтрация, генерация и так далее. Любая из них может сгенерировать параметрические адреса с одной и той же информацией по отношению к ресурсу без параметров в URL, например:
-
site.ru/rarticles.php
-
site.ru/rarticles.php?ajax=Y
-
-
Человеческий фактор. Ситуация обычно возникает из-за невнимательности администратора сайта, разместившего один и тот же текст в разных местах.
-
Технические ошибки. При использовании разных систем управления информацией со своими настройками неправильная генерация ссылок может привести к дублированию и даже зацикливанию, как в случае некорректной ссылки в системе Opencart:
-
site.ru/tools/tools/tools/…/…/…
-
Почему нужно избавляться от дублей страниц на сайте
Рассмотрим подробнее, чем грозит присутствие дублирующих разделов на сайте.
-
Ухудшается индексация сайта
Если в проекте из тысячи страниц появится хотя бы по одному дублю, то объем ресурса увеличится вдвое. А если их будет больше? Например, экспертиза одного новостного портала показала, что автоматическое размещение одной новости в каждом разделе приводит к появлению новой страницы сразу с несколькими дублями.

-
Неправильно распределяется внутренний ссылочный вес
Дубликат может появиться и в результате неправильно организованной перелинковки. В итоге страница-аналог приобретает больший вес, чем оригинал. Свою роль играют и посетители, попадающие на дублирующую копию, тем самым изменяя её показатели. В этом случае количество посещений на основной версии не изменится.
-
Меняется релевантная страница в поисковой выдаче
Поскольку сайт открыт для индексации, то поисковик, наткнувшись на копию, может посчитать её более релевантной запросу, чем оригинал. Происходящая при этом смена страницы в поисковой выдаче может заметно снизить позицию сайта.
-
Теряется внешний ссылочный вес
Заинтересовавшись вашим товаром или статьей, пользователь решил поделиться информацией и поставил ссылку на страницу. Если он побывал на дубле, то дал указатель именно на неё, а основная версия недосчитается полезной естественной ссылки.
Виды дублей страниц на сайте
Дубликаты бывают трех видов:
-
Полные — с полностью одинаковым контентом.
-
Частичные — с частично повторяющимся контентом.
-
Смысловые — когда несколько разделов несут один смысл, переданный разными словами.

Анализируя структуру сайта, эксперты чаще реагируют на полные совпадения, хотя поисковые системы замечают и частичные, и смысловые.
Полные
Полный аналог ухудшает факторы внутренней оптимизации всего сайта и затрудняет его продвижение в ТОП, что крайне нежелательно. Поэтому их надо ликвидировать сразу после обнаружения.
К ним относятся:
-
Версия с/без www. Возникает, если пользователь не указал зеркало в панели «Яндекса» и Google.
-
Различные варианты главной страницы:
-
site.net/index.html;
-
site.net/index/;
-
site.net/index;
-
site.net.
-
-
Страницы, которые появляются при ошибочной иерархии разделов:
-
site.net/category/gift/;
-
site.net/products/gift/;
-
site.net/products/category/gift/.
-
-
UTM-метки. Они используются, чтобы передавать данные для анализа рекламы и источника переходов. Поисковики их обычно не индексируют, но иногда бывают исключения.
-
GET-параметры в URL. Иногда при передаче данных GET-параметры попадают в адрес:
-
site.net/products/gift/page.php?color=red.
-
-
Разделы, сгенерированные реферальной ссылкой. Обычно их выделяют специальным параметром, добавляемым к URL. На такой ссылке должен стоять редирект на обычный URL, но этим часто пренебрегают.
-
Если неправильно настроить раздел с ошибкой 404, то он спровоцирует появление бесконечного количества дублей. Любые символы в адресе сайта автоматически превратятся в ссылку и без редиректа выдадут ошибку 404.
Прекратить появление дубликатов с полным совпадением можно, если поставить редирект, убрать ошибку программным путем или закрыть ресурс от индексации.
Частичные

Дубликаты с частичным совпадением меньше влияют на сайт. Трудно сказать, сколько дублей страниц сайта допустимо. Но если их слишком много, то это снижает позиции ресурса в поисковой выдаче, а также мешает его продвижению по конкретным ключевым запросам. Осталось выяснить, как частичные дубли появляются на сайте.
-
Характеристики в карточке товара
Описание товара на странице может иметь дополнительные вкладки, например отзывы или характеристики. Переключившись на одну из них, можно отследить изменение URL, хотя большая часть информации не меняется. Это и создает дубль.
-
Пагинация
Если система управления контентом настроена неверно, то при переходе на следующую страницу в одной категории URL меняется, а Title и Description остаются теми же. В результате получаем несколько различных ссылок с одинаковыми метатегами:
-
site.net/category/notebooks/?page=2;
-
site.net/category/notebooks/.
Поисковый алгоритм проиндексирует эти URL-адреса как разные документы. Этого можно избежать — надо лишь проверить реализацию вывода товаров и автогенерации с технической стороны.

Кроме этого, на каждом документе пагинации надо будет указать каноническую страницу как главную на сайте.
-
Подстановка контента
Когда владельцы ресурса хотят увеличить количество посещений по запросам с указанием города, они добавляют на сайт кнопку выбора региона. При переходе в другой город на странице с контактами меняется номер телефона. Но бывают случаи, когда в адресной строке появляется такой аргумент, как, например, «wt_city_by_default=..». В результате документ получает несколько дублей с разными ссылками. Подобная генерация недопустима, старайтесь использовать 301 редирект.
-
Версия для печати
Подразумевает точную копию содержимого раздела, но в другом, преобразованном формате, например:
-
site.net/blog/content;
-
site.net/blog/content/print — версия для печати.
Чтобы не создавать множество дубликатов, их надо закрывать от индексации в robots.txt.
Смысловые
Чтобы обнаружить смысловые дубли, а точнее статьи, написанные под запросы из одного кластера, необходимо провести парсинг сайта, например, с помощью программы Screaming Frog. Затем добавить в любой Hard-кластеризатор скопированные заголовки всех статей с порогом группировки 3,4. Смысловые дубли обязательно окажутся в одном кластере. Надо оставить лучшую статью, а с остальных поставить 301 редирект.
Как найти дубли страниц на сайте
Поняв, что такое дубли и чем грозит их появление на сайте, надо научиться их находить, чтобы потом удалить.

Рассмотрим несколько способов поиска дубликатов.
Поиск дублей с помощью поисковиков
Для Google достаточно указать в расширенном поиске адрес главной страницы, чтобы он выдал проиндексированный объем. Если же в поисковой строке задать адрес документа, который хотелось бы проверить, то система выложит перечень дублей, попавших в индексацию. В этом отношении работать с «Яндексом» проще: поисковик сразу показывает все копии проиндексированных страниц.
Если на вашем ресурсе много документов, для ускорения процесса анализа разбейте их на категории — товарные карточки, статьи в блоге, новости и так далее.
Если вы считаете, что дубли имеет конкретная страница, то на помощь придет поисковый запрос, сформированный из определенного фрагмента текста. Он складывается следующим образом: часть текста берется в кавычки, затем ставится пробел и оператор «site:». Здесь надо указать ваш сайт, на котором будет работать поисковый алгоритм. Например:
«Фрагмент текста со страницы сайта, которая может иметь дубли» site:examplesite.net
Если ваши сомнения не оправдались, то результатом станет та самая страница, которую вы подозревали в наличии дубликатов. Несколько документов, выданные в результате поиска, заставят задуматься о причинах размещения на них одинакового контента. Либо это и есть ожидаемые дубли, которые надо удалить.
Точно так же можно проанализировать сайт с помощью оператора «intitle:», который сравнит содержимое «Title» на представленных в выдаче страницах. Одинаковые метатеги могут быть признаком дубликата — проверить это можно с помощью поискового оператора «site:»:
site:examplesite.net intitle:полный или частичный текст тега Title.

Также с помощью операторов «site» и «inurl» вылавливаются продублированные документы, возникшие на страницах сортировок (sort) или при работе фильтров и поиска (filter, search). Чтобы найти, например, все страницы сортировок, надо задать в поисковой строке: site:examplesite.net inurl:sort. А для поиска страниц фильтров и поиска — site:examplesite.net inurl:filter, search.
Этот метод поиска ориентирован только на дубли, которые были проиндексированы системой. Поэтому полной гарантии того, что обнаружены все копии, он не дает.
Кейс: VT-metall
Узнай как мы снизили стоимость привлечения заявки в 13 раз для металлообрабатывающей компании в Москве
Узнать как
Программы и инструменты для поиска дублей
-
Программа XENU (Xenu Link Sleuth) позволяет провести аудит сайта и найти дубли, но только с полным совпадением. Для этого в специальную строку надо ввести URL сайта. Частичные повторы программа отследить не сможет.
-
Полные дубли можно обнаружить при помощи инструментов web-мастерской Google. Для этого надо в ней зарегистрироваться, и тогда в разделе «Оптимизация Html» появится перечень страниц с повторяющимся контентом и метатегами <Title>. Полностью дублированные документы в нём хорошо видны, но разделы с частичным совпадением определить невозможно.
-
Онлайн-seo-платформа Serpstat проводит технический seo-аудит сайта по 55+ ошибок. В неё входит и блок для распознавания и анализа дублируемого контента. Сервис способен найти полные дубликаты Title, Description, H1 на нескольких страницах. Он успешно распознает совпадение H1 и Title, замечает, когда на одной странице ошибочно прописали два метатега Title и не один заголовок формата H1.
Для работы с сервисом Serpstat надо в нём зарегистрироваться и открыть проект для технического аудита сайта.

-
Использование поисковых операторов. Для поиска дублей среди открытых для индексации страниц удобно использовать оператор «site:». Если ввести в строку поисковика (Google или «Яндекс») запрос «site:examplesite.net», то в общем индексе выйдут все страницы сайта. Их количество может сильно отличаться от найденных спайдером или от числа страниц в XML-карте. Проанализировав список выдачи, можно обнаружить и дублируемые, и мусорные разделы, которые необходимо закрыть от индексации.

Рабочие способы, как удалить дубли страниц на сайте
Прежде чем проводить регулярную чистку ресурса от дубликатов, неплохо было бы сначала удалить причину их появления. Иначе работа превратится в сизифов труд. Если программирование — ваш хлеб, то вы легко справитесь с ошибками в функционировании CMS. Или, чтобы не отнимать хлеб у программистов, пригласите знающего человека для наладки системы. После успешного решения проблемы можно заняться её последствиями.

-
Закрытие через robots.txt.
Текстовый файл robots.txt можно назвать в определенном смысле инструкцией по индексации ресурса для поисковых систем. С его помощью легко можно запретить индексацию разного рода служебных документов и выявленных дублей.
Директива Disallow не допускает поискового робота к индексации записанных в ней элементов:
-
• Disallow: /dir/ — директория dir запрещена для индексации.
-
• Disallow: /dir —
директория dir и все вложенные документы запрещены для индексации. -
• Disallow: *XXX — все страницы, в URL которых встречается набор символов XXX, запрещены для индексации.
При заполнении директивы требуется внимательность, чтобы не спрятать от поисковиков основные разделы или не скрыть от них вообще весь сайт.
Роботы послушно обходят стороной указанные в Disallow страницы, но реагируют на её присутствие каждый по-своему. С течением времени «Яндекс» просто удалит все запрещенные директории из индекса, а Google может обойти запрет, если на конкретный документ настроены ссылки.
-
-
301 редирект. Этот способ удобен тем, у кого дублей не так много, а по каким-либо причинам их не хотелось бы закрывать от индексации, например из-за проставленной внешней ссылки. Как убрать дубли страниц на сайте в этом случае? Настройте 301 редирект с дубликата на основную страницу.
-
Link rel=«canonical». Когда к одному и тому же контенту можно попасть через разные URL, удобно будет воспользоваться методом указания канонической страницы. Для каждой такой статьи создается тег вида <link=«canonical» href=«http://site.ru/cat1/page.php»>, где http://site.ru/cat1/page.php — тот вариант URL записи, который надо проиндексировать.
Тег внедряется программным путем в каждый подобный пост, а далее, даже если у него будет 100 URL, поисковая система воспользуется только тем, который прописан в коде. И не заметит те документы, у которых собственный URL отличается от URL, обозначенного в link rel=«canonical».
-
Google Search Console. Прием, не отличающийся популярностью, но вполне работающий. Им можно воспользоваться в разделе «Сканирование» — «Параметры URL» из Google Search Console.

Таблица содержит в себе необходимые параметры URL. Добавляя другие, мы сообщаем поисковому роботу, что страницы с дополнительными данными не изменяют содержимое раздела, поэтому индексировать их необязательно. Правда, возможен и такой вариант, когда при добавлении нового параметра в адрес содержимое раздела перемешивается, сохраняя свой состав без изменения. Например, это может быть сортировка записей в категории по популярности.
Дав необходимую информацию поисковику, владелец ресурса тем самым помогает Google точнее проанализировать сайт в процессе его сканирования. Но решение вопроса об индексации документов с добавленными параметрами в URL лучше предоставить «На усмотрение робота Googlebot&rauqo».
Онлайн-сервисы проверки сайта на дубли страниц
Как найти контент, представляющий собой дубликат оригинала? Для этого разработаны поисковые программы и сервисы онлайн-проверки. Одни из них платные, другие — бесплатные, часть — условно-бесплатные, предлагающие пробную версию на какое-то время или ограничивающие функционал до принятия решения об оплате.

Xenu — бесплатный аналог предыдущих программ. С её помощью на предмет поиска дублирующих разделов можно проанализировать даже сайт, не прошедший индексацию.
При сканировании программа найдет повторяющиеся заголовки и метатеги.
-
Яндекс.Вебмастер
Удобно и просто работать с Яндекс-панелью. Чтобы узнать о наличии дублей, необходимо:
-
выбрать вкладку «Индексирование»;
-
открыть раздел «Страницы в поиске»;
-
посмотреть количество «Исключенных страниц».
Причины исключения из индексации прописываются под ссылками. Они бывают разными, в том числе из-за идентичного текста.
-
-
Netpeak Spider
Netpeak Spider — платная программа с 14-дневным свободным доступом. Если провести поиск по заданному сайту, то программа покажет все найденные ошибки и дубликаты.
-
Xenu
-
Screaming Frog Seo Spider
Screaming Frog Seo Spider — условно-бесплатная программа, позволяющая быстро и эффективно проверить до 500 ссылок на наличие дублей. Если надо больше, придется заплатить или найти рабочий ключ в Интернете.
-
Сервис-лайфхак
Тем, у кого нет желания осваивать сервисные программы, подойдет Wizard.Sape. Технический аудит проводится в автоматическом режиме за 2–4 часа и стоит всего 690 рублей. В течение месяца ещё одну проверку можно устроить бесплатно. Инструмент собирает массу полезной информации для владельца ресурса и помимо найденных дублей разделов и метатегов показывает:
-
все 301 редиректы;
-
обработку заранее ошибочных адресов;
-
страницы, на которых нет контента;
-
битые внешние и внутренние ссылки и картинки.
-

Поиск дублей страниц сайта на примерах
Появление дублей происходит чаще всего по одним и тем же причинам. Поэтому продвигающие очередной проект разработчики в первую очередь обращают внимание на следующие ситуации:

-
Дубли разделов с разными протоколами: http и https.
Вот пример такого дубля: http://www.foxtrot.com.ua/ и https://www.foxtrot.com.ua/.
-
С www и без www.
Например: http://oknadeshevo.ru/ и http://www.oknadeshevo.ru/.
-
Со слешем на конце URL и без него.
Например: https://www.1tv.ru/live и https://www.1tv.ru/live/.
Еще пример: https://www.lamoda.ru/p/wa007ewbhbj9/clothes-wallis-bryuki и https://www.lamoda.ru/p/wa007ewbhbj9/clothes-wallis-bryuki/.
При этом на каждой странице прописана canonical на саму себя.
-
Строчные и прописные буквы во вложенностях URL.
Например: https://www.mosokna.ru/info/osteklenie-detskikh-sadov/ и https://www.mosokna.ru/info/OSTEKLENIE-DETSKIKH-SADOV/.
При том, что раздел https://www.mosokna.ru/PLASTIKOVYE-OKNA/ отдаёт код 404 ответа сервера.
Это пример того, как поисковые системы по-разному обрабатывают один и тот же принцип формирования дублей на разных типах документов.
-
Добавления в конце URL:
index.php
home.php
index.html
home.html
index.htm
home.htm
Например: https://www.eldorado.ru/cat/378830466/ и https://www.eldorado.ru/cat/378830466/index.html/.
Оба URL проиндексированы в «Яндексе».
-
Множественное добавление ////////////////// в конце URL.
Например, http://www.banki.ru/ и http://www.banki.ru////////.
-
Множественное добавление ////////////////// между вложенностями.
Например, https://moskva.beeline.ru/customers/products/mobile/services/details/nomer-na-vybor/krasivie-nomera/ и https://moskva.beeline.ru/customers///////products///////mobile///////services///////details///////nomer-na-vybor///////krasivie-nomera/.
Другой пример: https://f.ua/hewlett-packard/15-bs006ur-1zj72ea.html и https://f.ua/hewlett-packard///////15-bs006ur-1zj72ea.html.
Довольно часто встречающаяся ошибка.
-
Добавление произвольных символов в конец URL, формирующее новое вложение.
Например, https://apteka.ru/moskva/apteki/doktor-stoletov_16/ и https://apteka.ru/moskva/apteki/doktor-stoletov_16/Lfz/.
-
Добавление произвольных символов в существующее вложение.
Например, https://www.dochkisinochki.ru/brands/nutrilon/ и https://www.dochkisinochki.ru/brands/nutrilonbY5I/.
-
Добавление вложенности с произвольными символами.
Например, https://www.utkonos.ru/news/item/1343 и https://www.utkonos.ru/news/wg/item/1343.
Не совсем дубль, но страница отдаёт код 200 ответа сервера, а это дает ей право на индексацию.
-
Добавление * в конце URL.
Например, https://www.sportmaster.ru/product/10137329/ и https://www.sportmaster.ru/product/10137329/*/.
Ещё пример: https://docdoc.ru/clinic/set-evropeyskiy-medicinskiy-centr и https://docdoc.ru/clinic/set-evropeyskiy-medicinskiy-centr/*.
-
Замена нижнего подчеркивания «_» на тире «-» и наоборот.
Например, https://mamsy.ru/filter/zhenshinam_tovary_bolshie_razmery/ и https://mamsy.ru/filter/zhenshinam-tovary-bolshie-razmery/.
-
Добавление произвольных цифр в конце URL, что определяет новое вложение.
Например, https://apteka.ru/moskva/apteki/doktor-stoletov_16/ и https://apteka.ru/moskva/apteki/doktor-stoletov_16/2488/.
Этим часто грешат публикации на WordPress.
-
Перестановка вложенностей.
Например https://www.toy.ru/catalog/producers/BARBIE-Mattel/ и https://www.toy.ru/producers/catalog/BARBIE-Mattel/.
-
Пропущенное внутреннее вложение.
Например, https://www.toy.ru/catalog/producers/BARBIE-Mattel/ и https://www.toy.ru/producers/BARBIE-Mattel/.
Отметим, что пункты 14 и 15 не являются полными дублями, но аналогично пункту 10 отдают код 200 ответа сервера.
-
Копирование первой вложенности и добавление её в конец URL.
Например, https://www.dochkisinochki.ru/brands/nutrilon/ и https://www.dochkisinochki.ru/brands/nutrilon/brands/.
-
Дубли .html, .htm или .php для страниц, которые заканчиваются на одно из этих расширений.
Например:
• http://sad-i-ogorod.ru/shop/11041.php;
• http://sad-i-ogorod.ru/shop/11041.htm;
• http://sad-i-ogorod.ru/shop/11041.html.
Приведенные выше типы дублей реально существуют и были обнаружены в индексе поисковых систем нескольких проектов. Вряд ли кто-то из владельцев сайтов хотел бы получить такое огромное количество копий. Поэтому очень важно обнаружить их в процессе формирования и не допустить индексации поисковиками. Хотя на практике роботы такие документы всё-таки находят и индексируют их, причем без каких-либо внутренних или внешних ссылок.
Ручная проверка всех дублей займет много времени и всё равно не будет достаточно эффективной. Ведь на наличие копий надо проверять каждый тип документов. Категории товаров и определенный товар организованы по-разному и будут иметь разные дубли в случае их появления.
Многие сайты чаще всего используют разные CMS для определенного типа контента. Считается нормальным, когда к интернет-магазину на OpenCart подключен блог на WordPress. Понятно, что дубли разделов этих CMS будут так же отличаться друг от друга, как и сами системы.



Часто задаваемые вопросы про дубли страниц на сайте
-
«Многостраничные разделы (пагинация) — дубли или нет? Стоит закрывать их от индексации?»
Нет, многостраничники — это не дубли, потому что каждый раздел несет уникальный по отношению к другим директориям контент. Так что ни закрывать от индексации, ни ставить на первую страницу раздела rel=«canonical» не надо. К тому же поисковые системы умеют распознавать пагинацию. Для подстраховки достаточно проставить элементы микроразметки rel=«next» и rel=«prev».
Например:
<link rel=»next» href=»URL следующего по порядку документа раздела»>
<link rel=»prev» href=»URL предыдущего документа раздела»>
-
«URL с хештегами (#) — дубли или нет? Обязательно их удалять?»
Поисковики по умолчанию не обращают внимания на страницы с # в адресе и не индексируют их, так что можно не волноваться.
Скачайте полезный документ по теме:
Чек-лист: Как добиваться своих целей в переговорах с клиентами
Чтобы улучшить продвижение сайта, необходимо отслеживать появление на ресурсе дубликатов, полных или частичных, сгенерированных в результате технических ошибок или смысловых. Описанные в статье методы помогут вам их благополучно устранить.

Статья опубликована: 17.10.2019
Облако тегов
Понравилась статья? Поделитесь:
В статье про технический аудит сайта мы упомянули, что среди прочего SEO-специалисту важно проверить, а есть ли дубли страниц на продвигаемом им веб-ресурсе. И если они найдутся, то нужно немедленно устранить проблему. Однако там в рамках большого обзора я не хотел обрушивать на голову читателя кучу разнообразной информации, поэтому о том, что такое дубликаты страниц сайта, как их находить и удалять, мы вместе с вами детальнее рассмотрим здесь.
Почему и как дубли страниц мешают поисковому продвижению
Для начала отвечу на вопрос «Как?». Дубликаты страниц сильно затрудняют SEO, т. к. поисковые системы не могут понять, какую из веб-страниц им нужно показывать в выдаче по релевантным запросам. Поэтому чаще всего, чтобы не путаться, они понижают сайт в ранжировании или даже банят его, если проблема имеет массовый характер. После этого должно быть понятно, насколько важно сразу проверить продвигаемый ресурс на дубликаты.
Теперь давайте посмотрим, почему так получается, что дубли создают проблему? Для этого рассмотрим такой простой пример. Взгляните на следующее изображение и определите, какой из овощей наиболее точно соответствует запросу «спелый помидор»?

Хотя овощи немного отличаются размером, но все три из них подходят под категорию «спелого помидора». Поэтому сделать выбор в пользу одно из них довольно сложно.
Такая же дилемма встает перед поисковыми алгоритмами, когда они видят на сайте несколько одинаковых (полных) или почти одинаковых (частичных) копий одной и той же страницы.
Как наличие дублей сказывается на продвижении:
- Чаще всего падает релевантность основной продвигаемой страницы и, соответственно, снижаются позиции по используемым ключевым словам.
- Также могут «прыгать» позиции по ключам из-за того, что поисковик будет менять страницу для показа в поисковой выдаче.
- Если проблема не ограничивается несколькими урлами, а распространяется на весь сайт, то в таком случае Яндекс и Google могут наказать неприятным фильтром.
Понимая теперь, насколько серьезными могут быть последствия, рассмотрим виды дубликатов.
SEO-шников много, профессионалов — единицы. Научитесь технической и поведенческой оптимизации, создавайте семантические ядра и продвигайте проекты в ТОП!
Получить скидку →

Ежедневные советы от диджитал-наставника Checkroi прямо в твоем телеграме!
Подписывайся на канал
Подписаться
Виды дублей
Выше мы уже выяснили, что дубли бывают идентичными (полными) и частичными. Полным называют такой дубликат, когда одну и ту же веб-страницу поисковик находит по различным адресам.
Когда появляются полные дубли:
- Зачастую это происходит, если забыли указать главное зеркало, и весь сайт может показываться в поиске с www и без него, c http и с https. Чтобы устранить эту проблему, читайте здесь детальнее о том, что такое зеркало сайта.
- Кроме того, бывают ситуации, когда возникают дубли главной страницы ввиду особенностей движка или проведенной веб-разработчиком работы. Тогда, к примеру, главная может быть доступна со слешем «/» в конце и без него, с добавлением слов home, start, index.php и т. п.
- Нередко дубли возникают, когда в индекс попадают страницы с динамичными адресами, появляющиеся обычно при использовании фильтров для сортировки и сравнения товаров.
- Часть движков (WordPress, Joomla, Opencart, ModX) сами по себе генерируют дубли. К примеру, в Joomla по умолчанию часть страниц доступна к отображению с разными урлами: mysite.ru/catalog/17 и mysite.ru/catalog/17-article.html и т. п.
- Если для отслеживания сессий применяют специальные идентификаторы, то они также могут индексироваться и создавать копии.
- Иногда в индекс также попадают страницы по адресам, к которым добавлены utm-метки. Такие метки вставляют, чтобы отслеживать эффективность проводимых рекламных кампаний, и по-хорошему они не должны быть проиндексированы. Однако на практике подобные урлы часто можно видеть в поисковой выдаче.
Когда возникают частичные дубли
Полные дубли легко найти и устранить, а вот с частичными уже придется повозиться. Поэтому на рассмотрении их видов стоит остановиться детальнее.
Пагинация страниц
Используя пагинацию страниц, владельцы сайтов делают навигацию для посетителей более простой, но вместе с тем создают проблему для поискового продвижения. Каждая страница пагинации – это фактически дубль зачастую с теми же мета-данными, СЕО-текстом.
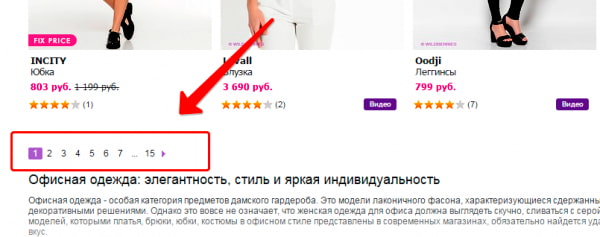
К примеру, основная страница имеет вид https://mysite.ru/women/clothes, а у страницы пагинации адрес будет https://mysite.ru/women/clothes/?page=2. Адреса получаются разные, а содержимое будет почти одинаковым.
Блоки новостей, популярных статей и комментариев
Чтобы удержать пользователя на сайте, ему часто предлагают ознакомиться с наиболее интересными новостями, комментариями и статьями. Название этих объектов с частью содержимого обычно размещают по бокам или снизу от основного материала. Если эти куски будут проиндексированы, то поисковик определит, что на некоторых страницах одинаковый контент, а это очень плохо.
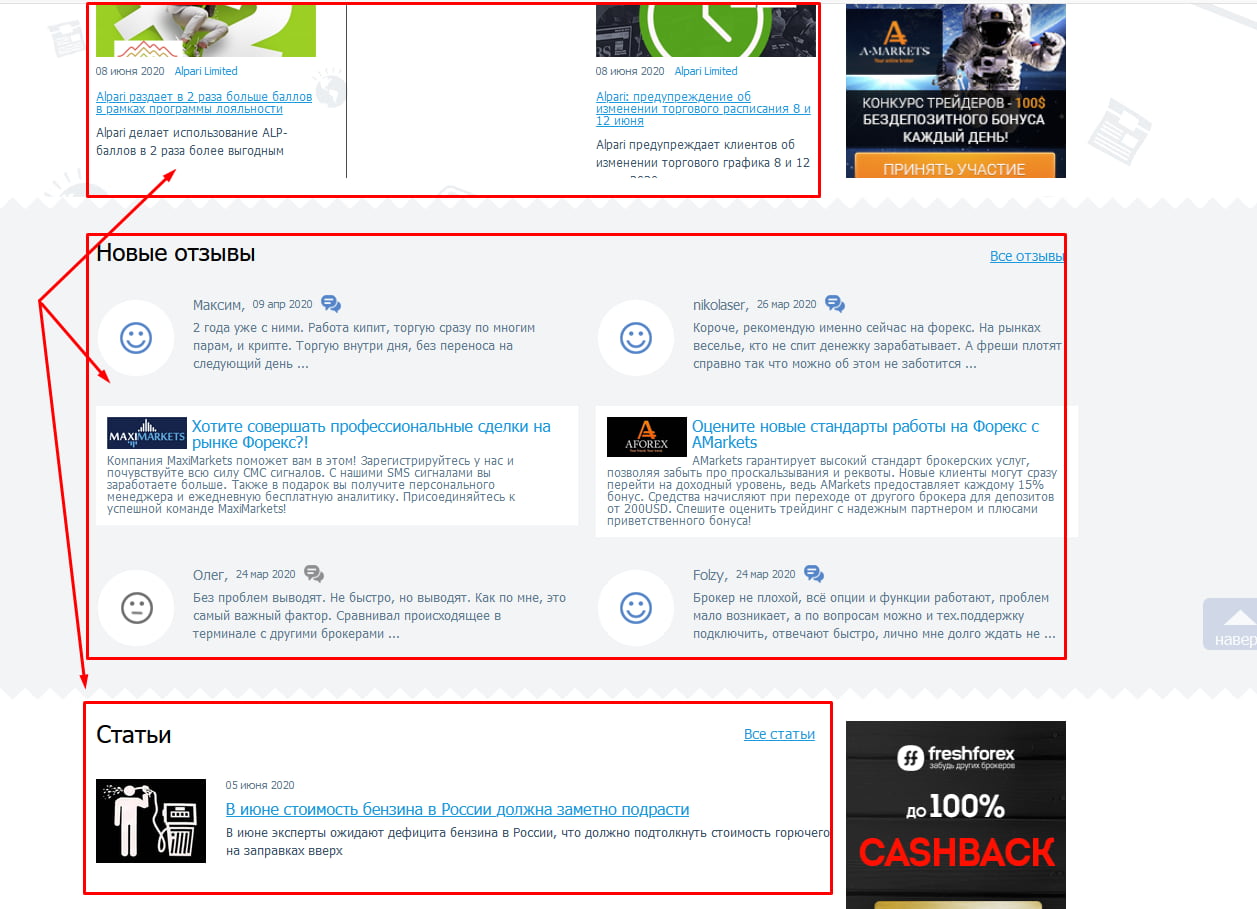
На скриншоте видно, как внизу главной страницы сайта размещаются три блока с последними статьями, новостями и отзывами. То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
Версии страниц для печати
Некоторые веб-страницы сайта доступны в обычном варианте и в версии для печати, которая отличается от основной адресом и отсутствием значительной части строк кода, т. к. для печатаемой страницы не нужна значительная часть функционала.
Обычная страница может открываться, например, по адресу https://my-site.ru/page, а у варианта для печати адрес немного изменится и будет похож на такой: https://my-site.ru/page?print.
Сайты с технологией AJAX
На некоторых сайтах, применяемых технологию AJAX, возникают так называемые html-слепки. Сами по себе они не опасны, если нет ошибок в имплантации способа индексирования AJAX-страниц, когда поисковых ботов направляют не на основную страницу, а на html-слепок, где робот индексирует одну и ту же страницу по двум адресам:
- основному;
- адресу html-слепка.
Для нахождения таких html-слепков стоит в основном адресе заменить часть «!#» на такой код: «?_escaped_fragment_=».
Частичные дубли опасны тем, что они не вызывают значительного снижения позиций в один момент, а понемногу портят картину, усугубляя ситуацию день за днем.
Как происходит поиск дублей страниц на сайте
Существует несколько основных способов, позволяющих понять, как найти дубли страниц оптимизатору на сайте:
Вручную
Уже зная, где стоит искать дубликаты, SEO-специалист без особого труда может найти значительную часть копий, попробовав различные варианты урлов.
С применением команды site
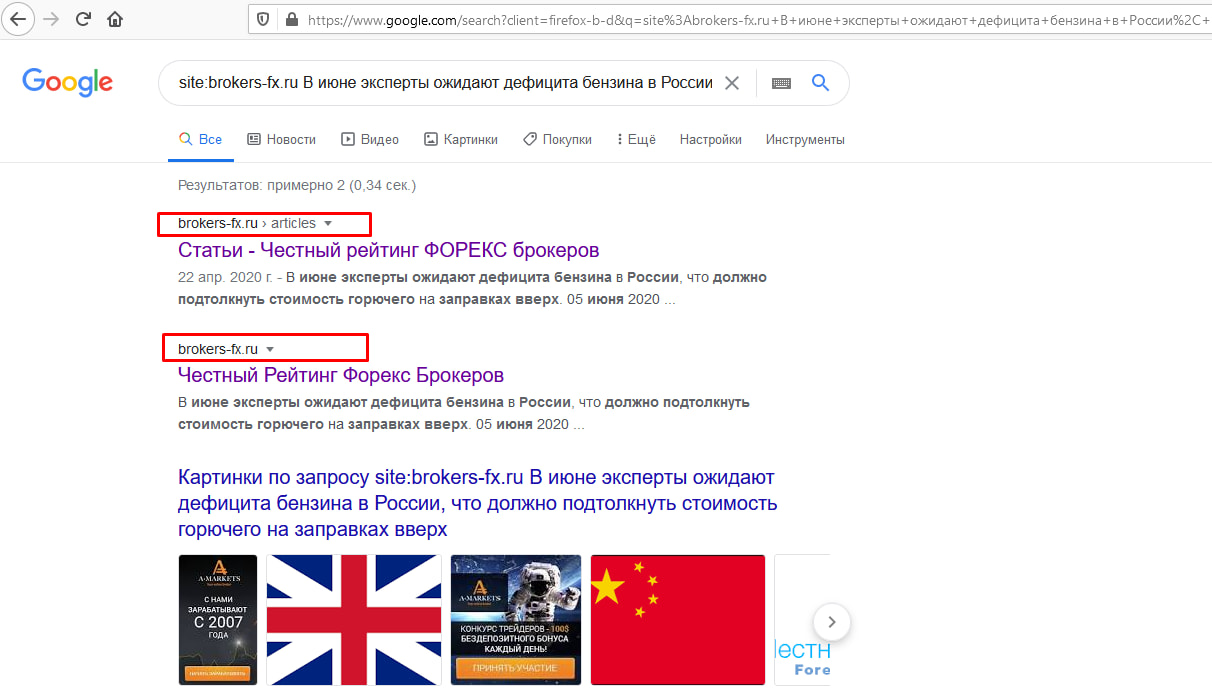
Вставляем в адресную строку команду «site:», вводим после нее домен и часть текстового содержания, после чего Google сам выдаст все найденные варианты. На скриншоте ниже видно, что мы ввели первое предложение свежей статьи после команды «site:», и Google показывает, что у основной страницы с материалом есть частичный дубль на главной.
С использованием программ и онлайн-сервисов
Для поиска дублей часто применяют три популярные программы на ПК:
- Xenu – бесплатная;
- NetPeak – от $15 в месяц, но есть 14-дневный trial;
- Screaming Frog – платная (149 фунтов за год), но есть ограниченная бесплатная версия, которой хватает для большинства нужд.
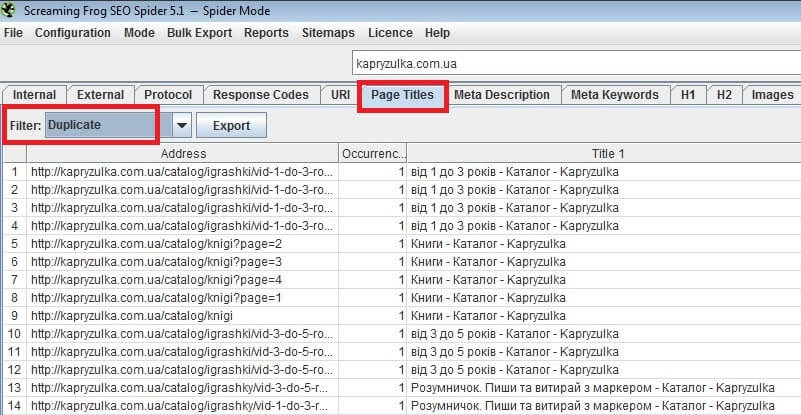
Вот пример того, как ищет дубликаты программа Screaming Frog:
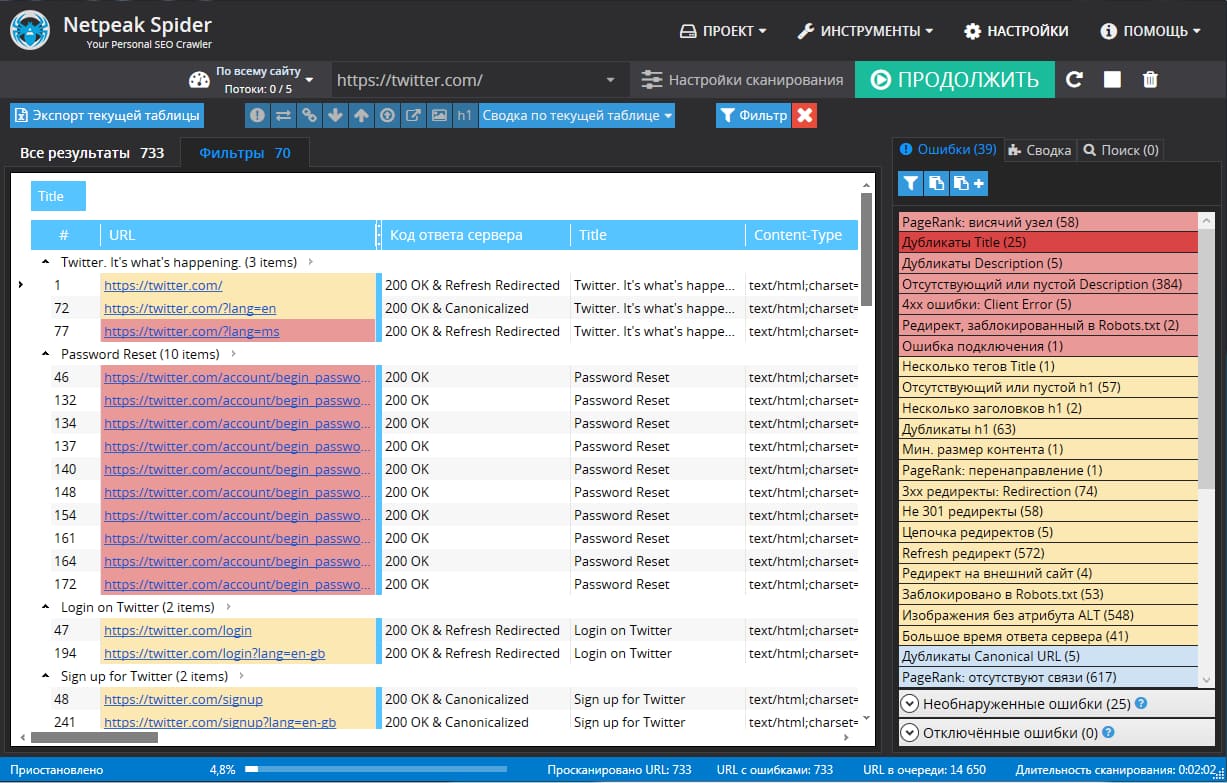
А вот как можно проверить дубли страниц в NetPeak:
Для онлайн-поиска дублей страниц можно использовать специальные веб-сервисы наподобие Serpstat.
Использование Google Search Console и Яндекс Вебмастер
В обновленной версии Google Search Console для поиска дублей смотрим «Предупреждения» и «Покрытие». Там поисковая система сама сообщает о проблемных, на ее взгляд, страницах, которым нужно уделить внимание.
Что касается Yandex, то здесь все намного удобнее. Для поиска дублей заходим в Яндекс Вебмастер, открыв раздел «Индексирование» – «Страницы в поиске». Опускаемся в самый низ, выбираем справа удобный формат файла – XLS или CSV, скачиваем его и открываем. В этом документе все дубликаты в строке «Статус» будут иметь обозначение DUPLICATE.
Как убрать дубли?
Чтобы удалить дубли страниц на сайте, можно использовать разные приемы в зависимости от ситуации. Давайте же с ними познакомимся:
При помощи noindex и nofollow
Самый простой способ – закрыть от индексации, используя метатег <meta name=”robots” content=”noindex,nofollow”/>, который помещают в шапку между открывающим тегом <head> и закрывающим </head>. Попав на страницу с таким метатегом, поисковые алгоритмы не станут ее индексировать и учитывать ссылки, находящиеся здесь.
При добавлении метатега «noindex,nofollow» на страницу, крайне важно, чтобы для нее не была запрещена индексация через файл robots.txt.
При помощи robots.txt
Индексирование отдельных дублей можно запретить в файле robots.txt, используя директиву Disallow. В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
User-agent: *
Disallow: /dublictate.html
Host: mysite.ru
Через robots.txt удобно запрещать индексацию служебных страниц. Выглядит это следующим образом:

Этот вариант зачастую применяют, если невозможно использовать предыдущий.
При помощи canonical
Еще один удобный способ – применить метатег canonical, который говорит поисковым роботам, что они попали на страницу-дубликат, а заодно указывает, где находится основная страница. Этот метатег помещают в шапку между открывающим тегом <head> и закрывающим </head>, и выглядит он так:
<link rel=”canonical” href=”адрес основной страницы” />
Как убрать дубликаты на страницах с пагинацией
В случае присутствия на сайте многостраничного каталога, на второй и последующих страницах могут возникать частичные дубли. Смотрим, как это может быть:
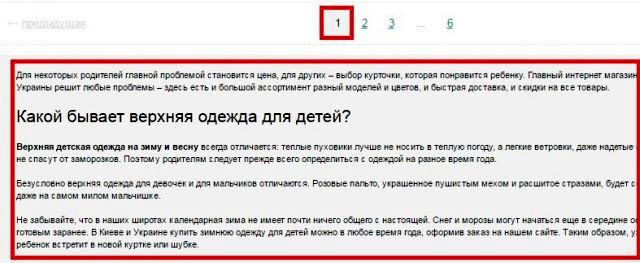
Выше на скрине 1-я страница каталога, а вот вторая:
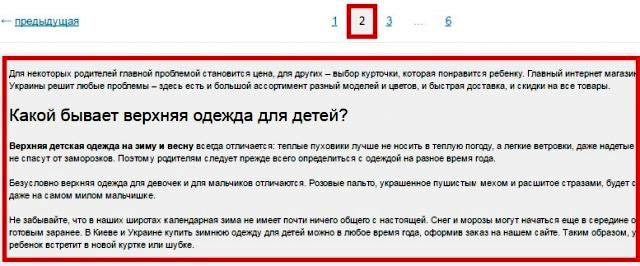 То есть на каждой странице дублируется текст и теги: Title и Description.
То есть на каждой странице дублируется текст и теги: Title и Description.
В таких случаях SEO-специалисту нужно добиться, чтобы:
- текст отображался только на 1-й странице;
- Title и Description были уникальными для каждой страницы, хотя их можно сделать шаблонными с минимальными отличиями;
- в адресах страниц пагинации должны отсутствовать динамические параметры.
Понимая теперь, что такое дубликаты страниц сайта, и как бороться с дублями, вы сможете не допустить попадания в индекс копий, которые будут препятствовать продвижению в поисковых системах. Если после прочтения статьи у вас остались вопросы, или вы хотите дополнить материал своими ценными замечаниями, то обязательно сделайте это в комментариях ниже.