
Иногда перед программистом стоит не самая простая задача: найти все ссылки на странице с помощью PHP. Где это может быть нужно? Да, много где, например, при выводе одного сайта на другом. Для этого требуется вытащить из него все ссылки и заменить на другие. Также поиск ссылок используется при создании ЧПУ-ссылок, ведь нужно вытащить все старые ссылки и поставить заместо них новые. В общем, задач можно придумать много, но ключевой вопрос всего один: «Как найти все ссылки на странице через PHP?«. Об этом я и написал данную статью.
Кто имеет хотя бы маленький опыт, тут же скажет, что надо написать регулярное выражение и будет абсолютно прав. Действительно, простыми строковыми функциями данную задачу будет крайне трудно решить. Ведь каждый пишет по-разному, кто-то прописными бувами, кто-то строчными, кто-то ставит пробел после, например, знака «=«, а кто-то нет. У кого-то двойные кавычки, а у кого-то одинарные. В общем, разновидностей очень много. И единственная возможность предусмотреть максимум всего — это регулярное выражение.
<?php
/* $html - некий html-код некой страницы, n - это переход на новую строку (верстальщики иногда это делают) */
$html = "Текст <a href='page1.html'>ссылка</a> и снова <a hREF n ="page2.html" title=''>ссылка</a> конец";
/* Вызываем функцию, которая все совпадения помещает в массив $matches */
preg_match_all("/<[Aa][s]{1}[^>]*[Hh][Rr][Ee][Ff][^=]*=[ '"s]*([^ "'>s#]+)[^>]*>/", $html, $matches);
$urls = $matches[1]; // Берём то место, где сама ссылка (благодаря группирующим скобкам в регулярном выражении)
/* Выводим все ссылки */
for ($i = 0; $i < count($urls); $i++)
echo $urls[$i]."<br />";
?>
Самая сложная часть — это регулярное выражение, ради его публикации данная статья и создавалась, чтобы новичкам не пришлось писать нечто подобное. Хотя это и является очень полезным, но сразу новичок такое никогда не напишет, а для решения задачи это требуется. Конечно, данное регулярное выражение по поиску ссылок неидеальное (едва ли можно написать идеальное), но, думаю, что 99% ссылок будут найдены. А если код писал адекватный верстальщик, то все 100%. А как работать с найденными ссылками дальше, это уже отдельная история.
-

Создано 26.09.2012 10:08:17
-
Михаил Русаков

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
Она выглядит вот так:
-
Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):

I have this text:
$string = "this is my friend's website http://example.com I think it is coll";
How can I extract the link into another variable?
I know it should be by using regular expression especially preg_match() but I don’t know how?
![]()
Amal Murali
75.2k18 gold badges127 silver badges150 bronze badges
asked May 26, 2009 at 14:13
![]()
2
Probably the safest way is using code snippets from WordPress. Download the latest one (currently 3.1.1) and see wp-includes/formatting.php. There’s a function named make_clickable which has plain text for param and returns formatted string. You can grab codes for extracting URLs. It’s pretty complex though.
This one line regex might be helpful.
preg_match_all('#bhttps?://[^s()<>]+(?:([wd]+)|([^[:punct:]s]|/))#', $string, $match);
But this regex still can’t remove some malformed URLs (ex. http://google:ha.ckers.org ).
See also:
How to mimic StackOverflow Auto-Link Behavior
![]()
answered Apr 17, 2011 at 0:27
![]()
NobuNobu
9,8774 gold badges39 silver badges47 bronze badges
6
I tried to do as Nobu said, using WordPress, but to much dependencies to other WordPress functions I instead opted to use Nobu’s regular expression for preg_match_all() and turned it into a function, using preg_replace_callback(); a function which now replaces all links in a text with clickable links. It uses anonymous functions so you’ll need PHP 5.3 or you may rewrite the code to use an ordinary function instead.
<?php
/**
* Make clickable links from URLs in text.
*/
function make_clickable($text) {
$regex = '#bhttps?://[^s()<>]+(?:([wd]+)|([^[:punct:]s]|/))#';
return preg_replace_callback($regex, function ($matches) {
return "<a href='{$matches[0]}'>{$matches[0]}</a>";
}, $text);
}
![]()
Amal Murali
75.2k18 gold badges127 silver badges150 bronze badges
answered Mar 23, 2012 at 11:24
![]()
Mikael RoosMikael Roos
2853 silver badges15 bronze badges
1
URLs have a quite complex definition — you must decide what you want to capture first. A simple example capturing anything starting with http:// and https:// could be:
preg_match_all('!https?://S+!', $string, $matches);
$all_urls = $matches[0];
Note that this is very basic and could capture invalid URLs. I would recommend catching up on POSIX and PHP regular expressions for more complex things.
![]()
Amal Murali
75.2k18 gold badges127 silver badges150 bronze badges
answered May 26, 2009 at 14:21
![]()
soulmergesoulmerge
73.3k19 gold badges118 silver badges154 bronze badges
0
The code that worked for me (especially if you have several links in your $string):
$string = "this is my friend's website https://www.example.com I think it is cool, but this one is cooler https://www.stackoverflow.com :)";
$regex = '/b(https?|ftp|file)://[-A-Z0-9+&@#/%?=~_|$!:,.;]*[A-Z0-9+&@#/%=~_|$]/i';
preg_match_all($regex, $string, $matches);
$urls = $matches[0];
// go over all links
foreach($urls as $url)
{
echo $url.'<br />';
}
Hope that helps others as well.
answered Apr 12, 2014 at 6:42
![]()
AvatarAvatar
14.3k9 gold badges118 silver badges194 bronze badges
1
If the text you extract the URLs from is user-submitted and you’re going to display the result as links anywhere, you have to be very, VERY careful to avoid XSS vulnerabilities, most prominently «javascript:» protocol URLs, but also malformed URLs that might trick your regexp and/or the displaying browser into executing them as Javascript URLs. At the very least, you should accept only URLs that start with «http», «https» or «ftp».
There’s also a blog entry by Jeff where he describes some other problems with extracting URLs.
![]()
Cœur
36.8k25 gold badges192 silver badges262 bronze badges
answered May 26, 2009 at 14:30
![]()
Michael BorgwardtMichael Borgwardt
341k78 gold badges481 silver badges718 bronze badges
preg_match_all('/[a-z]+://S+/', $string, $matches);
This is an easy way that’d work for a lot of cases, not all. All the matches are put in $matches. Note that this do not cover links in anchor elements (<a href=»»…), but that wasn’t in your example either.
answered May 26, 2009 at 14:19
![]()
runfalkrunfalk
1,9961 gold badge17 silver badges20 bronze badges
3
You could do like this..
<?php
$string = "this is my friend's website http://example.com I think it is coll";
echo explode(' ',strstr($string,'http://'))[0]; //"prints" http://example.com
answered Dec 24, 2013 at 6:02
![]()
preg_match_all ("/a[s]+[^>]*?href[s]?=[s"']+".
"(.*?)["']+.*?>"."([^<]+|.*?)?</a>/",
$var, &$matches);
$matches = $matches[1];
$list = array();
foreach($matches as $var)
{
print($var."<br>");
}
answered Sep 1, 2011 at 12:54
You could try this to find the link and revise the link (add the href link).
$reg_exUrl = "/(http|https|ftp|ftps)://[a-zA-Z0-9-.]+.[a-zA-Z]{2,3}(/S*)?/";
// The Text you want to filter for urls
$text = "The text you want to filter goes here. http://example.com";
if(preg_match($reg_exUrl, $text, $url)) {
echo preg_replace($reg_exUrl, "<a href="{$url[0]}">{$url[0]}</a> ", $text);
} else {
echo "No url in the text";
}
refer here: http://php.net/manual/en/function.preg-match.php
![]()
ᴄʀᴏᴢᴇᴛ
2,92125 silver badges44 bronze badges
answered Mar 11, 2015 at 8:44
![]()
There are a lot of edge cases with urls. Like url could contain brackets or not contain protocol etc. Thats why regex is not enough.
I created a PHP library that could deal with lots of edge cases: Url highlight.
Example:
<?php
use VStelmakhUrlHighlightUrlHighlight;
$urlHighlight = new UrlHighlight();
$urlHighlight->getUrls("this is my friend's website http://example.com I think it is coll");
// return: ['http://example.com']
For more details see readme. For covered url cases see test.
answered Jan 25, 2020 at 18:49
![]()
vstelmakhvstelmakh
7321 gold badge11 silver badges19 bronze badges
0
Here is a function I use, can’t remember where it came from but seems to do a pretty good job of finding links in the text. and making them links.
You can change the function to suit your needs. I just wanted to share this as I was looking around and remembered I had this in one of my helper libraries.
function make_links($str){
$pattern = '(?xi)b((?:https?://|wwwd{0,3}[.]|[a-z0-9.-]+[.][a-z]{2,4}/)(?:[^s()<>]+|(([^s()<>]+|(([^s()<>]+)))*))+(?:(([^s()<>]+|(([^s()<>]+)))*)|[^s`!()[]{};:'".,<>?«»“”‘’]))';
return preg_replace_callback("#$pattern#i", function($matches) {
$input = $matches[0];
$url = preg_match('!^https?://!i', $input) ? $input : "http://$input";
return '<a href="' . $url . '" rel="nofollow" target="_blank">' . "$input</a>";
}, $str);
}
Use:
$subject = 'this is a link http://google:ha.ckers.org maybe don't want to visit it?';
echo make_links($subject);
Output
this is a link <a href="http://google:ha.ckers.org" rel="nofollow" target="_blank">http://google:ha.ckers.org</a> maybe don't want to visit it?
answered Mar 7, 2020 at 4:35
![]()
Kyle CootsKyle Coots
2,0311 gold badge18 silver badges24 bronze badges
<?php
preg_match_all('/(href|src)[s]?=[s"']?+(.*?)[s"']+.*?/', $webpage_content, $link_extracted);
preview
answered Apr 22, 2020 at 18:21
![]()
TeslaTesla
1691 silver badge6 bronze badges
This Regex works great for me and i have checked with all types of URL,
<?php
$string = "Thisregexfindurlhttp://www.rubular.com/r/bFHobduQ3n mixedwithstring";
preg_match_all('/(https?|ssh|ftp)://[^s"]+/', $string, $url);
$all_url = $url[0]; // Returns Array Of all Found URL's
$one_url = $url[0][0]; // Gives the First URL in Array of URL's
?>
Checked with lots of URL’s can find here http://www.rubular.com/r/bFHobduQ3n
answered Sep 19, 2016 at 13:05
![]()
public function find_links($post_content){
$reg_exUrl = "/(http|https|ftp|ftps)://[a-zA-Z0-9-.]+.[a-zA-Z]{2,3}(/S*)?/";
// Check if there is a url in the text
if(preg_match_all($reg_exUrl, $post_content, $urls)) {
// make the urls hyper links,
foreach($urls[0] as $url){
$post_content = str_replace($url, '<a href="'.$url.'" rel="nofollow"> LINK </a>', $post_content);
}
//var_dump($post_content);die(); //uncomment to see result
//return text with hyper links
return $post_content;
} else {
// if no urls in the text just return the text
return $post_content;
}
}
answered Aug 23, 2017 at 8:08
![]()
karolkarpkarolkarp
2612 silver badges7 bronze badges

От автора: не люблю каждый раз натыкаться на одни и те же грабли! Вот сегодня опять та тема, в которой никак не обойтись без регулярных выражений. Это и есть мои любимые «грабли». Но все равно я не сдамся, и чтобы с помощью PHP находить ссылки, я обойдусь без них!
Никуда без них не деться!
Нет уж, господа консерваторы! Я постараюсь уж как-нибудь реализовать парсинг документов без этого застарелого средства. Ну не хватает у меня терпения на составление шаблонов с помощью регулярных выражений. А когда терпение лопается, то рождаются другие более «ругательные» выражения :). Так что «грабли» в сторону – мы идем по собственному галсу!
Чтобы не опростоволоситься, нам потребуется сторонняя библиотека — Simple HTML DOM. Скачать ее можно по этой ссылке. Не беспокойтесь, версия хоть и старая, но работает. А главное, что это средство посвежее будет, чем выражения регулярные :).
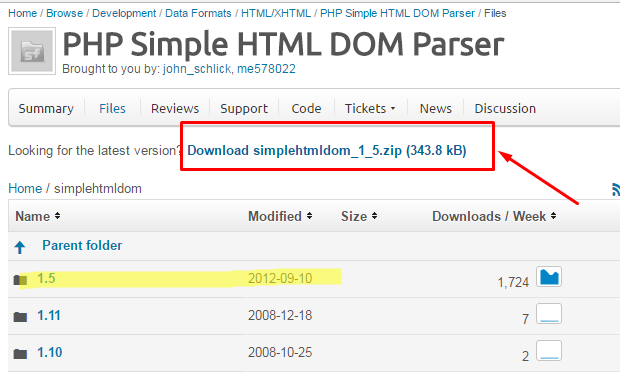
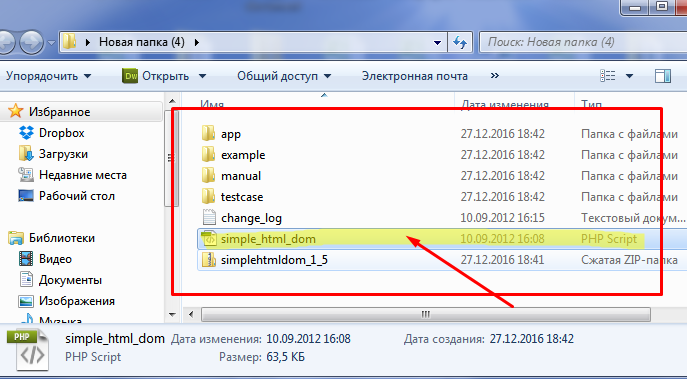
После распаковки помещаем файл simple_html_dom.php в папку со скриптом, чтоб легче было подключать. Все остальные файлы в принципе нас не интересуют, но пригодятся вам в будущем. Там есть и мануал, и примеры использования библиотеки.

Профессия PHP-разработчик с нуля до PRO
Готовим PHP-разработчиков с нуля
Вы с нуля научитесь программировать сайты и веб-приложения на PHP, освоите фреймворк
Laravel, напишете облачное хранилище и поработаете над интернет-магазином в команде.
Сможете устроиться на позицию Junior-разработчика.
Узнать подробнее
Командная стажировка под руководством тимлида
90 000 рублей средняя зарплата PHP-разработчика
3 проекта в портфолио для старта карьеры
Реализуем!
Напомню, что сегодня мы научимся, как найти ссылки PHP без «ужасных» регулярных выражений. Теперь нам осталось подключить скрипт библиотеки у себя в коде и просканировать указанную веб-страницу на наличие гиперссылок.
|
<?php include ‘simple_html_dom.php’; $razmetka = file_get_html(‘//test2.ru/’); foreach($razmetka—>find(‘a’) as $teg) echo $teg—>href . «<br>»; ?> |

Для доказательства действенности этого метода приведу код разметки «отпарсеной» страницы.

Сразу оговорюсь, что я не сканировал ничей сайт. Для демонстрации примера я использовал Денвер, а в нем стоит программная заглушка, которая не позволяет парсить удаленные хосты.
Еще пример!
Вот еще один вариант реализации, в котором нам также удастся обойтись без «граблей».
|
<?php $razmetka_html = file_get_contents(‘sample.html’); $dom = new DOMDocument; $dom—>loadHTML($razmetka_html); $tegi = $dom—>getElementsByTagName(«a»); foreach ($tegi as $teg) { echo $teg—>nodeValue.» «; echo $teg—>getAttribute(‘href’).«<br>»; echo «<br>»; } ?> |
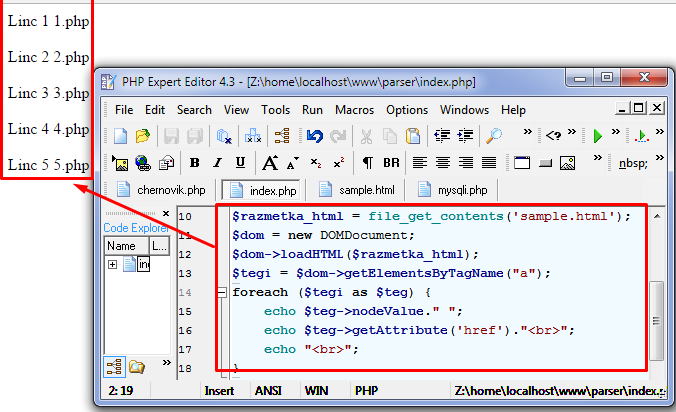
Разметка страницы, в которой с помощью PHP находили ссылки в тексте.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<html> <head> <title>Sample</title> </head> <body> <div class=«menu»> <h2>Menu</h2> <ul> <li><a href=«1.php»>Linc 1</a></li> <li><a href=«2.php»>Linc 2</a></li> <li><a href=«3.php»>Linc 3</a></li> <li><a href=«4.php»>Linc 4</a></li> <li><a href=«5.php»>Linc 5</a></li> </ul> </div> <div class=«cont»> <p>PHP is a server scripting language</p> </div> </body> </html> |

Профессия PHP-разработчик с нуля до PRO
Готовим PHP-разработчиков с нуля
Вы с нуля научитесь программировать сайты и веб-приложения на PHP, освоите фреймворк
Laravel, напишете облачное хранилище и поработаете над интернет-магазином в команде.
Сможете устроиться на позицию Junior-разработчика.
Узнать подробнее
Командная стажировка под руководством тимлида
90 000 рублей средняя зарплата PHP-разработчика
3 проекта в портфолио для старта карьеры
Мне очередной раз удалось избавиться от своих «граблей» :). А вам?
Reading Time: 5 minutes
17,950 Views
Inside this article we will see the concept of find and extract all links from a HTML string in php. Concept of this article will provide very classified information to understand the things.
This PHP tutorial is based on how to extract all links and their anchor text from a HTML string. In this guide, we will see how to fetch the HTML content of a web page by URL and then extract the links from it. To do this, we will be use PHP’s DOMDocument class.
DOMDocument of PHP also termed as PHP DOM Parser. We will see step by step concept to find and extract all links from a html using DOM parser.
Learn More –
- How To Generate Fake Data in PHP Using Faker Library
- How to Generate Fake Image URLs in PHP Using Faker
- How to Generate Random Name of Person in PHP
- How to Get HTML Tag Value in PHP | DOMDocument Object
Let’s get started.
Example 1: Get All Links From HTML String Value
Inside this example we will consider a HTML string value. From that html value we will extract all links.
Create file index.php inside your application.
Open index.php and write this complete code into it.
<?php
// HTML String
$htmlString = "<html>
<head></head>
<body>
<a href='https://www.google.com/' title='Google URL'>Google</a>
<a href='https://www.youtube.com/' title='Youtube URL'>Youtube</a>
<a href='https://onlinewebtutorblog.com/' title='Website URL'>Online Web Tutor</a>
</body>
</html>";
//Create a new DOMDocument object.
$htmlDom = new DOMDocument;
//Load the HTML string into our DOMDocument object.
@$htmlDom->loadHTML($htmlString);
//Extract all anchor elements / tags from the HTML.
$anchorTags = $htmlDom->getElementsByTagName('a');
//Create an array to add extracted images to.
$extractedAnchors = array();
//Loop through the anchors tags that DOMDocument found.
foreach($anchorTags as $anchorTag){
//Get the href attribute of the anchor.
$aHref = $anchorTag->getAttribute('href');
//Get the title text of the anchor, if it exists.
$aTitle = $anchorTag->getAttribute('title');
//Add the anchor details to $extractedAnchors array.
$extractedAnchors[] = array(
'href' => $aHref,
'title' => $aTitle
);
}
echo "<pre>";
//print_r our array of anchors.
print_r($extractedAnchors);
Concept

Output
When we run index.php. Here is the output


Example 2: Get All Links From a Web Page
Inside this example we will use web page URL to get all links.
Create file index.php inside your application.
Open index.php and write this complete code into it.
<?php
$htmlString = file_get_contents('https://onlinewebtutorblog.com/');
//Create a new DOMDocument object.
$htmlDom = new DOMDocument;
//Load the HTML string into our DOMDocument object.
@$htmlDom->loadHTML($htmlString);
//Extract all anchor elements / tags from the HTML.
$anchorTags = $htmlDom->getElementsByTagName('a');
//Create an array to add extracted images to.
$extractedAnchors = array();
//Loop through the anchors tags that DOMDocument found.
foreach($anchorTags as $anchorTag){
//Get the href attribute of the anchor.
$aHref = $anchorTag->getAttribute('href');
//Get the title text of the anchor, if it exists.
$aTitle = $anchorTag->getAttribute('title');
//Add the anchor details to $extractedAnchors array.
$extractedAnchors[] = array(
'href' => $aHref,
'title' => $aTitle
);
}
echo "<pre>";
//print_r our array of anchors.
print_r($extractedAnchors);
Output
When we run index.php. Here is the output

We hope this article helped you to Find and Extract All links From a HTML String in PHP Tutorial in a very detailed way.
Buy Me a Coffee
Online Web Tutor invites you to try Skillshike! Learn CakePHP, Laravel, CodeIgniter, Node Js, MySQL, Authentication, RESTful Web Services, etc into a depth level. Master the Coding Skills to Become an Expert in PHP Web Development. So, Search your favourite course and enroll now.
If you liked this article, then please subscribe to our YouTube Channel for PHP & it’s framework, WordPress, Node Js video tutorials. You can also find us on Twitter and Facebook.
I have this text:
$string = "this is my friend's website http://example.com I think it is coll";
How can I extract the link into another variable?
I know it should be by using regular expression especially preg_match() but I don’t know how?
![]()
Amal Murali
75.2k18 gold badges127 silver badges150 bronze badges
asked May 26, 2009 at 14:13
![]()
2
Probably the safest way is using code snippets from WordPress. Download the latest one (currently 3.1.1) and see wp-includes/formatting.php. There’s a function named make_clickable which has plain text for param and returns formatted string. You can grab codes for extracting URLs. It’s pretty complex though.
This one line regex might be helpful.
preg_match_all('#bhttps?://[^s()<>]+(?:([wd]+)|([^[:punct:]s]|/))#', $string, $match);
But this regex still can’t remove some malformed URLs (ex. http://google:ha.ckers.org ).
See also:
How to mimic StackOverflow Auto-Link Behavior
![]()
answered Apr 17, 2011 at 0:27
![]()
NobuNobu
9,8774 gold badges39 silver badges47 bronze badges
6
I tried to do as Nobu said, using WordPress, but to much dependencies to other WordPress functions I instead opted to use Nobu’s regular expression for preg_match_all() and turned it into a function, using preg_replace_callback(); a function which now replaces all links in a text with clickable links. It uses anonymous functions so you’ll need PHP 5.3 or you may rewrite the code to use an ordinary function instead.
<?php
/**
* Make clickable links from URLs in text.
*/
function make_clickable($text) {
$regex = '#bhttps?://[^s()<>]+(?:([wd]+)|([^[:punct:]s]|/))#';
return preg_replace_callback($regex, function ($matches) {
return "<a href='{$matches[0]}'>{$matches[0]}</a>";
}, $text);
}
![]()
Amal Murali
75.2k18 gold badges127 silver badges150 bronze badges
answered Mar 23, 2012 at 11:24
![]()
Mikael RoosMikael Roos
2853 silver badges15 bronze badges
1
URLs have a quite complex definition — you must decide what you want to capture first. A simple example capturing anything starting with http:// and https:// could be:
preg_match_all('!https?://S+!', $string, $matches);
$all_urls = $matches[0];
Note that this is very basic and could capture invalid URLs. I would recommend catching up on POSIX and PHP regular expressions for more complex things.
![]()
Amal Murali
75.2k18 gold badges127 silver badges150 bronze badges
answered May 26, 2009 at 14:21
![]()
soulmergesoulmerge
73.3k19 gold badges118 silver badges154 bronze badges
0
The code that worked for me (especially if you have several links in your $string):
$string = "this is my friend's website https://www.example.com I think it is cool, but this one is cooler https://www.stackoverflow.com :)";
$regex = '/b(https?|ftp|file)://[-A-Z0-9+&@#/%?=~_|$!:,.;]*[A-Z0-9+&@#/%=~_|$]/i';
preg_match_all($regex, $string, $matches);
$urls = $matches[0];
// go over all links
foreach($urls as $url)
{
echo $url.'<br />';
}
Hope that helps others as well.
answered Apr 12, 2014 at 6:42
![]()
AvatarAvatar
14.3k9 gold badges118 silver badges194 bronze badges
1
If the text you extract the URLs from is user-submitted and you’re going to display the result as links anywhere, you have to be very, VERY careful to avoid XSS vulnerabilities, most prominently «javascript:» protocol URLs, but also malformed URLs that might trick your regexp and/or the displaying browser into executing them as Javascript URLs. At the very least, you should accept only URLs that start with «http», «https» or «ftp».
There’s also a blog entry by Jeff where he describes some other problems with extracting URLs.
![]()
Cœur
36.8k25 gold badges192 silver badges262 bronze badges
answered May 26, 2009 at 14:30
![]()
Michael BorgwardtMichael Borgwardt
341k78 gold badges481 silver badges718 bronze badges
preg_match_all('/[a-z]+://S+/', $string, $matches);
This is an easy way that’d work for a lot of cases, not all. All the matches are put in $matches. Note that this do not cover links in anchor elements (<a href=»»…), but that wasn’t in your example either.
answered May 26, 2009 at 14:19
![]()
runfalkrunfalk
1,9961 gold badge17 silver badges20 bronze badges
3
You could do like this..
<?php
$string = "this is my friend's website http://example.com I think it is coll";
echo explode(' ',strstr($string,'http://'))[0]; //"prints" http://example.com
answered Dec 24, 2013 at 6:02
![]()
preg_match_all ("/a[s]+[^>]*?href[s]?=[s"']+".
"(.*?)["']+.*?>"."([^<]+|.*?)?</a>/",
$var, &$matches);
$matches = $matches[1];
$list = array();
foreach($matches as $var)
{
print($var."<br>");
}
answered Sep 1, 2011 at 12:54
You could try this to find the link and revise the link (add the href link).
$reg_exUrl = "/(http|https|ftp|ftps)://[a-zA-Z0-9-.]+.[a-zA-Z]{2,3}(/S*)?/";
// The Text you want to filter for urls
$text = "The text you want to filter goes here. http://example.com";
if(preg_match($reg_exUrl, $text, $url)) {
echo preg_replace($reg_exUrl, "<a href="{$url[0]}">{$url[0]}</a> ", $text);
} else {
echo "No url in the text";
}
refer here: http://php.net/manual/en/function.preg-match.php
![]()
ᴄʀᴏᴢᴇᴛ
2,92125 silver badges44 bronze badges
answered Mar 11, 2015 at 8:44
![]()
There are a lot of edge cases with urls. Like url could contain brackets or not contain protocol etc. Thats why regex is not enough.
I created a PHP library that could deal with lots of edge cases: Url highlight.
Example:
<?php
use VStelmakhUrlHighlightUrlHighlight;
$urlHighlight = new UrlHighlight();
$urlHighlight->getUrls("this is my friend's website http://example.com I think it is coll");
// return: ['http://example.com']
For more details see readme. For covered url cases see test.
answered Jan 25, 2020 at 18:49
![]()
vstelmakhvstelmakh
7321 gold badge11 silver badges19 bronze badges
0
Here is a function I use, can’t remember where it came from but seems to do a pretty good job of finding links in the text. and making them links.
You can change the function to suit your needs. I just wanted to share this as I was looking around and remembered I had this in one of my helper libraries.
function make_links($str){
$pattern = '(?xi)b((?:https?://|wwwd{0,3}[.]|[a-z0-9.-]+[.][a-z]{2,4}/)(?:[^s()<>]+|(([^s()<>]+|(([^s()<>]+)))*))+(?:(([^s()<>]+|(([^s()<>]+)))*)|[^s`!()[]{};:'".,<>?«»“”‘’]))';
return preg_replace_callback("#$pattern#i", function($matches) {
$input = $matches[0];
$url = preg_match('!^https?://!i', $input) ? $input : "http://$input";
return '<a href="' . $url . '" rel="nofollow" target="_blank">' . "$input</a>";
}, $str);
}
Use:
$subject = 'this is a link http://google:ha.ckers.org maybe don't want to visit it?';
echo make_links($subject);
Output
this is a link <a href="http://google:ha.ckers.org" rel="nofollow" target="_blank">http://google:ha.ckers.org</a> maybe don't want to visit it?
answered Mar 7, 2020 at 4:35
![]()
Kyle CootsKyle Coots
2,0311 gold badge18 silver badges24 bronze badges
<?php
preg_match_all('/(href|src)[s]?=[s"']?+(.*?)[s"']+.*?/', $webpage_content, $link_extracted);
preview
answered Apr 22, 2020 at 18:21
![]()
TeslaTesla
1691 silver badge6 bronze badges
This Regex works great for me and i have checked with all types of URL,
<?php
$string = "Thisregexfindurlhttp://www.rubular.com/r/bFHobduQ3n mixedwithstring";
preg_match_all('/(https?|ssh|ftp)://[^s"]+/', $string, $url);
$all_url = $url[0]; // Returns Array Of all Found URL's
$one_url = $url[0][0]; // Gives the First URL in Array of URL's
?>
Checked with lots of URL’s can find here http://www.rubular.com/r/bFHobduQ3n
answered Sep 19, 2016 at 13:05
![]()
public function find_links($post_content){
$reg_exUrl = "/(http|https|ftp|ftps)://[a-zA-Z0-9-.]+.[a-zA-Z]{2,3}(/S*)?/";
// Check if there is a url in the text
if(preg_match_all($reg_exUrl, $post_content, $urls)) {
// make the urls hyper links,
foreach($urls[0] as $url){
$post_content = str_replace($url, '<a href="'.$url.'" rel="nofollow"> LINK </a>', $post_content);
}
//var_dump($post_content);die(); //uncomment to see result
//return text with hyper links
return $post_content;
} else {
// if no urls in the text just return the text
return $post_content;
}
}
answered Aug 23, 2017 at 8:08
![]()
karolkarpkarolkarp
2612 silver badges7 bronze badges