Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
У 9 из 10 наших читателей есть свой сайт или интернет-магазин на 1C-UMI. Кто-то создал его недавно, а кому-то уже можно праздновать юбилей. За годы развития веб-ресурсы претерпевают множество изменений во внешнем виде и функционале. Иногда хочется вспомнить, каким же был ваш проект раньше, когда всё только начиналось. Или поднять какую-то утерянную информацию, которая была на сайте ранее. Сделать это легко при помощи чудо-сервиса Wayback Machine.
Как пользоваться веб-архивом
Откройте сервис, вбейте в строку поиска домен или полный адрес своего сайта. Сервис автоматически начнет поиск и через пару секунд покажет вам результаты в виде временной шкалы и календаря с датами, когда были сделаны снимки ресурса.

Чтобы перейти к конкретному году, кликните по соответствующему блоку на шкале. Затем в календаре ниже нажмите на одну из дат, выделенных голубым цветом. Если в тот день было сделано несколько снимков, при нажатии на дату вы увидите окно для выбора нужного вам времени. Если снимок был один, вы сразу попадете на сохраненную версию.
Вот так выглядел наш сайт 1C-UMI летом 2012 года:

А вот так его видели наши пользователи осенью 2016 года:

Чем дольше ресурс работает, тем больше его снимков будет в WebArhive. Для путешествия в прошлое используйте временную шкалу и блок переключения месяцев и чисел справа от нее.
Самое классное — что данный сервис не делает скриншоты сайтов, а сохраняет их целиком. Таким образом, вы увидите версию 10-летней давности и, все разделы, формы, почитаете тексты, полистаете изображения и многое другое.
Какие сайты попадают в веб-архив
Оказаться в Wayback Machine может любой сайт. Особенно это касается тех веб-ресурсов, которые находятся в каталоге DMOZ. Но так как сейчас туда свое «детище» уже не добавить, будет достаточно того, что на вашу площадку ссылаются сайты, снимки которых уже присутствуют в веб-архиве. А даже если таких ссылок нет, ваш ресурс все равно может попасть в базу сервиса. Главное, чтобы в его файле Robots.txt не было запрета.
Как проверить? Для сайтов на 1С-UMI откройте раздел «Реклама/SEO → Управление robots.txt» в панели управления сайтом и проверьте, нет ли в нем следующей записи:
User-agent: ia_archiver
Disallow: /
Если такой записи (как выше) нет, все хорошо, ваш сайт имеет шанс на попадание в веб-архив. В противном случае, при поиске своего ресурса в сервисе вы увидите надпись, как на скриншоте ниже.

Если вы не хотите ждать, когда сервис соблаговолит сделать снимок вашего сайта, добавьте его в базу WebArchive вручную. Для этого найдите функцию «Save Page Now», которая находится в центральной части страницы справа.

Укажите ссылку на свой ресурс и нажмите на кнопку «SAVE PAGE». Сохранение начнется через несколько секунд и, спустя минуту или около того, будет закончено. За ходом выполнения вы можете наблюдать в небольшом окошке по центру экрана.

После сохранения снимка страницы начнет загружаться только что архивированная версия сайта.

По окончании процесса окно загрузки закроется, и вы сможете просмотреть сохраненный снимок, побродить по всем разделам сайта и т. д.
Чем будет полезен веб-архив для вас
Данный сервис годится не только для того, чтобы смотреть, в каком состоянии была ваша страничка или любой другой ресурс некоторое время назад. С его помощью вы можете восстановить свой сайт, его страницу, какой-то текст или элемент, если вдруг по какой-то причине данные были стерты. Чтобы этого не произошло, не забывайте почаще выполнять резервное копирование вашего сайта, ну, а на экстренный случай имейте в виду WebArchive. Но имейте в виду также, что WebArchive делает снимки по своему усмотрению с непредсказуемой частотой, поэтому нужной вам версии сайта в нем может и не оказаться.
Вручную восстанавливать ресурс из веб-архива очень долго и для этого нужно неплохо разбираться в сайтостроении и верстке. Однако при желании восстановление можно автоматизировать при помощи онлайн-инструмента ARCHIVARIX.

До 200 файлов сервис восстанавливает бесплатно, а при большем количестве взимает небольшую плату.
Веб-архив может быть вам полезен и тем, что он содержит колоссальное количество уникальных текстов, которые опубликованы на канувших в небытие ресурсах. Как это можно использовать с выгодой для своего бизнеса? Допустим, вы запускаете сайт. Сами писать тексты не можете из-за отсутствия времени, а на оплату услуг копирайтера денег нет. Чтобы не откладывать запуск проекта, попробуйте найти уникальный контент в Wayback Machine.
Найдите любой сайт, близкий вашему по тематике, откройте его содержимое, скопируйте тексты и прогоните их через софт или сервис проверки на плагиат. Статьи, которые окажутся уникальными (от 90% и выше), вы можете без зазрения совести опубликовать на своем сайте. Это не будет считаться хищением, так как тексты после удаления ресурсов стали ничейными.
Для поиска таких сайтов можно использовать базы хостинговых компаний. Обычно они публикуют список тех доменов, срок действия которых истек или вот-вот истечет. Существуют и специальные программы, которые ищут освободившиеся домены по нужным параметрам.
Несколько фактов о веб-архиве
Первый запуск сервиса WebArchive состоялся в 1996 году. С тех пор этот инструмент сумел накопить в своей базе более 338 миллиардов сайтов. Представьте, сколько это! А дисковое пространство, которое занято информацией в архиве, составляет 1015 Терабайт. Если перевести на математический язык, то это квадриллион.

На следующий год после основания сервиса WebArchive добавил в свою базу сам себя. Хотите посмотреть, как он выглядел на тот момент? Тогда взгляните на изображение ниже.

Это самый первый его снимок от 26 января 1997 года.
На данный момент веб-архив считается наилучшим способом из бесплатных для создания снимков интернет-ресурсов. Возьмите его на вооружение.
Раньше история человечества фиксировалась на картинах, в книгах, письмах и газетах. Эти носители хранятся в картинных галереях, крупных библиотеках и исторических архивах. Сейчас значимые события обязательно появляются на сайтах, видеохостингах и в социальных сетях. Но сайты, как и книги, не вечны. Их удаляют, как только они становятся не нужны. Для сохранения этих данных есть веб-архив. Он доступен всем пользователям в любое время.
Что такое веб-архив и как им пользоваться
Веб-архив (web archive) – это бесплатная электронная библиотека, где вместо книг хранятся сайты. Сервис периодически делает снимки (снэпшоты) веб-ресурсов и сохраняет их. То есть вы всегда сможете увидеть, как выглядел сайт в момент, когда была сделана копия.
Как работает веб-архив? У каждого сайта могут быть сотни сохраненных копий. Частота снимков зависит от популярности веб-ресурса: у страниц с многотысячным трафиком копии могут делаться ежедневно или даже пару раз в день.
Есть несколько веб-архивов, например, archive.md (также он размещен на адресах archive.ph и archive.today), но самым популярным и удобным считается Wayback Machine. Сервис был создан в 1996 году Брюстером Кейлом. И создавался с целью сохранить историю развития интернета. А с 1999 года Wayback Machine стал фиксировать также аудио, видео, иллюстрации и ПО. За почти 30 лет он успел собрать 737 миллиардов страниц, поэтому далее мы будем рассматривать именно этот веб-архив.
Для чего нужен архив сайтов
- Для восстановления своего сайта. Никто не застрахован от поломки веб-ресурса. Конечно, лучше настраивать автоматическое резервное копирование. Но если его у вас его всё-таки нет, не беда. Найдите ближайшую версию сайта в веб-архиве и восстановите ее. Восстановить можно как вручную, так и с помощью дополнительных программ.
- Для анализа конкурентов. Ваши конкуренты могут тестировать лучшее расположение кнопок и баннеров, менять меню и цветовую гамму сайта. Всю историю изменений вы можете проследить в веб-архиве и сделать выводы для развития своего проекта.
- Поиск информации с удаленного веб-ресурса. Некоторые проекты закрываются, сайты удаляются и, возможно, ценная информация теряется. Поисковик может долго давать вам ссылку на уже нерабочий сайт. Но как узнать, что там было? Просто зайдите в веб-архив.
- Проанализировать историю домена перед покупкой. Покупая дроп-домен, вы рискуете приобрести веб-адрес с плохой историей: сайт на этом домене мог в лучшем случае быть непопулярным, а в худшем на нем распространялся недобросовестный контент, вследствие чего веб-адрес попал в черный список. Если у домена плохая история, проекту его нового владельца не поздоровится.
- Для проведения интересного расследования или погружения в приятную ностальгию. Веб-архив ― это современный кладезь знаний. В нем можно найти много интересного, проследить, как развивались крупные компании и какие интересные проекты реализовывались, на заре эры интернета.
- Поиск интересного контента для рерайта. Если сайт не выглядел современно, как сейчас, это не значит, что над его контентом не работали талантливые люди. Вы можете вдохновиться или даже взять информацию со старых страниц и опубликовать её на своем сайте. Но об этом мы поговорим позже.
Как посмотреть страницу в веб-архиве
Чтобы проследить историю конкретного сайта, вам нужно знать только его домен.
- Перейдите на сайт Wayback Machine.
- Введите адрес сайта или конкретной страницы.
-
Нажмите BROWSE HISTORY:

-
Перед вами появится временная шкала и календарь. Вы можете заметить, что разные даты имеют разный цвет:
✅ голубой ― при архивации не возникло проблем,
✅ зелёный ― был настроен редирект,
✅ оранжевый ― при архивации произошла ошибка на стороне клиента,
✅ красный ― проблемы на стороне сервера.Чаще всего нужны даты, которые находятся в голубых или зеленых кружках.
- Выберите необходимый год, месяц и дату. Теперь вы можете увидеть прошлые версии сайта. Вперед к изучению!

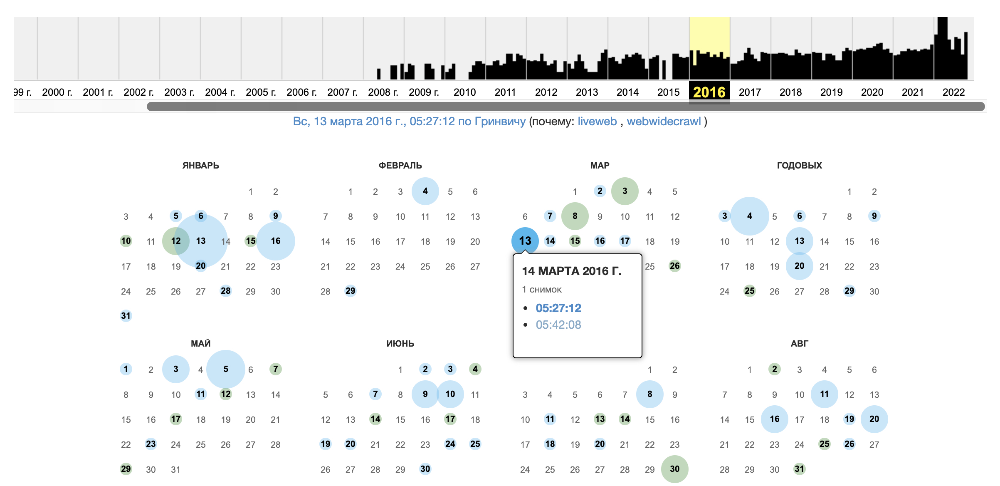

Вот так выглядел наш сайт в марте 2016 года
Если вы не знаете конкретный URL сайта, в поиск можно вбить ключевое слово, название компании или бренда. Архив выдаст вам все подходящие варианты, которые найдет у себя в хранилище.
С чем вы можете столкнуться
Во-первых, в некоторых версиях сайта может не быть картинок и элементов дизайна. К сожалению, тут ничего не поделаешь. В этой ситуации можно попробовать посмотреть другой снимок.
Во-вторых, сайт может вообще отсутствовать. Это происходит в случае, если:
- владелец веб-ресурса потребовал удалить копии его контента,
- снимки сайта удалили, так как проект нарушал закон о защите интеллектуальной собственности,
- создатели сайта ограничили доступ роботам веб-архива.
Как самостоятельно добавить версию сайта
Хотите, чтобы ваш сайт точно сохранился в архиве и копий было много?Возьмите дело в свои руки и добавьте копию сайта самостоятельно.
Для этого:
- В правом нижнем углу найдите поле Save Page Now.
- Введите в поле домен сайта и нажмите Save page:

Это актуально для небольших сайтов с маленьким трафиком, так как копии таких ресурсов делаются редко.
Как удалить копии сайта и запретить дальнейшее сохранение в веб-архив
Может случиться и обратная ситуация, когда владелец сайта не хочет, чтобы его сайт попал в веб-архив. Такое сделать тоже нетрудно. Для этого вам нужно ограничить веб-архиву доступ в robots.txt. Файл находится в корневой папке сайта. В robots.txt нужно добавить код:
User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: /
После вписанных в файл настроек существующие версии сайта удалятся из архива, а новые перестанут создаваться до тех пор, пока домен зарегистрирован и в robots.txt указаны настройки. Если регистрация домена закончится и он не будет продлен, старые версии сайта вернутся в веб-архив. То есть удалить историю сайта одним движением навсегда не получится.
Как восстановить сайт из веб-архива
Восстановление сайта можно сделать двумя способами:
- с использованием программ-помощников.
- вручную.
Хотим предостеречь! Веб-архив действительно может помочь в критической ситуации, но он ни в коем случае не заменит бэкапы. С какими проблемами вы можете столкнуться:
- Не все страницы сохраняются. Веб-архив не делает полную копию сайта. В основном 50-70%. Самые непопулярные страницы, скорее всего, будут потеряны. Однако, если никакой альтернативы нет, это лучше, чем ничего.
- Код может быть замусорен. Часто веб-архив добавляет свои строки кода, что влияет на чистоту написанного сайта. После восстановления код, скорее всего, придется чистить.
- Могут измениться URL страниц.
Способ 1. С использованием программ
Сейчас уже есть много программ, которые помогут скачать сайт из веб-архива. Вам останется только поместить файлы веб-сервиса на хостинг. Примеры программ:
✅ Archivarix,
✅ Wayback machine downloader,
✅ Rush Analytics,
✅ RoboTools.
Несмотря на то что сервисы платные, стоят они недорого. Также они могут почистить код и привести скачанные данные в приемлемый вид. Учитывая стоимость работ программиста, это действительно дешевле.
Способ 2. Вручную
- Перейдите на сервер или компьютер, куда нужно скачать копию сайта. Установите Ruby (если нет): sudo apt install ruby
- Теперь установим утилиту для скачивания сайта: sudo gem install wayback_machine_downloader
Дальнейшие действия зависят от того, какая версия сайта вам нужна. Если вам нужна самая последняя версия сайта, введите команду:
wayback_machine_downloader http://site.com
Где http://site.com ― URL нужного сайта.
Если вас интересует конкретная версия сайта:
- Перейдите в веб-архив и выберите нужную версию сайта.
- Скопируйте из URL, который появится при загрузке выбранной версии, только цифры, которые идут после web/:
https://web.archive.org/web/20220322041638/https://2domains.ru/ - Вернитесь на сервер/компьютер, куда хотите скачать копию сайта, и введите:

wayback_machine_downloader http://example.com —from 20220322041638
или
wayback_machine_downloader http://example.com —to 20220322041638
Где 20220322041638 ― номер версии, который вы скопировали из веб-архива.
Чем отличаются команды:
✅ —from ― скачивает файлы только с указанной даты или более поздней версии;
✅ —to ― скачивает файлы только с указанной даты или более ранней версии.
Другие параметры для скачивания можно прочитать здесь. Например, при вводе параметра —exclude можно скачать файлы конкретного типа (pdf, .jpg, .txt).
Теперь ждите, когда скачаются все файлы сайта, и можете переносить их на хостинг. Скачивание файлов может занять как несколько часов, так и несколько дней. Время скачивания зависит от размера сайта.
Теперь нужно просмотреть файлы и привести все в порядок. Как мы уже говорили, у полученного из веб-архива HTML-кода может быть много ненужных строк.
Можно ли использовать уникальный контент из старых материалов
Люди работают над продвижением сайтов. Наполняют их контентом: ведут блоги, делятся советами и лайфхаками, делают расследования и создают продающие тексты. Однако проекты заканчиваются, нередко компании удаляют свои сайты, блогеры перестают вести странички и т. д. Можно ли пользоваться всем этим полезным контентом в своих целях? Конечно, да. Мы не будем рассуждать об этической составляющей этого действия. С точки зрения закона и со стороны поисковых систем никаких претензий не будет.
Через некоторое время удаленные сайты перестают индексироваться поисковыми системами, то есть, если вы перезальете текст с нерабочей страницы к себе на веб-ресурс, система будет считать его уникальным.
Главное, чтобы кто-то другой не сделал также с выбранной вами статьей. Вполне возможно, что вы ни один такой умный искатель контента. Поэтому, как только вы нашли подходящий текст, обязательно проверьте его на уникальность. Сделать это можно, например, на text.ru или content-watch.ru.
Проверить, свободен ли домен, можно в Whois или посмотреть среди освободившихся доменов.
Где хранится история интернета? Теперь вы знаете ответ. Вперед за удивительными и интересными открытиями!
![]()
Загрузить PDF
![]()
Загрузить PDF
Вы когда-нибудь задумывались, как некоторый сайт выглядел в прошлом? Хотите посмотреть сайт Microsoft на момент выпуска Windows XP? Тогда вперед! Wayback Machine — это архив старых версий сайтов. В этой статье мы расскажем вам, как на Wayback Machine найти заархивированную версию сайта, а также как добавить сайты в этот архив.
-
1
Перейдите на страницу https://web.archive.org в веб-браузере. Это можно сделать на компьютере или мобильном устройстве. Заархивируйте текущую версию сайта, чтобы ссылаться на него в будущем.[1]
-
2
Введите URL-адрес сайта, который хотите добавить в архив. Сделайте это в поле «Save Page Now» (Сохранить страницу сейчас). Оно находится в правой нижней части страницы.
- Чтобы скопировать полный URL-адрес сайта, который будет заархивирован, откройте этот сайт в веб-браузере, а затем скопируйте адрес из адресной строки в верхней части экрана.
- На компьютере выделите URL-адрес и нажмите ⌘ Cmd+C (Mac) или Ctrl+C (PC), чтобы скопировать его. Теперь щелкните правой кнопкой мыши по полю «Save Page Now» и в меню выберите «Вставить», чтобы вставить скопированный URL-адрес.
- На мобильном устройстве выделите URL-адрес, нажмите и удерживайте его, а затем в меню выберите «Копировать». Чтобы вставить скопированный URL-адрес в поле «Save Page Now», нажмите и удерживайте его, а затем в меню нажмите «Вставить».
Совет: будьте внимательны при вводе адреса. Wayback Machine заархивирует контент только на одной странице, а не на других связанных страницах. Например, чтобы заархивировать страницу с данной статьей, введите https://www.wikihow.com/Use-the-Internet-Archive%27s-Wayback-Machine. Если же ввести адрес https://www.wikihow.com, будет заархивирована только главная страница wikiHow.
- Чтобы скопировать полный URL-адрес сайта, который будет заархивирован, откройте этот сайт в веб-браузере, а затем скопируйте адрес из адресной строки в верхней части экрана.
-
3
Нажмите SAVE PAGE (Сохранить страницу). Эта кнопка находится справа от текстового поля с адресом. В верхнем левом углу появится миниатюра веб-сайта и текст «Saving page now» (Сохранение страницы). Текст исчезнет, когда страница будет добавлена в архив.
- Некоторые веб-сайты нельзя заархивировать на Wayback Machine из-за их конфигурации. Если появилась ошибка, владелец сайта запретил Wayback Machine работать с сайтом.
Реклама



-
1
Перейдите по адресу https://web.archive.org в веб-браузере. С помощью Wayback Machine старые версии веб-сайтов можно просматривать на любом компьютере и мобильном устройстве.
-
2
-
3
Нажмите ↵ Enter или ⏎ Return. Отобразятся результаты поиска в виде гистограммы и календаря.
- Если вы искали сайт по его имени или ключевому слову, появится список сайтов. Нажмите на URL-адрес сайта, а затем перейдите к следующему шагу.
-
4
Выберите год на гистограмме. По умолчанию на гистограмме, которая расположена в верхней части страницы, будет выбран текущий год. Черные полосы указывают, сколько раз страница была заархивирована Wayback Machine за этот год. Щелкните по области над годом, чтобы открыть 12-месячный календарь.
Примечание: если в нужном вам году черных полос нет, в этом году страница ни разу не сохранялась.
-
5
Нажмите на число (дату) в календаре. В зависимости от сайта вокруг некоторых чисел в календаре отобразятся зеленые и/или синие кружки. Если число обведено, в этот день сайт был заархивирован. Щелкните по числу, чтобы открыть заархивированную версию веб-сайта.
- Если в какой-то день сайт был заархивирован несколько раз, диаметр кружка будет больше. Наведите курсор мыши на число, чтобы просмотреть список заархивированных версий, а затем нажмите на время архивирования, чтобы открыть нужную версию сайта.
- Если появилась ошибка, сайту запрещено работать с Wayback Machine. Также ошибка может означать, что сайт был недоступен во время архивирования.
- В зависимости от метода архивирования сайта можно щелкнуть по ссылке на странице, чтобы просмотреть другой заархивированный контент. Но, как правило, переход по ссылке на заархивированном сайте приводит к ошибке.
-
6
Просмотрите другие заархивированные версии сайта. Вверху заархивированного сайта отображается гистограмма — используйте ее, чтобы просматривать версии сайта, заархивированные в других числах. С помощью значков в виде синих стрелок перейдите к предыдущей или следующей заархивированной версии сайта, или щелкните по другой дате.
Реклама






Советы
- В некоторых старых архивах контента нет. В этом случае выберите другое число и посмотрите, есть ли на сайте контент.
- Авторизоваться на заархивированном сайте не получится. Это сделано для того, чтобы предотвратить комментирование старых версий сайтов и чтобы защитить скриншоты, так их редактирование сродни внесению изменений в историю.
Реклама
Об этой статье
Эту страницу просматривали 26 549 раз.