В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом  (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее  мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
![[ begin{array}{l} 1: 600-394 = 206 \ 2: 470-394 = 76 \ 3: 170-394 = -224\ 4: 430-394 = 36\ 5: 300-394 = -94 end{array} ]](https://yourtutor.info/wp-content/ql-cache/quicklatex.com-3916a3ccd97d909589dfe1dabb970af0_l3.png "Rendered by QuickLaTeX.com")
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия  мм2.
мм2.
Таким образом, дисперсия составляет 21704 мм2.
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть  значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм2.
мм2.
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
 .
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Среднее квадратичное отклонение двух, трех, четырех и более чисел. Оно же стандартное отклонение, среднеквадратическое отклонение, среднеквадратичное отклонение, средняя квадратическая, стандартный разброс — показатель рассеивания значений случайной величины относительно её математического ожидания в теории вероятностей и статистике.
Как правило перечисленные термины равны квадратному корню дисперсии.
Пример вычисления стандартного отклонения по следующим формулам:
Вычислим среднюю оценку ученика: 2; 4; 5; 6; 8.
Cредняя оценка будет равна:

Вычисляем квадраты отклонений оценок от их средней оценки:

Вычислим среднее арифметическое (дисперсию) этих значений:

Стандартное отклонение равно квадратному корню дисперсии:

Эта формула справедлива только если эти пять значений и являются генеральной совокупностью. Если бы эти данные были случайной выборкой из какой-то большой совокупности (например, оценки пяти случайно выбранных учеников большого города), то в знаменателе формулы для вычисления дисперсии вместо n = 5 нужно было бы поставить n − 1 = 4:

Тогда стандартное отклонение будет равняться:

Этот результат называется стандартным отклонением на основании несмещённой оценки дисперсии. Деление на n − 1 вместо n даёт неискажённую оценку дисперсии для больших генеральных совокупностей.
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone — просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android — просто добавьте страницу
«На главный экран»

Смотрите также
![]()
Загрузить PDF
![]()
Загрузить PDF
Вычислив среднеквадратическое отклонение, вы найдете разброс значений в выборке данных.[1]
Но сначала вам придется вычислить некоторые величины: среднее значение и дисперсию выборки. Дисперсия – мера разброса данных вокруг среднего значения.[2]
Среднеквадратическое отклонение равно квадратному корню из дисперсии выборки. Эта статья расскажет вам, как найти среднее значение, дисперсию и среднеквадратическое отклонение.
-

1
Возьмите наборе данных. Среднее значение – это важная величина в статистических расчетах.[3]
- Определите количество чисел в наборе данных.
- Числа в наборе сильно отличаются друг от друга или они очень близки (отличаются на дробные доли)?
- Что представляют числа в наборе данных? Тестовые оценки, показания пульса, роста, веса и так далее.
- Например, набор тестовых оценок: 10, 8, 10, 8, 8, 4.
-
2
Для вычисления среднего значения понадобятся все числа данного набора данных.[4]
- Среднее значение – это усредненное значение всех чисел в наборе данных.
- Для вычисления среднего значения сложите все числа вашего набора данных и разделите полученное значение на общее количество чисел в наборе (n).
- В нашем примере (10, 8, 10, 8, 8, 4) n = 6.
-
3
Сложите все числа вашего набора данных.[5]
- В нашем примере даны числа: 10, 8, 10, 8, 8 и 4.
- 10 + 8 + 10 + 8 + 8 + 4 = 48. Это сумма всех чисел в наборе данных.
- Сложите числа еще раз, чтобы проверить ответ.
-
4
Разделите сумму чисел на количество чисел (n) в выборке. Вы найдете среднее значение.[6]
- В нашем примере (10, 8, 10, 8, 8 и 4) n = 6.
- В нашем примере сумма чисел равна 48. Таким образом, разделите 48 на n.
- 48/6 = 8
- Среднее значение данной выборки равно 8.
Реклама




-
1
Вычислите дисперсию. Это мера разброса данных вокруг среднего значения.[7]
- Эта величина даст вам представление о том, как разбросаны данные выборки.
- Выборка с малой дисперсией включает данные, которые ненамного отличаются от среднего значения.
- Выборка с высокой дисперсией включает данные, которые сильно отличаются от среднего значения.
- Дисперсию часто используют для того, чтобы сравнить распределение двух наборов данных.
-
2
Вычтите среднее значение из каждого числа в наборе данных. Вы узнаете, насколько каждая величина в наборе данных отличается от среднего значения.[8]
- В нашем примере (10, 8, 10, 8, 8, 4) среднее значение равно 8.
- 10 — 8 = 2; 8 — 8 = 0, 10 — 2 = 8, 8 — 8 = 0, 8 — 8 = 0, и 4 — 8 = -4.
- Проделайте вычитания еще раз, чтобы проверить каждый ответ. Это очень важно, так как полученные значения понадобятся при вычислениях других величин.
-
3
Возведите в квадрат каждое значение, полученное вами в предыдущем шаге.[9]
- При вычитании среднего значения (8) из каждого числа данной выборки (10, 8, 10, 8, 8 и 4) вы получили следующие значения: 2, 0, 2, 0, 0 и -4.
- Возведите эти значения в квадрат: 22, 02, 22, 02, 02, и (-4)2 = 4, 0, 4, 0, 0, и 16.
- Проверьте ответы, прежде чем приступить к следующему шагу.
-
4
Сложите квадраты значений, то есть найдите сумму квадратов.[10]
- В нашем примере квадраты значений: 4, 0, 4, 0, 0 и 16.
- Напомним, что значения получены путем вычитания среднего значения из каждого числа выборки: (10-8)^2 + (8-8)^2 + (10-2)^2 + (8-8)^2 + (8-8)^2 + (4-8)^2
- 4 + 0 + 4 + 0 + 0 + 16 = 24.
- Сумма квадратов равна 24.
-
5
Разделите сумму квадратов на (n-1). Помните, что n – это количество данных (чисел) в вашей выборке. Таким образом, вы получите дисперсию.[11]
- В нашем примере (10, 8, 10, 8, 8, 4) n = 6.
- n-1 = 5.
- В нашем примере сумма квадратов равна 24.
- 24/5 = 4,8
- Дисперсия данной выборки равна 4,8.
Реклама





-
1
Найдите дисперсию, чтобы вычислить среднеквадратическое отклонение.[12]
- Помните, что дисперсия – это мера разброса данных вокруг среднего значения.
- Среднеквадратическое отклонение – это аналогичная величина, описывающая характер распределения данных в выборке.
- В нашем примере дисперсия равна 4,8.
-
2
Извлеките квадратный корень из дисперсии, чтобы найти среднеквадратическое отклонение.[13]
- Как правило, 68% всех данных расположены в пределах одного среднеквадратического отклонения от среднего значения.
- В нашем примере дисперсия равна 4,8.
- √4,8 = 2,19. Среднеквадратическое отклонение данной выборки равно 2,19.
- 5 из 6 чисел (83%) данной выборки (10, 8, 10, 8, 8, 4) находится в пределах одного среднеквадратического отклонения (2,19) от среднего значения (8).
-
3
Проверьте правильность вычисления среднего значения, дисперсии и среднеквадратического отклонения. Это позволит вам проверить ваш ответ.[14]
- Обязательно записывайте вычисления.
- Если в процессе проверки вычислений вы получили другое значение, проверьте все вычисления с самого начала.
- Если вы не можете найти, где сделали ошибку, проделайте вычисления с самого начала.
Реклама



Об этой статье
Эту страницу просматривали 65 043 раза.
Была ли эта статья полезной?
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
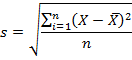
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:
Числовые характеристики распределения вероятностей. Математическое ожидание, дисперсия и стандартное отклонение
- Закон распределения дискретной случайной величины
- Математическое ожидание
- Дисперсия
- Среднее квадратичное отклонение
- Правило трёх сигм
- Примеры
п.1. Закон распределения дискретной случайной величины
Законом распределения дискретной случайной величины называют соответствие между полученными на опыте значениями этой величины X= {xi} и их вероятностями pi = P(xi).
При этом сумма всех вероятностей равна 1: (mathrm{sum_{i=1}^n p_i=1})
Закон распределения можно задать таблицей, графиком или аналитически (в виде формулы).
Например:
Закон распределения случайной величины X = {0;1;2;3}, равной числу выпадения орлов при 3 бросках монеты, аналитически задаётся формулой: $$ mathrm{ p_i=P(x_i)=P_3(i)=frac{C_3^{i}}{2^3}, i={0;1;2;3} } $$
В табличном виде:
|
xi |
pi |
|
0 |
1/8 |
|
1 |
3/8 |
|
2 |
3/8 |
|
3 |
1/8 |
В виде графика:

п.2. Математическое ожидание
Математическое ожидание дискретной случайной величины X = {xi} равно сумме произведений всех возможных значений xi на соответствующие вероятности pi: $$ mathrm{ M(X)=x_1p_1+x_2p_2+…+x_{n}p_{n}=sum_{i=1}^n x_{i}p_{i} } $$ Математическое ожидание является средним значением величины X.
Свойства математического ожидания
1) Размерность математического ожидания равна размерности случайной величины.
2) Математическое ожидание может быть любым действительным числом: положительным, равным 0, отрицательным.
3) Математическое ожидание постоянной величины равно этой постоянной:
M(C) = C
4) Математическое ожидание суммы независимых случайных величин равно сумме математических ожиданий:
M(X + Y) = M(X) + M(Y)
5) Математическое ожидание произведения двух независимых случайных величин равно произведению математических ожиданий:
M(XY) = M(X) · M(Y)
6) Постоянный множитель можно вынести за знак математического ожидания:
M(CX) = C · M(X)
Например:
Пусть в результате экспериментов получено следующее распределение случайной величины X – числа появления белых шаров (см. пример 1, §40 данного справочника):
| Число белых шаров, xi | 0 | 1 | 2 | 3 | 4 | 5 |
| pi | (mathrm{C_5^0q^5}) | (mathrm{C_5^1pq^4}) | (mathrm{C_5^2p^2q^3}) | (mathrm{C_5^3p^3q^2}) | (mathrm{C_5^4p^4q}) | (mathrm{C_5^5p^5}) |
| 0,0074 | 0,0618 | 0,2060 | 0,3433 | 0,2861 | 0,0954 |
Найдём математическое ожидание для данного распределения:
M(X) = 0 · 0,0074 + 1 · 0,0618 + … + 5 · 0,0954 = 3,125
п.3. Дисперсия
Дисперсия дискретной случайной величины X = {xi} – это математическое ожидание квадрата отклонения случайной величины от её математического ожидания: $$ mathrm{ D(X)=M(X-M(X))^2 } $$ На практике дисперсия рассчитывается по формуле: $$ mathrm{ D(X)=M(X)^2-M^2(X)=sum_{i=1}^n x_i^2p_i-M^2(X) } $$
Свойства дисперсии
1) Размерность дисперсии равна квадрату размерности случайной величины.
2) Дисперсия может быть любым неотрицательным действительным числом.
3) Дисперсия постоянной величины равна нулю:
D(C) = 0
4) Дисперсия суммы независимых случайных величин равна сумме дисперсий:
D(X + Y) = D(X) + D(Y)
5) Постоянный множитель можно вынести за знак дисперсии:
D(CX) = C2 · D(X)
Например:
Продолжим исследование и найдём дисперсию для распределения случайной величины X – числа появления белых шаров. Составим расчётную таблицу:
pi
0,0074
0,0618
0,2060
0,3433
0,2861
0,0954
1
xip1
0
0,0618
0,4120
1,0300
1,1444
0,4768
3,125
(mathrm{x_i^2})
0
1
4
9
16
25
–
(mathrm{x_i^2p_i})
0
0,0618
0,8240
3,0899
4,5776
2,3842
10,9375
Получаем: D(X) = 10,9375 – 3,1252 ≈ 1,1719.
п.4. Среднее квадратичное отклонение
Среднее квадратичное отклонение (СКО) дискретной случайной величины X = {xi} – это корень квадратный от дисперсии: $$ mathrm{ sigma(X)=sqrt{D(X)} } $$ СКО характеризует степень отклонения случайной величины от среднего значения.
Свойства СКО
1) Размерность СКО равна размерности случайной величины.
2) СКО может быть любым неотрицательным действительным числом.
3) СКО постоянной величины равно нулю:
σ(C) = 0
4) Постоянный множитель можно вынести за знак СКО:
σ(CX) = C · σ(X)
п.5. Правило трёх сигм
Большое количество случайных величин, измеряемых в экспериментах (например, в школьных лабораторных работах), имеет так называемое нормальное распределение.
В частности, при больших n, биномиальное распределение можно с хорошей точностью описывать как нормальное с M(X) = np и (mathrm{sigma(X)=sqrt{npq}}).
График плотности нормального распределения p(x) похож на колокол, с максимумом, соответствующим M(X) = Xcp – среднему значению измеряемой величины.
Величина СКО σ(X) характеризует степень отклонения X от среднего значения M(X).
Если величина X имеет нормальное распределение, то в пределах
±σ лежит 68,26% значений, принимаемых этой величиной
±2σ лежит 95,44% значений, принимаемых этой величиной
±3σ лежит 99,72% значений, принимаемых этой величиной
Вероятность того, что нормально распределённая величина примет значение, отклоняющееся от среднего больше, чем на «три сигмы», равна 0,28%, т.е. пренебрежимо мала.
п.6. Примеры
Пример 1. Найдите математическое ожидание, дисперсию и СКО при бросании кубика.
Закон распределения величины X – очки на верхней грани при бросании кубика и расчётная таблица:
pi
1/6
1/6
1/6
1/6
1/6
1/6
1
xip1
1/6
1/3
1/2
2/3
5/6
1
3,5
(mathrm{x_i^2})
1
4
9
16
25
36
–
(mathrm{x_i^2p_i})
(mathrm{frac16})
(mathrm{frac23})
(mathrm{1frac12})
(mathrm{2frac23})
(mathrm{4frac16})
6
(mathrm{15frac16})
Получаем: begin{gather*} mathrm{ M(X)=sum_{i=1}^6 x_ip_i=3,5 }\ mathrm{ D(X)=sum_{i=1}^6 x_i^2p_i-M^2(X)=15frac16-3,5^3=2frac{11}{12} }\ mathrm{ sigma(X)=sqrt{D(X)}=sqrt{2frac{11}{12}}approx 1,7 } end{gather*} Ответ: (mathrm{M(X)=3,5; D(X)=2frac{11}{12}; sigma(X)approx 1,7}).
Пример 2*. Найти математическое ожидание, дисперсию и СКО суммы очков при бросании двух кубиков.
Используем свойства мат.ожиданий и дисперсий.
Пусть X – очки на первом кубике, Y – на втором.
Параметры распределения для каждого из кубиков рассчитаны в примере 1.
(mathrm{M(X)=M(Y)=3,5, D(X)=D(Y)=2frac{11}{12}}).
Для суммы очков получаем:
(mathrm{M(X+Y)=M(X)+M(Y)=3,5+3,5=7})
(mathrm{D(X+Y)=D(X)+D(Y)=2frac{11}{12}+2frac{11}{12}=5frac56})
(mathrm{sigma(X+Y)=sqrt{D(X+Y)}=sqrt{5frac56}approx 2,4})
Ответ: (mathrm{M(X+Y)=7; D(X+Y)=5frac56; sigma(X+Y)approx 2,4}).
Пример 3*. Докажите, что в опытах по схеме Бернулли математическое ожидание M(X)=np, а дисперсия D(X)=npq.
Проведем один опыт. В нём может быть только два исхода: «успех» и «неудача».
Составим расчётную таблицу:
(mathrm{x_i^2p_i})
0
p
p
Мат.ожидание первого опыта (mathrm{M(X)=sum x_ip_i=p}).
Общее число успехов при n опытах складывается из числа успехов при каждом опыте, т.е. (mathrm{X=X_1+X_2+…+X_n}). Все опыты между собой независимы.
По свойству мат.ожидания суммы независимых событий: begin{gather*} mathrm{ M(X)=M(X_1+X_2+…+X_n)=M(X_1)+M(X_2)+…+M(X_n)= }\ mathrm{=underbrace{p+p+…+p}_{n text{раз}}=np } end{gather*} Дисперсия первого опыта (mathrm{D(X)=sum x_i^2p_i-M(X)=p-p^2=p(1-p)=pq})
По свойству дисперсии суммы независимых событий: begin{gather*} mathrm{ D(X)=D(X_1+X_2+…+X_n)=D(X_1)+D(X_2)+…+D(X_n)= }\ mathrm{=underbrace{pq+pq+…+pq}_{n text{раз}}=npq } end{gather*} Что и требовалось доказать.
Пример 4. 100 канцелярских кнопок высыпали на стул. Вероятность, что кнопка упала острием вверх, равна 0,4. Найдите среднее количество, дисперсию и СКО для числа кнопок, упавших острием вверх. Найдите интервал оценки для количества этих кнопок по правилу «трёх сигм».
По условию n = 100, p = 0,4.
Для каждой кнопки может быть два исхода: упасть острием вверх или вниз.
Таким образом, это испытание Бернулли с биномиальным распределением случайной величины. begin{gather*} mathrm{ M(X)=np=100cdot 0,4=40 }\ mathrm{D(X)=npq=100cdot 0,4cdot 0,6=24 }\ mathrm{sigma(X)=sqrt{D(X)}=sqrt{24}approx 4,9} end{gather*} Интервал оценки «три сигмы»: begin{gather*} mathrm{ M(X)-3sigma(X)lt Xlt M(X)+3sigma(X) }\ mathrm{40-3cdot 4,9lt Xlt 40+3cdot 4,9 }\ mathrm{25,3lt Xlt 54,7}\ mathrm{26leq Xleq 54} end{gather*} Скорее всего (99,7%), от 26 до 54 кнопок будут острием вверх.
Ответ: (mathrm{M(X)=40; D(X)=24; sigma(X)approx 4,9; 26leq Xleq 54})
Пример 5*. В тесте 10 задач с 4 вариантами ответов. Ответы выбираются наугад. Постройте распределение величины X = «количество угаданных ответов», найдите числовые характеристики этого распределения.
Найдите интервал оценки для количества угаданных ответов по правилу «трёх сигм».
Какова вероятность угадать хотя бы 1 ответ? Хотя бы 5 ответов? Угадать все 10 ответов?
По условию: (mathrm{n=10, p=frac14, q=frac34}).
Для каждого ответа может быть два исхода: «угадал»/ «не угадал».
Таким образом, это испытание Бернулли с биномиальным распределением случайной величины. $$ mathrm{ P_{10}(k)=C_{10}^kp^kq^{10-k}=C_{10}^kfrac{3^{10-k}}{4^{10}}=left(frac34right)^{10}frac{C_{10}^k}{3^k} } $$ Строим расчётную таблицу. Для (mathrm{C_{10}^k}) используем рекуррентную формулу (см. §36 данного справочника): $$ mathrm{ C_{n}^k=frac{n-k+1}{k}C_n^{k-1} } $$
| (mathrm{x_i=k}) | (mathrm{C_k}) | (mathrm{3^k}) | (mathrm{p_i(x_i)}) | (mathrm{x_icdot p_i}) | (mathrm{x_i^2}) | (mathrm{x_i^2cdot p_i}) |
| 0 | 1 | 1 | 0,0563135 | 0,0000000 | 0 | 0,0000000 |
| 1 | 10 | 3 | 0,1877117 | 0,1877117 | 1 | 0,1877117 |
| 2 | 45 | 9 | 0,2815676 | 0,5631351 | 4 | 1,1262703 |
| 3 | 120 | 27 | 0,2502823 | 0,7508469 | 9 | 2,2525406 |
| 4 | 210 | 81 | 0,1459980 | 0,5839920 | 16 | 2,3359680 |
| 5 | 252 | 243 | 0,0583992 | 0,2919960 | 25 | 1,4599800 |
| 6 | 210 | 729 | 0,0162220 | 0,0973320 | 36 | 0,5839920 |
| 7 | 120 | 2187 | 0,0030899 | 0,0216293 | 49 | 0,1514053 |
| 8 | 45 | 6561 | 0,0003862 | 0,0030899 | 64 | 0,0247192 |
| 9 | 10 | 19683 | 0,0000286 | 0,0002575 | 81 | 0,0023174 |
| 10 | 1 | 59049 | 0,0000010 | 0,0000095 | 100 | 0,0000954 |
| Σ | 1 | 2,5 | 8,125 |
Получаем: begin{gather*} mathrm{ M(X)=sum_{i=0}^{10} x_ip_i=2,5 }\ mathrm{ D(X)=sum_{i=0}^{10} x_i^2p_i-M^2(X)=8,125=2,5^2=1,875 }\ mathrm{ sigma(X)=sqrt{D(X)}=sqrt{1,875}approx 1,37 } end{gather*} 
Интервал оценки «три сигмы»: begin{gather*} mathrm{ M(X)-3sigma(X) lt Xlt M(X)+3sigma(X) }\ mathrm{ 2,5-3cdot 1,37lt X lt 2,5+3cdot 1,37 }\ mathrm{ -1,61lt Xlt 6,61 }\ mathrm{ 0leq Xleq 6 } end{gather*} Скорее всего (по расчетам – 99,65%), вы угадаете от 0 до 6 ответов.
Вероятность угадать хотя бы один ответ: begin{gather*} mathrm{ P(Xgeq 1)=1-p_0approx 1-0,0563=0,9437 }end{gather*} Очень хорошие шансы – 94,37%.
Вероятность угадать хотя бы 5 ответов: begin{gather*} mathrm{ P(Xgeq 5)=1-left(sum_{i=0}^{4}{p_i} right)approx 1-(0,0563+0,1877+…+0,1460)=0,0781 }end{gather*} Шансов мало – 7,81%. Т.е. «средний балл» при сдаче тестов мало достижим методом научного тыка.
Вероятность угадать все 10 ответов: p10≈ 0,000001. Шанс – один из миллиона.