Как найти рифму
Рифма – созвучие слов в стихотворной строфе. Как правило, определяется по конечным слогам строки и обязательно включает в себя один ударный слог. Возможны дополнительные безударные слоги. Опытный поэт легко находит рифму к любому слову или ставит слова в таком порядке, чтобы найти ее было легко. Начинающим стихотворцам полезно знать несколько приемов.

Инструкция
Множество сайтов для поэтов имеют так называемый словарь рифм. После ввода слова в специальное поле ресурс автоматически предлагает несколько десятков вариантов рифм. Однако выбор таких словарей не всегда понятен: в некоторых случаях слова, которые он выдает, никак не соотносятся с исходным, к примеру: грусть – тоска. Поэтому от использования таких словарей пользы немного.
Второй вариант более затруднителен и требует большой умственной работы. Выделите последние слоги строки (от последнего ударного до конца), к примеру: «В поле спустилась лавина тумана». Вас интересуют слоги «ана».
Выпишите на листе все согласные в алфавитном порядке, от «б» до «ш». Добавьте заодно и букву «й» — ученые спорят, является ли она полугласной или полусогласной, но вам она может помочь. Приписывайте выделенное окончание строки к каждой из них, пока не получите слово или конец слова. В вашем случае получится сразу несколько вариантов, запомните их все.
Со временем вы запомните порядок согласных и сможете производить эту операцию в уме. Все зависит от вашей продуктивности.
Начните писать строку. По ее контексту вы поймете, какое из полученных слов нужно использовать и как расположить слова, чтобы получилась стройная пара строк.
При постановке строки учтите, что ряд слов (любовь, друг, нужен, спокоен) имеют ограниченное количество рифм или не имеют их вовсе. Со временем вы найдете целый список таких слов. Храните их в собственной памяти или в специальной тетрадке для «неудобных» рифм. В случае с таким словом, как, к примеру, «любовь», все рифмы известны вдоль и поперек, поэтому использование их опасно (может создаться впечатление небрежности, графоманства): кровь, вновь. С другими словами, у которых точной рифмы в русском языке нет, часто используется приблизительная рифма, но и количество слов и с отдаленно похожим окончанием бывает ограничено. Для таких случаев перемените порядок слов в строке, чтобы на конце оказалось удобная рифма.
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Автоматический поиск рифм — задача, казалось бы, несложная в современном мире. Компьютер умеет переводить текст в его звуковое представление (как можно догадаться по общению с Siri или Алисой). Значит, программа может проанализировать последние звуки в строках и, ориентируясь на них, найти все рифмы?
Не так просто. Во-первых, подобный алгоритм пропустит неточные рифмы, столь любимые поэтами XX и XXI веков. Другой проблемой станут слова, произношение которых в прошлом отличалось от современного. Таким образом, «наивный» метод поиска рифм не даст хороших результатов.
Недостатки этого подхода были учтены в работе чешского стиховеда Петра Плехача (Petr Plecháč). В 2018 году ученый предложил свой способ поиска рифм, основанный на извлечении коллокаций и машинном обучении. Программа, написанная филологом, поддерживает семь языков: чешский, английский, французский, русский, немецкий, испанский, нидерландский.
В этой статье мы подробно расскажем о работе программы на примере ее первой версии, которая поддерживала только английский, французский и чешский языки. О ней Петр Плехач написал научную статью.
Материал для обучения RhymeTagger
Для обучения алгоритма необходим тренировочный датасет. Он собирается автоматически: из корпуса стихотворений соответствующего языка отбираются пары слов, которые программа распознает как рифмы. Как именно это происходит?
- Из стихотворений в корпусе извлекаются последние слова всех строк. Далее программа рассматривает их как обычный текст.
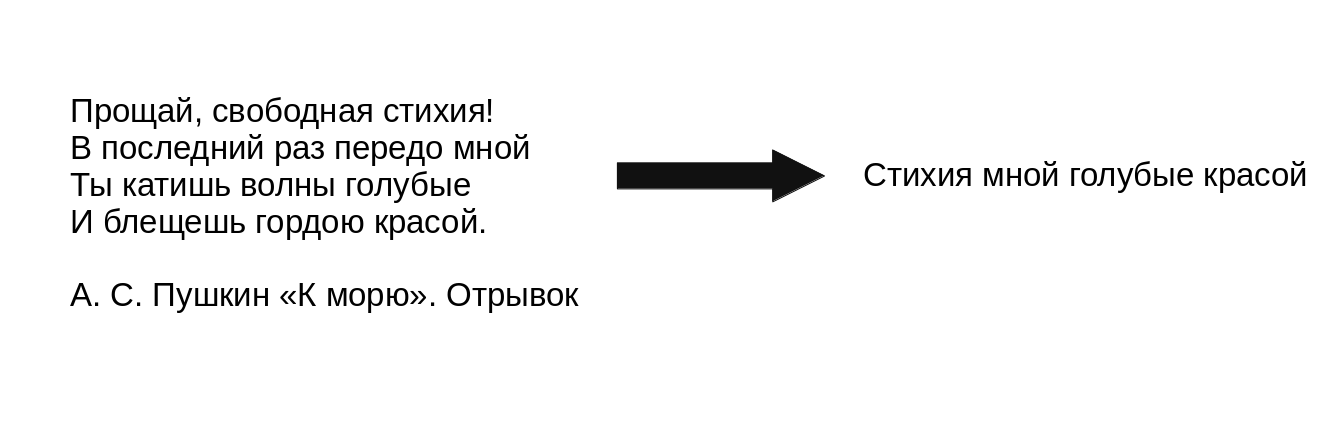
- Алгоритм ищет коллокации — пары слов, которые повторяются достаточно часто (хотя бы 4 раза во всем корпусе); при этом между потенциально рифмующимися словами должно быть не более 3 слов.
- Рассчитывается t-критерий Стьюдента для найденных пар. Он позволяет оценить, с какой точностью можно считать коллокации рифмами, а не случайными парами слов.
- Если значение t-критерия превышает пороговое значение, установленное автором программы, то обнаруженная пара слов попадает в тренировочный датасет, так как она с высокой вероятностью является рифменной.
Обучение алгоритма
У каждого слова в тренировочном датасете есть транскрипция — она была сделана для исходных корпусов стихотворных текстов с помощью существующих программ (KVĚTA для чешского, MaryTTS для английского и французского).
Используя тренировочный датасет, состоящий из рифменных пар, RhymeTagger просчитывает вероятность того, что определенные звуки или наборы звуков рифмуются между собой. Чтобы сделать это, программа сначала извлекает из транскрипции звуки, которые отвечают за создание рифмы. Алгоритм, который выполняет эту операцию, работает так:
- из транскрипции убираются все звуки, предшествующие слогообразующему звуку [1] последнего ударного слога;
- если оставшаяся часть слова длиннее двух слогов, алгоритм убирает часть транскрипции, находящуюся до слогообразующего звука предпоследнего слога;
- затем удаляются все согласные звуки, находящиеся перед первой из оставшихся гласных;
- оставшаяся часть транскрипции слова разбивается на части: слогообразующие звуки и кластеры согласных; получившиеся наборы звуков программа записывает в обратном порядке (последний элемент транскрипции становится первым и т.д.).
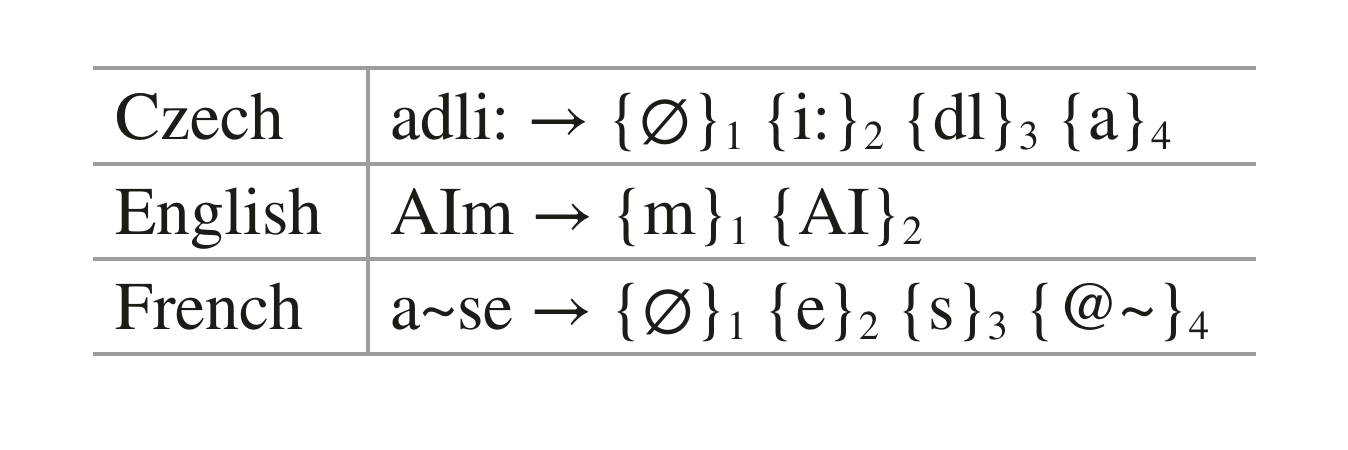
Работа RhymeTagger
На основе данных, полученных при обучении, алгоритм может вычислить вероятность того, что некоторые два слова в корпусе рифмуются. Расчет вероятности включает несколько этапов. Опишем их на примере слов «розы» и «абрикосы».
Для работы программы тексты стихотворений, которые нужно исследовать, должны быть обработаны следующим образом:
- последнее слово каждой строки всех стихотворений должно быть извлечено; эти слова записываются по порядку и создают отдельный текст;
- финальное слово каждой строки должно иметь транскрипцию; она обрабатывается так же, как транскрипции тренировочного датасета.
Исходные тексты стихотворений также нужны для работы алгоритма.
В результате такой обработки «розы» и «абрикосы» будут представлены, соответственно, наборами звуков: {о}, {з}, {ыэ}; {о}, {с}, {ыэ} ({ыэ} — это звук, близкий к {ы}, но имеющий призвук {э}; он произносится на месте буквы «ы», так как последний слог в данных словах не является ударным).
Алгоритм рассчитывает вероятность того, что два слова рифмуются, основываясь на вероятности рифмовки звуков, занимающих одну и ту же позицию в обработанных транскрипциях исследуемых слов. В нашем примере программа будет высчитывать вероятность того, что рифмуются слова, у которых последний звук одинаковый — {ыэ}, предпоследние звуки — {с} и {з} соответственно, а третий с конца звук снова один и тот же: {о}.
Алгоритм работает следующим образом. Для каждой пары звуков, занимающих одинаковые позиции в представленных транскрипциях, выполняются вычисления:
- рассчитывается относительная частотность пар слов (рифм) в составе тренировочного датасета, в которых данные два звука занимают ту же позицию, что и в исследуемых словах; в нашем примере будет определена относительная частотность пар слов, в одном из которых на предпоследнем месте находится звук {с}, а в другом — {з};
- рассчитывается относительная частотность слов во всем необработанном корпусе стихотворений, где {с} занимает предпоследнее место;
- определяется относительная частотность слов в необработанном корпусе, где {з} занимает предпоследнее место;
- вычисляется вероятность того, что исследуемые слова рифмуются, основанная лишь на информации о предпоследнем звуке каждого из исследуемых слов; для этого используется формула:

При выполнении этих шагов препятствием может стать ограниченность тренировочного корпуса: в нем может не оказаться пары слов, где предпоследнюю позицию занимают звуки {з} и {с}. В таком случае действует другой алгоритм: программа проверяет, одинаковы ли в исследуемых словах звуки на интересующей нас позиции. Если они одинаковы, то вероятность рифмовки слов признается высокой — 90%. Если звуки разные (как в нашем примере), то вероятность считается очень низкой — 0.01%.
Выполнив описанные выше шаги, программа вычисляет итоговую вероятность рифмовки исследуемых слов — на этот раз используя данные всех звуков. (Если слова представлены разным количеством звуков, то в более длинной транскрипции «лишние» звуки не учитываются.) Итоговое вычисление выполняется по формуле, которая для нашего примера будет выглядеть так:

В зависимости от количества звуков в транскрипции (от двух до четырех), формула будет меняться. Для слов, в обработанной транскрипции которых осталось только два звука, выражение будет выглядеть так:
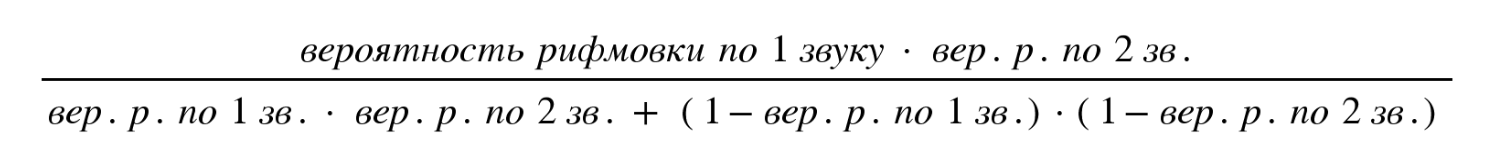
Самую длинную формулу, для четырех звуков, представить себе нетрудно.
Разметка рифм
Алгоритм отметит пару строк в корпусе как рифмующиеся, если их последние слова отвечают двум условиям:
- не совпадают;
- вероятность рифмовки данной пары слов (рассчитанная по формуле выше) больше 95%.
Сами строки при этом должны находиться на определенном расстоянии друг от друга: между ними не должно быть более 3 строк.
Когда подводит транскрипция
Как быть со словами, автоматическая транскрипция которых выполняется неверно, потому что их произношение изменилось со временем? Петр Плехач предлагает ориентироваться на написание. Формула, по которой рассчитывается вероятность рифмовки таких слов, схожа с формулой для расчета вероятности рифмовки на основании информации об одном звуке (это первая формула в статье). Только вместо определенного звука программа ориентируется на последние три символа слова (триграмм).
Как алгоритм определяет, в каких словах лучше учитывать триграммы, а не транскрипцию? Специального списка для этого, конечно, нет. Алгоритм размечает пары рифм на основании триграмм только в том случае, если ни одно из слов в паре не было признано рифмующимся на основании транскрипции.
Завершение обучения
После того как алгоритм отметил все рифмы, которые он смог обнаружить в корпусе, из них создается отдельный датасет. Он становится новым тренировочным корпусом, и с помощью него рифмы в стихотворениях определяются заново. Получившийся новый корпус рифм в свою очередь становится тренировочным — и начинается новый цикл обучения. Так повторяется до тех пор, пока тренировочный датасет и корпус найденных рифм не станут одинаковыми.
Точность алгоритма
По результатам тестирования, которое провел автор программы, RhymeTagger смог найти более 95% рифм в корпусе стихотворений на чешском языке и более 85% — в корпусах поэзии на английском и французском. В целом, во всех трех корпусах алгоритм неверно определял рифмы (принимал за них не рифмующиеся слова) менее чем в 7% случаев. По оценке автора алгоритма, это очень хорошие результаты.
Тестируем инструмент
Как алгоритм работает на практике? Мы решили проверить на примере двух стихотворений — на русском и английском. Для этого мы написали свою программу, используя библиотеку Python, созданную Плехачем. Библиотека была опубликована в начале 2021 года, об этом писал Системный Блокъ. Библиотека поддерживает больше языков, чем инструмент, описанный в статье 2018 года. Были добавлены русский, немецкий, испанский и нидерландский.
Перейдем к примерам. Сможет ли RhymeTagger распознать рифмы в стихотворении Маяковского? Или ему помешает «Лесенка» — знаменитый способ записи стихов, которым пользовался поэт?
А вы могли бы?
Я сразу смазал карту будня,
плеснувши краску из стакана;
я показал на блюде студня
косые скулы океана.
На чешуе жестяной рыбы
прочел я зовы новых губ.
А вы
ноктюрн сыграть
могли бы
на флейте водосточных труб?
Согласно В. Н. Дядичеву [2], с формальной точки зрения это произведение состоит из двух четверостиший, хотя графическое деление на строфы и отсутствует. При этом третья строка второго четверостишия разделена на 3 части.
Программа верно определила рифмы в первых четырех строках — вывела схему, соответствующую перекрестной рифмовке. Однако во втором четверостишии деление третьей строки сбило алгоритм с толку. Настоящий тип рифмовки здесь также перекрестный; рифмуются строки, оканчивающиеся словами: «рыбы» — «могли бы», «губ» — «труб». Однако программа неправильно распознала один из наборов рифм: отметила, что строчка «А вы» входит в группу строк с рифмой «рыбы» — «могли бы».
Тем не менее, в целом, RhymeTagger показал хороший результат: он смог узнать неточную рифму («рыбы» — «могли бы»).
Второе стихотворение, на материале которого мы протестировали RhymeTagger, — это 117-й сонет Шекспира («Accuse Me Thus: That I Have Scanted All»). На его примере можно проверить, работает ли распознавание рифм в словах, произношение которых изменилось со времени написания произведения (эти слова — «winds» и «love»).
Алгоритму удалось правильно определить схему рифмовки сонета: три четверостишия с перекрестной рифмой и две заключительных строки, рифмующиеся между собой. Это классическая форма шекспировского сонета [3].
Таким образом, высокую точность RhymeTagger легко можно увидеть на практике.
Вы можете воспроизвести наш эксперимент и воспользоваться программой здесь. Для этого нужно иметь Google аккаунт.
Автор алгоритма
RhymeTagger — одно из многих достижений чешского ученого Петра Плехача. Он — очень известный в мировом сообществе цифровой стиховед (ученый, который разрабатывает и применяет цифровые методы в исследованиях поэзии). Плехач участвовал в создании Корпуса чешского стиха и в настоящее время работает над этим проектом. Также филолог занимается стилометрией, в том числе развивает идеи использования стихотворных признаков для определения авторства. Недавно Плехач выпустил про это целую книгу.
Среди стилометрических исследований Плехача — известная работа о «Генрихе VIII». С помощью машинного обучения ученый определил, какие строки в пьесе не принадлежат Шекспиру [4] [5].
В другой научной работе команда ученых, используя машинное обучение, раскрывает мистификацию — доказывает, что стихи поэта-декабриста Батенькова, обнаруженные в XX веке, являются подделкой.
Источники
Plecháč P. (2018) A Collocation-Driven Method of Discovering Rhymes (in Czech, English, and French Poetry). In: Fidler M., Cvrček V. (eds) Taming the Corpus. Quantitative Methods in the Humanities and Social Sciences. Springer, Cham.
[1] Слогообразующий звук — это звук, способный образовать слог. В русском языке такими звуками являются гласные. В чешском, например, слогообразующими являются также и сонорные («vlk» — «волк» на чешском).
[2] «А вы могли бы?» Википедия
[3] Сонет. Википедия
[4] Machine learning has revealed exactly how much of a Shakespeare play was written by someone else. MIT Technology Review
[5] Искусственный интеллект определил, какая часть пьесы «Генрих VIII» написана не Шекспиром. Habr.com
Необходимость в поиске рифмы возникает у многих. Часто люди составляют поздравления для близких людей или пишут стихи. Иногда это необходимо в рамках школьной программы.
Процесс составления текста с рифмами развивает креативность и творческий потенциал. Интернет открыл немало новых возможностей. Теперь рифма перестала быть проблемой. Найти её можно за считанные минуты. Поможет в этом генератор рифмы онлайн rifma.org.
Генератор рифмы помогает быстро решить задачу, вне зависимости от сложности таковой, обеспечивая при этом широкие возможности для выбора. С примером поиска рифмы и результатом ознакомит ссылка https://rifma.org/rhyme/%D1%81%D0%B5%D0%BC%D1%8C%D1%8F.
Как использовать генератор рифмы?
Алгоритм сводится к простым и доступным в понимании манипуляциям. Нужно ввести слово в строку поиска, и активировать процесс. Затем останется ознакомиться с выдачей и выбрать вариант, который наиболее подходит для контекста или конкретной задачи. Процесс займёт считанные минуты. Наиболее подходящие рифмы зачастую находятся в начале списка. При этом в середине и в конце могут быть оригинальные варианты. Программа уникальная.
Подбор рифмы происходит с отголоском на звучание слова. Можно выбрать ударение на любую букву, чтобы гарантировать максимальную созвучность. База слов сервиса просто огромная. Выдача порой удивляет многообразием вариаций. Теперь подобрать рифму для слова можно быстро, в любой момент и абсолютно бесплатно. Для этого лишь необходимо обеспечить себе доступ к сети Интернет.
Сайт удобно использовать не только с компьютера, но и с мобильных устройств. После списка рифм, могут быть показаны анаграммы, синонимы, а также прочие формы слова. Сайт также распознаёт аббревиатуры. Удачных поисков!
18+