From Proxmox VE
Jump to navigation
Jump to search
Proxmox VE is using the Linux network stack. This provides a lot of flexibility on
how to set up the network on the Proxmox VE nodes. The configuration can be done
either via the GUI, or by manually editing the file /etc/network/interfaces,
which contains the whole network configuration. The interfaces(5) manual
page contains the complete format description. All Proxmox VE tools try hard to keep
direct user modifications, but using the GUI is still preferable, because it
protects you from errors.
A vmbr interface is needed to connect guests to the underlying physical
network. They are a Linux bridge which can be thought of as a virtual switch
to which the guests and physical interfaces are connected to. This section
provides some examples on how the network can be set up to accomodate different
use cases like redundancy with a bond,
vlans or
routed and
NAT setups.
The Software Defined Network is an option for more complex
virtual networks in Proxmox VE clusters.
|
|
It’s discouraged to use the traditional Debian tools ifup and ifdown if unsure, as they have some pitfalls like interupting all guest traffic on ifdown vmbrX but not reconnecting those guest again when doing ifup on the same bridge later. |
Apply Network Changes
Proxmox VE does not write changes directly to /etc/network/interfaces. Instead, we
write into a temporary file called /etc/network/interfaces.new, this way you
can do many related changes at once. This also allows to ensure your changes
are correct before applying, as a wrong network configuration may render a node
inaccessible.
Live-Reload Network with ifupdown2
With the recommended ifupdown2 package (default for new installations since
Proxmox VE 7.0), it is possible to apply network configuration changes without a
reboot. If you change the network configuration via the GUI, you can click the
Apply Configuration button. This will move changes from the staging
interfaces.new file to /etc/network/interfaces and apply them live.
If you made manual changes directly to the /etc/network/interfaces file, you
can apply them by running ifreload -a
|
|
If you installed Proxmox VE on top of Debian, or upgraded to Proxmox VE 7.0 from an older Proxmox VE installation, make sure ifupdown2 is installed: apt install ifupdown2 |
Reboot Node to Apply
Another way to apply a new network configuration is to reboot the node.
In that case the systemd service pvenetcommit will activate the staging
interfaces.new file before the networking service will apply that
configuration.
Naming Conventions
We currently use the following naming conventions for device names:
-
Ethernet devices: en*, systemd network interface names. This naming scheme is
used for new Proxmox VE installations since version 5.0. -
Ethernet devices: eth[N], where 0 ≤ N (eth0, eth1, …) This naming
scheme is used for Proxmox VE hosts which were installed before the 5.0
release. When upgrading to 5.0, the names are kept as-is. -
Bridge names: vmbr[N], where 0 ≤ N ≤ 4094 (vmbr0 — vmbr4094)
-
Bonds: bond[N], where 0 ≤ N (bond0, bond1, …)
-
VLANs: Simply add the VLAN number to the device name,
separated by a period (eno1.50, bond1.30)
This makes it easier to debug networks problems, because the device
name implies the device type.
Systemd Network Interface Names
Systemd uses the two character prefix en for Ethernet network
devices. The next characters depends on the device driver and the fact
which schema matches first.
-
o<index>[n<phys_port_name>|d<dev_port>] — devices on board
-
s<slot>[f<function>][n<phys_port_name>|d<dev_port>] — device by hotplug id
-
[P<domain>]p<bus>s<slot>[f<function>][n<phys_port_name>|d<dev_port>] — devices by bus id
-
x<MAC> — device by MAC address
The most common patterns are:
-
eno1 — is the first on board NIC
-
enp3s0f1 — is the NIC on pcibus 3 slot 0 and use the NIC function 1.
Choosing a network configuration
Depending on your current network organization and your resources you can
choose either a bridged, routed, or masquerading networking setup.
Proxmox VE server in a private LAN, using an external gateway to reach the internet
The Bridged model makes the most sense in this case, and this is also
the default mode on new Proxmox VE installations.
Each of your Guest system will have a virtual interface attached to the
Proxmox VE bridge. This is similar in effect to having the Guest network card
directly connected to a new switch on your LAN, the Proxmox VE host playing the role
of the switch.
Proxmox VE server at hosting provider, with public IP ranges for Guests
For this setup, you can use either a Bridged or Routed model, depending on
what your provider allows.
Proxmox VE server at hosting provider, with a single public IP address
In that case the only way to get outgoing network accesses for your guest
systems is to use Masquerading. For incoming network access to your guests,
you will need to configure Port Forwarding.
For further flexibility, you can configure
VLANs (IEEE 802.1q) and network bonding, also known as «link
aggregation». That way it is possible to build complex and flexible
virtual networks.
Default Configuration using a Bridge

Bridges are like physical network switches implemented in software.
All virtual guests can share a single bridge, or you can create multiple
bridges to separate network domains. Each host can have up to 4094 bridges.
The installation program creates a single bridge named vmbr0, which
is connected to the first Ethernet card. The corresponding
configuration in /etc/network/interfaces might look like this:
auto lo
iface lo inet loopback
iface eno1 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.10.2/24
gateway 192.168.10.1
bridge-ports eno1
bridge-stp off
bridge-fd 0
Virtual machines behave as if they were directly connected to the
physical network. The network, in turn, sees each virtual machine as
having its own MAC, even though there is only one network cable
connecting all of these VMs to the network.
Routed Configuration
Most hosting providers do not support the above setup. For security
reasons, they disable networking as soon as they detect multiple MAC
addresses on a single interface.
|
|
Some providers allow you to register additional MACs through their management interface. This avoids the problem, but can be clumsy to configure because you need to register a MAC for each of your VMs. |
You can avoid the problem by “routing” all traffic via a single
interface. This makes sure that all network packets use the same MAC
address.

A common scenario is that you have a public IP (assume 198.51.100.5
for this example), and an additional IP block for your VMs
(203.0.113.16/28). We recommend the following setup for such
situations:
auto lo
iface lo inet loopback
auto eno0
iface eno0 inet static
address 198.51.100.5/29
gateway 198.51.100.1
post-up echo 1 > /proc/sys/net/ipv4/ip_forward
post-up echo 1 > /proc/sys/net/ipv4/conf/eno0/proxy_arp
auto vmbr0
iface vmbr0 inet static
address 203.0.113.17/28
bridge-ports none
bridge-stp off
bridge-fd 0
Masquerading (NAT) with iptables
Masquerading allows guests having only a private IP address to access the
network by using the host IP address for outgoing traffic. Each outgoing
packet is rewritten by iptables to appear as originating from the host,
and responses are rewritten accordingly to be routed to the original sender.
auto lo
iface lo inet loopback
auto eno1
#real IP address
iface eno1 inet static
address 198.51.100.5/24
gateway 198.51.100.1
auto vmbr0
#private sub network
iface vmbr0 inet static
address 10.10.10.1/24
bridge-ports none
bridge-stp off
bridge-fd 0
post-up echo 1 > /proc/sys/net/ipv4/ip_forward
post-up iptables -t nat -A POSTROUTING -s '10.10.10.0/24' -o eno1 -j MASQUERADE
post-down iptables -t nat -D POSTROUTING -s '10.10.10.0/24' -o eno1 -j MASQUERADE
|
|
In some masquerade setups with firewall enabled, conntrack zones might be needed for outgoing connections. Otherwise the firewall could block outgoing connections since they will prefer the POSTROUTING of the VM bridge (and not MASQUERADE). |
Adding these lines in the /etc/network/interfaces can fix this problem:
post-up iptables -t raw -I PREROUTING -i fwbr+ -j CT --zone 1 post-down iptables -t raw -D PREROUTING -i fwbr+ -j CT --zone 1
For more information about this, refer to the following links:
Linux Bond
Bonding (also called NIC teaming or Link Aggregation) is a technique
for binding multiple NIC’s to a single network device. It is possible
to achieve different goals, like make the network fault-tolerant,
increase the performance or both together.
High-speed hardware like Fibre Channel and the associated switching
hardware can be quite expensive. By doing link aggregation, two NICs
can appear as one logical interface, resulting in double speed. This
is a native Linux kernel feature that is supported by most
switches. If your nodes have multiple Ethernet ports, you can
distribute your points of failure by running network cables to
different switches and the bonded connection will failover to one
cable or the other in case of network trouble.
Aggregated links can improve live-migration delays and improve the
speed of replication of data between Proxmox VE Cluster nodes.
There are 7 modes for bonding:
-
Round-robin (balance-rr): Transmit network packets in sequential
order from the first available network interface (NIC) slave through
the last. This mode provides load balancing and fault tolerance. -
Active-backup (active-backup): Only one NIC slave in the bond is
active. A different slave becomes active if, and only if, the active
slave fails. The single logical bonded interface’s MAC address is
externally visible on only one NIC (port) to avoid distortion in the
network switch. This mode provides fault tolerance. -
XOR (balance-xor): Transmit network packets based on [(source MAC
address XOR’d with destination MAC address) modulo NIC slave
count]. This selects the same NIC slave for each destination MAC
address. This mode provides load balancing and fault tolerance. -
Broadcast (broadcast): Transmit network packets on all slave
network interfaces. This mode provides fault tolerance. -
IEEE 802.3ad Dynamic link aggregation (802.3ad)(LACP): Creates
aggregation groups that share the same speed and duplex
settings. Utilizes all slave network interfaces in the active
aggregator group according to the 802.3ad specification. -
Adaptive transmit load balancing (balance-tlb): Linux bonding
driver mode that does not require any special network-switch
support. The outgoing network packet traffic is distributed according
to the current load (computed relative to the speed) on each network
interface slave. Incoming traffic is received by one currently
designated slave network interface. If this receiving slave fails,
another slave takes over the MAC address of the failed receiving
slave. -
Adaptive load balancing (balance-alb): Includes balance-tlb plus receive
load balancing (rlb) for IPV4 traffic, and does not require any
special network switch support. The receive load balancing is achieved
by ARP negotiation. The bonding driver intercepts the ARP Replies sent
by the local system on their way out and overwrites the source
hardware address with the unique hardware address of one of the NIC
slaves in the single logical bonded interface such that different
network-peers use different MAC addresses for their network packet
traffic.
If your switch support the LACP (IEEE 802.3ad) protocol then we recommend using
the corresponding bonding mode (802.3ad). Otherwise you should generally use the
active-backup mode.
If you intend to run your cluster network on the bonding interfaces, then you
have to use active-passive mode on the bonding interfaces, other modes are
unsupported.
The following bond configuration can be used as distributed/shared
storage network. The benefit would be that you get more speed and the
network will be fault-tolerant.
Example: Use bond with fixed IP address
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manual
iface eno3 inet manual
auto bond0
iface bond0 inet static
bond-slaves eno1 eno2
address 192.168.1.2/24
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer2+3
auto vmbr0
iface vmbr0 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports eno3
bridge-stp off
bridge-fd 0

Another possibility it to use the bond directly as bridge port.
This can be used to make the guest network fault-tolerant.
Example: Use a bond as bridge port
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manual
auto bond0
iface bond0 inet manual
bond-slaves eno1 eno2
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer2+3
auto vmbr0
iface vmbr0 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports bond0
bridge-stp off
bridge-fd 0
VLAN 802.1Q
A virtual LAN (VLAN) is a broadcast domain that is partitioned and
isolated in the network at layer two. So it is possible to have
multiple networks (4096) in a physical network, each independent of
the other ones.
Each VLAN network is identified by a number often called tag.
Network packages are then tagged to identify which virtual network
they belong to.
VLAN for Guest Networks
Proxmox VE supports this setup out of the box. You can specify the VLAN tag
when you create a VM. The VLAN tag is part of the guest network
configuration. The networking layer supports different modes to
implement VLANs, depending on the bridge configuration:
-
VLAN awareness on the Linux bridge:
In this case, each guest’s virtual network card is assigned to a VLAN tag,
which is transparently supported by the Linux bridge.
Trunk mode is also possible, but that makes configuration
in the guest necessary. -
«traditional» VLAN on the Linux bridge:
In contrast to the VLAN awareness method, this method is not transparent
and creates a VLAN device with associated bridge for each VLAN.
That is, creating a guest on VLAN 5 for example, would create two
interfaces eno1.5 and vmbr0v5, which would remain until a reboot occurs. -
Open vSwitch VLAN:
This mode uses the OVS VLAN feature. -
Guest configured VLAN:
VLANs are assigned inside the guest. In this case, the setup is
completely done inside the guest and can not be influenced from the
outside. The benefit is that you can use more than one VLAN on a
single virtual NIC.
VLAN on the Host
To allow host communication with an isolated network. It is possible
to apply VLAN tags to any network device (NIC, Bond, Bridge). In
general, you should configure the VLAN on the interface with the least
abstraction layers between itself and the physical NIC.
For example, in a default configuration where you want to place
the host management address on a separate VLAN.
Example: Use VLAN 5 for the Proxmox VE management IP with traditional Linux bridge
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno1.5 inet manual
auto vmbr0v5
iface vmbr0v5 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports eno1.5
bridge-stp off
bridge-fd 0
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
Example: Use VLAN 5 for the Proxmox VE management IP with VLAN aware Linux bridge
auto lo
iface lo inet loopback
iface eno1 inet manual
auto vmbr0.5
iface vmbr0.5 inet static
address 10.10.10.2/24
gateway 10.10.10.1
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
The next example is the same setup but a bond is used to
make this network fail-safe.
Example: Use VLAN 5 with bond0 for the Proxmox VE management IP with traditional Linux bridge
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manual
auto bond0
iface bond0 inet manual
bond-slaves eno1 eno2
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer2+3
iface bond0.5 inet manual
auto vmbr0v5
iface vmbr0v5 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports bond0.5
bridge-stp off
bridge-fd 0
auto vmbr0
iface vmbr0 inet manual
bridge-ports bond0
bridge-stp off
bridge-fd 0
Disabling IPv6 on the Node
Proxmox VE works correctly in all environments, irrespective of whether IPv6 is
deployed or not. We recommend leaving all settings at the provided defaults.
Should you still need to disable support for IPv6 on your node, do so by
creating an appropriate sysctl.conf (5) snippet file and setting the proper
sysctls,
for example adding /etc/sysctl.d/disable-ipv6.conf with content:
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1
This method is preferred to disabling the loading of the IPv6 module on the
kernel commandline.
Disabling MAC Learning on a Bridge
By default, MAC learning is enabled on a bridge to ensure a smooth experience
with virtual guests and their networks.
But in some environments this can be undesired. Since Proxmox VE 7.3 you can disable
MAC learning on the bridge by setting the ‘bridge-disable-mac-learning 1`
configuration on a bridge in `/etc/network/interfaces’, for example:
# ...
auto vmbr0
iface vmbr0 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports ens18
bridge-stp off
bridge-fd 0
bridge-disable-mac-learning 1
Once enabled, Proxmox VE will manually add the configured MAC address from VMs and
Containers to the bridges forwarding database to ensure that guest can still
use the network — but only when they are using their actual MAC address.
 Настройка сетевой конфигурации системы виртуализации — одна из самых главных задач, она же вызывает наибольшие затруднения у начинающих. Поэтому начиная цикл статей о Proxmox мы сразу решили подробно разобрать этот вопрос. Тем более, что официальная документация довольно скупо освещает эту тему и может сложиться впечатление, что Proxmox ограничен в сетевых возможностях по сравнению с другими гипервизорами. Однако это не так, скорее даже наоборот, потому что перед нами открытое ПО и мы можем конфигурировать его именно так, как считаем нужным, даже если этих возможностей не было из коробки.
Настройка сетевой конфигурации системы виртуализации — одна из самых главных задач, она же вызывает наибольшие затруднения у начинающих. Поэтому начиная цикл статей о Proxmox мы сразу решили подробно разобрать этот вопрос. Тем более, что официальная документация довольно скупо освещает эту тему и может сложиться впечатление, что Proxmox ограничен в сетевых возможностях по сравнению с другими гипервизорами. Однако это не так, скорее даже наоборот, потому что перед нами открытое ПО и мы можем конфигурировать его именно так, как считаем нужным, даже если этих возможностей не было из коробки.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Если обратиться к официальной документации, то там будет рассказано о двух основных сетевых конфигурациях: с использованием моста и маршрутизации. Приведенные примеры покрывают основные сценарии использования и не углубляются в подробности, но различные комбинации настроек для этих вариантов позволяют реализовывать самые разнообразные сетевые конфигурации. В данном материале мы рассмотрим базовые возможности Proxmox, не касаясь объединения сетевых адаптеров или использования Open vSwitch, потому как это отдельные темы, лежащие за рамками базовой настройки.
Все сетевые параметры настраиваются на уровне ноды, для этого перейдите на нужный сервер и раскройте Система — Сеть. Ниже показан пример нашего тестового сервера, где реализованы все те сетевые конфигурации, о которых мы будем говорить ниже.
 Внешняя сеть
Внешняя сеть
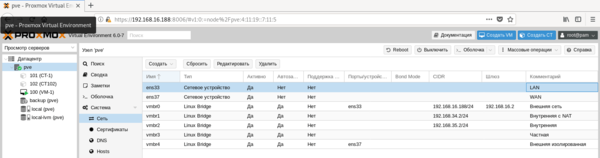 Внешняя сеть
Внешняя сетьСетевая конфигурация, создаваемая по умолчанию, когда и виртуальные машины, и гипервизор получают прозрачный доступ к вешней сети, подключенной через физический сетевой адаптер. Она же самая часто используемая, так как позволяет организовать простой доступ к виртуальным машинам, как к самым обычным узлам локальной сети.
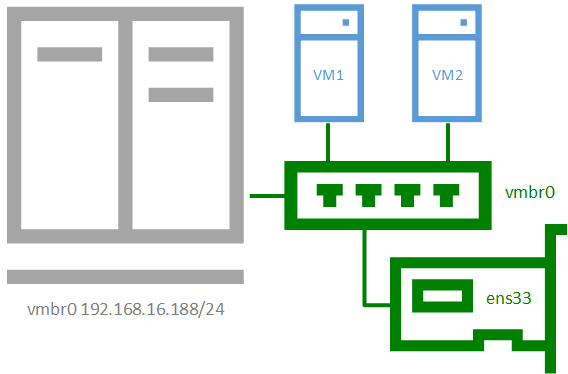 В основе всех виртуальных сетей в Proxmoх лежит сетевой мост (Linux Bridge) — vmbr, допускается создание до 4095 таких устройств. Сетевой мост может включать в себя как физические, так и виртуальные адаптеры, выполняя для них роль неуправляемого коммутатора. Физическая сетевая карта, подключенная к мосту, не имеет настроек и используется как физический Ehternet-интерфейс для данного виртуального коммутатора. Все сетевые настройки производятся внутри виртуальных машин, которые через мост и физический адаптер прозрачно попадают во внешнюю сеть.
В основе всех виртуальных сетей в Proxmoх лежит сетевой мост (Linux Bridge) — vmbr, допускается создание до 4095 таких устройств. Сетевой мост может включать в себя как физические, так и виртуальные адаптеры, выполняя для них роль неуправляемого коммутатора. Физическая сетевая карта, подключенная к мосту, не имеет настроек и используется как физический Ehternet-интерфейс для данного виртуального коммутатора. Все сетевые настройки производятся внутри виртуальных машин, которые через мост и физический адаптер прозрачно попадают во внешнюю сеть.
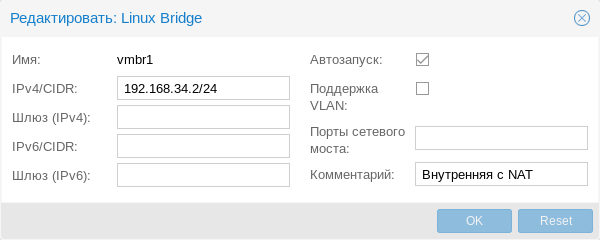
Присвоение интерфейсу моста IP-адреса фактически подключает к виртуальному коммутатору сам хост, т.е. гипервизор, который также прозрачно попадет во внешнюю сеть. Если в Hyper-V для подключения гипервизора к сети на хосте создавался еще один виртуальный сетевой адаптер, то в Proxmox для этого следует назначить IP-адрес интерфейсу моста. Ниже показан пример такой настройки:
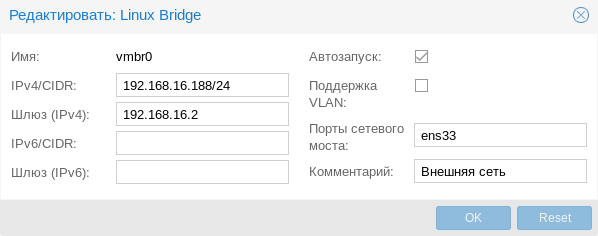 В настройках указывается адрес и шлюз, опция автозапуска и привязанный к мосту физический адаптер. Также мы советуем в поле комментарий оставлять осмысленное описание сетевого устройства, чтобы всегда было понятно, что это и зачем.
В настройках указывается адрес и шлюз, опция автозапуска и привязанный к мосту физический адаптер. Также мы советуем в поле комментарий оставлять осмысленное описание сетевого устройства, чтобы всегда было понятно, что это и зачем.
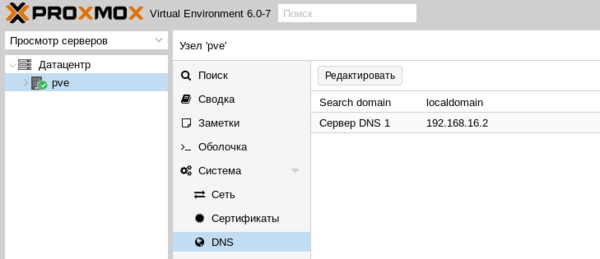
Фактически это сетевые настройки самого гипервизора. Обратите внимание, что сервера DNS указываются отдельно, в Система — DNS:
 Для того, чтобы подключить к такой сети виртуальную машину в настройках ее сетевого адаптера следует выбрать нужный мост (виртуальный коммутатор):
Для того, чтобы подключить к такой сети виртуальную машину в настройках ее сетевого адаптера следует выбрать нужный мост (виртуальный коммутатор):
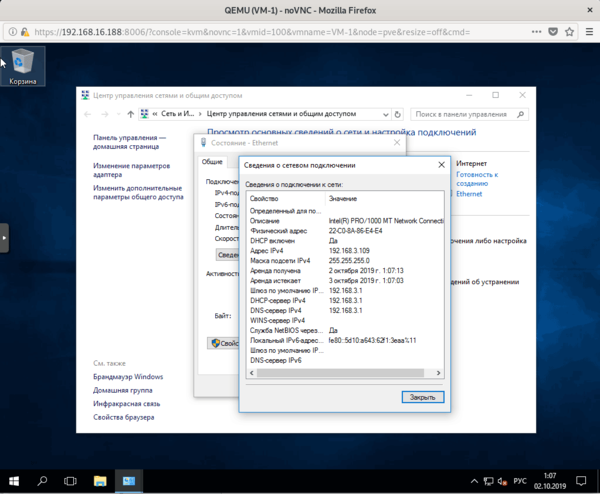
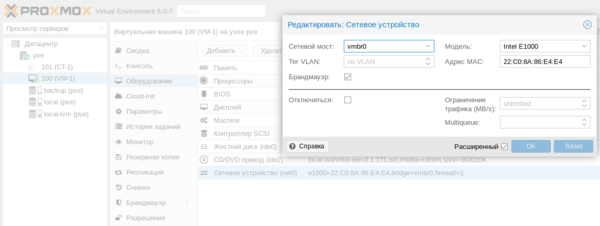 Сетевые настройки виртуальной машины либо задаются вручную, либо могут быть получены от DHCP-сервера внешней сети.
Сетевые настройки виртуальной машины либо задаются вручную, либо могут быть получены от DHCP-сервера внешней сети.
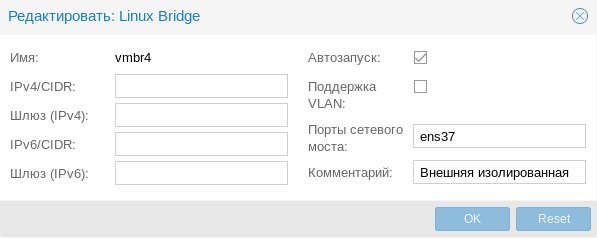
Внешняя изолированная сеть
Данная конфигурация требует минимум двух сетевых адаптеров и предусматривает изоляцию гипервизора от внешней сети и виртуальных машин. Это может быть полезно при виртуализации пограничных устройства, например, шлюза. Либо когда виртуальные машины арендуются третьими лицами, либо находятся вне доверенной сети и доступ к гипервизору оттуда должен быть закрыт.
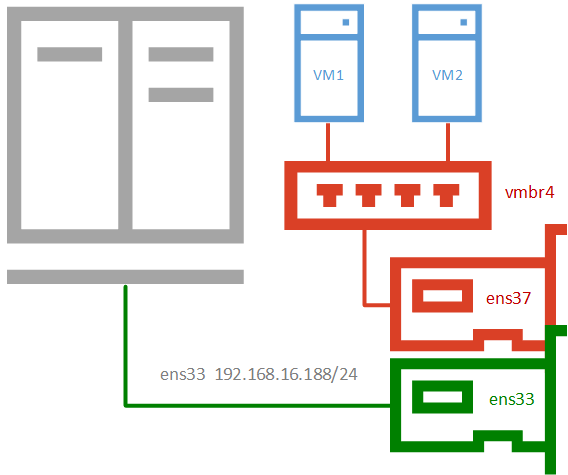 Для создания изолированной внешней сети нам потребуется создать новый сетевой мост без сетевых настроек и привязать к нему физический адаптер (тоже без настроек), таким образом будет обеспечен доступ виртуальных машин во внешнюю сеть с изоляцией этой сети от гипервизора.
Для создания изолированной внешней сети нам потребуется создать новый сетевой мост без сетевых настроек и привязать к нему физический адаптер (тоже без настроек), таким образом будет обеспечен доступ виртуальных машин во внешнюю сеть с изоляцией этой сети от гипервизора.
 Для доступа к самому гипервизору может быть использован либо другой сетевой адаптер (как показано на нашей схеме), так и созданная по умолчанию внешняя сеть с сетевым мостом. Оба варианта имеют право на жизнь, а во втором случае вы сможете также подключать виртуальные машины к разным виртуальным сетям. Поэтому не следует рассматривать приведенную нами схему как догму, это только один из возможных вариантов и выбран нами в целях упрощения схемы.
Для доступа к самому гипервизору может быть использован либо другой сетевой адаптер (как показано на нашей схеме), так и созданная по умолчанию внешняя сеть с сетевым мостом. Оба варианта имеют право на жизнь, а во втором случае вы сможете также подключать виртуальные машины к разным виртуальным сетям. Поэтому не следует рассматривать приведенную нами схему как догму, это только один из возможных вариантов и выбран нами в целях упрощения схемы.
Для примера мы подключили к такой сети виртуальную машину, которая тут же получила по DHCP адрес из внешней сети, никак не связанной с гипервизором.
 Внутренняя сеть с NAT
Внутренняя сеть с NAT
 Внутренняя сеть с NAT
Внутренняя сеть с NATПрименяется в тех случаях, когда нужно изолировать виртуальные машины в собственной сети, но в тоже время обеспечить им доступ в интернет, а также доступ из внешней сети к некоторым из них (или отдельным сетевым службам). Широко используется в лабораторных сценариях, а также при работе с контейнерами.
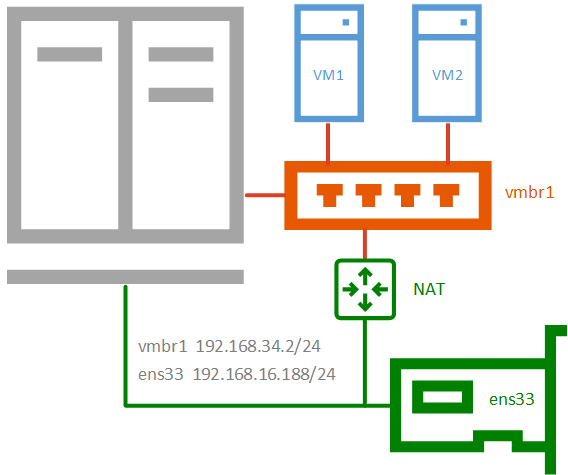 Обратите внимание, данная конфигурация не может быть изолирована от хоста, так как именно хост предоставляет ей службу трансляции сетевых адресов (NAT) и выступает шлюзом для виртуальных машин. Для настройки такой сети создайте новый сетевой мост без привязки к физическому адаптеру и назначьте ему IP-адрес из произвольной сети, отличной от внешней.
Обратите внимание, данная конфигурация не может быть изолирована от хоста, так как именно хост предоставляет ей службу трансляции сетевых адресов (NAT) и выступает шлюзом для виртуальных машин. Для настройки такой сети создайте новый сетевой мост без привязки к физическому адаптеру и назначьте ему IP-адрес из произвольной сети, отличной от внешней.
 Все изменения сетевой конфигурации требуют перезагрузки узла гипервизора, поэтому, чтобы не перезагружать узел дважды перейдем в консоль сервера и перейдем в директорию /etc/network, в котором будут присутствовать файлы interfaces — с текущей сетевой конфигурацией и interfaces.new — с новой, которая вступит в силу после перезагрузки.
Все изменения сетевой конфигурации требуют перезагрузки узла гипервизора, поэтому, чтобы не перезагружать узел дважды перейдем в консоль сервера и перейдем в директорию /etc/network, в котором будут присутствовать файлы interfaces — с текущей сетевой конфигурацией и interfaces.new — с новой, которая вступит в силу после перезагрузки.
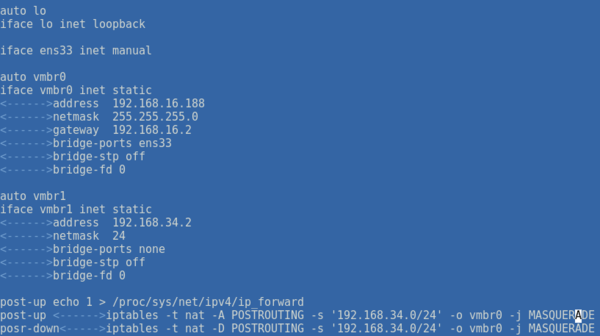
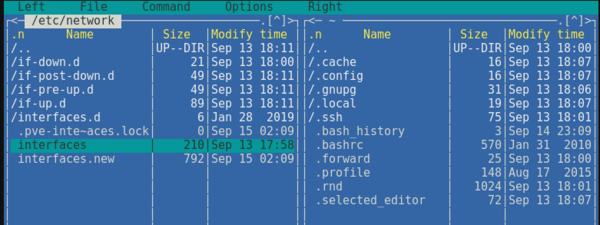 Откроем именно interfaces.new и внесем в конец следующие строки:
Откроем именно interfaces.new и внесем в конец следующие строки:
post-up echo 1 > /proc/sys/net/ipv4/ip_forward
post-up iptables -t nat -A POSTROUTING -s '192.168.34.0/24' -o ens33 -j MASQUERADE
post-down iptables -t nat -D POSTROUTING -s '192.168.34.0/24' -o ens33 -j MASQUERADEВ качестве сети, в нашем случае 192.168.34.0/24, укажите выбранную вами сеть, а вместо интерфейса ens33 укажите тот сетевой интерфейс, который смотрит во внешнюю сеть с доступом в интернет. Если вы используете сетевую конфигурацию по умолчанию, то это будет не физический адаптер, а первый созданный мост vmbr0, как на скриншоте ниже:
 Перезагрузим узел и назначим виртуальной машине или контейнеру созданную сеть (vmbr1), также выдадим ей адрес из этой сети, а шлюзом укажем адрес моста.
Перезагрузим узел и назначим виртуальной машине или контейнеру созданную сеть (vmbr1), также выдадим ей адрес из этой сети, а шлюзом укажем адрес моста.
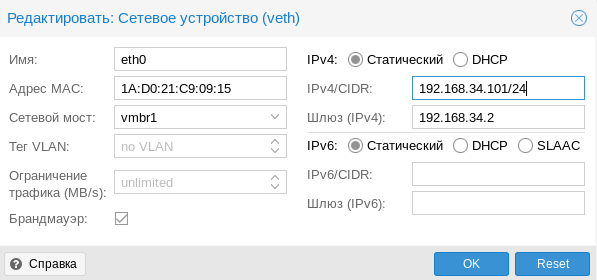
Не забудьте указать доступный адрес DNS-сервера и убедитесь, что виртуальная машина имеет выход в интернет через NAT.
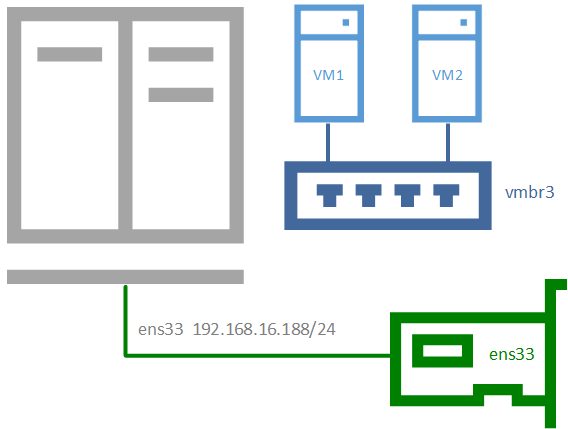
Внутренняя сеть
Позволяет изолировать виртуальные машины от внешней сети и не предоставляет им доступ в интернет, используется в основном в лабораторных целях, когда в качестве шлюза будет выступать одна из виртуальных машин и обычно сочетается на хосте с одной из сетей, имеющих выход в интернет.
Чтобы получить такую сеть, просто создайте еще один мост без привязки к адаптеру и назначьте ему IP-адрес из любой отличной от используемых сети.
 Частная сеть
Частная сеть
 Частная сеть
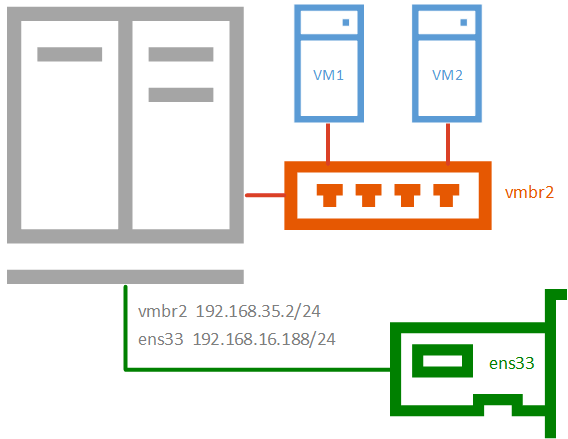
Частная сетьРазновидность внутренней сети, которая подразумевает изоляцию не только от внешней сети, но и от хоста. Что позволяет получить полностью независимую сеть между виртуальными машинами, может быть полезна в лабораторных условиях, когда нужно смоделировать сеть, адресация которой пересекается с используемыми вами сетями.
 Для такой сети просто создайте еще один сетевой мост без каких-либо настроек:
Для такой сети просто создайте еще один сетевой мост без каких-либо настроек:
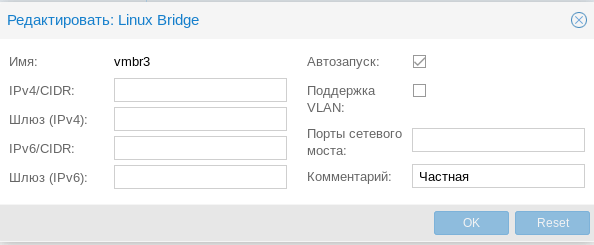 Подобные сети также обычно используются не самостоятельно, а в сочетании с иными типами сетей на хосте.
Подобные сети также обычно используются не самостоятельно, а в сочетании с иными типами сетей на хосте.
Организуем службы DNS и DHCP для внутренних сетей
Как вы уже могли заметить все адреса для виртуальных машин во внутренних сетях мы назначали вручную. Но можно это делать автоматически, сняв с себя еще одну заботу, это удобно, особенно в лабораторных и тестовых средах, где виртуальных машин много и назначать им адреса вручную может быть достаточно затруднительно.
В нашем примере мы организуем службы DNS и DHCP для внутренней сети с NAT и просто внутренней сети. Для первой мы должны будет выдавать адрес, шлюз и сервера DNS, для второй просто адрес. Данная конфигурация не является реальной, а создана нами исключительно в учебных целях.
В качестве серверов DNS и DHCP мы будем использовать уже известный нашим читателям пакет dnsmasq, который является простым и легким кеширующим DNS и DHCP-сервером. Установим его:
apt install dnsmasqЗатем перейдем в конфигурационный файл /etc/dnsmasq.conf и найдем и приведем к следующему виду параметры:
interface= vmbrl, vmbr2
listen-address= 127.0.0.1, 192.168.34.2, 192.168.35.2Здесь мы явно указали интерфейсы и адреса, на которых будет работать наш сервер. С одной стороны, присутствует некоторая избыточность, но лучше так, чем потом, при изменении сетевых настроек в вашей сети неожиданно появится неавторизованный DHCP-сервер.
Затем укажем выдаваемые клиентам диапазоны адресов:
dhcp-range=interface:vmbr1,192.168.34.101,192.168.34.199,255.255.255.0,12h
dhcp-range=interface:vmbr2,192.168.35.101,192.168.35.199,255.255.255.0,12hОбратите внимание на формат записи, перед каждой настройкой мы указываем сетевой интерфейс к которой она применяется.
Аналогичным образом зададим нужные DHCP-опции, в нашем случае это Option 3 и 6 (шлюз и DNS-сервер).
dhcp-option=interface:vmbr1,3,192.168.34.2
dhcp-option=interface:vmbr1,6,192.168.34.2
dhcp-option=interface:vmbr2,3
dhcp-option=interface:vmbr2,6Если настройки для моста vmbr1 не вызывают вопросов, то настройки для второй сети следует пояснить. Так как нам нужно передавать ей только IP-адрес и маску, без шлюза и серверов имен, то соответствующие опции следует передать пустыми, иначе будут переданы опции по умолчанию, где в качестве этих узлов будет передан адрес сервера.
Сохраняем конфигурационный файл и перезапускаем службу
service dnsmasq restartПосле чего в виртуальных машинах, подключенных к внутренним сетям, мы можем установить настройки для получения адреса через DHCP и убедиться, что все работает как надо.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Время на прочтение
13 мин
Количество просмотров 111K
За последние несколько лет я очень тесно работаю с кластерами Proxmox: многим клиентам требуется своя собственная инфраструктура, где они могут развивать свой проект. Именно поэтому я могу рассказать про самые распространенные ошибки и проблемы, с которыми также можете столкнуться и вы. Помимо этого мы конечно же настроим кластер из трех нод с нуля.

Proxmox кластер может состоять из двух и более серверов. Максимальное количество нод в кластере равняется 32 штукам. Наш собственный кластер будет состоять из трех нод на мультикасте (в статье я также опишу, как поднять кластер на уникасте — это важно, если вы базируете свою кластерную инфраструктуру на Hetzner или OVH, например). Коротко говоря, мультикаст позволяет осуществлять передачу данных одновременно на несколько нод. При мультикасте мы можем не задумываться о количестве нод в кластере (ориентируясь на ограничения выше).
Сам кластер строится на внутренней сети (важно, чтобы IP адреса были в одной подсети), у тех же Hetzner и OVH есть возможность объединять в кластер ноды в разных датацентрах с помощью технологии Virtual Switch (Hetzner) и vRack (OVH) — о Virtual Switch мы также поговорим в статье. Если ваш хостинг-провайдер не имеет похожие технологии в работе, то вы можете использовать OVS (Open Virtual Switch), которая нативно поддерживается Proxmox, или использовать VPN. Однако, я рекомендую в данном случае использовать именно юникаст с небольшим количеством нод — часто возникают ситуации, где кластер просто “разваливается” на основе такой сетевой инфраструктуры и его приходится восстанавливать. Поэтому я стараюсь использовать именно OVH и Hetzner в работе — подобных инцидентов наблюдал в меньшем количестве, но в первую очередь изучайте хостинг-провайдера, у которого будете размещаться: есть ли у него альтернативная технология, какие решения он предлагает, поддерживает ли мультикаст и так далее.
Установка Proxmox
Proxmox может быть установлен двумя способами: ISO-инсталлятор и установка через shell. Мы выбираем второй способ, поэтому установите Debian на сервер.
Перейдем непосредственно к установке Proxmox на каждый сервер. Установка предельно простая и описана в официальной документации здесь.
Добавим репозиторий Proxmox и ключ этого репозитория:
echo "deb http://download.proxmox.com/debian/pve stretch pve-no-subscription" > /etc/apt/sources.list.d/pve-install-repo.list
wget http://download.proxmox.com/debian/proxmox-ve-release-5.x.gpg -O /etc/apt/trusted.gpg.d/proxmox-ve-release-5.x.gpg
chmod +r /etc/apt/trusted.gpg.d/proxmox-ve-release-5.x.gpg # optional, if you have a changed default umaskОбновляем репозитории и саму систему:
apt update && apt dist-upgradeПосле успешного обновления установим необходимые пакеты Proxmox:
apt install proxmox-ve postfix open-iscsiЗаметка: во время установки будет настраиваться Postfix и grub — одна из них может завершиться с ошибкой. Возможно, это будет вызвано тем, что хостнейм не резолвится по имени. Отредактируйте hosts записи и выполните apt-get update
С этого момента мы можем авторизоваться в веб-интерфейс Proxmox по адресу https://<внешний-ip-адрес>:8006 (столкнетесь с недоверенным сертификатом во время подключения).

Изображение 1. Веб-интерфейс ноды Proxmox
Установка Nginx и Let’s Encrypt сертификата
Мне не очень нравится ситуация с сертификатом и IP адресом, поэтому я предлагаю установить Nginx и настроить Let’s Encrypt сертификат. Установку Nginx описывать не буду, оставлю лишь важные файлы для работы Let’s encrypt сертификата:
/etc/nginx/snippets/letsencrypt.conf
location ^~ /.well-known/acme-challenge/ {
allow all;
root /var/lib/letsencrypt/;
default_type "text/plain";
try_files $uri =404;
}
Команда для выпуска SSL сертификата:
certbot certonly --agree-tos --email sos@livelinux.info --webroot -w /var/lib/letsencrypt/ -d proxmox1.domain.name
Конфигурация сайта в NGINX
upstream proxmox1.domain.name {
server 127.0.0.1:8006;
}
server {
listen 80;
server_name proxmox1.domain.name;
include snippets/letsencrypt.conf;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name proxmox1.domain.name;
access_log /var/log/nginx/proxmox1.domain.name.access.log;
error_log /var/log/nginx/proxmox1.domain.name.error.log;
include snippets/letsencrypt.conf;
ssl_certificate /etc/letsencrypt/live/proxmox1.domain.name/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/proxmox1.domain.name/privkey.pem;
location / {
proxy_pass https://proxmox1.domain.name;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_redirect off;
proxy_buffering off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
Не забываем после установки SSL сертификата поставить его на автообновление через cron:
0 */12 * * * /usr/bin/certbot -a ! -d /run/systemd/system && perl -e 'sleep int(rand(3600))' && certbot -q renew --renew-hook "systemctl reload nginx"Отлично! Теперь мы можем обращаться к нашему домену по HTTPS.
Заметка: чтобы отключить информационное окно о подписке, выполните данную команду:
sed -i.bak "s/data.status !== 'Active'/false/g" /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js && systemctl restart pveproxy.serviceСетевые настройки
Перед подключением в кластер настроим сетевые интерфейсы на гипервизоре. Стоит отметить, что настройка остальных нод ничем не отличается, кроме IP адресов и названия серверов, поэтому дублировать их настройку я не буду.
Создадим сетевой мост для внутренней сети, чтобы наши виртуальные машины (в моем варианте будет LXC контейнер для удобства) во-первых, были подключены к внутренней сети гипервизора и могли взаимодействовать друг с другом. Во-вторых, чуть позже мы добавим мост для внешней сети, чтобы виртуальные машины имели свой внешний IP адрес. Соответственно, контейнеры будут на данный момент за NAT’ом у нас.
Работать с сетевой конфигурацией Proxmox можно двумя способами: через веб-интерфейс или через конфигурационный файл /etc/network/interfaces. В первом варианте вам потребуется перезагрузка сервера (или можно просто переименовать файл interfaces.new в interfaces и сделать перезапуск networking сервиса через systemd). Если вы только начинаете настройку и еще нет виртуальных машин или LXC контейнеров, то желательно перезапускать гипервизор после изменений.
Теперь создадим сетевой мост под названием vmbr1 во вкладке network в веб-панели Proxmox.

Изображение 2. Сетевые интерфейсы ноды proxmox1

Изображение 3. Создание сетевого моста

Изображение 4. Настройка сетевой конфигурации vmbr1
Настройка предельно простая — vmbr1 нам нужен для того, чтобы инстансы получали доступ в Интернет.
Теперь перезапускаем наш гипервизор и проверяем, создался ли интерфейс:

Изображение 5. Сетевой интерфейс vmbr1 в выводе команды ip a
Заметьте: у меня уже есть интерфейс ens19 — это интерфейс с внутренней сетью, на основе ее будет создан кластер.
Повторите данные этапы на остальных двух гипервизорах, после чего приступите к следующему шагу — подготовке кластера.
Также важный этап сейчас заключается во включении форвардинга пакетов — без нее инстансы не будут получать доступ к внешней сети. Открываем файл sysctl.conf и изменяем значение параметра net.ipv4.ip_forward на 1, после чего вводим следующую команду:
sysctl -pВ выводе вы должны увидеть директиву net.ipv4.ip_forward (если не меняли ее до этого)
Настройка Proxmox кластера
Теперь перейдем непосредственно к кластеру. Каждая нода должна резолвить себя и другие ноды по внутренней сети, для этого требуется изменить значения в hosts записях следующих образом (на каждой ноде должна быть запись о других):
172.30.0.15 proxmox1.livelinux.info proxmox1
172.30.0.16 proxmox2.livelinux.info proxmox2
172.30.0.17 proxmox3.livelinux.info proxmox3
Также требуется добавить публичные ключи каждой ноды к остальным — это требуется для создания кластера.
Создадим кластер через веб-панель:

Изображение 6. Создание кластера через веб-интерфейс
После создания кластера нам необходимо получить информацию о нем. Переходим в ту же вкладку кластера и нажимаем кнопку “Join Information”:

Изображение 7. Информация о созданном кластере
Данная информация пригодится нам во время присоединения второй и третьей ноды в кластер. Подключаемся к второй ноде и во вкладке Cluster нажимаем кнопку “Join Cluster”:

Изображение 8. Подключение к кластеру ноды
Разберем подробнее параметры для подключения:
- Peer Address: IP адрес первого сервера (к тому, к которому мы подключаемся)
- Password: пароль первого сервера
- Fingerprint: данное значение мы получаем из информации о кластере
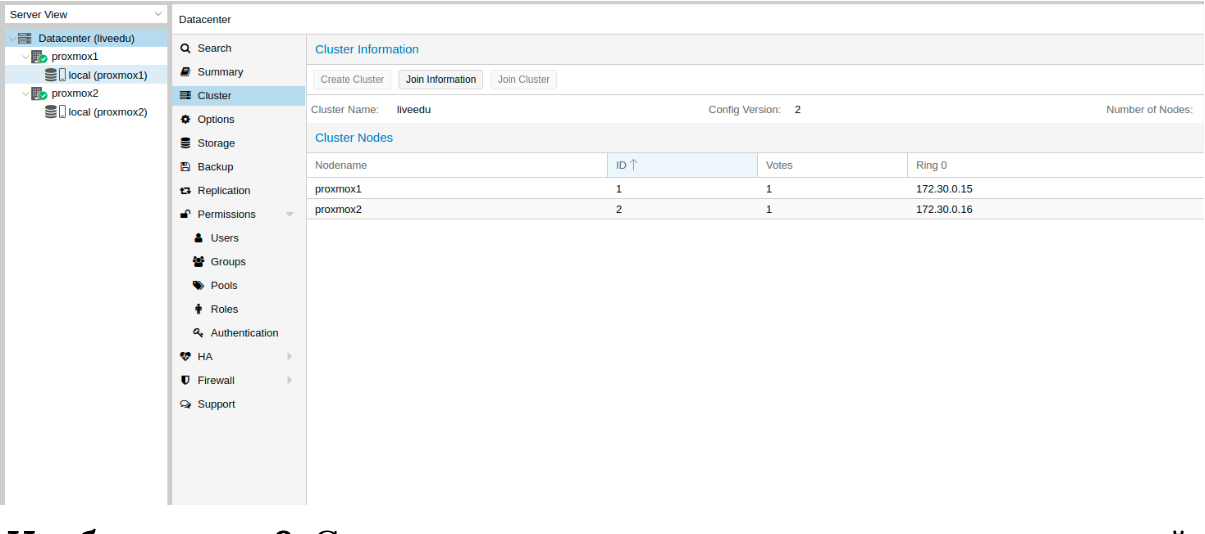
Изображение 9. Состояние кластера после подключения второй ноды
Вторая нода успешно подключена! Однако, такое бывает не всегда. Если вы неправильно выполните шаги или возникнут сетевые проблемы, то присоединение в кластер будет провалено, а сам кластер будет “развален”. Лучшее решение — это отсоединить ноду от кластера, удалить на ней всю информацию о самом кластере, после чего сделать перезапуск сервера и проверить предыдущие шаги. Как же безопасно отключить ноду из кластера? Для начала удалим ее из кластера на первом сервере:
pvecm del proxmox2После чего нода будет отсоединена от кластера. Теперь переходим на сломанную ноду и отключаем на ней следующие сервисы:
systemctl stop pvestatd.service
systemctl stop pvedaemon.service
systemctl stop pve-cluster.service
systemctl stop corosync
systemctl stop pve-cluster
Proxmox кластер хранит информацию о себе в sqlite базе, ее также необходимо очистить:
sqlite3 /var/lib/pve-cluster/config.db
delete from tree where name = 'corosync.conf';
.quit
Данные о коросинке успешно удалены. Удалим оставшиеся файлы, для этого необходимо запустить кластерную файловую систему в standalone режиме:
pmxcfs -l
rm /etc/pve/corosync.conf
rm /etc/corosync/*
rm /var/lib/corosync/*
rm -rf /etc/pve/nodes/*
Перезапускаем сервер (это необязательно, но перестрахуемся: все сервисы по итогу должны быть запущены и работать корректно. Чтобы ничего не упустить делаем перезапуск). После включения мы получим пустую ноду без какой-либо информации о предыдущем кластере и можем начать подключение вновь.
Установка и настройка ZFS
ZFS — это файловая система, которая может использоваться совместно с Proxmox. С помощью нее можно позволить себе репликацию данных на другой гипервизор, миграцию виртуальной машины/LXC контейнера, доступ к LXC контейнеру с хост-системы и так далее. Установка ее достаточно простая, приступим к разбору. На моих серверах доступно три SSD диска, которые мы объединим в RAID массив.
Добавляем репозитории:
nano /etc/apt/sources.list.d/stretch-backports.list
deb http://deb.debian.org/debian stretch-backports main contrib
deb-src http://deb.debian.org/debian stretch-backports main contrib
nano /etc/apt/preferences.d/90_zfs
Package: libnvpair1linux libuutil1linux libzfs2linux libzpool2linux spl-dkms zfs-dkms zfs-test zfsutils-linux zfsutils-linux-dev zfs-zed
Pin: release n=stretch-backports
Pin-Priority: 990
Обновляем список пакетов:
apt updateУстанавливаем требуемые зависимости:
apt install --yes dpkg-dev linux-headers-$(uname -r) linux-image-amd64Устанавливаем сам ZFS:
apt-get install zfs-dkms zfsutils-linuxЕсли вы в будущем получите ошибку fusermount: fuse device not found, try ‘modprobe fuse’ first, то выполните следующую команду:
modprobe fuseТеперь приступим непосредственно к настройке. Для начала нам требуется отформатировать SSD и настроить их через parted:
Настройка /dev/sda
parted /dev/sda
(parted) print
Model: ATA SAMSUNG MZ7LM480 (scsi)
Disk /dev/sda: 480GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 4296MB 4295MB primary raid
2 4296MB 4833MB 537MB primary raid
3 4833MB 37,0GB 32,2GB primary raid
(parted) mkpart
Partition type? primary/extended? primary
File system type? [ext2]? zfs
Start? 33GB
End? 480GB
Warning: You requested a partition from 33,0GB to 480GB (sectors 64453125..937500000).
The closest location we can manage is 37,0GB to 480GB (sectors 72353792..937703087).
Is this still acceptable to you?
Yes/No? yes
Аналогичные действия необходимо произвести и для других дисков. После того, как все диски подготовлены, приступаем к следующему шагу:
zpool create -f -o ashift=12 rpool /dev/sda4 /dev/sdb4 /dev/sdc4
Мы выбираем ashift=12 из соображений производительности — это рекомендация самого zfsonlinux, подробнее про это можно почитать в их вики: github.com/zfsonlinux/zfs/wiki/faq#performance-considerations
Применим некоторые настройки для ZFS:
zfs set atime=off rpool
zfs set compression=lz4 rpool
zfs set dedup=off rpool
zfs set snapdir=visible rpool
zfs set primarycache=all rpool
zfs set aclinherit=passthrough rpool
zfs inherit acltype rpool
zfs get -r acltype rpool
zfs get all rpool | grep compressratio
Теперь нам надо рассчитать некоторые переменные для вычисления zfs_arc_max, я это делаю следующим образом:
mem =`free --giga | grep Mem | awk '{print $2}'`
partofmem=$(($mem/10))
echo $setzfscache > /sys/module/zfs/parameters/zfs_arc_max
grep c_max /proc/spl/kstat/zfs/arcstats
zfs create rpool/data
cat > /etc/modprobe.d/zfs.conf << EOL
options zfs zfs_arc_max=$setzfscache
EOL
echo $setzfscache > /sys/module/zfs/parameters/zfs_arc_max
grep c_max /proc/spl/kstat/zfs/arcstatsВ данный момент пул успешно создан, также мы создали сабпул data. Проверить состояние вашего пула можно командой zpool status. Данное действие необходимо провести на всех гипервизорах, после чего приступить к следующему шагу.
Теперь добавим ZFS в Proxmox. Переходим в настройки датацентра (именно его, а не отдельной ноды) в раздел «Storage», кликаем на кнопку «Add» и выбираем опцию «ZFS», после чего мы увидим следующие параметры:
ID: Название стораджа. Я дал ему название local-zfs
ZFS Pool: Мы создали rpool/data, его и добавляем сюда.
Nodes: указываем все доступные ноды
Данная команда создает новый пул с выбранными нами дисками. На каждом гипервизоре должен появится новый storage под названием local-zfs, после чего вы сможете смигрировать свои виртуальные машины с локального storage на ZFS.
Репликация инстансов на соседний гипервизор
В кластере Proxmox есть возможность репликации данных с одного гипервизора на другой: данный вариант позволяет осуществлять переключение инстанса с одного сервера на другой. Данные будут актуальны на момент последней синхронизации — ее время можно выставить при создании репликации (стандартно ставится 15 минут). Существует два способа миграции инстанса на другую ноду Proxmox: ручной и автоматический. Давайте рассмотрим в первую очередь ручной вариант, а в конце я предоставлю вам Python скрипт, который позволит создавать виртуальную машину на доступном гипервизоре при недоступности одного из гипервизоров.
Для создания репликации необходимо перейти в веб-панель Proxmox и создать виртуальную машину или LXC контейнер. В предыдущих пунктах мы с вами настроили vmbr1 мост с NAT, что позволит нам выходить во внешнюю сеть. Я создам LXC контейнер с MySQL, Nginx и PHP-FPM с тестовым сайтом, чтобы проверить работу репликации. Ниже будет пошаговая инструкция.
Загружаем подходящий темплейт (переходим в storage —> Content —> Templates), пример на скриншоте:

Изображение 10. Local storage с шаблонами и образами ВМ
Нажимаем кнопку “Templates” и загружаем необходимый нам шаблон LXC контейнера:

Изображение 11. Выбор и загрузка шаблона
Теперь мы можем использовать его при создании новых LXC контейнеров. Выбираем первый гипервизор и нажимаем кнопку “Create CT” в правом верхнем углу: мы увидим панель создания нового инстанса. Этапы установки достаточно просты и я приведу лишь конфигурационный файл данного LXC контейнера:
arch: amd64
cores: 3
memory: 2048
nameserver: 8.8.8.8
net0: name=eth0,bridge=vmbr1,firewall=1,gw=172.16.0.1,hwaddr=D6:60:C5:39:98:A0,ip=172.16.0.2/24,type=veth
ostype: centos
rootfs: local:100/vm-100-disk-1.raw,size=10G
swap: 512
unprivileged:
Контейнер успешно создан. К LXC контейнерам можно подключаться через команду pct enter , я также перед установкой добавил SSH ключ гипервизора, чтобы подключаться напрямую через SSH (в PCT есть небольшие проблемы с отображением терминала). Я подготовил сервер и установил туда все необходимые серверные приложения, теперь можно перейти к созданию репликации.
Кликаем на LXC контейнер и переходим во вкладку “Replication”, где создаем параметр репликации с помощью кнопки “Add”:

Изображение 12. Создание репликации в интерфейсе Proxmox

Изображение 13. Окно создания Replication job
Я создал задачу реплицировать контейнер на вторую ноду, как видно на следующем скриншоте репликация прошла успешно — обращайте внимание на поле “Status”, она оповещает о статусе репликации, также стоит обращать внимание на поле “Duration”, чтобы знать, сколько длится репликация данных.

Изображение 14. Список синхронизаций ВМ
Теперь попробуем смигрировать машину на вторую ноду с помощью кнопки “Migrate”
Начнется миграция контейнера, лог можно просмотреть в списке задач — там будет наша миграция. После этого контейнер будет перемещен на вторую ноду.
Ошибка “Host Key Verification Failed”
Иногда при настройке кластера может возникать подобная проблема — она мешает мигрировать машины и создавать репликацию, что нивелирует преимущества кластерных решений. Для исправления этой ошибки удалите файл known_hosts и подключитесь по SSH к конфликтной ноде:
/usr/bin/ssh -o 'HostKeyAlias=proxmox2' root@172.30.0.16
Примите Hostkey и попробуйте ввести эту команду, она должна подключить вас к серверу:
/usr/bin/ssh -o 'BatchMode=yes' -o 'HostKeyAlias=proxmox2' root@172.30.0.16
Особенности сетевых настроек на Hetzner
Переходим в панель Robot и нажимаем на кнопку “Virtual Switches”. На следующей странице вы увидите панель создания и управления интерфейсов Virtual Switch: для начала его необходимо создать, а после “подключить” выделенные сервера к нему. В поиске добавляем необходимые сервера для подключения — их не не нужно перезагружать, только придется подождать до 10-15 минут, когда подключение к Virtual Switch будет активно.
После добавления серверов в Virtual Switch через веб-панель подключаемся к серверам и открываем конфигурационные файлы сетевых интерфейсов, где создаем новый сетевой интерфейс:
auto enp4s0.4000
iface enp4s0.4000 inet static
address 10.1.0.11/24
mtu 1400
vlan-raw-device enp4s0Давайте разберем подробнее, что это такое. По своей сути — это VLAN, который подключается к единственному физическому интерфейсу под названием enp4s0 (он у вас может отличаться), с указанием номера VLAN — это номер Virtual Switch’a, который вы создавали в веб-панели Hetzner Robot. Адрес можете указать любой, главное, чтобы он был локальный.
Отмечу, что конфигурировать enp4s0 следует как обычно, по сути он должен содержать внешний IP адрес, который был выдан вашему физическому серверу. Повторите данные шаги на других гипервизорах, после чего перезагрузите на них networking сервис, сделайте пинг до соседней ноды по IP адресу Virtual Switch. Если пинг прошел успешно, то вы успешно установили соединение между серверами по Virtual Switch.
Я также приложу конфигурационный файл sysctl.conf, он понадобится, если у вас будут проблемы с форвардингом пакетом и прочими сетевыми параметрами:
net.ipv6.conf.all.disable_ipv6=0
net.ipv6.conf.default.disable_ipv6 = 0
net.ipv6.conf.all.forwarding=1
net.ipv4.conf.all.rp_filter=1
net.ipv4.tcp_syncookies=1
net.ipv4.ip_forward=1
net.ipv4.conf.all.send_redirects=0
Добавление IPv4 подсети в Hetzner
Перед началом работ вам необходимо заказать подсеть в Hetzner, сделать это можно через панель Robot.
Создадим сетевой мост с адресом, который будет из этой подсети. Пример конфигурации:
auto vmbr2
iface vmbr2 inet static
address ip-address
netmask 29
bridge-ports none
bridge-stp off
bridge-fd 0Теперь переходим в настройки виртуальной машины в Proxmox и создаем новый сетевой интерфейс, который будет прикреплен к мосту vmbr2. Я использую LXC контейнер, его конфигурацию можно изменять сразу же в Proxmox. Итоговая конфигурация для Debian:
auto eth0
iface eth0 inet static
address ip-address
netmask 26
gateway bridge-addressОбратите внимание: я указал 26 маску, а не 29 — это требуется для того, чтобы сеть на виртуальной машине работала.
Добавление IPv4 адреса в Hetzner
Ситуация с одиночным IP адресом отличается — обычно Hetzner дает нам дополнительный адрес из подсети сервера. Это означает, что вместо vmbr2 нам требуется использоваться vmbr0, но на данный момент его у нас нет. Суть в том, что vmbr0 должен содержать IP адрес железного сервера (то есть использовать тот адрес, который использовал физический сетевой интерфейс enp2s0). Адрес необходимо переместить на vmbr0, для этого подойдет следующая конфигурация (советую заказать KVM, чтобы в случае чего возобновить работу сети):
auto enp2s0
iface enp2s0 inet manual
auto vmbr0
iface vmbr0 inet static
address ip-address
netmask 255.255.255.192
gateway ip-gateway
bridge-ports enp2s0
bridge-stp off
bridge-fd 0
Перезапустите сервер, если это возможно (если нет, перезапустите сервис networking), после чего проверьте сетевые интерфейсы через ip a:
2: enp2s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master vmbr0 state UP group default qlen 1000
link/ether 44:8a:5b:2c:30:c2 brd ff:ff:ff:ff:ff:ff
Как здесь видно, enp2s0 подключен к vmbr0 и не имеет IP адрес, так как он был переназначен на vmbr0.
Теперь в настройках виртуальной машины добавляем сетевой интерфейс, который будет подключен к vmbr0. В качестве gateway укажите адрес, прикрепленный к vmbr0.
В завершении
Надеюсь, что данная статья пригодится вам, когда вы будете настраивать Proxmox кластер в Hetzner. Если позволит время, то я расширю статью и добавлю инструкцию для OVH — там тоже не все очевидно, как кажется на первый взгляд. Материал получился достаточно объемным, если найдете ошибки, то, пожалуйста, напишите в комментарии, я их исправлю. Всем спасибо за уделенное внимание.
Автор: Илья Андреев, под редакцией Алексея Жадан и команды «Лайв Линукс»
В первую очередь, на сервере виртуализации необходимо настроить сетевые подключения, которые в дальнейшем будут использоваться для доступа виртуальных машин в Интернет, обмена данными друг с другом, при необходимости распределить сети по VLAN. Для этого можно использовать реализованные в ядре Linux функции или установить Open vSwitch. В панели управления Proxmox VE реализован простой и понятный интерфейс управления сетями.
Таким образом, сервер на Proxmox VE можно использовать в качестве ядра виртуальной сети. В этой статье разберемся как выполняется настройка сети Proxmox Ve. Разберем, как настроить виртуальный мост и интерфейс с балансировкой по различным алгоритмам. Proxmox VE позволяет настроить VLAN на базе ядра Linux или Open vSwitch, но это отдельная большая тема, вне рамок обзора возможностей.
- Linux Bridge — способ соединения двух сегментов Ethernet на канальном уровне, то есть без использования протоколов более высокого уровня, таких как IP. Поскольку передача выполняется на канальном уровне (уровень 2 модели OSI), все протоколы более высокого уровня прозрачно проходят через мост.
- Linux Bond — метод агрегации нескольких сетевых интерфейсов в единый логический bonded интерфейс. Таким образом, bond обеспечивает балансировку нагрузки либо горячий резерв по определённому сценарию.
- Linux VLAN – реализация на ядре Linux виртуальной локальной компьютерной сети.
- OVS Bridge – реализация моста на базе Open vSwitch.
- OVS Bond – реализация балансировки на базе Open vSwitch. Отличается от реализованной в ядре Linux балансировки режимами.
- OVS IntPort — реализация VLAN на базе Open vSwitch.
Установка OVS в Proxmox VE
После установки Proxmox VE доступны сетевые функции ядра Linux. Для того, чтобы использовать функциональность Open vSwitch, необходимо установить его в систему. В программе терминал напишите команды:
sudo apt install openvswitch-switch
После этого нужно перезагрузить компьютер.
Настройка сети в Proxmox VE
После установки всех необходимых пакетов и перезагрузки ОС в WTB-интерфейсе Proxmox VE перейдите в раздел Датацентр, выберите имя гипервизора (на скриншоте PVE). В меню Система найдите раздел Сеть и нажмите кнопку Создать:
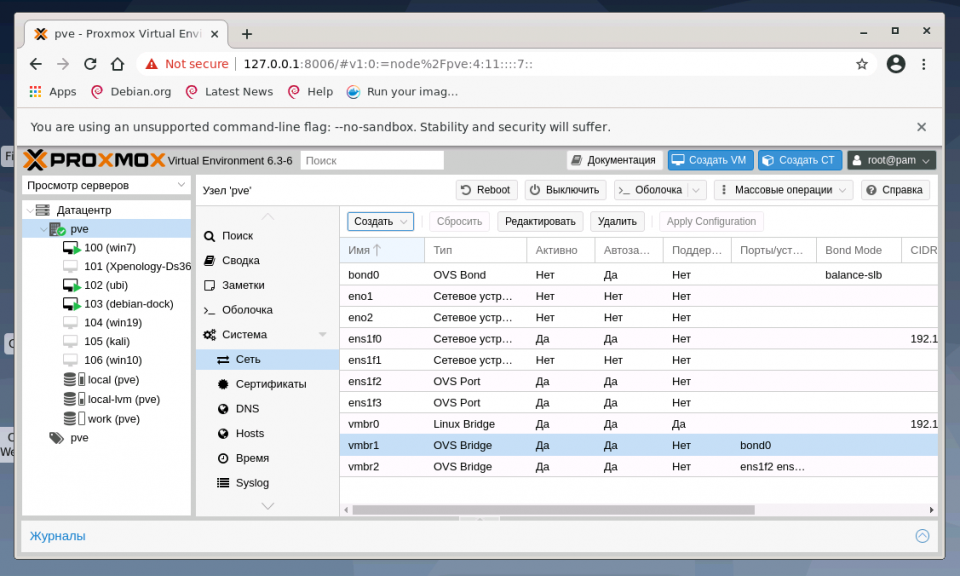
1. Настройка bridge
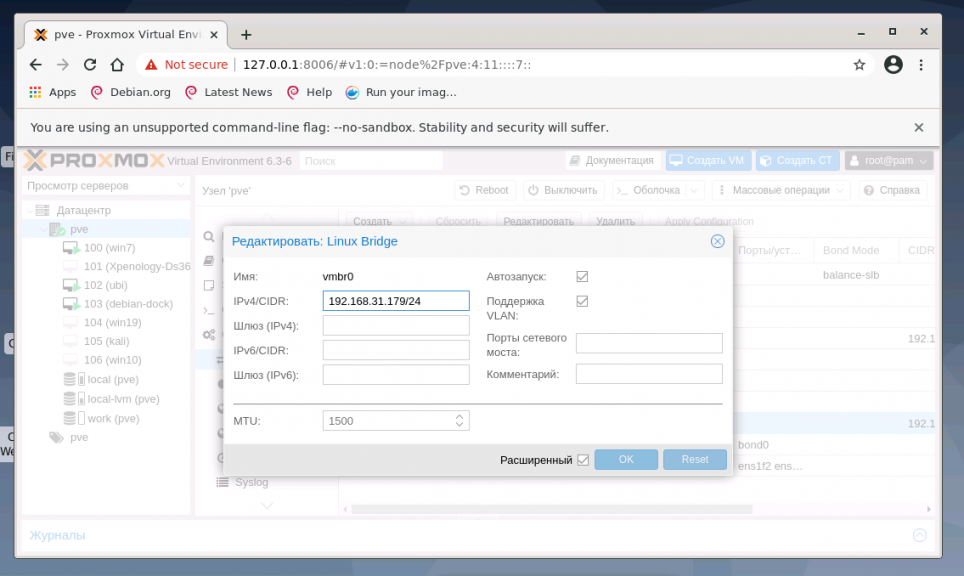
Создание интерфейса bridge для Open vSwitch и для ядра Linux практически ничем не отличаются, за исключением выбора способа создания и возможности указания для OVS Bridge дополнительных ключей Open vSwitch. Если планируется использовать VLAN для сетевого интерфейса, не забудьте указать чек-бокс возле пункта VLAN при создании bridge. Включение чек-бокса Автозапуск позволяет запускать выбранный сетевой интерфейс при загрузке гипервизора:
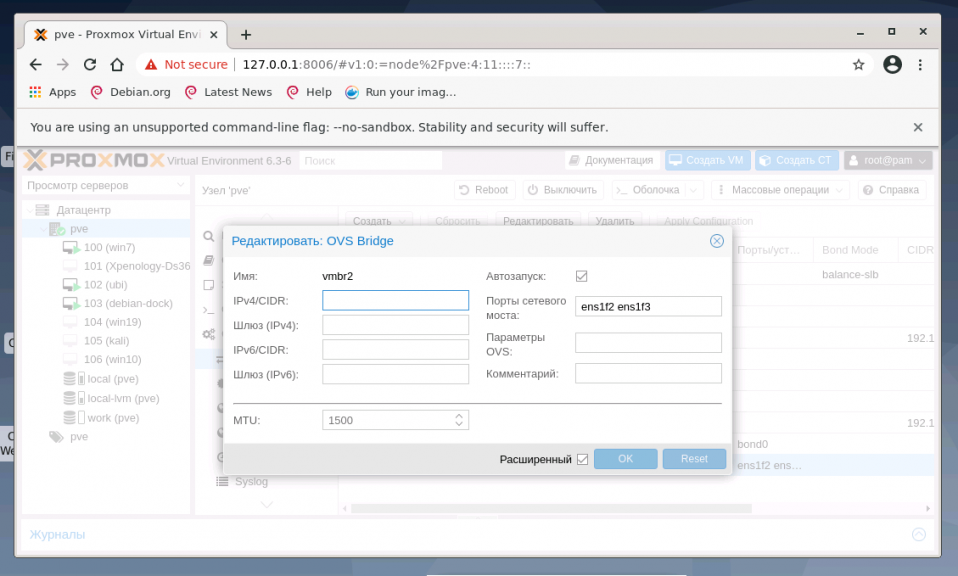
В общем случае, если сетевой интерфейс bridge создаётся единственный для гипервизора, то нет необходимости перечислять в пункте Порты сетевого моста все имеющиеся сетевые карты. Однако, если существует необходимость на уровне интерфейса разделить подключения к различным каналам связи или сегментам сети, то можно использовать различные комбинации сетевых устройств. На представленном хосте гипервизора их четыре, поэтому можно ввести два из них (перечислением через пробел) в bridge OVS:
Адрес интерфейса можно не указывать, настроенные на подключение к интерфейсу виртуальные машины будут использовать его как обычный свитч. Если же указать адрес IPv4 и/или IPv6, то он будет доступен извне на всех сетевых интерфейсах или на интерфейсах, перечисленных в поле Порты сетевого моста:
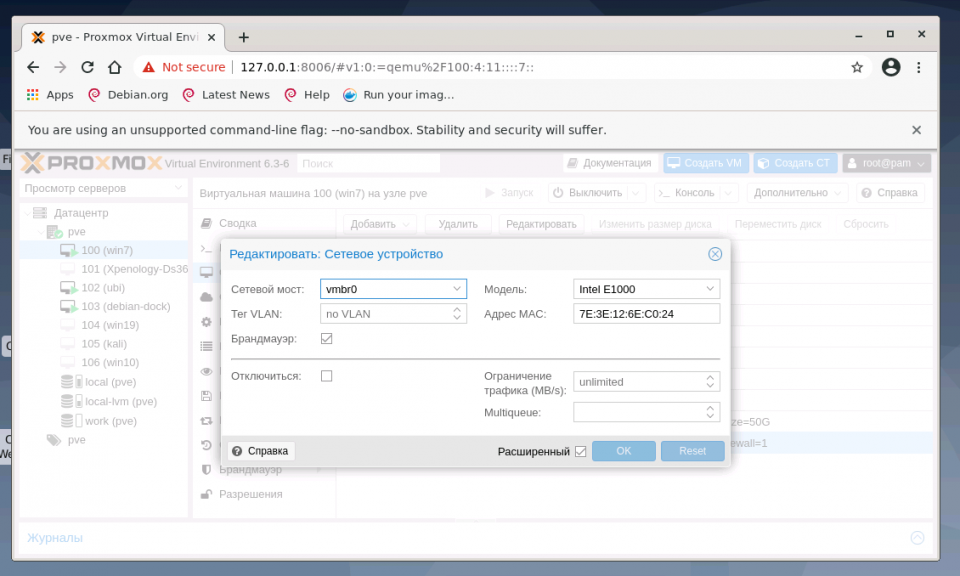
2. Настройка bond
Для балансировки нагрузки и объединения нескольких сетевых интерфейсов в один виртуальный, создайте OVS Bond. Это связано с тем, что его возможности шире, чем Linux Bond, а процесс создания практически идентичен. Для создания балансировщика нагрузки нажмите в меню Сеть кнопку Создать и выберите пункт OVS Bond:
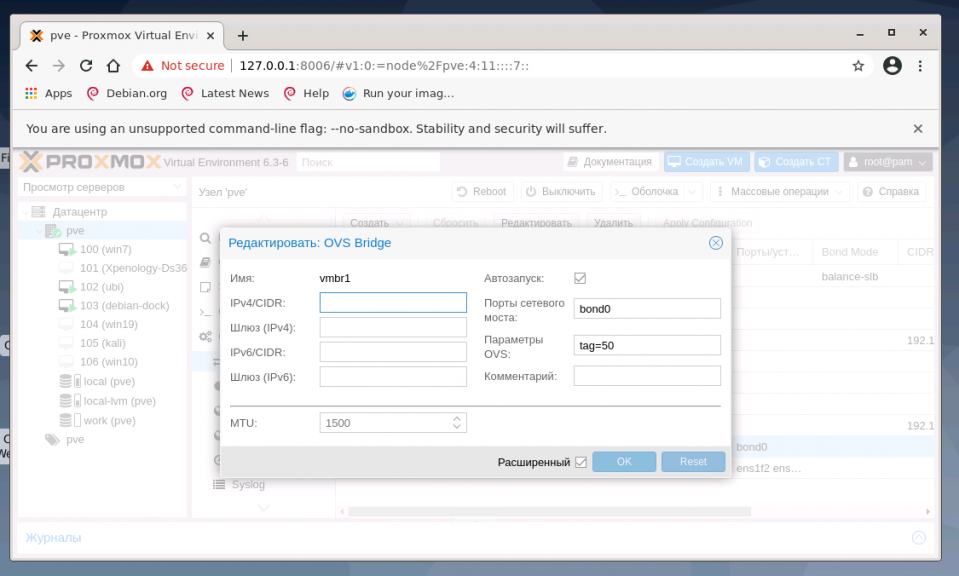
В отличие от создания OVS bridge, в параметрах vmbr1 OVS Bond указано в портах сетевого моста bond0 и в пункте OVS Options для тегирования VLAN можно использовать ключ tag=$VLAN, где $VLAN надо заменить на целое числовое значение, в примере это 50:
Режимы балансировки можно установить только при создании интерфейса bond, перечислим их основные характеристики.
Для OVS Bridge:
- Режим Active-Backup использует один из перечисленных сетевых интерфейсов для работы, а остальные находятся в резерве в статусе down, на случай выхода из строя основного интерфейса
- Режимы Balance-slb, LACP (balance-slb), LACP (balance-tcp) подходят для случая, когда вам необходимо расширить полосу пропускания и отказоустойчивость канала, объединив в единый бонд несколько сетевых интерфейсов.
Для Linux Bond:
- Режим balance-rr ядра Linux скорее переназначен для исходящего траффика, чем для входящего. Пакеты отправляются последовательно, начиная с первого доступного интерфейса и заканчивая последним. Применяется для балансировки нагрузки и отказоустойчивости.
- Режим active-backup ничем не отличается от аналогичного режима в OVS. Передача распределяется между сетевыми картами используя формулу: [( «MAC адрес источника» XOR «MAC адрес назначения») по модулю «число интерфейсов»]. Получается одна и та же сетевая карта передаёт пакеты одним и тем же получателям. Режим XOR применяется для балансировки нагрузки и отказоустойчивости.
- Режим агрегирования каналов по стандарту IEEE 802.3ad. Создаются агрегированные группы сетевых карт с одинаковой скоростью и дуплексом. При таком объединении передача задействует все каналы в активной агрегации, согласно стандарту IEEE 802.3ad. Необходимо оборудование гипервизора и активной сетевой части с поддержкой стандарта.
- Режим адаптивной балансировки нагрузки передачи balance-tlb. Исходящий трафик распределяется в зависимости от загруженности каждой сетевой карты (определяется скоростью загрузки). Не требует дополнительной настройки на коммутаторе. Входящий трафик приходит на текущую сетевую карту. Если она выходит из строя, то другая сетевая карта берёт себе MAC адрес вышедшей из строя карты.
- Режим адаптивной балансировки нагрузки Balance-alb. Включает в себя политику balance-tlb, а также осуществляет балансировку входящего трафика. Не требует дополнительной настройки на коммутаторе.
3. Настройка VLAN
В меню Система найдите раздел Сеть и нажмите кнопку Создать и выберите OVS InPort:
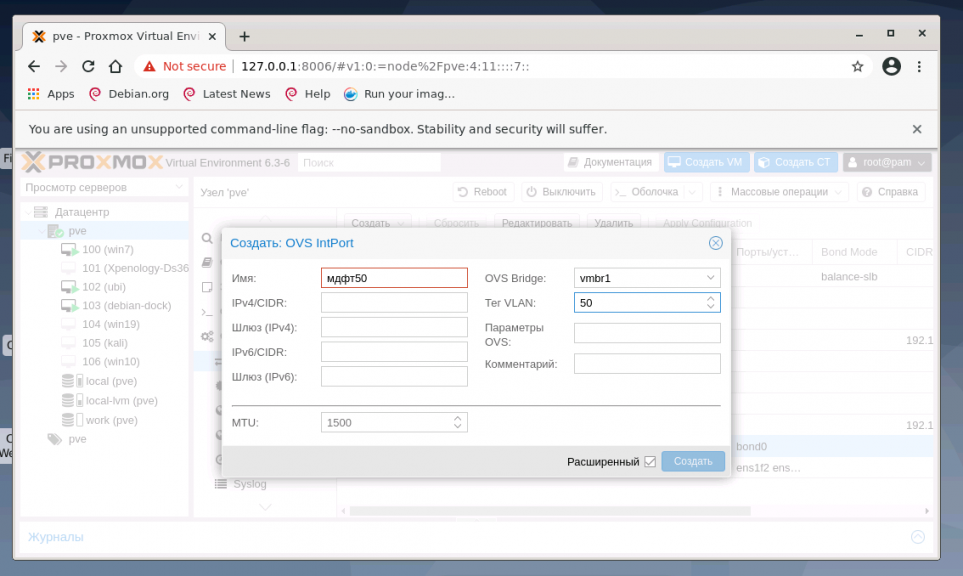
Задайте имя интерфейса vlan50 тег VLAN, равный 50, укажите OVS Bridge. VLAN 50 на указанном виртуальном интерфейсе OVS Bridge vmbr1 с тегом 50 создан и может быть использован, например для организации видеонаблюдения. Таким образом, предлагаю настроить дополнительно VLAN30 для IP телефонии и VLAN100 для локальной сети с виртуализированными рабочими местами. Для создания всех VLAN используйте интерфейс vmbr1.
Выводы
В этой статье рассказано как выполняется настройка сети Proxmox VE. Теперь вы знаете про различные сетевые подключения с помощью интерфейса управления сервером. Гибкость решения позволяет использовать Proxmox VE в качестве управляемого и неуправляемого коммутатора, балансировать нагрузку по различным режимам балансировки.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Об авторе

Системный администратор и программист 1С с 1996 года. Сначала освоил FreeBSD, а потом, как 1С появился для Linux перешёл на CentOS, затем на Debian и Ubuntu. Делаю тонкие клиенты на старых компьютерах и виртуализацию на ProxmoxVE.
При установке гипервизора на выделенный сервер возникает необходимость произвести настройку сети для виртуальных машин. На серверах с подключенным VPU эти настройки немного отличаются от привычных нам, поэтому в этой статье расскажем, как настроить сеть на виртуальной машине, поднятой на Proxmox.
У вас должен быть основной IP-адрес, на котором будет работать сам выделенный сервер с гипервизором, и дополнительный IP-адрес для виртуальной машины.
Для начала установим сам Proxmox – установка проходит как обычно, никаких особенностей нет. Подключаем к серверу ISO с образом Proxmox, грузимся с него и согласно пунктам установщика ставим систему.
Подключить ISO можно, написав нам запрос в поддержку. В запросе лучше приложить прямую ссылку на образ для скачивания. Либо можно подключить IP-KVM в личном кабинете, указав в заказе ссылку на образ. Тогда вместе с IP-KVM к серверу будет подключена флешка с образом. Используя IP-KVM, далее можно произвести установку.
Перезагружаем сервер, грузимся с носителя с образом и видим меню установщика.

Соглашаемся с условиями использования.

Выбираем диск, на который будет установлена система. По кнопке Options можно изменить параметры разметки диска.

Указываем временную зону и раскладку клавиатуры.

Задаем пароль пользователя root и email.
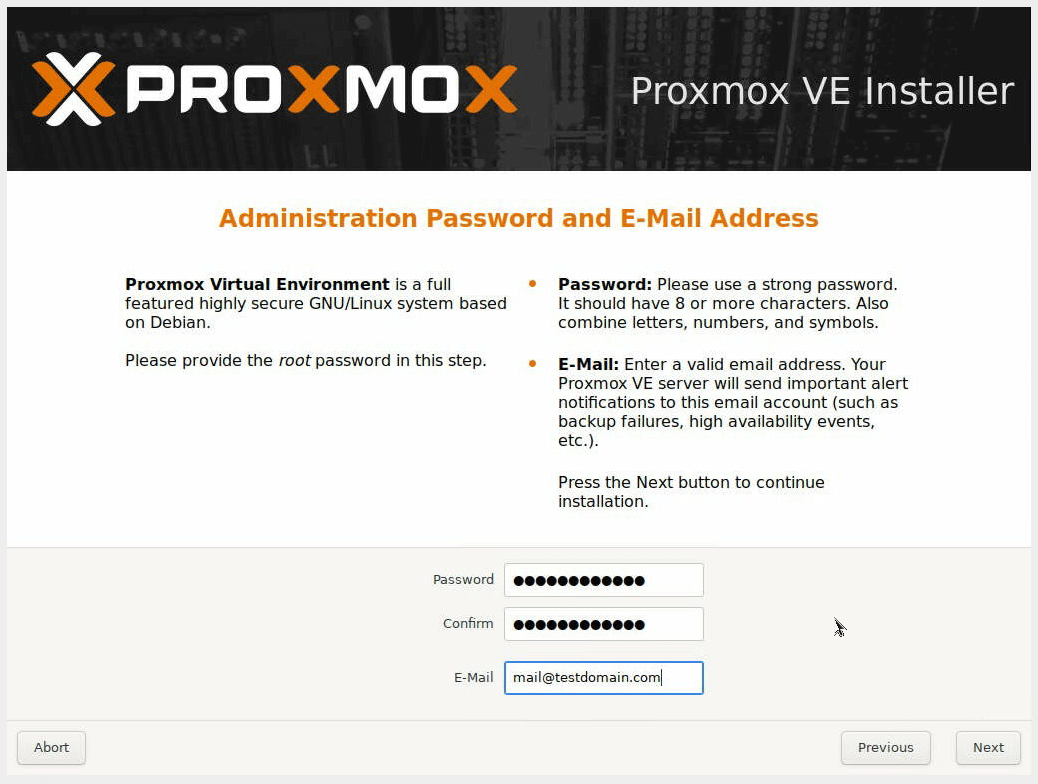
Далее указываем настройки сети. Параметры настройки сети можно посмотреть в панели DCImanager (кнопка IP-адреса), доступы к ней есть в инструкции к серверу, а также в письме об открытии сервера.
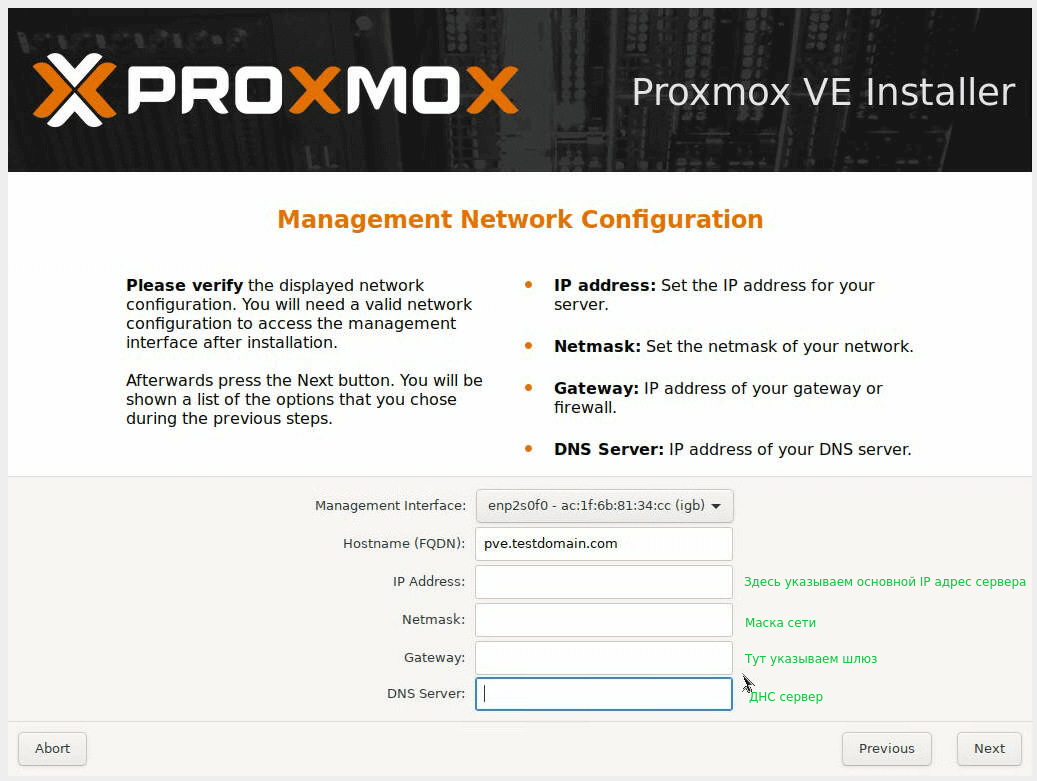
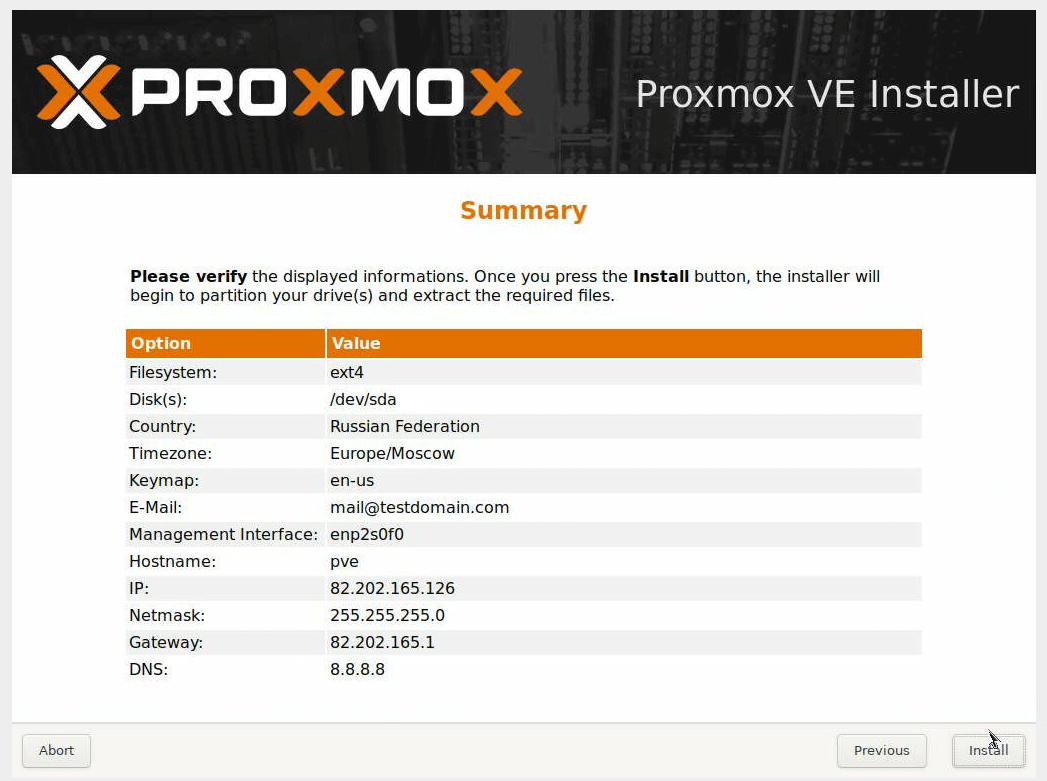
Проверяем, всё ли корректно, и жмем кнопку Install.
Дожидаемся окончания установки и перезагружаем сервер.
2. Создание VM
Установка Proxmox завершена, теперь можно создать виртуальную машину. Для этого заходим в веб-интерфейс по адресу:
https://ВАШ_IP_СЕРВЕРА:8006/
Чтобы установить систему на виртуальную машину, качаем образ с необходимой ОС в директорию /var/lib/vz/template/iso/ на выделенном сервере. После в веб-интерфейсе нажимаем кнопку Create VM.
В открывшемся меню задаем необходимые параметры для сервера. Выбрать образ, с которого будем ставить, можно разделе OС:
После создания виртуальной машины она появится в меню, запускаем ее и переходим в интерфейс VNC для установки системы.
Производим установку ОС:
- Установка CentOS 8
- Установка Debian 10
3. Настройка сети на виртуальной машине
После того, как система будет установлена на виртуальную машину, настроим на ней заказанный дополнительно IP-адрес. В зависимости от выбранной ОС конфигурация может отличаться, вот примеры для наиболее популярных систем (проверьте, чтобы имя интерфейса совпадало с вашим на VM):
CentOS
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static"
IPADDR=ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС
NETMASK=255.255.255.255
SCOPE="peer IP_АДРЕС_ГИПЕРВИЗОРА"
DNS1="188.120.247.2"
# cat /etc/sysconfig/network-scripts/route-eth0
ADDRESS0=0.0.0.0
NETMASK0=0.0.0.0
GATEWAY0=IP_АДРЕС_ГИПЕРВИЗОРАDebian/Ubuntu
# cat /etc/network/interfaces
iface ens3 inet static
address ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС
netmask 255.255.255.255
gateway IP_АДРЕС_ГИПЕРВИЗОРА
pointopoint IP_АДРЕС_ГИПЕРВИЗОРА4. Настройки сети на гипервизоре
Чтобы наша виртуальная машина стала доступна в сети, нужно выполнить настройки на стороне самого гипервизора.
Включаем IP forwarding, для этого в конец файла /etc/sysctl.conf на выделенном сервере добавляем строку:
net.ipv4.ip_forward = 1Применяем конфигурацию (вводим в консоли команду):
# sysctl -pТеперь добавим маршрут для виртуальной машины:
# ip route add ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС_VM/32 dev vmbr0 scope linkЧтобы он автоматически добавлялся после перезагрузки сервера, пропишем его в конфигурации сети. В секцию с настройками виртуального интерфейса добавим строки:
up ip route add ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС_VM/32 dev vmbr0 scope link
down ip route add ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС_VM/32 dev vmbr0 scope linkПримерно так будет выглядеть файл настройки сети на выделенном сервере:
# cat /etc/network/interfaces
auto lo
iface lo inet loopback
iface enp1s0f0 inet manual
auto vmbr0
iface vmbr0 inet static
address ОСНОВНОЙ_IP_АДРЕС_СЕРВЕРА
netmask 255.255.255.254
gateway ШЛЮЗ
bridge_ports enp1s0f0
bridge_stp off
bridge_fd 0
up ip route add ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС_VM/32 dev vmbr0 scope link
down ip route add ДОПОЛНИТЕЛЬНЫЙ_IP_АДРЕС_VM/32 dev vmbr0 scope link
iface enp1s0f1 inet manualНа этом всё, ваша виртуальная машина должна быть доступна в сети. Если же вы решили использовать VMmanager 6 для создания и работы с виртуальными машинами, то про настройку сети в VPU также можете прочитать в нашей статье — настройка сети в VMmanager 6 на выделенных серверах с VPU.
Алексей Гарин, системный администратор