
Тема: В каком файле искать нужный блок div? (Прочитано 3292 раз)
04 Сентябрь 2014, 17:02:32
Добрый день.
Подскажите пожалуйста где(в каком файле) я могу найти нужный мне блок div? Поясню: захожу на сайт, жму F12 нахожу <div id=»center _column» style=» width: 20.5%»>..</div>/ В этом блоке я хочу поменять ширину на width: 15%, т.к. этот стиль прописан в самом блоке div, то в таблице стилей его нет. Подскажите где его искать?

Записан
04 Сентябрь 2014, 18:50:21
Ответ #1
Обычно все div колонок находяться в шаблонах — header.tpl и footer.tpl.
Используйте поиск по содержимому файлов
man grep
grep -rl 'pattern' /path/to/files
Записан
04 Сентябрь 2014, 18:52:48
Ответ #2
Спасибо за совет, буду искать.
Записан
17 Сентябрь 2014, 17:29:59
Ответ #3
Добрый день.
Возник вопрос. Есть блок <div>, в котором отображается логотип производителя, мне нужно переместить его в другую часть страницы товара. Вопрос в том, что если я просматриваю расположение блоков в браузере, то я четко вижу, что нужный мне блок <div> имеет определенный класс и расположен в другом блоке. Когда открываю шаблон страницы товара и пытаюсь найти этот блок, — то безуспешно, нет такого блока с таким классом.
Подскажите пожалуйста, как можно еще найти нужный мне блок?
Записан
17 Сентябрь 2014, 17:34:00
Ответ #4
Всего 2 варианта или в шаблоне страницы, или в модуле Производители.
Записан
17 Сентябрь 2014, 17:45:12
Ответ #5
Ни в том ни в другом шаблоне не нашел такого блока с таким классом, который мне нужно, хотя я его четко вижу в браузере: в нем находится картинка бренда и ссылка.
Записан
17 Сентябрь 2014, 17:50:35
Ответ #6
Если блок показан на странице товара, то он должен быть в
1. Шаблоне product.tpl
2. Шаблоне модуля, который подключается в хуки страницы товара.
3. Javascript функции, которая выполняется при загрузки страницы товара.
Все эти файлы расположены в вашей теме.
Используйте поиск по содержимому файлов
man grep
grep -rl 'pattern' /path/to/files
Записан
17 Сентябрь 2014, 18:00:16
Ответ #7
Подскажите пожалуйста шаблон модуля, который подключается в хуки страницы товара.
Записан
17 Сентябрь 2014, 19:19:38
Ответ #8
Модули > Расположение блоков
Product footer — 0 Модуль [This hook adds new blocks under the product’s description] (Техническое имяdisplayFooterProduct)
— Названия модулей
New elements on the product page (left column) — 2 Модули [This hook displays new elements in the left-hand column of the product page] (Техническое имяdisplayLeftColumnProduct)
— Названия модулей
Tabs on product page — 1 Модуль [This hook is called on the product page’s tab] (Техническое имяdisplayProductTab)
— Названия модулей
Записан
17 Сентябрь 2014, 19:39:31
Ответ #9
Записан
Время на прочтение
6 мин
Количество просмотров 87K
Всем добра!
Данную тему мы уже раскрывали на вебинаре, который проводил наш преподаватель, но решили дополнить чуть текстом (да и многим, как оказалось, так удобнее). В общем представляем статью на тему «Селекторы CSS», которую Павел Попов прорабатывал в рамках нашего курса «Автоматизация в тестировании».
Поехали.
Каждый курс или статья для начинающих автоматизаторов рассказывает об удобном и универсальном средстве поиска элементов Web-страницы, как XPath. Данный вид локаторов на элемент был создан в 1999 году для указания на элементы в XML файлах. С помощью встроенных функций XPath стал очень популярным инструментом поиска элементов на Web-странице. Если HTML код вашего приложения выглядит как-то так:
…
<form class=“form_upload>
<div>
<div class=“row_element_3 row tile_fixed”>
<div class=“button_cell wrapper_tile”>
<button type=“submit” class=“button_submit wrapper_button”>Нажми меня</button>
</div>
</div>
</div>
</form>
…и вы не можете найти достойный XPath для кнопки “Нажми меня”, не стоит сразу бежать в сторону разработчика с просьбой о помощи. Есть отличная возможность воспользоваться CSS селектором, он будет выглядеть так:
.button_submitДобро пожаловать в мир CSS.

Принято считать, что в CSS селекторах все завязано на классы. Это не совсем так, но если Web приложение использует “оптимизатор” или “обфускатор” HTML кода, и выглядит вот так:
<form class=“afhfsdh__”>
<div>
<div class=“hfgeyq fjjs qurlzn”>
<div class=“fjdfmzn fjafjd”>
<button type=“submit” class=“ajffalf wjf_fjaap”></button>
</div>
</div>
</div>
</form>
…(все названия css классов уменьшены с помощью оптимизатора)
, то получить короткий CSS селектор не удастся — как правило, после каждого нового билда css классы меняются на новые. Но все равно, CSS селектор может оказаться проще и в этом случае: css: form button[type=‘submit’], вместо XPath: //form//button[@type=‘submit’]
Допустим, что оптимизаторы HTML у нас не установлены и разработчики не планируют его использовать на проекте (проверьте этот факт!).
Как вы могли уже догадаться, символ. используется вместо слова class и будет искать вхождение данного класса в любом элементе, в независимости от количества классов у этого элемента.
Смотрите:
<form class=“form_upload>
<div>
<div class=“row_element_3 row tile_fixed”>
<div class=“button_cell wrapper_tile”>
<button type=“submit” class=“button_submit wrapper_button”></button>
</div>
</div>
</div>
</form>
css для элемента button: .button_submit, при этом класс .wrapper_button указывать необязательно, но если он нужен для указания на наш класс, мы можем его добавить сразу после указания первого css класса: css: .button_submit.wrapper_button. Порядок классов роли не играет, поэтому их можно поменять местами:
.wrapper_button.button_submit .Следующим незаменимым помощником в поиске HTML элементов являются Теги. Написать css селектор, указывающий на тег button очень просто, тем более, что он уже был написан в этом предложении. CSS селектор для button –
css: button.И ничего больше указывать вам не требуется, если ваша цель — это привязка к тегу. Совмещая теги и классы получаем::
button.button_submitи это также является css селектором к нашему элементу.
Помимо тегов, атрибуты также помогают уникально идентифицировать элемент на странице. Часто разработчики создают дополнительные атрибуты вместо добавления новых “айдишников”, например, могут создавать дополнительные атрибуты data-id или auto-id у каждого элемента, с которым планируется дальнейшее действие. К примеру, разработчики могут добавить атрибут data-id к нашей кнопке button. Тогда к атрибутам с помощью css селектора можно обратиться через фигурные скобки: [data-id=‘submit’]. Дополнительно, вы можете не указывать значение атрибута после знака равно [data-id]. Такой селектор найдет вам все элементы, у которого существует атрибут data-id с любым значением внутри. Вы также можете указать атрибут class для поиска нашей кнопки: [class=‘button_submit’], но в CSS, как вы уже знаете, можно полениться и написать так: .button_submit. Соединять все вместе также достаточно просто:
button[type=‘submit’].button_submit
тег атрибут классНо это большая удача, если нам удается находить элемент, используя селектор с указанием только одного элемента, как, например, использовать атрибут [data-id] который однозначно находит один элемент на странице. Очень часто нам приходится использовать предков элемента, чтобы найти потомка. И это в CSS тоже возможно сделать достаточно просто:
<form class=“form_upload>
<div>
<div class=“row_element_3 row tile_fixed”>
<div class=“button_cell wrapper_tile”>
<button type=“submit” class=“button_submit wrapper_button”></button>
</div>
</div>
</div>
</form>
css:form > div > div > div > button.button_submit
и знак > позволяет найти элемент исключительно у предка внутри. Но писать все элементы ненужно, так как в CSS есть возможность поиска во всех потомках, этот символ — пробел “ “. Используя данный указатель мы можем быстро найти элемент внутри формы:
Было: css: form > div > div > div > button.button_submit
Стало: css: form button,button_submit
Удобно также находить следующего “родственника” через предыдущего. Дополним наш пример еще одним span:
<form class=“form_upload>
<div>
<div class=“row_element_3 row tile_fixed”>
<div class=“button_cell wrapper_tile”>
<div class=“content”></div>
<span data-id=“link”>Ссылка</span> <!-- элемент с атрибутом data-id -->
<button type=“submit” class=“button_submit wrapper_button”> <!-- искомая кнопка --></button>
</div>
</div>
</div>
</form>
[data-id=‘link’] + button найдет button, у которого выше на один уровень есть родственник с атрибутом data-id=”link”. Этим указателем можно пользоваться, когда у предыдущего элемента есть id или уникальный атрибут, а у элемента, который находится следующим после нужного, таких идентификаторов нет. Итак, с помощью символа + css селектор найдет следующего родственника.
NOTE:
div + span[data-id=‘link’] + buttonДополнительно вы можете собирать “паровозик” из следующих элементов с использованием указателя +, но не советую это делать из-за возможного изменения местонахождения элементов.
Не стоит упускать вариант поиска по части атрибута. Делается это просто: button[class*=‘submit’] — из длинного названия класса button_submit мы берем только правую часть submit и добавляем к знаку = символ *. Также можно найти по слову cell из значения класса: div[class*=‘cell’].
Есть еще одна особенность css селекторов, которая позволит найти вам все ссылки или расширения файлов, это ^= и $= , но такая задача стоит не так часто, как поиск по вхождению значения у атрибута.
a[href^=“https:”] — найдет все ссылки, которые начинаются с https,
a[href$=“.pdf”] — найдет все ссылки, которые заканчиваются на .pdf.
Немного о том, как найти потомков с одним и тем же тегом у предка. Начнем, как всегда, с примера:
<div class=“tiles”>
<div class=“tile”>…</div>
<div class=“tile”>…</div>
</div>
Как найти второй div class=“tile” у div class=“tiles”? Варианта два:
div > div:nth-of-type(2) div > div:nth-child(2)Но в чем различие между этими двумя селекторами? Дополним пример:
<div class=“tiles”>
<a class=“link”>…</a> <!—1—>
<div class=“tile”>…</div><!—2—>
<div class=“tile”>…</div><!—3—>
</div>
css 1 вариант: div > div:nth-of-type(2)
css 2 вариант: div > div:nth-child(2)
Теперь эти селекторы ведут на два разных элемента. Прежде чем идти далее, попробуйте догадаться, какой селектор ведет на какой элемент?
Разгадка:
первый селектор будет указывать на строчку номер 2, тогда как второй селектор будет указывать на строчку номер 3. nth-child ищет второй div, который является потомком родителя . Второй
<div>
у элемента
<div class=“tiles”>
это третья строка. В свою очередь nth-of-type ищет второй элемент у родителя
<div class=“tiles”>
, который должен являться тегом
div
, это строка номер два.
Есть правило, которое позволяет упростить работу с селекторами в ситуации, когда вам нужно найти конкретный элемент: использовать nth-of-type везде, где это возможно. Если вы разобрались с примером выше, рекомендую вам всегда обращать внимание на количество одинаковых элементов у предка, используя nth-child, и тогда вам будет неважно, куда поместят ссылку
<a>
: наверху, между
<div>
или внизу блока, всегда селектор div:nth-child(2) будет все равно указывать на нужный элемент – второй элемент div внутри блока.
Была опущена еще одна функция поиска элемента по id. Вы уже знаете, что поиск по любому из атрибутов осуществляется с использованием указания квадратных скобок [attribute=“value”] и для нашего случая мы можем найти элемент так [id=“value”]. А что если есть существует более быстрый способ поиска по id элемента?
#value. “#” - указатель, что поиск осуществляется по id.Используя все приобретенные навыки попробуйте написать селектор для кнопки
<button>
Отправить
…
<div>
<div class=“tile_wrapper tile content”>
<div class=“row row_content”>
<div class=“outline description__on”></div>
<div class=“outline description__off button_send hover_mouse”>
<button class=“outline button_send”>Отправить</button>
</div>
</div>
</div>
</div>
Будем рады увидеть ваши комментарии и варианты в комментариях тут или обсудить это на очередном открытом уроке, который пройдёт у нас 13-го марта.
Спасибо!
В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
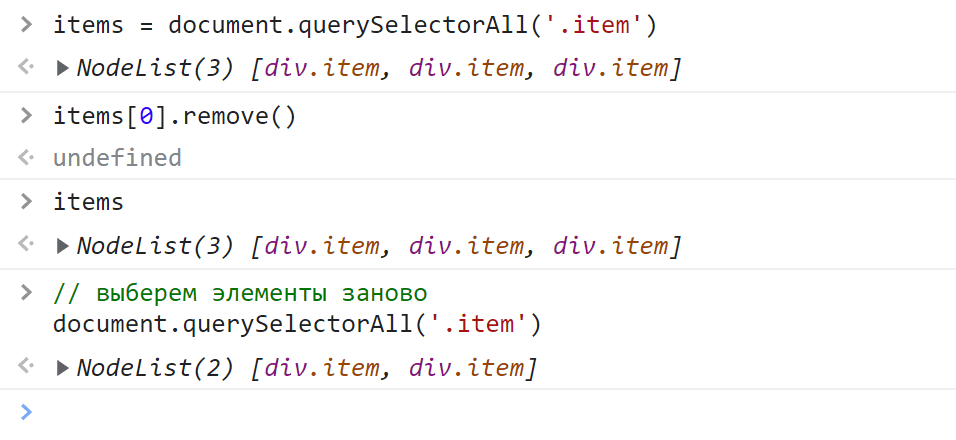
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>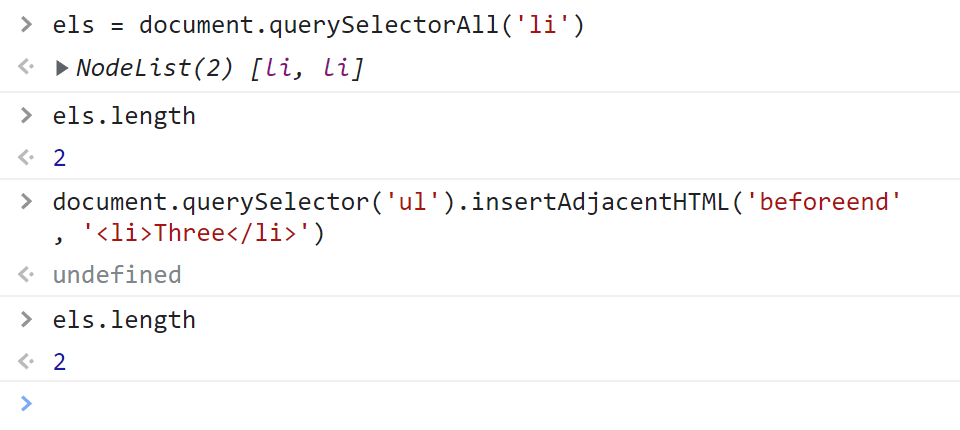
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
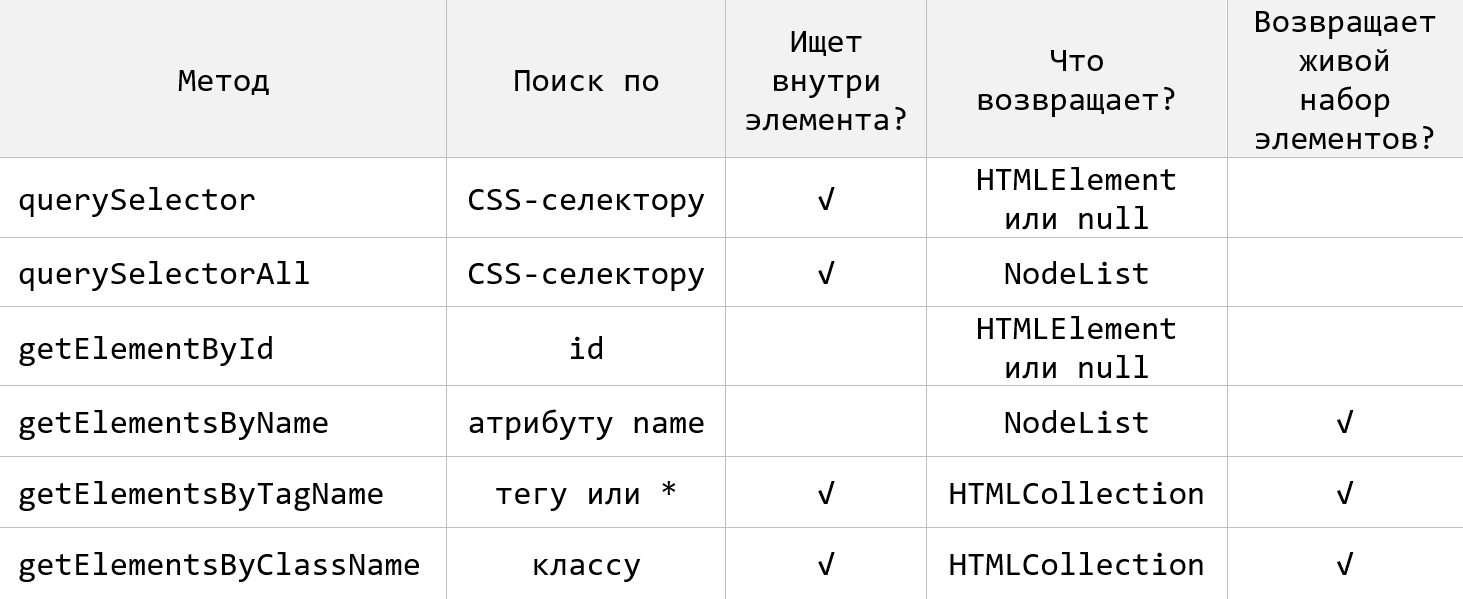
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
- Поиск по id
- Поиск по тегу
- Получить всех потомков
-
Поиск по
name: getElementsByName - Другие способы
Стандарт DOM предусматривает несколько средств поиска элемента. Это методы getElementById, getElementsByTagName и getElementsByName.
Более мощные способы поиска предлагают javascript-библиотеки.
Поиск по id
Самый удобный способ найти элемент в DOM — это получить его по id. Для этого используется вызов document.getElementById(id)
Например, следующий код изменит цвет текста на голубой в div‘е c id="dataKeeper":
document.getElementById('dataKeeper').style.color = 'blue'
Поиск по тегу
Следующий способ — это получить все элементы с определенным тегом, и среди них искать нужный. Для этого служит document.getElementsByTagName(tag). Она возвращает массив из элементов, имеющих такой тег.
Например, можно получить второй элемент(нумерация в массиве идет с нуля) с тэгом li:
document.getElementsByTagName('LI')[1]
Что интересно, getElementsByTagName можно вызывать не только для document, но и вообще для любого элемента, у которого есть тег (не текстового).
При этом будут найдены только те объекты, которые находятся под этим элементом.
Например, следующий вызов получает список элементов LI, находящихся внутри первого тега div:
document.getElementsByTagName('DIV')[0].getElementsByTagName('LI')
Получить всех потомков
Вызов elem.getElementsByTagName('*') вернет список из всех детей узла elem в порядке их обхода.
Например, на таком DOM:
<div id="d1">
<ol id="ol1">
<li id="li1">1</li>
<li id="li2">2</li>
</ol>
</div>
Такой код:
var div = document.getElementById('d1')
var elems = div.getElementsByTagName('*')
for(var i=0; i<elems.length; i++) alert(elems[i].id)
Выведет последовательность: ol1, li1, li2.
Поиск по name: getElementsByName
Метод document.getElementsByName(name) возвращает все элементы, у которых имя (атрибут name) равно данному.
Он работает только с теми элементами, для которых в спецификации явно предусмотрен атрибут name: это form, input, a, select, textarea и ряд других, более редких.
Метод document.getElementsByName не будет работать с остальными элементами типа div,p и т.п.
Другие способы
Существуют и другие способы поиска по DOM: XPath, cssQuery и т.п. Как правило, они реализуются javascript-библиотеками для расширения стандартных возможностей браузеров.
Также есть метод getElementsByClassName для поиска элементов по классу, но он совсем не работает в IE, поэтому в чистом виде им никто не пользуется.
Частая опечатка связана с отсутствием буквы s в названии метода getElementById, в то время как в других методах эта буква есть: getElementsByName.
Правило здесь простое: один элемент — Element, много — Elements. Все методы *Elements* возвращают список узлов.
|
Остап 0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
||||||||||||
|
1 |
||||||||||||
|
10.07.2015, 20:57. Показов 16157. Ответов 23 Метки нет (Все метки)
Всем доброго времени суток! Проблема следующая, на странице рубрики в моем шаблоне на каждую статью по 3 ссылки, 1 из названия, 2 при щелчке по картинке и 3 при щелчке по кнопке «читать далее». Две из них я хочу закрыть от индексации, но не могу найти нужный мне div что бы это сделать. Я уже как мог все перерыл и без толку, открывал все страницы шаблона в Notepad++ и выполнял поиск по всем файлам, — ничего. Прошу помощи… Вот собственно кусок кода в котором 3 ссылки на статью:
Я хочу найти в файле код с
и
и закрыть их от индексации. Насколько я понял именно они отвечают за ссылки в картинке и кнопке «read more». Заранее спасибо тем кто ответит!
0 |

|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
10.07.2015, 21:56 |
2 |
|
Попробуйте уменьшить шаблон поиска до имени отдельных css классов: Должны присутсвовать. Целиком эти куски кода в шаблонах вряд ли найдете. Добавлено через 4 минуты
0 |
|
Остап 0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
||||
|
10.07.2015, 23:03 [ТС] |
3 |
|||
|
Спасибо за ответ. Я попробовал поискать image_styled или entry_image, но с этими двумя ничего не удалось. А вот строки с read_more_wrap встретились мне в файле loop.php:
И заметил там атрибуты «nofollow», то есть с кнопками все еще не так критично… Но все же хотелось бы закрыть полностью от индексации обе ссылки, и с картинок и с кнопок
0 |
|
GradX 22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
||||||||||||
|
11.07.2015, 00:52 |
4 |
|||||||||||
|
Должны присутствовать и те классы в каком-то файле .php. Можно конечно было бы на месте разрабов сделать в одном файле что-то вроде:
А в другом такое:
Но вы все равно смогли бы найти ‘entry_image’. Есть конечно вариант добавления класса с помощью джаваскрипта. Но что первое, что второе в данном случае — крайне маловероятно, так как незачем так изощряться для установки css классов. Также можно попробовать поискать совпадения для классов внутренних элементов (например, image_shadow_wrap или image_frame или effect-icon). Но то, что они в одном или нескольких .php файлах это 99% (1% на то, что разработчики — извращенцы) Добавлено через 1 час 6 минут
Этот код будет оборачивать все ссылки, которые имеют классы read_more_link или image_icon_doc в html тег noindex
1 |
|
0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
|
|
11.07.2015, 03:51 [ТС] |
5 |
|
Попробовал, — ошибку выдает когда вставляю код в functions.php. Исправил, скопировал кусок от <script> до </script> и вставил в «Custom CSS & JS Fields» в настройках шаблона в админке, заработало на половину, read_more_link оборачивает а image_icon_doc никак. Уж как ни крутил, не получается…
0 |
|
GradX 22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
||||||||
|
11.07.2015, 10:17 |
6 |
|||||||
|
А что за ошибку выдает? Скрин или текст бы… Добавлено через 12 минут Добавлено через 17 минут
Добавлено через 8 минут
Добавлено через 1 час 7 минут
0 |
|
Остап 0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
||||||||||||
|
11.07.2015, 11:33 [ТС] |
7 |
|||||||||||
|
Вставил этот вариант:
Ошибки нет, но и результата тот же что и с копированием скрипта в «Custom CSS & JS Fields», — работает на половину. Вот кусок кода картинки с сылкой после установки скрипта:
Не изменился. Вот кусок кода с ссылкой в кнопке:
0 |
|
GradX 22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
||||||||
|
11.07.2015, 11:49 |
8 |
|||||||
|
Похоже что ваша ссылка для картинки действительно генерируется javascript-ом.
3. В файл functions.php вашей темы добавте следующий код:
Кратко о том как это работает и почему так:
0 |
|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 12:17 |
9 |
|
Я попробовал протестировать — у меня работает.
0 |
|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 12:25 |
10 |
|
Хотя установить его как обычный плагин не получиться (я еще создание плагинов только изучаю). Но можно просто распаковать в папку с плагинами, и он отобразится в админке среди плагинов, его можно активировать и деактивировать и удалить из админки. А установка почему-то пока только в ручном режиме. Добавлено через 3 минуты
0 |
|
Остап 0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
||||||||
|
11.07.2015, 13:45 [ТС] |
11 |
|||||||
|
Попробовал и руками и плагин, — к сожалению не помогло… вот кусок кода страницы рубрики, на которой нужно закрыть ссылки:
Все тот же кусок с ненужными ссылками:
0 |
|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 13:57 |
12 |
|
А можно увидеть часть кода страницы перед закрывающим тегом </body>?
0 |
|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 14:06 |
13 |
|
если скрипт работает как задуманно, то должно быть что-то вроде: Миниатюры
0 |

|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 14:08 |
14 |
|
Но если ссылка генерируется таким же образом (т.е. скрипт внедряет скрипт, а тот уже генерирует ссылки), то можно попробовать увеличить «вложенность» оборачивающего скрипта. Но если код в точности как на скрине, то я не знаю как еще его перехитрить.
0 |
|
Остап 0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
||||
|
11.07.2015, 14:26 [ТС] |
15 |
|||
|
Вот так, видимо я что то не правильно делаю
0 |
|
GradX 22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
||||||||
|
11.07.2015, 14:55 |
16 |
|||||||
|
У меня есть два варианта:
2. Если первый вариант не даст результатов — попробуйте изменить код в файле wrap-link.js на такой:
У меня работают оба. Первый просто увеличивает «вложенность» оборачивающего скрипта. А второй оборачивает ссылки спустя 5 секунд после загрузки страницы. Второй вариант должен работать в любом случае (хотя у меня уже есть сомнения), но не знаю как эта «задержка» будет восприниматься поисковиками. Первый раз с такой «камасутрой» сталкиваюсь. Добавлено через 3 минуты Добавлено через 1 минуту
0 |
|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 16:20 |
17 |
|
Рабочая версия плагина.
0 |
|
GradX 22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
||||
|
11.07.2015, 16:58 |
18 |
|||
|
Кстати, попробуйте еще в ostap-plugin.php изменить код:
Если будет работать, тогда таскать jQuery за собой этому плагину не придется. И вместо 96КБ будет менее 1КБ дополнительного веса.
0 |
|
22 / 22 / 8 Регистрация: 17.11.2012 Сообщений: 124 |
|
|
11.07.2015, 17:34 |
19 |
|
Скрины закрытых ссылок кнопки и картинки: Миниатюры
0 |
|
Остап 0 / 0 / 0 Регистрация: 07.04.2015 Сообщений: 25 |
||||
|
12.07.2015, 07:26 [ТС] |
20 |
|||
|
Большое спасибо за помощь! Все работает, жаль только что вес так увеличен. Вариант с этим кодом попробовал, не сработал. Ну все же лучше так, чем с дублями. Спасибо, еще раз.
0 |