Автоопределение кодировки текста
Время на прочтение
6 мин
Количество просмотров 51K

Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandiacpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
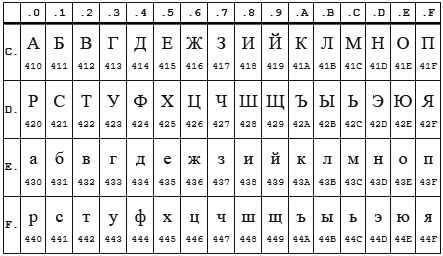
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
//test input interfase
if r == nil {
return ASCII, nil
}
//make slice of byte from input reader
buf, err := bufio.NewReader(r).Peek(ReadBufSize)
if (err != nil) && (err != io.EOF) {
return ASCII, err
}
...вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File
res, err := CodePageDetect(data)В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Version: 20230216
By the same author: Virtour.fr — visites virtuelles
Универсальный декодер — конвертер кириллицы
Результат
[Результат перекодировки появится здесь…]
|
Гостевая книга
Поставьте ссылку на наш сайт! <a href=»https://2cyr.com/decode/»>Универсальный декодер кириллицы</a> |
Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available). FAQ and contact information. |
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
- Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 8280 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Декодер онлайн (decoder online)
Текст успешно скопирован!
Определить исходную кодировку
Как узнать кодировку текста онлайн?
Существует ряд сервисов, которые способны определить кодировку текста онлайн. Они все делают автоматически, в том числе позволяют конвертировать слова в правильный формат. Хотя подобных сервисов много, не все они одинаково хорошо подходят для определения кодировки онлайн. Мы подобрали несколько лучших вариантов.
Online Decoder
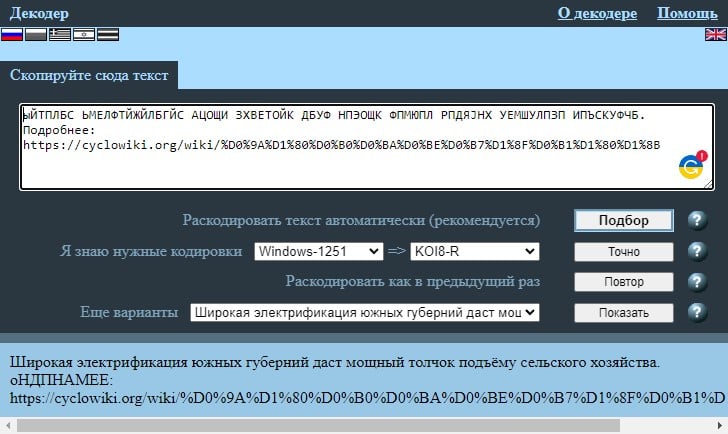
Помимо того, что сервис позволит узнать кодировку онлайн для любого фрагмента текста, он также способен конвертировать его. Поддерживает практически все кодировки. Работает быстро, просто и эффективно. Если нужен также конвертер кодировок онлайн, этот вариант окажется одним из лучших. Все необходимые действия можно выполнить в рамках 1 минуты и это в первый раз.
Что нужно сделать:
- Открывать сайт Online Decoder.
- Вставляем в пустое поле наш текст с неправильной кодировкой.
- В строке «Раскодировать текст автоматически (рекомендуется)» нажимаем на кнопку «Подбор».
- Немного ниже, в строке «Я знаю нужные кодировки» обращаем внимание на первую часть. Там указана кодировка вставленного текста, а во втором поле – та, в которую конвертирован фрагмент.
2cyr
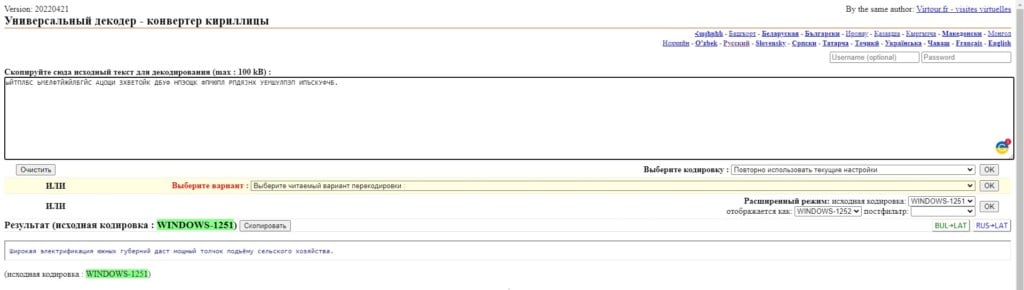
Сервис создан для декодирования различного текста, в том числе он способен преобразовывать строки между различными кодировками. Он довольно прост и не требует никаких особенных знаний. Вам достаточно открыть сайт 2cyr, вставить текст и нажать на кнопку «Ок» справа под пустым полем. После непродолжительного анализа система выдаст информацию о родной кодировке текста и той, что была установлена после преобразования.
FoxTools
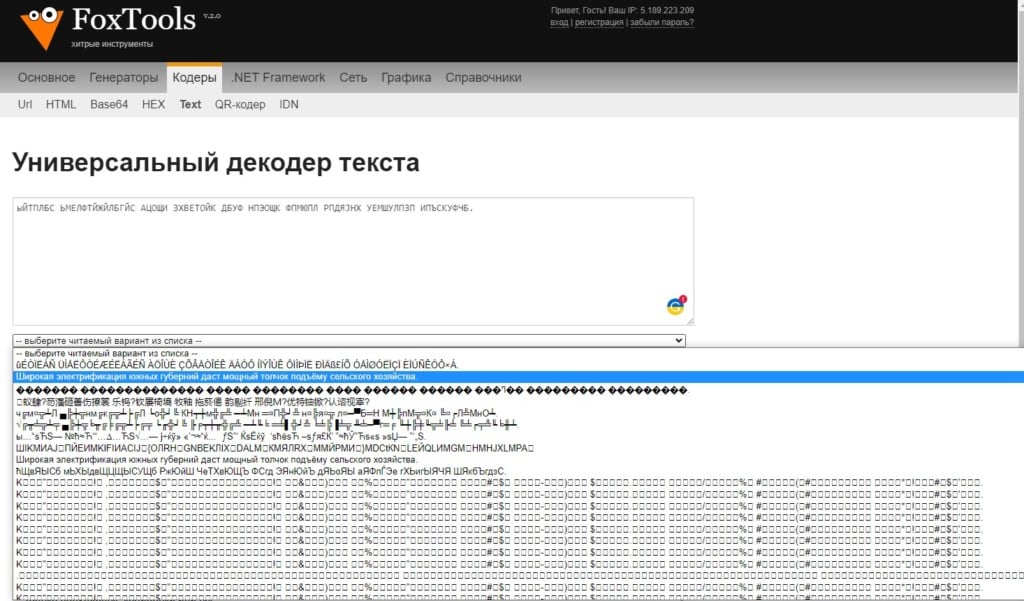
Принцип работы подобен описанным выше сервисам, но есть и одно отличие. Сайт предоставляет большой выбор вариантов текста на выходе. Он предлагает вам самостоятельно найти ту кодировку, в которой текст будет читаться правильно. Это положительная особенность, так как некоторые форматы пересекаются между собой и могут неправильно определяться автоматическими сервисами.
Как это работает:
- Переходим на целевую страницу FoxTools.
- Вставляем в пустое поле текст и жмем по кнопке «Отправить».
- Нажимаем по выпадающему списку с названием «Выберите читаемый вариант из списка» и ищем тот текст, который мы можем без проблем прочитать.
Определение кодировки онлайн – простая задача, особенно с помощью хороших веб-сервисов. Все они бесплатные, простые в использовании и достаточно точны.
Как определить кодировку текстового файла
Кодировкой текста в файлах цифровых документов называют способ сопоставления последовательностей байт символам языка. Существует множество различных кодировок для разных языков. Определить кодировку текстового файла можно при помощи ряда программных средств.

Вам понадобится
- — Microsoft Office Word;
- — KWrite;
- — Mozilla Firefox;
- — enca.
Инструкция
Используйте редактор Microsoft Office Word, если он установлен на компьютере, для определения кодировки текстового файла. Запустите данное приложение. В главном меню последовательно выберите пункты «Файл» и «Открыть…» или нажмите сочетание клавиш Ctrl+O. В отобразившемся диалоге перейдите к нужному каталогу и выделите файл. Нажмите кнопку «Открыть». Если кодировка текста отличается от CP1251, автоматически откроется диалог «Преобразование файла». Активируйте в нем опцию «Другая» и подберите кодировку, используя список, находящийся справа. При выборе правильной кодировки в поле «Образец» будет выведен читаемый текст.
Примените текстовые редакторы, допускающие выбор кодировки текста источника. Хорошим примером подобного приложения является KWrite (работает в среде KDE в UNIX-подобных системах). Загрузите текстовый файл в редактор. Затем просто перебирайте кодировки, пока не отобразится читаемый текст (в KWrite для этого используется раздел Encoding меню Tools).
Аналогично текстовому редактору для определения кодировки файла можно использовать и браузер. Воспользуйтесь Mozilla Firefox. Запустите данное приложение. Если оно не установлено, загрузите подходящий дистрибутив с сайта mozilla.org и инсталлируйте его. Откройте в браузере текстовый файл. Для этого выберите в главном меню пункты «Файл» и «Открыть файл…» или нажмите Ctrl+O. Если загруженный текст отобразился корректно, разверните раздел «Кодировка» меню «Вид» и узнайте кодировку из названия пункта, на котором установлена отметка. В противном случае подберите данный параметр путем выбора различных пунктов того же меню, а также его раздела «Дополнительные».
Примените специализированные утилиты для определения кодировок текстовых файлов. В UNIX-подобных системах можно использовать enca. При необходимости установите эту программу при помощи доступных менеджеров пакетов. Выведите список доступных языков, выполнив команду:
enca —list languages
Определите кодировку текстового файла, указав его имя при помощи опции -g и язык документа при помощи опции -L. Например:
enca -L russian -g /home/vic/tmp/aaa.txt.
Источники:
- Кодировка текста ASCII
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.