FWIW, here are a couple of non-RE alternatives that I think are neater than poke’s solution.
The first uses str.index and checks for ValueError:
def findall(sub, string):
"""
>>> text = "Allowed Hello Hollow"
>>> tuple(findall('ll', text))
(1, 10, 16)
"""
index = 0 - len(sub)
try:
while True:
index = string.index(sub, index + len(sub))
yield index
except ValueError:
pass
The second tests uses str.find and checks for the sentinel of -1 by using iter:
def findall_iter(sub, string):
"""
>>> text = "Allowed Hello Hollow"
>>> tuple(findall_iter('ll', text))
(1, 10, 16)
"""
def next_index(length):
index = 0 - length
while True:
index = string.find(sub, index + length)
yield index
return iter(next_index(len(sub)).next, -1)
To apply any of these functions to a list, tuple or other iterable of strings, you can use a higher-level function —one that takes a function as one of its arguments— like this one:
def findall_each(findall, sub, strings):
"""
>>> texts = ("fail", "dolly the llama", "Hello", "Hollow", "not ok")
>>> list(findall_each(findall, 'll', texts))
[(), (2, 10), (2,), (2,), ()]
>>> texts = ("parallellized", "illegally", "dillydallying", "hillbillies")
>>> list(findall_each(findall_iter, 'll', texts))
[(4, 7), (1, 6), (2, 7), (2, 6)]
"""
return (tuple(findall(sub, string)) for string in strings)
Skip to content
В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке.
При использовании Microsoft Excel для анализа данных вы часто можете оказаться в ситуации, когда вам нужно получить все совпадающие значения для определенного имени, наименования, артикула или какого-либо другого уникального идентификатора. Первое решение, которое приходит на ум, — это использование функции Excel ВПР (VLOOKUP). Но проблема в том, что она может возвращать только одно значение.
Поиск нескольких значений в Excel может быть выполнен с помощью совместного использования ряда функций. Если вы не являетесь экспертом в Excel, не спешите покидать эту страницу. Я постараюсь объяснить логику поиска, чтобы даже новичок мог понять формулы и настроить их для решения подобных задач.
Поиск нескольких позиций в Excel с помощью формулы
Как было сказано ранее, невозможно заставить функцию ВПР Excel возвращать несколько значений. Проблему можно решить, используя следующие функции в формуле массива:
- ЕСЛИ – оценивает условие и возвращает одно значение, если условие выполняется, и другое значение, если условие не выполняется.
- НАИМЕНЬШИЙ– получает N-е наименьшее значение в массиве.
- ИНДЕКС — возвращает элемент массива на основе указанных вами номеров строк и столбцов.
- СТРОКА — возвращает номер строки.
- СТОЛБЕЦ — возвращает номер столбца.
- ЕСЛИОШИБКА – перехватывает ошибки.
Ниже вы найдете несколько примеров таких формул. Их часто называют формулами ВПР нескольких значений, хотя сама функция ВПР здесь не используется. Дело в том, что часто под термином ВПР подразумевают любой поиск в Excel, какими бы формулами и функциями он ни осуществлялся.
Поиск нескольких значений и возврат результатов в столбец
Допустим, у вас есть имена продавцов в столбце А и товары, которые они продали, в столбце В. Таблица содержит несколько записей для каждого продавца. Ваша цель — получить список всех товаров, относящихся к данному человеку. Чтобы это сделать, выполните следующие действия:
- Введите список имен продавцов в какую-нибудь пустую строку того же или другого рабочего листа. В этом примере имена вводятся в ячейки D2:H2:

Совет. Чтобы быстро записать все имеющиеся в списке имена, вы можете использовать эту инструкцию — как получить список уникальных значений в Excel.
- Под именем выберите количество пустых ячеек, равное или превышающее максимально возможное количество совпадений, введите одно из следующих выражений и нажмите
Ctrl + Shift + Enterдля ввода его как формулы массива (в этом случае вы сможете редактировать формулу только сразу во всем диапазоне, где она введена). Или же вы можете записать это в левую верхнюю ячейку, также использовавCtrl + Shift + Enter, а затем перетащить вниз еще на несколько ячеек (в этом случае вы сможете редактировать формулу в каждой ячейке отдельно).
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13; НАИМЕНЬШИЙ(ЕСЛИ(D$2=$A$3:$A$13; СТРОКА($B$3:$B$13)-2;»»); СТРОКА()-2));»»)
или
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13;НАИМЕНЬШИЙ(ЕСЛИ(D$2=$A$3:$A$13;СТРОКА($A$3:$A$13)-МИН(СТРОКА($A$3:$A$13))+1;»»); СТРОКА()-2));»»)
Как видите, первая формула немного компактнее, а вторая более универсальна и требует меньше модификаций (подробнее о синтаксисе и логике мы поговорим чуть дальше).
- Скопируйте формулу в соседние столбцы справа. Для этого перетащите маркер заполнения (небольшой квадрат в правом нижнем углу выбранного диапазона) вправо.
Результат ВПР нескольких значений в столбце будет выглядеть примерно так:

Здесь мы использовали первую формулу:
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13; НАИМЕНЬШИЙ(ЕСЛИ(D$2=$A$3:$A$13; СТРОКА($B$3:$B$13)-2;»»); СТРОКА()-2));»»)
Как это работает.
Это пример использования Excel от среднего до продвинутого уровня, который подразумевает базовые знания формул массива и функций Excel. Итак, разберём пошагово:
- Функция ЕСЛИ
В основе поиска – функция ЕСЛИ, чтобы получить позиции всех вхождений искомого значения в диапазоне поиска: ЕСЛИ(D$2=$A$3:$A$13; СТРОКА($B$3:$B$13) )-2;»»)
ЕСЛИ сравнивает искомое значение (D2) с каждым значением в диапазоне поиска (A3:A13) и, если совпадение найдено, возвращает относительную позицию строки; пустое значение («») в противном случае.
Относительная позиция вычисляется путем вычитания 2 из СТРОКА($B$3:$B$13), чтобы первая позиция с формулой имела порядковый номер 1 (то есть, 3-2=1). Если ваш диапазон вывода начинается со строки 2, тогда вычтите 1 и так далее. Результатом этой операции является массив {1;2;3;4;5;6;7;8;9;10;11}, который поступает в аргумент значение_если_истина функции ЕСЛИ.
Вместо приведенного выше вычисления вы можете использовать следующее выражение:
СТРОКА(столбец_просмотра) — МИН(СТРОКА(столбец_просмотра))+1
Оно возвращает тот же результат, но не требует каких-либо изменений независимо от местоположения возвращаемого столбца. В этом примере это будет СТРОКА($A$3:$A$13)-МИН(СТРОКА($A$3:$A$13))+1.
Итак, на данный момент у вас есть массив, состоящий из чисел (позиций совпадений) и пустых строк (несовпадений). Для ячейки D3 в этом примере у нас есть следующий массив:
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13; НАИМЕНЬШИЙ({1:»»:»»:»»:5:»»:»»:8:»»:»»:»»}; СТРОКА()-2));»»)
Если вы сверитесь с исходными данными, вы увидите, что «Сергей» (значение поиска в D2) появляется на 1- й , 5 -й и 8 -й позициях в диапазоне поиска (A3: A13).
- Функция НАИМЕНЬШИЙ
Затем вступает в действие функция НАИМЕНЬШИЙ(массив; k), чтобы определить, какие совпадения должны быть возвращены в конкретной ячейке.
С уже установленным в предыдущем шаге массивом давайте определим аргумент k , т. е. k-е наименьшее возвращаемое значение. Для этого вы делаете своего рода «инкрементный счетчик» СТРОКА()-n, где «n» — это номер строки первой ячейки формулы минус 1. В этом примере мы ввели формулу в ячейки D3:D7, поэтому СТРОКА()-2 возвращает «1» для ячейки D3 (строка 3 минус 2), «2» для ячейки D4 (строка 4 минус 2) и т. д.
В результате функция НАИМЕНЬШИЙ извлекает первый наименьший элемент массива в ячейку D3, второй наименьший элемент в ячейку D4 и так далее. И это превращает первоначальную длинную и сложную формулу в очень простую, например:
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13;{1});»»)
Совет. Чтобы увидеть значение, вычисленное определенной частью формулы, выделите эту часть в самой формуле и нажмите F9.
- Функция ИНДЕКС
Здесь все просто. Вы используете функцию ИНДЕКС, чтобы вернуть значение элемента массива на основе его номера.
- Функция ЕСЛИОШИБКА
И, наконец, вы оборачиваете формулу в функцию ЕСЛИОШИБКА для обработки возможных ошибок, которые неизбежны, потому что вы не можете знать, сколько совпадений будет возвращено для того или иного искомого значения. Ведь вы копируете формулу в число ячеек явно большее, чем количество возможных совпадений, то есть «с запасом». Чтобы не пугать пользователей кучей ошибок, просто замените их пустой строкой (пустой ячейкой).
Примечание. Обратите внимание на правильное использование абсолютных и относительных ссылок на ячейки в формуле. Все ссылки фиксированы, за исключением ссылки на относительный столбец в искомом значении (D$2), которая должна изменяться в зависимости от относительного положения столбцов, в которые копируется формула, чтобы возвращать совпадения для других имён.
На скриншоте ниже вы можете видеть, как работает вторая формула
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13;НАИМЕНЬШИЙ(ЕСЛИ(D$2=$A$3:$A$13;СТРОКА($A$3:$A$13)-МИН(СТРОКА($A$3:$A$13))+1;»»); СТРОКА()-2));»»)

Обобщив эти два решения, мы получим следующие общие формулы для ВПР нескольких значений в Excel, которые будут выведены в столбец:
Вариант 1 :
=ЕСЛИОШИБКА(ИНДЕКС(диапазон_возвращаемых_значений; НАИМЕНЬШИЙ(ЕСЛИ(искомое_значение = диапазон_искомых_значений; СТРОКА(диапазон_возвращаемых_значений)-m;»»); СТРОКА()-n));»»)
Вариант 2:
=ЕСЛИОШИБКА(ИНДЕКС(диапазон_возвращаемых_значений;НАИМЕНЬШИЙ(ЕСЛИ(искомое_значение = диапазон_искомых_значений;СТРОКА(диапазон_искомых_значений)-МИН(СТРОКА(диапазон_искомых_значений))+1;»»); СТРОКА()-n));»»)
где:
- m — номер строки первой ячейки в возвращаемом диапазоне минус 1.
- n — номер строки первой ячейки с формулой минус 1.
Примечание. В приведенном выше примере и n, и m равны 2, потому что наш диапазон возвращаемых значений начинается, да и сама формула расположена, в строке 3. В ваших таблицах Эксель это вполне могут быть и другие числа.
Поиск нескольких совпадений и возврат результатов в строке
Если вы хотите вернуть несколько найденных значений в строках, а не в столбцах, измените приведенные выше формулы Excel следующим образом:
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13; НАИМЕНЬШИЙ(ЕСЛИ($D3=$A$3:$A$13;СТРОКА($B$3:$B$13)-2;»»); СТОЛБЕЦ()-4));»»)
или
=ЕСЛИОШИБКА(ИНДЕКС($B$3:$B$13;НАИМЕНЬШИЙ(ЕСЛИ($D3=$A$3:$A$13;СТРОКА($A$3:$A$13)-МИН(СТРОКА($A$3:$A$13))+1;»»);СТОЛБЕЦ()-4)); «»)
Как и в предыдущем примере, обе они являются формулами массива, поэтому не забудьте нажать комбинацию Ctrl + Shift + Enter, чтобы записать их правильно.

Формулы работают с той же логикой, что и в предыдущем примере, за исключением того, что вы используете функцию СТОЛБЕЦ вместо СТРОКА. Чтобы определить, какое совпадающее значение должно быть возвращено в конкретной ячейке, используем: СТОЛБЕЦ()-n где n — номер столбца первой ячейки, в которую вводится формула, минус 1. В этом примере результаты выводятся в диапазон E2:H2. Поскольку E является пятым столбцом, n равно 4 (5-1=4).
Примечание. Чтобы формула правильно копировалась вправо и вниз, обратите внимание на ссылки на значения поиска, где используется абсолютный адрес столбца и относительный адрес строки, например $D3.
И вот общие формулы для ВПР в Excel нескольких значений, возвращаемых по строке:
Формула 1 :
=ЕСЛИОШИБКА(ИНДЕКС(диапазон_возвращаемых_значений; НАИМЕНЬШИЙ(ЕСЛИ(искомое_значение = диапазон_искомых_значений; СТРОКА(диапазон_возвращаемых_значений)-m;»»); СТОЛБЕЦ()-n));»»)
Формула 2:
=ЕСЛИОШИБКА(ИНДЕКС(диапазон_возвращаемых_значений;НАИМЕНЬШИЙ(ЕСЛИ(искомое_значение = диапазон_искомых_значений;СТРОКА(диапазон_искомых_значений)-МИН(СТРОКА(диапазон_искомых_значений))+1;»»); СТОЛБЕЦ()-n));»»)
где:
- m — номер строки первой ячейки в возвращаемом диапазоне, минус 1.
- n — номер столбца первой ячейки, в которой записана формула, минус 1.
Поиск нескольких значений на основе нескольких условий
Вы уже знаете, как выполнять поиск нескольких значений в Excel на основе одного условия. Но что, если вы хотите вернуть несколько совпадений сразу на основе двух или более критериев? Продолжая предыдущие примеры – что, если у вас в таблице есть дополнительный столбец «Месяц» и вы хотите получить список всех товаров, проданных конкретным продавцом в определенном месяце?
Если вы знакомы с формулами массивов, то, возможно, помните, что они позволяют использовать знак умножения (*) в качестве логического оператора И. Таким образом, вы можете просто взять выражения, рассмотренные в двух предыдущих примерах, и заставить их проверять несколько условий, как показано ниже.
Как вернуть несколько значений в столбце.
Выведем искомые значения, соответствующие одновременно нескольким условиям, в привычном нам виде – вертикально в одном столбце.
В общем виде это выглядит так:
=ЕСЛИОШИБКА(ИНДЕКС(диапазон_возвращаемых_значений; НАИМЕНЬШИЙ(ЕСЛИ(1=((—(искомое_значение1 = диапазон_искомых_значений1)) * (—(искомое_значение2 = диапазон_искомых_значений2))) ; СТРОКА(диапазон_возвращаемых_значений)-m;»»); СТРОКА()-n));»»)
где:
- m — номер строки первой ячейки в возвращаемом диапазоне, минус 1.
- n — номер строки первой слева ячейки с формулой, минус 1.
Предположим, что список продавцов (диапазон_искомых_значений1) находится в A3:A30, список месяцев (диапазон_искомых_значений2) находится в B3: B30, интересующий продавец (искомое_значение1) указан в ячейке E3, а нужный месяц (искомое_значение2) – в ячейке F3. Тогда формула поиска принимает следующий вид:
=ЕСЛИОШИБКА(ИНДЕКС($C$3:$C$30; НАИМЕНЬШИЙ(ЕСЛИ(1=((—($E$3=$A$3:$A$30))*(—($F$3=$B$3:$B$30))); СТРОКА($C$3:$C$30)-2;»»); СТРОКА()-2));»»)
Таким образом, мы вводим имя в E3, месяц в F3, и получаем список товаров в столбце G:

Как вернуть несколько результатов в строке.
Если вы хотите получить по горизонтали несколько искомых значений на основе нескольких критериев, то есть когда результаты размещаются в одной строке, то используйте следующий общий шаблон:
=ЕСЛИОШИБКА(ИНДЕКС(диапазон_возвращаемых_значений; НАИМЕНЬШИЙ(ЕСЛИ(1=((—(искомое_значение1 = диапазон_искомых_значений1)) * (—(искомое_значение2 = диапазон_искомых_значений2))) ; СТРОКА(диапазон_возвращаемых_значений)-m;»»); СТОЛБЕЦ()-n));»»)
где:
- m — номер строки первой ячейки в возвращаемом диапазоне, минус 1.
- n — номер столбца первой слева ячейки, в которой записана формула, минус 1.
Для нашего примера набора данных формула выглядит следующим образом:
=ЕСЛИОШИБКА(ИНДЕКС($C$3:$C$30; НАИМЕНЬШИЙ(ЕСЛИ(1=((—($E3=$A$3:$A$30))*(—($F3=$B$3:$B$30))); СТРОКА($C$3:$C$30)-2;»»); СТОЛБЕЦ()-6));»»)
И результат ВПР нескольких значений по нескольким условиям может выглядеть так:

Аналогичным образом вы можете выполнять ВПР с тремя, четырьмя и более условиями.
Как это работает?
По сути, формулы для ВПР нескольких значений с несколькими условиями работают с уже знакомой логикой, объясненной в самом первом нашем примере. Единственное отличие состоит в том, что функция ЕСЛИ теперь проверяет несколько условий:
1=((—(искомое_значение1 = диапазон_искомых_значений1)) * (—(искомое_значение2 = диапазон_искомых_значений2)) * …..)
Результатом каждого сравнения (искомое_значение = диапазон_искомых_значений) является массив логических значений ИСТИНА (условие выполнено) и ЛОЖЬ (условие не выполнено). Двойное отрицание (—) переводит логические значения в единицы и нули. А поскольку умножение на ноль всегда дает ноль, в правой части этого равенства у вас будет получаться 1 только для тех элементов, которые удовлетворяют всем указанным вами условиям.
Вы просто сравниваете окончательный массив нулей и единиц с числом 1, чтобы функция СТРОКА вернула порядковые номера строк, удовлетворяющих всем условиям, в противном случае — пустоту.
Напоминание. Все формулы поиска, обсуждаемые в этой статье, являются формулами массива. Таким образом, каждая из них перебирает все элементы массива каждый раз, когда исходные данные изменяются или рабочий лист пересчитывается. На больших листах, содержащих сотни или тысячи позиций, это может значительно замедлить работу Excel.
Как вернуть несколько значений ВПР в одну ячейку
Мы продолжаем работать с набором данных, который использовали в предыдущем примере. Но на этот раз мы хотим добиться другого результата — вместо того, чтобы извлекать несколько совпадений в отдельные ячейки, мы хотим, чтобы они отображались в одной текстовой ячейке, разделенные запятой, пробелом или другим разделителем по вашему выбору.
Используем выражение, которое мы рассматривали чуть выше и которая позволяет получить несколько результатов ВПР с условиями в одной строке:
=ЕСЛИОШИБКА(ИНДЕКС($C$3:$C$30; НАИМЕНЬШИЙ(ЕСЛИ(1=((—($E3=$A$3:$A$30))*(—($F3=$B$3:$B$30))); СТРОКА($C$3:$C$30)-2;»»); СТОЛБЕЦ()-6));»»)
Внесем в нее небольшие изменения.
Чтобы обработать сразу несколько результатов, в функцию СТОЛБЕЦ добавим аргумент – диапазон ячеек, в который мы ранее копировали формулу. То есть, вместо СТОЛБЕЦ() у нас теперь будет СТОЛБЕЦ(G3:K3). Это позволит формуле массива получить сразу несколько номеров столбцов.
Затем применим крайне полезную при работе с текстовыми значениями функцию ОБЪЕДИНИТЬ (доступна в Excel 2019 и более поздних версиях). Она позволит нам объединить несколько текстовых значений, отделив их друг от друга выбранным нами разделителем. К примеру, запятой с пробелом после нее.
Вот что у нас получится:
=ОБЪЕДИНИТЬ(«, «; ИСТИНА; ЕСЛИОШИБКА(ИНДЕКС($C$3:$C$30; НАИМЕНЬШИЙ(ЕСЛИ(1=((—($E3=$A$3:$A$30))*(—($F3=$B$3:$B$30))); СТРОКА($C$3:$C$30)-2;»»); СТОЛБЕЦ(G3:K3)-6));»»))
И видим результат ВПР нескольких значений в одной ячейке на этом скриншоте:

Еще один, более простой вариант, чтобы подтянуть несколько значений и вывести результат в одной ячейке:
=ОБЪЕДИНИТЬ(«, «;ИСТИНА;ЕСЛИ(($A$3:$A$30=E3)*($B$3:$B$30=F3)=1;$C$3:$C$30;»»))
Ее также нужно вводить как формулу массива:

Как найти несколько значений без дубликатов
А если так случится, что в результатах поиска будет несколько одинаковых значений? Пример таких данных вы можете видеть на скриншоте ниже. Естественно, выводить в ячейке несколько дубликатов было бы не совсем хорошо.
Если вы хотите получить в одной ячейке результаты поиска нескольких значений без повторов, попробуйте так:
=ОБЪЕДИНИТЬ(«, «; ИСТИНА; ЕСЛИ(ЕСЛИОШИБКА(ПОИСКПОЗ($C$3:$C$13; ЕСЛИ(E3=$A$3:$A$13; $C$3:$C$13; «»); 0);»»)=ПОИСКПОЗ(СТРОКА($C$3:$C$13); СТРОКА($C$3:$C$13)); $C$3:$C$13; «»))
Вставьте это выражение в нужную ячейку, не забыв завершить ввод комбинацией Ctrl+Shift+Enter, так как это формула массива. Затем можете скопировать вниз по столбцу, чтобы получить данные по другим критериям выбора.

Как видите, мы получили в одной ячейке несколько значений, среди которых нет одинаковых, хотя в исходных данных таковые имеются.
Надеюсь, эти примеры будут вам полезны для поиска сразу нескольких значений в Excel. Благодарю вас за чтение.
 Функция ЕСЛИОШИБКА – примеры формул — В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального…
Функция ЕСЛИОШИБКА – примеры формул — В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального…  5 способов – поиск значения в массиве Excel — В статье предлагается несколько различных формул для выполнения поиска в двумерном массиве значений Excel. Просмотрите эти варианты и выберите наиболее для вас подходящий. При поиске данных в электронных таблицах Excel… Поиск ИНДЕКС ПОИСКПОЗ по нескольким условиям — В статье показано, как выполнять быстрый поиск с несколькими условиями в Excel с помощью ИНДЕКС и ПОИСКПОЗ. Хотя Microsoft Excel предоставляет специальные функции для вертикального и горизонтального поиска, опытные пользователи… ИНДЕКС ПОИСКПОЗ как лучшая альтернатива ВПР — В этом руководстве показано, как использовать ИНДЕКС и ПОИСКПОЗ в Excel и чем они лучше ВПР. В нескольких недавних статьях мы приложили немало усилий, чтобы объяснить основы функции ВПР новичкам и предоставить…
5 способов – поиск значения в массиве Excel — В статье предлагается несколько различных формул для выполнения поиска в двумерном массиве значений Excel. Просмотрите эти варианты и выберите наиболее для вас подходящий. При поиске данных в электронных таблицах Excel… Поиск ИНДЕКС ПОИСКПОЗ по нескольким условиям — В статье показано, как выполнять быстрый поиск с несколькими условиями в Excel с помощью ИНДЕКС и ПОИСКПОЗ. Хотя Microsoft Excel предоставляет специальные функции для вертикального и горизонтального поиска, опытные пользователи… ИНДЕКС ПОИСКПОЗ как лучшая альтернатива ВПР — В этом руководстве показано, как использовать ИНДЕКС и ПОИСКПОЗ в Excel и чем они лучше ВПР. В нескольких недавних статьях мы приложили немало усилий, чтобы объяснить основы функции ВПР новичкам и предоставить…  Поиск в массиве при помощи ПОИСКПОЗ — В этой статье объясняется с примерами формул, как использовать функцию ПОИСКПОЗ в Excel. Также вы узнаете, как улучшить формулы поиска, создав динамическую формулу с функциями ВПР и ПОИСКПОЗ. В Microsoft…
Поиск в массиве при помощи ПОИСКПОЗ — В этой статье объясняется с примерами формул, как использовать функцию ПОИСКПОЗ в Excel. Также вы узнаете, как улучшить формулы поиска, создав динамическую формулу с функциями ВПР и ПОИСКПОЗ. В Microsoft…  Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…
Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…  Как объединить две или несколько таблиц в Excel — В этом руководстве вы найдете некоторые приемы объединения таблиц Excel путем сопоставления данных в одном или нескольких столбцах. Как часто при анализе в Excel вся необходимая информация собирается на одном…
Как объединить две или несколько таблиц в Excel — В этом руководстве вы найдете некоторые приемы объединения таблиц Excel путем сопоставления данных в одном или нескольких столбцах. Как часто при анализе в Excel вся необходимая информация собирается на одном… 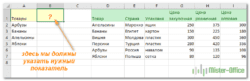 Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.…
Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.…
Предположим, есть строка в которой есть N ссылок, регулярку для поиска ссылки написал, работает.
Можно ли как-то обойтись одним рег. выражением и сразу извлечь все адреса из строки?
Или тут нужно писать цикл и пока строка не кончилась начинать новый поиск с предыдущей позиции?
std::string str = "<html><body><a href="url1">name link1</a><bla bla bla><a href="url2">name link2</a></body></html>";
std::smatch res;
std::regex reg("(<a href=")([\w\s]*)(">)(.*)(</a>)");
std::regex_search(str, res, reg);
std::cout << res[2] << std::endl;
std::regex_search(str, res, reg);
std::cout << res[2] << std::endl;В предыдущих уроках вы узнали, как найти совпадение с конкретными символами, используя разнообразные мета символы и специальные наборы-классы. В этом уроке вы научитесь находить совпадения с несколькими повторе ниями шаблона, представляющего собой символ и набор символов.
Сколько совпадений?
Вы изучили все основные способы сопоставления с шаблоном (т.е. с регулярным выражением), но во всех примерах чувствовалось одно очень серьезное ограничение. Изученными средствами было бы очень сложно записать регулярное выражение, соответствующее адресу электронной почты. Вот основной формат адреса электронной почты:
text@text.text
Используя метасимволы, изученные в предыдущем уроке, можно создать следующее регулярное выражение:
w@w.w
Метасимвол w соответствует всем алфавитно-цифровым символам (плюс символ подчеркивания, который является допустимым в адресе электронной почты). В отличие от точки . символ @ защищать не нужно.
Это — совершенно правильное регулярное выражение, хотя и довольно бесполезное. Оно соответствует адресу электронной почты вроде a@b.c (который, хотя и является синтаксически правильным, очевидно, не может быть правильным (допустимым) адресом на практике). Проблема в том, что w соответствует одному отдельному символу, а вы не можете заранее знать, сколько символов предшествует @. Приведенные ниже адреса электронной почты являются правильными (допустимыми), но они все имеют разное число символов перед @:
b@forta.com ben@forta.com bforta@forta.com
Нужен способ установить соответствие с несколькими символами, и это делается с помощью одного из нескольких специальных метасимволов.
Соответствие с одним или несколькими символами
Чтобы установить соответствие символа (или набора) шаблона с одним или несколькими символами, просто добавьте в конец шаблона символ +. Символ + устанавливает соответствие с одним или несколькими символами (по крайней мере с одним символом; с нулем символов он соответствие не устанавливает). Принимая во внимание, что a соответствует a, выражение a+ соответствует одному или нескольким вхождениям a. Точно так же, учитывая, что диапазон [0-9] соответствует любой цифре, [0-9]+ соответствует последовательности, состоящей из одной или нескольких цифр.
Когда + означает повторение набора, + должен быть помещен вне набора. Поэтому выражение [0-9]+ является правильным и ему может соответствовать непустая последовательность цифр, тогда как выражение [0-9+], хотя и является синтаксически правильным, имеет совсем другое назначение. На самом деле [0-9+] — правильное (допустимое) регулярное выражение, но ему не будет соответствовать последовательность длиной более одной цифры. Это выражение определяет набор от 0 до 9 и символ +; поэтому ему будут соответствовать любая единственная цифра или знак «плюс». Хотя это выражение синтаксически правильно, означает оно совсем не то, что [0-9]+.
Давайте повторно рассмотрим пример с адресами электронной почты, на сей раз используя +, чтобы установить соответствие с одним или несколькими символами:
Текст
Send personal email to ben@forta.com. For questions about a book use support@forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
Регулярное выражение
w+@w+.w+
Результат
Send personal email to ben@forta.com. For questions about a book use support@forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
Шаблон в точности соответствует всем трем адресам. Регулярное выражение с помощью w+ сначала находит один или несколько алфавитно-цифровых символов. Затем устанавливается соответствие с @, после чего снова используется w+, чтобы установить соответствие с одним или несколькими символами, следующими за @. Затем устанавливается соответствие с точкой . (используется защищенная точка .) и еще один шаблон w+, чтобы установить соответствие с концом адреса.
+ — метасимвол. Чтобы найти +, его надо защитить, т.е. задать как +.
Плюс + может также использоваться для того, чтобы установить соответствие с одним или несколькими наборами символов. Чтобы продемонстрировать это, в следующем примере применяется то же самое регулярное выражение, но текст немного отличается:
Текст
Send personal email to ben@forta.com or ben.forta@forta.com. For questions about a book use support@forta.com. If your message is urgent try ben@urgent.forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
Регулярное выражение
w+@w+.w+
Результат
Send personal email to ben@forta.com or ben.forta@forta.com. For questions about a book use support@forta.com. If your message is urgent try ben@urgent.forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
Регулярное выражение соответствовало пяти адресам, но два из них охвачены не полностью. Почему так получилось? Потому что в w+@w+.w+ ничего не предусмотрено для символов . перед @, и потому это выражение допускает только одну точку ., отделяющую две строки после @. Хотя ben.forta@forta.com — совершенно законный адрес электронной почты, регулярное выражение найдет только forta (вместо ben.forta), потому что w соответствует алфавитно-цифровым символам, но не точке . в середине строки текста.
Здесь нужно установить соответствие с w или точкой ., т.е. с набором [w.]. Ниже приведен тот же пример с пересмотренным шаблоном:
Текст
Send personal email to ben@forta.com or ben.forta@forta.com. For questions about a book use support@forta.com. If your message is urgent try ben@urgent.forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
Регулярное выражение
[w.]+@[w.]+.w+
Результат
Send personal email to ben@forta.com or ben.forta@forta.com. For questions about a book use support@forta.com. If your message is urgent try ben@urgent.forta.com. Feel free to send unsolicited email to spam@forta.com (wouldn't it be nice if it were that simple, huh?).
Этим, казалось бы, мы достигли цели. Выражение [w.]+ соответствует одному или нескольким вхождениям любого алфавитно-цифрового символа, символа подчеркивания и точки ., и потому вхождение ben.forta будет найдено. Выражение [w.]+ также используется для строки после @, так что будут установлены соответствия с именами (названиями) более глубоких доменов (или с именем (названием) главного компьютера).
Обратите внимание, что для заключительного соответствия использовалось выражение w+, а не [w.]+. Попытайтесь объяснить, почему? Используйте [w.] в качестве заключительного шаблона и выясните, что случится со вторым, третьим и четвертым совпадением.
Обратите внимание, что точка . в наборе не защищена, и все равно она каким-то образом соответствует . (она была обработана как буквальный символ, а не как метасимвол). Вообще, метасимволы типа . и + рассматриваются как буквальный текст, когда используются в наборах, и поэтому защищать их не нужно. Однако если защитить их, это не причинит вреда. Выражение [w.] функционально эквивалентно [w.].
Поиск нуля или большего количества символов
Плюс + соответствует вхождению одного или нескольких символов. С отсутствующими символами (т.е. с нулевым количеством символов) соответствие установлено не будет, потому что должен быть по крайней мере один символ. Иными словами, в случае использования метасимвола + для установления соответствия необходимо не менее одного символа. Но что же делать, если нужно установить соответствие с необязательными символами, т.е. с такими символами, которые могут отсутствовать вообще (иными словами, с символами, количество которых может равняться нулю)?
Чтобы сделать это, используйте метасимвол *. Метасимвол * используется в точности так, как +; он записывается сразу после символа или набора и будет соответствовать нулю или большему количеству вхождений символа или шаблона. Поэтому шаблон В.* Forta соответствует B Forta, B. Forta, Ben Forta и, конечно же, и другим комбинациям.
Чтобы продемонстрировать использование +, рассмотрим измененную версию примера с адресами электронной почты:
Текст
Hello .ben@forta.com is my email address.
Регулярное выражение
[w.]+@[w.]+.w+
Результат
Hello .ben@forta.com is my email address.
Вспомните, что [w.]+ соответствует одному или нескольким вхождениям алфавитно-цифровых символов и точки ., и потому вхождение .ben было найдено. Однако в предыдущем тексте, очевидно, есть опечатка (лишняя точка в середине текста), но сейчас это к делу не относится. Гораздо большая проблема состоит в том, что хотя точка . является допустимым символом в адресе электронной почты, с нее не может начинаться адрес электронной почты, т.е. она не является допустимым символом в начале адреса электронной почты.
Другими словами, необходимо установить соответствие с алфавитно-цифровым текстом, который может содержать необязательные дополнительные символы. Вот пример:
Текст
Hello .ben@forta.com is my email address.
Регулярное выражение
w+[w.]*@[w.]+.w+
Результат
Hello .ben@forta.com is my email address.
Этот шаблон выглядит довольно сложным (но фактически он таким не является). Давайте рассмотрим его вместе. Выражение w+ соответствует любому алфавитно-цифровому символу, но не точке . (иными словами, он соответствует всем допустимым символам, с которых может начинаться адрес электронной почты). После начальных допустимых символов действительно может следовать точка . и дополнительные символы, хотя фактически они могут и не присутствовать. Выражение [w.]* соответствует нулю или большему количеству вхождений точки . или алфавитно-цифровых символов, а именно это нам и было необходимо.
Помните о том, что метасимвол * всегда относится к некоторому шаблону и делает этот шаблон необязательным. В отличие от +, который требует не менее одного соответствия, * соответствует любому количеству совпадений, если они встретятся, но не требует ни одного совпадения в обязательном порядке.
* является метасимволом. Чтобы установить соответствие со звездочкой * как с обычным символом, ее нужно защитить, т.е. задать как *.
Соответствие с нулем вхождений или с вхождением одного символа
Есть еще один очень полезный метасимвол — ? (знак вопроса). Подобно +, знак вопроса ? отмечает необязательный текст (так что ему будет соответствовать и нулевое количество вхождений шаблона). Но в отличие от знака + знак вопроса ? соответствует только отсутствию вхождений или одному вхождению символа (или набора), но не более чем одному вхождению. Поэтому знак ? очень полезен тогда, когда нужно установить соответствие с одним конкретным необязательным символом в блоке текста.
Рассмотрим следующий пример:
Текст
The URL is http://www.forta.com/, to connect securely use https://www.forta.com/ instead.
Регулярное выражение
http://[w./]+
Результат
The URL is http://www.forta.com/, to connect
securely use https://www.forta.com/ instead.
Чтобы найти URL, используется шаблон http:// (который является буквальным текстом и поэтому соответствует только себе); за ним следует шаблон [w./]+, соответствующий одному или нескольким вхождениям набора, в котором допускаются алфавитно-цифровые символы, точка . и косая черта /. Этот шаблон может найти только первый URL (тот, который начинается с http://), но не второй, который начинается с https://. Причем s* (нуль или больше вхождений s) не является правильным шаблоном, потому что ему соответствовало бы и httpsssss:// (что явно не допустимо).
Решение? Используйте s? как показано в следующем примере:
Текст
The URL is http://www.forta.com/, to connect securely use https://www.forta.com/ instead.
Регулярное выражение
https?://[w./]+
Результат
The URL is http://www.forta.com/, to connect securely use https://www.forta.com/ instead.
Шаблон здесь начинается с https?://. Метасимвол ? указывает, что с предшествующим ему в шаблоне символом (s) должно быть установлено соответствие, если в тексте этого символа нет или если есть одно вхождение этого символа в текст. Другими словами, https?:// соответствует и http://, и https:// (но ничему иному).
Кстати, использование метасимвола ? решает также проблему, рассмотренную в предыдущем уроке. Вспомните пример, в котором использовался шаблон rn, чтобы установить соответствие с концом строки, и я упоминал, что в Unix и Linux нужно использовать n (без r) и что идеальное решение состояло бы в том, чтобы установить соответствие с необязательным r, за которым следует n. Рассмотрим этот пример снова, но на сей раз немного изменим регулярное выражение:
Текст
"101","Ben","Forta" "102","Jim","James" "103","Roberta","Robertson" "104","Bob","Bobson"
Регулярное выражение
[r]?n[r]?n
Результат
"101","Ben","Forta" "102","Jim","James" "103","Roberta","Robertson" "104","Bob","Bobson"
Выражение [r]?n соответствует одному необязательному вхождению r, за которым обязательно следует n.
Обратите внимание, что здесь использовано регулярное выражение [r]?, а не r?. Выражение [r] определяет набор, содержащий единственный метасимвол, т.е. одноэлементный набор, поэтому [r]? фактически функционально идентично r?. Квадратные скобки [ ] обычно используются, чтобы определить набор символов, но некоторые разработчики любят заключать в них даже единственный символ, чтобы предотвратить всякую двусмысленность (выделив шаблон, к которому применяется следующий метасимвол). Если вы используете и [ ], и ?, удостоверьтесь, что ? поместили вне набора. В соответствии с этими правилами правильно писать http[s]?://, a не http[s?]://.
Знак вопроса ? является метасимволом. Чтобы найти ?, нужно защитить его, т.е. задать как ?.
Использование интервалов
Метасимволы +, * и ? помогают решить много проблем с регулярными выражениями, но иногда этих знаков недостаточно. Учтите следующее:
+и*соответствуют неограниченному числу символов. Они не дают возможности установить максимальное число символов, которым может соответствовать предшествующий им шаблон;- минимальное количество вхождений, указываемое с помощью
+,*и?, равно нулю или единице. Эти метасимволы не позволяют установить минимальное количество совпадений явно; - нет способа определить точно количество желаемых совпадений.
Чтобы решить эти проблемы и обеспечивать большую свободу управления повторением совпадений, в регулярных выражениях допускается использование интервалов. Интервалы определяются между символами { и }.
Фигурные скобки { и } — метасимволы и поэтому их нужно защитить с помощью , если необходимо использовать их как буквальный текст. Впрочем, стоит отметить, что многие реализации регулярных выражений способны правильно обработать { и }, даже если они не защищены (поскольку способны определить, когда эти символы используются буквально, а когда они метасимволы). Однако лучше всего не полагаться на это, а защищать эти символы, когда они используются как литералы.
Указание точного количества совпадений
Чтобы определить точное количество совпадений, число совпадений указывают между фигурными скобками { и }. Поэтому {3} означает поиск соответствий с тремя экземплярами предыдущего символа или набора. Если есть только 2 вхождения шаблона, соответствие установлено не будет.
Чтобы продемонстрировать это, давайте повторно рассмотрим пример с RGB-значениями (использованный в уроках 3, «Соответствие набору символов», и 4, «Использование метасимволов»). Как вы помните, RGB-значения определяются как три набора шестнадцатеричных чисел (причем каждый набор состоит из 2 символов). Первый шаблон для поиска RGB-значения имел следующий вид:
#[0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f]
В уроке 4, «Использование метасимволов», мы имели дело с классом POSIX и шаблон выглядел так:
#[[:xdigit:]][[:xdigit:]][[:xdigit:]][[:xdigit:] ][[ixdigit:]][[:xdigit:]]
Проблема с обоими шаблонами состоит в том, что приходится повторять один и тот же набор символов (или класс) шесть раз. Теперь в том же самом примере используем интервал для установления соответствия:
Текст
<BODY BGCOLOR="#336633" TEXT="#FFFFFF"
MARGINWIDTH="0" MARGINHEIGHT="0"
TOPMARGIN="0" LEFTMARGIN="0">
Регулярное выражение
#[[:xdigit:]]{6}
Результат
<BODY BGCOLOR="#336633" TEXT="#FFFFFF" MARGINWIDTH="0" MARGINHEIGHT="0" TOPMARGIN="0" LEFTMARGIN="0">
[:xdigit:] соответствует шестнадцатеричному символу, а {6} повторяет класс POSIX шесть раз. Повторение работает точно так же в выражении
#[0-9A-Fa-f]{6}
Установление соответствия в случае интервала-диапазона
Чтобы определить диапазон количества вхождений (от минимального до максимального значения количества вхождений шаблона), могут использоваться также интервалы. Диапазоны определяются, например, так: {2,4}. (Этот диапазон задает 2 в качестве минимального значения для количества вхождений шаблона и 4 — в качестве максимального значения для количества вхождений шаблона). Пример применения диапазона — регулярное выражение, используемое для проверки правильности формата дат:
Текст
4/8/03 10-6-2004 2/2/2 01-01-01
Регулярное выражение
d{l,2}[-/]d{l,2}[-/]d{2,4}
Результат
4/8/03 10-6-2004 2/2/2 01-01-01
Перечисленные здесь даты — значения, которые пользователи могут вводить в качестве значений полей в формах; эти значения должны представлять собой правильно отформатированные даты. Шаблону d{l,2} соответствует одна или две цифры (такая проверка используется для дня и месяца); d{2,4} соответствует году; [-/] соответствует - или / в качестве разделителя даты. Использованный шаблон нашел три даты, но не нашел 2/2/2 (потому что для года последовательность цифр слишком короткая).
В использованном здесь регулярном выражении наклонная черта / защищена и потому записана как /. Во многих реализациях регулярных выражений защита не нужна, но некоторые синтаксические анализаторы регулярных выражений действительно требуют этого. Поэтому рекомендуется всегда защищать наклонную черту /.
Обратите внимание, что предыдущий шаблон не проверяет правильность дат (недопустимые даты типа 54/67/9999 выдержали бы испытание) — он только проверяет правильность формата (шаг, обычно предпринимаемый непосредственно перед проверкой правильности дат).
Интервалы могут начинаться с 0. Интервал {0,3} соответствует нулю, одному, двум или трем вхождениям шаблона. Как отмечалось ранее, знак вопроса ? находит нуль совпадений или одно совпадение для шаблона, который предшествует этому знаку. Поэтому знак вопроса ? функционально эквивалентен интервалу {0,1}.
Соответствие в случае интервала типа «не менее»
Интервалы используются также для того, чтобы определить минимальное количество совпадений с шаблоном, не указывая при этом максимального. Синтаксис для этого типа интервала подобен синтаксису для диапазона, но в нем опущен максимум. Например, {3,} означает совпадение не менее чем с 3 вхождениями. Иными словами, здесь требуется 3 или больше совпадений.
Следующий пример охватывает большую часть того, что было изучено в этом уроке. Здесь регулярное выражение используется для того, чтобы определить местонахождение всех заказов, оцененных в 100 или больше долларов ($):
Текст
1001: $496.80 1002: $1290.69 1003: $26.43 1004: $613.42 1005: $7.61 1006: $414.90 1007: $25.00
Регулярное выражение
d+: $d{3,}.d{2}
Результат
1001: $496.80 1002: $1290.69 1003: $26.43 1004: $613.42 1005: $7.61 1006: $414.90 1007: $25.00
Предыдущий текст — сообщение, где указаны номера заказов, за которыми следует стоимость соответствующего заказа. Регулярное выражение сначала использует шаблон d+:, чтобы найти порядковый номер заказа (если этот шаблон опустить, то, когда будет найдена стоимость, соответствие будет установлено только с ней, а не со всей строкой, включающей также и порядковый номер заказа). Чтобы установить соответствие со стоимостью, используется шаблон $d{3,}.d{2}. Выражение $ соответствует $, d{3,} соответствует числам, содержащим не менее трех цифр (и таким образом стоимости не менее 100$), . соответствует ., и, наконец, d{2} соответствует тем двум цифрам, которые следуют после десятичной точки. Весь шаблон правильно устанавливает соответствие с четырьмя из семи заказов.
Будьте внимательны при использовании этой формы интервала. Если опустить запятую ,, то поиск будет происходить иначе: будет попытка установить соответствие с тем количеством вхождений шаблона, которое указано в фигурных скобках.
Знак + функционально эквивалентен {1,}.
Предотвращение лишних соответствий
Метасимвол ? ограничивает количество совпадений — их может быть нуль или только одно. То же самое относится и к совпадениям, задаваемым интервалами, если в них указаны точные количества совпадений или диапазоны. Однако другие формы повторения шаблона, описанные в этом уроке, могут соответствовать неограниченному количеству совпадений — иногда их слишком много.
Все примеры к настоящему моменту были тщательно отобраны так, чтобы не столкнуться со слишком большим количеством соответствий. Но теперь пришло время рассмотреть следующий пример. Выбранный для примера текст является частью Web-страницы и содержит текст со встроенными HTML-тегами <B>. Регулярное выражение должно найти любой текст внутри тегов <B> (это может потребоваться при замене форматирования). Вот пример:
Текст
This offer is not available to customers living in <B>AK</B> and <B>HI</B>.
Регулярное выражение
<[Bb]>.*</[Bb]>
Результат
This offer is not available to customers living in <B>AK</B> and <B>HI</B>.
Выражение <[Bb]> соответствует открывающему тегу <B> (на верхнем или нижнем регистре), а соответствует закрывающему тегу </B> (также на верхнем или нижнем регистре). Однако вместо двух совпадений было найдено только одно, причем .* соответствовало всему, что было расположено после первого <B> до последнего тега </B>, так что фактически был найден текст AK</B> and <B>HI. Найденный текст содержит текст, который нужно было найти, но помимо него он включает также и другие вхождения тегов.
Причина этого состоит в том, что метасимволы типа * и + являются жадными; т.е. они ищут самое длинное возможное соответствие, а не наименьшее. Из-за этого кажется, что соответствие начинается не с начала, а с конца текста и продолжается назад (т.е. в направлении к началу), пока не будет найдено следующее соответствие. Это делается преднамеренно — кванторы по природе своей жадны.
Но что, если вам не нужно жадное соответствие? Решение состоит в том, чтобы использовать ленивые версии этих кванторов (они называются ленивыми, потому что устанавливают соответствие с наименьшим (а не наибольшим) возможным количеством символов). Ленивые кванторы определяются путем добавления в конец ? к используемому квантору, причем для каждого из жадных кванторов имеется ленивый эквивалент (табл. 5.1).
Таблица 5.1. Жадные и ленивые кванторы
| Жадный | Ленивый |
|---|---|
* |
*? |
+ |
+? |
? |
?? |
{n} |
{n}? |
{n,} |
{n,}? |
{n,m} |
{n,m}? |
Квантор *? — ленивая версия *, так что давайте повторно рассмотрим наш пример, на сей раз используя *?:
Текст
This offer is not available to customers living in <B>AK</B> and <B>HI</B>.
Регулярное выражение
<[Bb]>.*?</[Bb]>
Результат
This offer is not available to customers living in <B>AK</B> and <B>HI</B>.
Используя ленивый квантор *?, мы добились правильного результата. Первый раз с ним было сопоставлено только вхождение <B>AK</B>, и совершенно независимо от него было найдено вхождение <B>HI</B>.
В большинстве примеров в этой книге для простоты используются жадные кванторы. Однако не стесняйтесь применять ленивые кванторы, если именно они вам необходимы.
Резюме
Реальная мощь шаблонов из регулярных выражений становится очевидной именно при использовании повторения совпадений. В этом уроке введены кванторы + (соответствует одному или большему количеству совпадений), * (нуль или больше совпадений), ? (нуль или одно совпадение). Эти кванторы можно рассматривать как способы найти повторяющиеся совпадения. Для более тонкого управления могут использоваться интервалы, так как они позволяют определить точное количество повторений или же минимальное и максимальное их количество. Жадные кванторы могут найти слишком много соответствий; чтобы избежать этого, используйте ленивые кванторы.
Автор оригинала: Chris.
Проблема формулировки : Учитывая более длинную строку и более короткую строку. Как найти все вхождения более короткой строки в дольше?
Рассмотрим следующий пример:
- Длинная струна :
Финансовы изучают Python с Finxter ' - Короче строка:
'Finxter' - Результат :
['Finxter', 'finxter']
Необязательно, вы также можете распечатать позиции, где возникают более короткая строка в более длительной строке:
- Результат 2 :
[(0, 'finxter'), (27, 'finxter')]]
Метод 1: Regex Re.finditer ()
Чтобы получить все вхождения шаблона в данной строке, вы можете использовать метод регулярного выражения Re.finditer (шаблон, строка) Отказ Результатом является неразмерный для Соответствующие объекты -Вы можете получить индексы совпадения с использованием Match.Start () и Match.end () Функции.
import re
s = 'Finxters learn Python with Finxter'
pattern = 'Finxter'
# Method 1: re.finditer
for m in re.finditer(pattern, s):
print(pattern, 'matched from position', m.start(), 'to', m.end())
Вывод:
Finxter matched from position 0 to 7 Finxter matched from position 27 to 34
Метод 2: Re.Finditer () + Понимание списка
Чтобы получить шаблон строки, начать индекс и завершить индекс матча на Список кортежи Вы можете использовать следующие одноклассник на основе Понимание списка : [(Pattern, M.start (), M.end ()) для M в Re.Finditer (Pattern, S)] Отказ
import re s = 'Finxters learn Python with Finxter' pattern = 'Finxter' # Method 2: re.finditer + list comprehension l = [(pattern, m.start(), m.end())for m in re.finditer(pattern, s)] print(l)
Вывод:
[('Finxter', 0, 7), ('Finxter', 27, 34)]
Способ 3: NO-REGEX, рекурсивное, перекрытие
Следующий метод основан на Рекурсия И это не требует внешней библиотеки. Идея состоит в том, чтобы неоднократно находить следующее возникновение шаблона подстроки в строке и вызовов один и тот же метод рекурсивно на более короткой движущейся строке начальной позиции вправо, пока не найдено совпадение. Все найденные спички подстроки накапливаются в переменной ACC Как вы проходите через рекурсионные звонки.
s = 'Finxters learn Python with Finxter'
pattern = 'Finxter'
# Method 3: recursive, without regex
def find_all(pattern, # string pattern
string, # string to be searched
start=0, # ignore everything before start
acc=[]): # All occurrences of string pattern in string
# Find next occurrence of pattern in string
i = string.find(pattern, start)
if i == -1:
# Pattern not found in remaining string
return acc
return find_all(pattern, string, start = i+1,
acc = acc + [(pattern, i)]) # Pass new list with found pattern
l = find_all(pattern, s)
print(l)
Вывод:
[('Finxter', 0), ('Finxter', 27)]
Обратите внимание, что этот метод также находит перекрывающиеся совпадения – в отличие от методов Regex, которые потребляют все частично сопоставленные подстроки.
Куда пойти отсюда?
Достаточно теории, давайте познакомимся!
Чтобы стать успешным в кодировке, вам нужно выйти туда и решать реальные проблемы для реальных людей. Вот как вы можете легко стать шестифункциональным тренером. И вот как вы польские навыки, которые вам действительно нужны на практике. В конце концов, что такое использование теории обучения, что никто никогда не нуждается?
Практические проекты – это то, как вы обостряете вашу пилу в кодировке!
Вы хотите стать мастером кода, сосредоточившись на практических кодовых проектах, которые фактически зарабатывают вам деньги и решают проблемы для людей?
Затем станьте питоном независимым разработчиком! Это лучший способ приближения к задаче улучшения ваших навыков Python – даже если вы являетесь полным новичком.
Присоединяйтесь к моему бесплатным вебинаре «Как создать свой навык высокого дохода Python» и посмотреть, как я вырос на моем кодированном бизнесе в Интернете и как вы можете, слишком от комфорта вашего собственного дома.
Присоединяйтесь к свободному вебинару сейчас!
Ресурсы : https://stackoverflow.com/questions/3873361/finding-multiple-occurrences-of-a-string-within-a-string-in-nypython.
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python One-listers (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.