Ниже представлена таблица значений критических точек распределения χ2 (хи-квадрат) критерия Пирсона, широко используемые в задачах математической статистики, таких как построение доверительных интервалов,
проверка статистических гипотез и непараметрическое оценивание.
|
Число степеней свободы k |
Уровень значимости α | |||||
| 0,01 | 0,025 | 0,05 | 0,95 | 0,975 | 0,99 | |
| 1 | 6,6 | 5 | 3,8 | 0,0039 | 0,00098 | 0,00016 |
| 2 | 9,2 | 7,4 | 6 | 0,103 | 0,051 | 0,02 |
| 3 | 11,3 | 9,4 | 7,8 | 0,352 | 0,216 | 0,115 |
| 4 | 13,3 | 11,1 | 9,5 | 0,711 | 0,484 | 0,297 |
| 5 | 15,1 | 12,8 | 11,1 | 1,15 | 0,831 | 0,554 |
| 6 | 16,8 | 14,4 | 12,6 | 1,64 | 1,24 | 0,872 |
| 7 | 18,5 | 16 | 14,1 | 2,17 | 1,69 | 1,24 |
| 8 | 20,1 | 17,5 | 15,5 | 2,73 | 2,18 | 1,65 |
| 9 | 21,7 | 19 | 16,9 | 3,33 | 2,7 | 2,09 |
| 10 | 23,2 | 20,5 | 18,3 | 3,94 | 3,25 | 2,56 |
| 11 | 24,7 | 21,9 | 19,7 | 4,57 | 3,82 | 3,05 |
| 12 | 26,2 | 23,3 | 21 ,0 | 5,23 | 4,4 | 3,57 |
| 13 | 27,7 | 24,7 | 22,4 | 5,89 | 5,01 | 4,11 |
| 14 | 29,1 | 26,1 | 23,7 | 6,57 | 5,63 | 4,66 |
| 15 | 30,6 | 27,5 | 25 | 7,26 | 6,26 | 5,23 |
| 16 | 32 | 28,8 | 26,3 | 7,96 | 6,91 | 5,81 |
| 17 | 33,4 | 30,2 | 27,6 | 8,67 | 7,56 | 6,41 |
| 18 | 34,8 | 31,5 | 28,9 | 9,39 | 8,23 | 7,01 |
| 19 | 36,2 | 32,9 | 30,1 | 10,1 | 8,91 | 7,63 |
| 20 | 37,6 | 34,2 | 31,4 | 10,9 | 9,59 | 8,26 |
| 21 | 38,9 | 35,5 | 32,7 | 11,6 | 10,3 | 8,9 |
| 22 | 40,3 | 36,8 | 33,9 | 12,3 | 11 | 9,54 |
| 23 | 41,6 | 38,1 | 35,2 | 13,1 | 11,7 | 10,2 |
| 24 | 43 | 39,4 | 36,4 | 13,8 | 12,4 | 10,9 |
| 25 | 44,3 | 40,6 | 37,7 | 14,6 | 13,1 | 11,5 |
| 26 | 45,6 | 41,9 | 38,9 | 15,4 | 13,8 | 12,2 |
| 27 | 47 | 43,2 | 40,1 | 16,2 | 14,6 | 12,9 |
| 28 | 48,3 | 44,5 | 41,3 | 16,9 | 15,3 | 13,6 |
| 29 | 49,6 | 45,7 | 42,6 | 17,7 | 16 | 14,3 |
| 30 | 50,9 | 47 | 43,8 | 18,5 | 16,8 | 15 |
Пример решения задачи
Задача
Имеется
три независимых реализации нормальной случайной величины: 0.6, 3.4, 2.0.
Проверить
гипотезу
: дисперсия равна
10.0.
Используются
таблицы распределения хи-квадрат.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Решение
Вычислим
среднее и
исправленную дисперсию:
Для
того, чтобы при заданном уровне значимости
проверить нулевую гипотезу
о равенстве неизвестной генеральной дисперсии
гипотетическому значению
при конкурирующей гипотезе
вычисляем наблюдаемое значение критерия:
При
уровне значимости
находим:
— нет
оснований отвергнуть нулевую гипотезу
В этом руководстве объясняется, как читать и интерпретировать таблицу распределения хи-квадрат .
Что такое таблица распределения хи-квадрат?
Таблица распределения хи-квадрат — это таблица, которая показывает критические значения распределения хи-квадрат. Чтобы использовать таблицу распределения хи-квадрат, вам нужно знать только два значения:
- Степени свободы для теста хи-квадрат
- Альфа-уровень для теста (обычно выбираются 0,01, 0,05 и 0,10).
На следующем изображении показаны первые 20 строк таблицы распределения хи-квадрат со степенями свободы в левой части таблицы и альфа-уровнями в верхней части таблицы:
Примечание. Полную таблицу распределения хи-квадрата с большим количеством степеней свободы вы можете найти здесь .

Критические значения в таблице часто сравнивают со статистикой теста Хи-квадрат. Если статистика теста больше критического значения, найденного в таблице, то вы можете отклонить нулевую гипотезу теста хи-квадрат и сделать вывод, что результаты теста статистически значимы.
Примеры использования таблицы распределения хи-квадрат
Мы продемонстрируем, как использовать таблицу распределения хи-квадрат со следующими тремя типами тестов хи-квадрат:
- Тест хи-квадрат на независимость
- Тест хи-квадрат на качество подгонки
- Тест хи-квадрат на однородность
Тест хи-квадрат на независимость
Мы используем тест Хи-квадрат на независимость , когда хотим проверить, существует ли значительная связь между двумя категориальными переменными.
Пример: предположим, мы хотим знать, связан ли пол с предпочтениями политической партии. Мы берем простую случайную выборку из 500 избирателей и опрашиваем их об их предпочтениях в отношении политических партий. Используя уровень значимости 0,05, мы проводим тест хи-квадрат на независимость, чтобы определить, связан ли пол с предпочтениями политической партии. В следующей таблице представлены результаты опроса:

Оказывается, статистика теста для этого теста хи-квадрат составляет 0,864.
Затем мы можем найти критическое значение для теста в таблице распределения хи-квадрат. Степени свободы равны (#rows-1) * (#columns-1) = (2-1) * (3-1) = 2, и проблема подсказала нам, что мы должны использовать альфа-уровень 0,05. Таким образом, по таблице распределения хи-квадрат критическое значение теста равно 5,991 .

Поскольку наша тестовая статистика меньше нашего критического значения, мы не можем отвергнуть нулевую гипотезу. Это означает, что у нас нет достаточных доказательств, чтобы утверждать, что существует связь между полом и предпочтениями политических партий.
Тест хи-квадрат на качество подгонки
Мы используем критерий пригодности хи-квадрат , когда хотим проверить, следует ли категориальная переменная гипотетическому распределению.
Пример: Владелец магазина утверждает, что 30 % всех его покупателей на выходных посещают его в пятницу, 50 % — в субботу и 20 % — в воскресенье. Независимый исследователь посещает магазин в случайные выходные и обнаруживает, что 91 покупатель посещает его в пятницу, 104 — в субботу и 65 — в воскресенье. Используя уровень значимости 0,10, мы проводим критерий хи-квадрат на соответствие, чтобы определить, согласуются ли данные с заявлением владельца магазина.
В этом случае тестовая статистика оказывается равной 10,616.
Затем мы можем найти критическое значение для теста в таблице распределения хи-квадрат. Степени свободы равны (#outcomes-1) = 3-1 = 2, и задача подсказала нам, что мы должны использовать альфа-уровень 0,10. Таким образом, по таблице распределения хи-квадрат критическое значение теста равно 4,605 .

Поскольку наша тестовая статистика больше нашего критического значения, мы отклоняем нулевую гипотезу. Это означает, что у нас есть достаточно доказательств, чтобы сказать, что истинное распределение покупателей, заходящих в этот магазин по выходным, не равно 30% в пятницу, 50% в субботу и 20% в воскресенье.
Тест хи-квадрат на однородность
Мы используем тест хи-квадрат на однородность , когда хотим формально проверить, есть ли разница в пропорциях между несколькими группами.
Пример. Баскетбольный тренировочный центр хочет проверить, улучшат ли две новые тренировочные программы долю игроков, прошедших сложный тест по стрельбе. 172 игрока случайным образом распределяются по программе 1, 173 — по программе 2 и 215 — по текущей программе. После использования тренировочных программ в течение одного месяца игроки проходят тест по стрельбе. В таблице ниже показано количество игроков, прошедших тест на стрельбу, в зависимости от того, какую программу они использовали.

Используя уровень значимости 0,05, мы проводим критерий хи-квадрат на однородность, чтобы определить, является ли процент сдачи одинаковым или для каждой тренировочной программы.
Оказывается, статистика теста для этого теста хи-квадрат равна 4,208.
Затем мы можем найти критическое значение для теста в таблице распределения хи-квадрат. Степени свободы равны (#rows-1) * (#columns-1) = (2-1) * (3-1) = 2, и проблема подсказала нам, что мы должны использовать альфа-уровень 0,05. Таким образом, по таблице распределения хи-квадрат критическое значение теста равно 5,991 .
Поскольку наша тестовая статистика меньше нашего критического значения, мы не можем отвергнуть нулевую гипотезу. Это означает, что у нас нет достаточных доказательств того, что три программы обучения дают разные результаты.
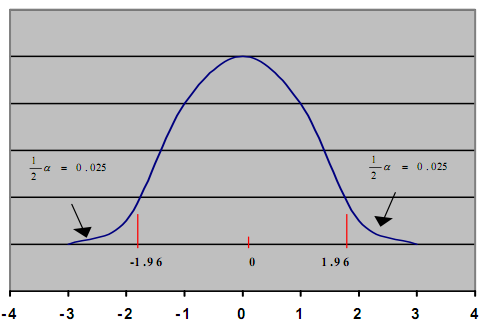
Рисунок 2
Из
рис.2 мы видим, что область допустимых
значений для уровня значимости 0,05 будет
находиться от –1,96 до +1,96. То есть если
значение, полученное по формуле
z-критерия,
попадет в промежуток от –1,96 до +1,96, мы
принимаем нулевую гипотезу, если нет —
отвергаем. Также мы видим, что область
«ошибочного принятия верной гипотезы»
(хвосты распределения больше +1,96 и меньше
–1,96) разделена на две части. Это говорит
о том, что критерий двусторонний. Такой
критерий обычно используется, когда мы
проверяем двустороннюю гипотезу. Если
же мы имеем дело с односторонней
гипотезой, (а21)
то следует использовать односторонний
критерий. Графически это выглядит
следующим образом:
Нормальное распределение: критическая область для уровня значимости 0.05 (односторонний критерий)
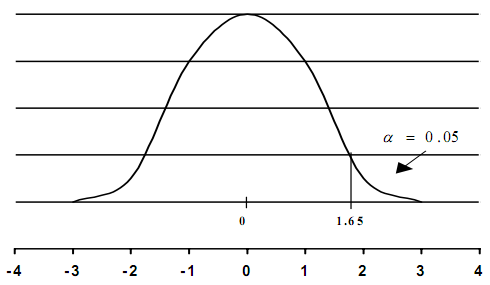
Рисунок 3
Чтобы
найти значение критической точки для
рис. 3 в таблице стандартизированного
нормального распределения, надо
пользоваться уровнем значимости
![]()
.
Соответственно,
если, например, мы хотим узнать критическую
точку для одностороннего критерия при
уровне значимости 0,01, мы должны искать
в таблице критическую точку для уровня
значимости 0,02 (она будет равна 2,33) и т.д.
Распределение
Стьюдента.
Итак,
когда мы применяем t-критерий,
то пользуемся распределением Стьюдента.
Значение критической точки распределения
Стьюдента зависит не только от выбранного
нами уровня значимости, но также, как
было уже отмечено выше, от числа степеней
свободы, обычно обозначаемого df.
Формула,
по которой можно определить число
степеней свободы для конкретных двух
независимых выборок выглядит следующим
образом: где
![]()
и
![]()
объем
первой и второй выборок соответственно.
Допустим число
степеней свободы у нас равно 9. Тогда
для уровня значимости 0,05 графически
критическая область будет выглядеть,
как показано ниже:
Распределение Стьюдента: критическая область для уровня значимости 0.05 и числа степеней свободы равного 9. (двусторонний критерий)
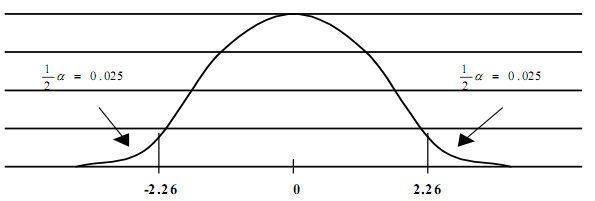
Рисунок 4
Из
рис.4 мы видим, что область допустимых
значений для уровня значимости 0,05 в
данном случае будет находиться от –2,26
до +2,26. То есть если значение, полученное
по формуле t-критерия,
попадет в промежуток от –2,26 до +2,26, мы
принимаем нулевую гипотезу, если нет –
отвергаем.
Если мы хотим
построить график для одностороннего
уровня значимости, следует действовать
по той же схеме, что и для нормального
распределения.
Итак, для того,
чтобы определить критическую точку нам
надо, прежде всего, задать уровень
значимости или вероятность отвергнуть
нулевую гипотезу, когда она верна. Если
мы отвергаем верную гипотезу, то совершаем
ошибку. Но мы также можем совершить и
другую ошибку: принять неверную гипотезу.
Такого рода ошибки называются ошибками
первого и второго рода соответственно.
Проверка любой
гипотезы может иметь четыре исхода,
которые обычно представляют в виде
следующей таблицы:
Таблица №3.
|
Нулевая гипотеза |
Нулевая гипотеза |
|
|
Нулевая гипотеза |
Правильное |
Ошибка второго |
|
Нулевая гипотеза |
Ошибка первого |
Правильное |
Таким
образом, нельзя сказать, что чем меньше
мы возьмем уровень значимости ,
тем
более вероятно правильное решение и
тем меньше возможность ошибиться. Если
мы зададим максимально маленький уровень
значимости ,
то
практически исключим вероятность ошибки
первого рода, но не ошибки второго рода.
Достаточно
сложно определить вероятность совершения
ошибки второго рода, обозначаемой
греческой буквой .
Вероятность
не отвергнуть ложную гипотезу зависит
от многих факторов, включая следующие:
-
истинного
значения изучаемого параметра, то есть
того, которое мы получили бы, опросив
всю генеральную совокупность; -
величины
уровня значимости ; -
от того, односторонний
или двусторонний у нас критерий; -
от дисперсии
генеральной совокупности; -
от объема нашей
выборки.
Очевидно,
что истинного значения изучаемого
параметра мы никогда не знаем (иначе,
зачем бы мы проводили исследование) да
и знание дисперсии генеральной
совокупности случай не такой уж частый.
Поэтому
мы
посчитать не можем. Но зато можем
постараться снизить вероятность ошибки
второго рода, зная некоторые ее свойства.
Вероятность
совершить ошибку второго рода будет
уменьшаться:
-
с
увеличением разницы между истинным и
гипотетическим (тем, которое мы получили)
параметрами; -
с
увеличением уровня значимости ; -
с увеличением
размера выборки; -
с
уменьшением стандартного отклонения
от среднего генеральной совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
До конца XIX века нормальное распределение считалась всеобщим законом вариации данных. Однако К. Пирсон заметил, что эмпирические частоты могут сильно отличаться от нормального распределения. Встал вопрос, как это доказать. Требовалось не только графическое сопоставление, которое имеет субъективный характер, но и строгое количественное обоснование.
Так был изобретен критерий χ2 (хи квадрат), который проверяет значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Это произошло в далеком 1900 году, однако критерий и сегодня на ходу. Более того, его приспособили для решения широкого круга задач. Прежде всего, это анализ категориальных данных, т.е. таких, которые выражаются не количеством, а принадлежностью к какой-то категории. Например, класс автомобиля, пол участника эксперимента, вид растения и т.д. К таким данным нельзя применять математические операции вроде сложения и умножения, для них можно только подсчитать частоты.
Наблюдаемые частоты обозначим О (Observed), ожидаемые – E (Expected). В качестве примера возьмем результат 60-кратного бросания игральной кости. Если она симметрична и однородна, вероятность выпадения любой стороны равна 1/6 и, следовательно, ожидаемое количество выпадения каждой из сторон равна 10 (1/6∙60). Наблюдаемые и ожидаемые частоты запишем в таблицу и нарисуем гистограмму.

Нулевая гипотеза заключается в том, что частоты согласованы, то есть фактические данные не противоречат ожидаемым. Альтернативная гипотеза – отклонения в частотах выходят за рамки случайных колебаний, расхождения статистически значимы. Чтобы сделать строгий вывод, нам потребуется.
- Обобщающая мера расхождения между наблюдаемыми и ожидаемыми частотами.
- Распределение этой меры при справедливости гипотезы о том, что различий нет.
Начнем с расстояния между частотами. Если взять просто разницу О — E, то такая мера будет зависеть от масштаба данных (частот). Например, 20 — 5 =15 и 1020 – 1005 = 15. В обоих случаях разница составляет 15. Но в первом случае ожидаемые частоты в 3 раза меньше наблюдаемых, а во втором случае – лишь на 1,5%. Нужна относительная мера, не зависящая от масштаба.
Обратим внимание на следующие факты. В общем случае количество категорий, по которым измеряются частоты, может быть гораздо больше, поэтому вероятность того, что отдельно взятое наблюдение попадет в ту или иную категорию, довольно мала. Раз так, то, распределение такой случайной величины будет подчинятся закону редких событий, известному под названием закон Пуассона. В законе Пуассона, как известно, значение математического ожидания и дисперсии совпадают (параметр λ). Значит, ожидаемая частота для некоторой категории номинальной переменной Ei будет являться одновременное и ее дисперсией. Далее, закон Пуассона при большом количестве наблюдений стремится к нормальному. Соединяя эти два факта, получаем, что, если гипотеза о согласии наблюдаемых и ожидаемых частот верна, то, при большом количестве наблюдений, выражение
![]()
имеет стандартное нормальное распределение.
Важно помнить, что нормальность будет проявляться только при достаточно больших частотах. В статистике принято считать, что общее количество наблюдений (сумма частот) должна быть не менее 50 и ожидаемая частота в каждой группе должна быть не менее 5. Только в этом случае величина, показанная выше, имеет стандартное нормальное распределение. Предположим, что это условие выполнено.
У стандартного нормального распределения почти все значение находятся в пределах ±3 (правило трех сигм). Таким образом, мы получили относительную разность в частотах для одной группы. Нам нужна обобщающая мера. Просто сложить все отклонения нельзя – получим 0 (догадайтесь почему). Пирсон предложил сложить квадраты этих отклонений.
![]()
Это и есть статистика для критерия Хи-квадрат Пирсона. Если частоты действительно соответствуют ожидаемым, то значение статистики Хи-квадрат будет относительно не большим (отклонения находятся близко к нулю). Большое значение статистики свидетельствует в пользу существенных различий между частотами.
«Большой» статистика Хи-квадрат становится тогда, когда появление наблюдаемого или еще большего значения становится маловероятным. И чтобы рассчитать такую вероятность, необходимо знать распределение статистики Хи-квадрат при многократном повторении эксперимента, когда гипотеза о согласии частот верна.
Как нетрудно заметить, величина хи-квадрат также зависит от количества слагаемых. Чем больше слагаемых, тем больше ожидается значение статистики, ведь каждое слагаемое вносит свой вклад в общую сумму. Следовательно, для каждого количества независимых слагаемых, будет собственное распределение. Получается, что χ2 – это целое семейство распределений.
И здесь мы подошли к одному щекотливому моменту. Что такое число независимых слагаемых? Вроде как любое слагаемое (т.е. отклонение) независимо. К. Пирсон тоже так думал, но оказался неправ. На самом деле число независимых слагаемых будет на один меньше, чем количество групп номинальной переменной n. Почему? Потому что, если мы имеем выборку, по которой уже посчитана сумма частот, то одну из частот всегда можно определить, как разность общего количества и суммой всех остальных. Отсюда и вариация будет несколько меньше. Данный факт Рональд Фишер заметил лет через 20 после разработки Пирсоном своего критерия. Даже таблицы пришлось переделывать.
По этому поводу Фишер ввел в статистику новое понятие – степень свободы (degrees of freedom), которое и представляет собой количество независимых слагаемых в сумме. Понятие степеней свободы имеет математическое объяснение и проявляется только в распределениях, связанных с нормальным (Стьюдента, Фишера-Снедекора и сам Хи-квадрат).
Чтобы лучше уловить смысл степеней свободы, обратимся к физическому аналогу. Представим точку, свободно движущуюся в пространстве. Она имеет 3 степени свободы, т.к. может перемещаться в любом направлении трехмерного пространства. Если точка движется по какой-либо поверхности, то у нее уже две степени свободы (вперед-назад, вправо-влево), хотя и продолжает находиться в трехмерном пространстве. Точка, перемещающаяся по пружине, снова находится в трехмерном пространстве, но имеет лишь одну степень свободы, т.к. может двигаться либо вперед, либо назад. Как видно, пространство, где находится объект, не всегда соответствует реальной свободе перемещения.
Примерно также распределение статистики может зависеть от меньшего количества элементов, чем нужно слагаемых для его расчета. В общем случае количество степеней свободы меньше наблюдений на число имеющихся зависимостей.
Таким образом, распределение хи квадрат (χ2) – это семейство распределений, каждое из которых зависит от параметра степеней свободы. Формальное определение следующее. Распределение χ2 (хи-квадрат) с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Далее можно было бы перейти к самой формуле, по которой вычисляется функция распределения хи-квадрат, но, к счастью, все давно подсчитано за нас. Чтобы получить интересующую вероятность, можно воспользоваться либо соответствующей статистической таблицей, либо готовой функцией в Excel.
Интересно посмотреть, как меняется форма распределения хи-квадрат в зависимости от количества степеней свободы.

С увеличением степеней свободы распределение хи-квадрат стремится к нормальному. Это объясняется действием центральной предельной теоремы, согласно которой сумма большого количества независимых случайных величин имеет нормальное распределение. Про квадраты там ничего не сказано )).
Проверка гипотезы по критерию Хи квадрат Пирсона
Вот мы и подошли к проверке гипотез по методу хи-квадрат. В целом техника остается прежней. Выдвигается нулевая гипотеза о том, что наблюдаемые частоты соответствуют ожидаемым (т.е. между ними нет разницы, т.к. они взяты из той же генеральной совокупности). Если этот так, то разброс будет относительно небольшим, в пределах случайных колебаний. Меру разброса определяют по статистике Хи-квадрат. Далее либо полученную статистику сравнивают с критическим значением (для соответствующего уровня значимости и степеней свободы), либо, что более правильно, рассчитывают наблюдаемый p-value, т.е. вероятность получить такое или еще больше значение статистики при справедливости нулевой гипотезы.
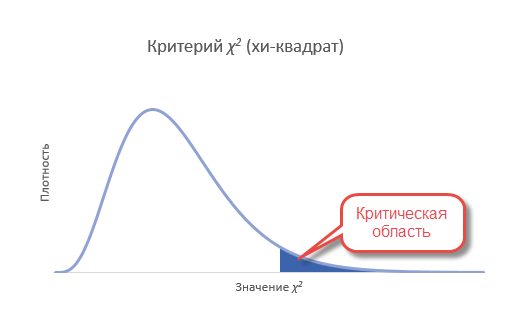
Т.к. нас интересует согласие частот, то отклонение гипотезы произойдет, когда статистика окажется больше критического уровня. Т.е. критерий является односторонним. Однако иногда (иногда) требуется проверить левостороннюю гипотезу. Например, когда эмпирические данные уж оооочень сильно похожи на теоретические. Тогда критерий может попасть в маловероятную область, но уже слева. Дело в том, что в естественных условиях, маловероятно получить частоты, практически совпадающие с теоретическими. Всегда есть некоторая случайность, которая дает погрешность. А вот если такой погрешности нет, то, возможно, данные были сфальсифицированы. Но все же обычно проверяют правостороннюю гипотезу.
Вернемся к задаче с игральной костью. Рассчитаем по имеющимся данным значение статистики критерия хи-квадрат.
![]()
Теперь найдем критическое значение при 5-ти степенях свободы (k) и уровне значимости 0,05 (α) по таблице критических значений распределения хи квадрат.

То есть квантиль 0,05 хи квадрат распределения (правый хвост) с 5-ю степенями свободы χ20,05; 5 = 11,1.
Сравним фактическое и табличное значение. 3,4 (χ2) < 11,1 (χ20,05; 5). Расчетный значение оказалось меньшим, значит гипотеза о равенстве (согласии) частот не отклоняется. На рисунке ситуация выглядит вот так.

Если бы расчетное значение попало в критическую область, то нулевая гипотеза была бы отклонена.
Более правильным будет рассчитать еще и p-value. Для этого нужно в таблице найти ближайшее значение для заданного количества степеней свободы и посмотреть соответствующий ему уровень значимости. Но это прошлый век. Воспользуемся ЭВМ, в частности MS Excel. В эксель есть несколько функций, связанных с хи-квадрат.

Ниже их краткое описание.
ХИ2.ОБР – критическое значение Хи-квадрат при заданной вероятности слева (как в статистических таблицах)
ХИ2.ОБР.ПХ – критическое значение при заданной вероятности справа. Функция по сути дублирует предыдущую. Но здесь можно сразу указывать уровень α, а не вычитать его из 1. Это более удобно, т.к. в большинстве случаев нужен именно правый хвост распределения.
ХИ2.РАСП – p-value слева (можно рассчитать плотность).
ХИ2.РАСП.ПХ – p-value справа.
ХИ2.ТЕСТ – по двум диапазонам частот сразу проводит тест хи-квадрат. Количество степеней свободы берется на одну меньше, чем количество частот в столбце (так и должно быть), возвращая значение p-value.
Давайте пока рассчитаем для нашего эксперимента критическое (табличное) значение для 5-ти степеней свободы и альфа 0,05. Формула Excel будет выглядеть так:
=ХИ2.ОБР(0,95;5)
Или так
=ХИ2.ОБР.ПХ(0,05;5)
Результат будет одинаковым – 11,0705. Именно это значение мы видим в таблице (округленное до 1 знака после запятой).
Рассчитаем, наконец, p-value для 5-ти степеней свободы критерия χ2 = 3,4. Нужна вероятность справа, поэтому берем функцию с добавкой ПХ (правый хвост)
=ХИ2.РАСП.ПХ(3,4;5) = 0,63857
Значит, при 5-ти степенях свободы вероятность получить значение критерия χ2 = 3,4 и больше равна почти 64%. Естественно, гипотеза не отклоняется (p-value больше 5%), частоты очень хорошо согласуются.
А теперь проверим гипотезу о согласии частот с помощью теста хи квадрат и функции Excel ХИ2.ТЕСТ.

Никаких таблиц, никаких громоздких расчетов. Указав в качестве аргументов функции столбцы с наблюдаемыми и ожидаемыми частотами, сразу получаем p-value. Красота.
Представим теперь, что вы играете в кости с подозрительным типом. Распределение очков от 1 до 5 остается прежним, но он выкидывает 26 шестерок (количество всех бросков становится 78).

p-value в этом случае оказывается 0,003, что гораздо меньше чем, 0,05. Есть серьезные основания сомневаться в правильности игральной кости. Вот, как выглядит эта вероятность на диаграмме распределения хи-квадрат.

Статистика критерия хи-квадрат здесь получается 17,8, что, естественно, больше табличного (11,1).
Надеюсь, мне удалось объяснить, что такое критерий согласия χ2 (хи-квадрат) Пирсона и как с его помощью проверяются статистические гипотезы.
Напоследок еще раз о важном условии! Критерий хи-квадрат исправно работает только в случае, когда количество всех частот превышает 50, а минимальное ожидаемое значение для каждой группы не меньше 5. Если в какой-либо категории ожидаемая частота менее 5, но при этом сумма всех частот превышает 50, то такую категорию объединяют с ближайшей, чтобы их общая частота превысила 5. Если это сделать невозможно, или сумма частот меньше 50, то следует использовать более точные методы проверки гипотез. О них поговорим в другой раз.
Ниже находится видео ролик о том, как в Excel проверить гипотезу с помощью критерия хи-квадрат.
Скачать файл с примером.
Поделиться в социальных сетях: