Время на прочтение
13 мин
Количество просмотров 28K
Всем привет.
Есть такая задача – проверить, являются ли два графа изоморфными друг другу. Т.е., говоря по-простому, узнать, являются ли оба эти графа «одним и тем же» графом, но с разной нумерацией вершин и, в случае задания графов графически, с разным их пространственным расположением. Решение этой задачи не является таким уж очевидным, как может кому-то показаться на первый взгляд: даже для небольших графов взгляд на их графическое представление не всегда даст однозначный ответ. См., например, рисунок в той же Вики: ru.wikipedia.org/wiki/Изоморфизм_графов#Пример.
Ну как, очевидно?
А есть и более сложная задача: поиск в некотором «большом» графе всех подграфов, изоморфных некоторому другому графу «поменьше». Это еще более «темный лес». То есть, конечно, не совсем темный, но задача, согласитесь, не самая простая.
Итак, что же мы имеем?
1. Зачем вообще все это надо
И хотя задача про изоморфные (под)графы, как мы уже упомянули, сложная, она довольно нужная и полезная. А зачем? А затем, например, чтобы искать в базе данных химические соединения, подобные некоторой заданной молекуле по ее структурной формуле. Ведь ее можно представить себе в виде графа, не так ли? Этим занимается хемоинформатика – есть такая наука. А ведь есть еще задачи сопоставления с образцом, различные биоинформатические задачи, да много всего интересного.
2. Как решают эту задачу?
Классический подход к решению данной задачи был заложен Дж. Ульманом в 1976 году [3], впоследствии он существенно доработал свой алгоритм [4]. Также данный подход получил дальнейшее развитие в работах многих других авторов, например, Корделлы и соавторов [2] (алгоритм VF2), Бонници и соавторов [1] (алгоритм RI), и др.
Если кратко, то суть этого подхода заключается в «умном переборе» возможных соответствий вершин графа-образца B и графа A, в котором идет его поиск. «Умным» этот перебор делает ввод различных условий и ограничений, которые позволяют как можно раньше отсечь неподходящие варианты. Также для этих целей может проводиться различная предварительная обработка исходных данных.
Не будем здесь заниматься пересказом данных работ, а предложим читателю познакомиться с ними самостоятельно. Однако «показ лучше наказа», и, нужно отметить, что в Сети есть и неплохие графические примеры и объяснения этих алгоритмов. См., например, следующие:
coderoad.ru/17480142/Есть-ли-простой-пример-для-объяснения-алгоритма-Ульмана – очень хорошее и понятное объяснение с примером,
issue.life/questions/8176298 – шаги алгоритма VF2 с примером.
Однако возникает вопрос – возможны ли также еще какие-либо иные пути и подходы для решения этой задачи, пусть и для каких-то частных случаев? И вот с одним из возможных ответов на этот вопрос и хотелось бы Вас познакомить.
3. Изоморфизм графов и NB-пути
Давайте сразу договоримся: под NB-путями (и не из англомании, а просто потому, что так – короче) мы будем называть maximal non-branching paths, т.е. максимально протяженные неразветвляющиеся пути некоторого графа.
Итак, если у нас если два графа изоморфны друг другу, то для любого представления первого графа в виде последовательности максимально протяженных неразветвляющихся путей (т.е. этих наших NB-путей) всегда существует соответствующее ему такое же представление второго графа, и при этом:
- для ориентированных графов соответствующие друг другу пути будут сонаправлены,
- степени соответствующих друг другу вершин для неориентированных графов (а для ориентированных – количества входящих и исходящих ребер соответственно) будут равны,
- при «совмещении» таких представлений в результате мы будем иметь соответствие вершин первого и второго графов.
Пример. Граф A = {1->2, 1->6, 4->5, 5->1, 3->3}. Граф B = {3->4, 3->5, 1->2, 2->3, 6->6}
PathsA (maximal non-branching paths of A): 1->2, 1->6, 4->5->1, 3->3
PathsB (maximal non-branching paths of B): 3->4, 3->5, 1->2->3, 6->6
Соответствие вершин: 1(A):3(B), 2(A):4(B), 6(A):5(B), 4(A):1(B), 5(A):2(B), 3(A):6(B).
Таким образом, задачу проверки изоморфизма двух графов можно решить нахождением таких соответствующих друг другу путей и, затем, проверкой равенства друг другу матриц смежности, построенных исходя их сохранения порядка вершин в полученных последовательностях путей (при этом каждая вершина добавляется в порядок следования единожды, при ее первом «упоминании»). В нашем примере для построения матриц смежности будут использоваться следующие порядки вершин:
A: 1, 2, 6, 4, 5, 3
B: 3, 4, 5, 1, 2, 6
Матрица смежности для A для заданного порядка вершин:
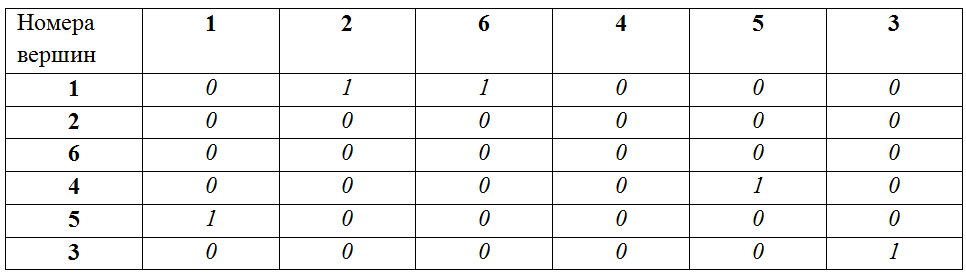
Матрица смежности для B для заданного порядка вершин:
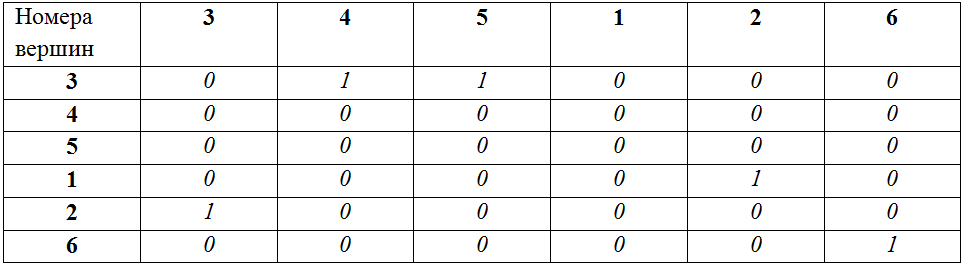
Матрицы равны, следовательно, графы A и B – изоморфны.
При этом данный подход (1) применим как для ориентированных, так и неориентированных графов, (2) применим для графов, содержащих более одной компоненты связности/ сильной связности, (3) применим для графов, содержащих кратные (множественные) ребра и петли, однако (4) не учитывает вершины, для которых отсутствуют инцидентные им ребра.
4. Ну хорошо, проверили изоморфизм графов. А что же с поиском подграфов?
А тут, честно признаюсь, все значительно сложнее. Тут у нас будет следующее ограничение: исходя из самой сути метода можно находить не любые, но лишь
«вписанные» подграфы
. А
«вписанным» подграфом
графа A мы будем называть такой его подграф, который может быть «приклеен» к другим частям графа A только за счет ребер, инцидентных лишь граничным вершинам его (подграфа) неразветвляющихся путей максимальной длины (при этом граф A может содержать и иные компоненты связности). Не волнуйтесь, ниже будет пример, и все будет понятней. Прим. С 12.2020 все же удалось доработать данный метод для поиска всех (а не только «вписанных») подграфов, изоморфных данному. Но об этом в самом конце (см. Раздел 8. Вместо послесловия – Продолжение).
Кроме того, при решении данной задачи, помимо поиска соответствий NB-путей графов A и B по длине (как это было в рассмотренном выше примере с проверкой изоморфизма), также необходимо отдельно искать и следующие возможные соответствия между ними:
- Соответствия NB-путей – простых цепей из графа B NB-путям – простым цепям/ простым из циклам графа A. При этом изначально такие пути в графе A могут быть длиннее – в этом случае берутся их отрезки, равные по длине искомому пути из B.
- Соответствия NB-«концевых» путей графа B каким-либо NB-путям графа A (при этом пути из графа A также могут быть длиннее – в этом случае берутся их отрезки, равные по длине искомому пути из графа B).
Разберемся на примере:
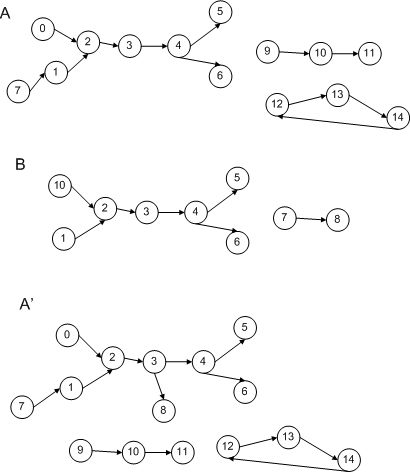
При поиске «вписанного» изоморфного подграфа графа B в графе A (см. рис. выше) будут обнаружены следующие соответствия:
- внутренний путь 2->3->4 графа B: внутренний путь 2->3->4 графа A,
- концевые пути 1->2 и 10->2 графа B: концевой путь 0->2 графа A и фрагмент концевого пути 7->1->2 графа A, а именно 1->2,
- простая цепь 7->8 графа B: отрезки простой цепи 9->10->11 графа A, а именно 9->10 и 10->11, а также отрезки простого цикла 12->13->14->12 графа A, а именно 12->13, 13->14, и 14->12.
Таким образом, в качестве «изоморфных графу B «вписанных» подграфов графа A могут быть найдены следующие 5 вариантов:
A1 = {0->2, 1->2, 2->3, 3->4, 4->5, 4->6, 9->10}
A2 = {0->2, 1->2, 2->3, 3->4, 4->5, 4->6, 10->11}
A3 = {0->2, 1->2, 2->3, 3->4, 4->5, 4->6, 12->13}
A4 = {0->2, 1->2, 2->3, 3->4, 4->5, 4->6, 13->14}
A5 = {0->2, 1->2, 2->3, 3->4, 4->5, 4->6, 14->12}
Однако, если мы добавим к графу A дополнительное ребро 3->8, у нас получится граф A’ (ниже на том же рисунке). И в A’ уже будет не найти «вписанных» подграфов, изоморфных графу B. Действительно: ребро 3->8 «разбивает» путь 2->3->4 графа A на два и, значит, путей-кандидатов для внутреннего пути 2->3->4 графа B обнаружено не будет.
5. Теперь сам алгоритм
Теперь мы можем перейти к более детальному рассмотрению алгоритма поиска «вписанных» в граф А подграфов, изоморфных некоторому графу B.
Итак, алгоритм будет состоять из 4-х этапов:
- Препроцессинг,
- Сопоставление,
- Прореживание,
- Заключение.
Этап I. Препроцессинг
На данном этапе мы находим все NB-пути по каждому из графов, а также оцениваем факторы, ограничивающие пространство выбора при переборе. Т.е. мы делаем следующее:
- Находим все NB-пути в графе A и заносим их в динамический массив (в С++ – в вектор) PathsA
- Находим все NB-пути в графе B и заносим их в динамический массив (вектор) PathsB
- Вычисляем и запоминаем кратность всех ребер графов A и B. Дальнейшие действия по этапам II-IV проводятся исходя из допущения, что кратности всех ребер равны 1. Однако на финальной стадии производится сравнение кратности ребер подграфа графа A-кандидата на изоморорфизм с графом B и кратности ребер самого графа B: все ребра подходящего графа-кандидата должны иметь кратность не меньшую, чем сопоставляемое им ребро графа B.
- Подсчитываем степени всех вершин графов A и B (для ориентированных графов степени по входящим и исходящим ребрам учитываются отдельно).
- Вычисляем матрицы кратчайших путей между каждой парой вершин в A и в B: назовем их DA и DB соответственно.
- Формируем матрицу смежности – назовем ее B0 – для графа B таким же образом, как мы это делали выше, когда проверяли изоморфизм двух графов.
Итак, у нас есть NB-пути по обоим графам и параметры-ограничители из п.п. 3-5.
Этап II. Сопоставление
На данном этапе мы будем подбирать NB-пути-кандидаты (далее – просто «пути-кандидаты») из графа A для каждого из NB-путей графа B. Отметка о каждом пути-кандидате из PathsA для каждого i-го пути PathsB[i] будет записываться в двумерный динамический массив (в C++ – в вектор векторов) NPaths – соответственно в i-й вектор (i-ю строку) – в виде упорядоченного триплета чисел: номер соответствующего пути в PathsA – номер стартовой позиции в нем – длина пути.
Например, PathsB[2] = {1, 0, 3, 3, 1, 3} означает, что пути PathsB[2] сопоставлено 2 пути-кандидата из A: из PathsA[1] – 3 первых элемента пути начиная с нулевого (начального), и из PathsA[3] – также 3 элемента начиная с первого (следующего за начальным).
При этом поиск (подбор) путей-кандидатов мы будем производить по 4-м направлениям:
- Поиск путей-кандидатов для всех внутренних NB-путей графа B из PathsB, т.е. тех, обе граничных вершины которых соединены в графе B как минимум с 2-мя другими вершинами (независимо от направления такой связи) и при этом такой путь не является простым циклом (ориентированным – для ориентированных графов).
- Поиск путей-кандидатов для концевых NB-путей из PathsB.
- Поиск путей-кандидатов для NB-путей – простых циклов из PathsB.
- Поиск путей-кандидатов для NB-путей – простых цепей из PathsB.
При отборе путей-кандидатов для каждого i-го пути из PathsB сравниваются (вот тут-то нам и начинают пригождаться некоторые из вычисленных ранее параметров-ограничителей):
- его длина и длина пути-кандидата (должны быть равны для случаев 1 и 3, а для случаев 2 и 4 путь-кандидат из PathsA также может быть длиннее),
- степени его граничных вершин и соответствующих им вершин пути-кандидата (у вершин из пути-кандидата данные значения должны быть не менее чем у пути из PathsB),
- кратность ребра пути-кандидата должна быть не менее, чем у пути из PathsB,
- другие возможные ограничения (например, совпадения меток вершин, если мы говорим о тех же химических соединениях, когда вершины можно маркировать соответствующими атомами, и т.д.)
Если по результатам этапа II для какого-либо из путей в PathsB не найдено ни одного пути-кандидата из PathsA, то считается, что A не содержит «вписанных» подграфов, изоморфных графу B.
Предварительное прореживание
Теперь давайте попробуем «ужать» граф A. Оставим в нем лишь те ребра, которые вошли в найденные нами пути-кандидаты. Если при этом граф A потерял хоть бы одно ребро по сравнению с его изначальным состоянием – возвращаемся на этап I “Препроцессинг”: степени вершин графа A и, соответственно, перечень путей-кандидатов может быть уменьшен и, соответственно, может быть сокращено пространство поиска.
Этап III. Прореживание перечня путей-кандидатов
Целью настоящего этапа является дальнейшее максимально возможное исключение неподходящих путей кандидатов. Для этого осуществим следующие действия.
- Исключение заведомо неподходящих путей-кандидатов исходя из минимальных расстояний между вершинами в графе B. Исключению подлежит тот путь-кандидат по каждому PathsB[i], для которого хотя бы по одному PathsB[j] не нашлось ни одного такого пути-кандидата, чтобы кратчайшие расстояния между их граничными вершинами в графе A было меньше или равно кратчайшему расстоянию между соответствующими им граничными вершинами путей PathsB[i] и PathsB[j] из графа B.
- Исключение для всех циклов из PathsB сопоставленных им нециклических путей-кандидатов и наоборот.
- Аналогичное п. 1 исключение путей-кандидатов, но не по критерию кратчайшего расстояния между граничными вершинами, а их (граничных вершин) взаимному равенству либо неравенству.
Например, если:
- начальный элемент пути PathsB[i] не равен начальному элементу пути PathsB[j], и
- конечный элемент пути PathsB[i] не равен конечному элементу пути PathsB[j], и
- начальный элемент пути PathsB[i] равен конечному элементу пути PathsB[j], и
- начальный элемент пути PathsB[j] не равен конечному элементу пути PathsB[i],
то исключению подлежит тот путь-кандидат по пути PathsB[i], для которого хотя бы по одному PathsB[j] не нашлось ни одного пути-кандидата, удовлетворяющего приведенному выше условию относительно равенства/ неравенства соответственно их (путей-кандидатов) начальных и конечных вершин.
Т.е., грубо говоря, мы выкидываем те пути-кандидаты, которые заведомо не войдут в искомые подграфы – исходя из расстояния до всех прочих путей-кандидатов (страшно далеки эти пути от всех прочих), исходя из их цикличности/ нецикличности, а также исходя из должного равенства/ неравенства их граничных вершин с граничными вершинами других путей-кандидатов.
Если по результатам этапа III хотя бы 1 путь-кандидат был удален из PathsA, то – опять же – обновляется граф А – в нем остаются только те ребра, которые вошли в оставшиеся пути-кандидаты. И, опять же, если при этом граф A «похудел» хотя бы на одно ребро – снова возвращаемся на этап I “Препроцессинг”: степени вершин графа A и, соответственно, перечень путей-кандидатов может быть уменьшен и, соответственно, может быть сокращено пространство поиска.
Этап IV. Заключение
Каждое возможное сочетания всех оставшихся путей-кандидатов задает подграф графа A. Для каждого такого подграфа строится матрица смежности с учетом порядка следования путей кандидатов таким же образом, как была построена матрица смежности B0 для графа B, а затем эти матрицы смежности сравниваются между собой.
Если они равны, то сравниваются кратности ребер (см. п. 3 Этапа I Препроцессинг). Если все эти условия выполнены – найденный подграф считается изоморфным графу B и добавляется в множество найденных результатов.
При проведении этапа IV “Заключение” возможно применение различных дополнительных проверок, ускоряющих выявление и отбрасывание неподходящего подграфа.
6. Как все запутано… Рассмотрим пример работы алгоритма
Не знаю как Вам, а мне без примера было бы непонятно. Давайте рассмотрим все на примере.
На рис. ниже приведены графы A = {1->2, 2->5, 5->15, 16->15, 5->5, 5->5, 5->4, 5->6, 7->6, 6->8, 6->6, 6->9, 9->10, 9->11, 12->0, 0->12, 4->13, 13->14, 14->4} и B = {1->1, 4->5, 5->1, 1->3, 3->3, 3->2, 2->7, 2->8, 9->10, 10->9, 1->6, 6->11, 11->12, 12->6}. Нашей задачей является нахождение в графе A всех «вписанных» подграфов, изоморфных графу B. Результат также отражен на рисунке: найденные вершины и ребра графа A выделены толстой линией, а номера соответствующих вершин графа B указаны в скобках (если вариантов несколько – они указываются через дробь).
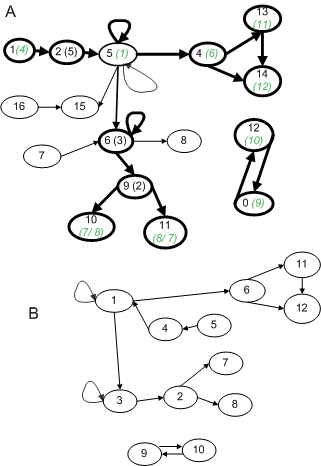
При решении задачи поиска в графе A «вписанных» подграфов, изоморфных графу B, имеем следующие результаты работы алгоритма.
Этап I: Выполнены все действия и расчеты по п.п. 1-5 данного этапа, ниже приводятся полученные PathsA и PathsB.
PathsA:
1->2->5
4->13->14 4
5->4
5->5
5->6
5->15
6->6
6->8
6->9
7->6
9->10
9->11
16->15
0->12->0
PathsB:
1->1
1->3
1->6
2->7
2->8
3->2
3->3
4->5->1
6->11->12->6
9->10->9
Этапы II-III. Сопоставление показало, что для каждого пути из PathsA находится как минимум один путь-кандидат из PathsB, а по результатам предварительного прореживания PathsA был сокращен. На этапе основного прореживания (III) дальнейшего сокращения PathsA не произошло. В результате PathsA и PathsB приняли вид:
PathsA:
1->2->5
4->13->14->4
5->4
5->5
5->6
6->6
6->9
9->10
9->11
0->12->0
PathsB:
1->1
1->3
1->6
2->7
2->8
3->2
3->3
4->5->1
6->11->12->6
9->10->9
Итоговое сопоставление NPaths имеет вид:
NPaths:
i=0: 3 0 2
i=1: 4 0 2
i=2: 2 0 2
i=3: 7 0 2 8 0 2
i=4: 7 0 2 8 0 2
i=5: 6 0 2
i=6: 5 0 2
i=7: 0 0 3
i=8: 1 0 4
i=9: 9 0 3
Здесь самое время вспомнить, что каждый упорядоченный триплет чисел в NPaths[i] задает соответствующий PathsB[i] путь-кандидат из A в формате: номер соответствующего пути из PathsA – стартовая позиция отрезка из данного пути – длина отрезка. Таким образом, нетрудно убедиться, что пути PathsB[0] = {1->1} (i=0: 3 0 2) соответствует единственный путь из A, а именно: отрезок из пути PathsA[3], начинающийся с его самого начала и имеющий длину 2.
Этап IV. В результате в графе A был найден единственный подграф A1, изоморфный графу B. A1 = {0->12, 1->2, 2->5, 4->13, 5->4, 5->5, 5->6, 6->6, 6->9, 9->10, 9->11, 12->0, 13->14, 14->4}.
7. Что же дальше?
А, дальше, в принципе, и все. Хотя не совсем: автор должен признаться, что алгоритм может еще дорабатываться и дорабатываться. Что тут нужно добавить?
- При введении дополнительных признаков вершин графов A и B (например, при задании графами химических соединений каждой вершине может быть сопоставлен числовой код, соответствующий одному и только одному атому (изотопу)) процесс поиска может быть ускорен за счет большей точности сопоставлений по Этапу II: дополнительным условием отбора путей-кандидатов будет соответствие меток вершин.
- Скорость работы представленного алгоритма очень сильно зависит от структур исходных графов и их взаимного соответствия. Алгоритм будет работать тем быстрее, чем более «уникальную», «нестандартную» и несимметричную структуру имеет граф-образец B.
- Исходя из этого, одним из возможных путей использования представленного алгоритма может являться, в том числе, «скриннинговый» поиск решения по любому из направлений:
(1) поиск именно «вписанных» подграфов, изоморфных данному,
(2) проверка изоморфности двух различных графов.
«Скрининг» здесь подразумевает «предварительный экспресс-поиск решения», для чего необходимо задать некоторое предельное время его работы, по истечении которого при отсутствии результата можно считать, что данная задача подлежит решению другим алгоритмом. - Возможно, для кого-то представленный алгоритм может оказаться полезным как при решении различных практических задач, так и при разработке новых алгоритмов решения задачи об изоморфном подграфе.
8. Вместо послесловия – Продолжение
В декабре 2020 случилось то, что должно было случиться: удалось как адаптировать данный подход для поиска всех (а не только «вписанных») подграфов в графе по образцу, так и воплотить это на практике. Решение, в принципе, лежало на поверхности: вместо non-branching paths (нет короткого аналога термина по-русски) были взяты сами ребра графов. И с января 2021 также на практике была реализована функция, позволяющая искать изоморфные подграфы с учетом меток вершин, причем произвольного типа (в т.ч. — строкового, что позволяет использовать «многогранные» метки; возможно, это может оказаться полезным для различных задач, в том числе, в области химии).
Литература
Общее по проблематике:
1. Bonnici, V., Giugno, R., Pulvirenti, A. et al. A subgraph isomorphism algorithm and its application to biochemical data. BMC Bioinformatics 14, S13 (2013). doi.org/10.1186/1471-2105-14-S7-S13.
2. Cordella L, Foggia P, Sansone C, Vento M: A (Sub)Graph Isomorphism Algorithm for Matching Large Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2004, 26 (10): 1367-1372. 10.1109/TPAMI.2004.75.
3. Ullmann Julian R.: An algorithm for Subgraph Isomorphism. Journal of the Association for Computing Machinery. 1976, 23: 31-42. 10.1145/321921.321925.
4. Ullmann Julian R.: Bit-vector algorithms for binary constraint satisfaction and subgraph isomorphism. J Exp Algorithmics. 2011, 15 (1.6): 1.1-1.6. 1.64
Написанный более официальным языком препринт автора про это самый «алгоритм на основе анализа NB-Paths», содержащий также инфу о предпринятой попытке его реализации на C++:
5. Черноухов С.А. 2020. Preprints.RU. Проверка изоморфности двух графов и поиск изоморфных подграфов: подход, основанный на анализе максимально протяженных неразветвляющихся путей / Maximal non-branching paths approach to solve (sub)graph isomorphism problem. DOI: dx.doi.org/10.24108/preprints-3111977
Полезные интернет-источники по теме:
6. coderoad.ru/17480142/Есть-ли-простой-пример-для-объяснения-алгоритма-Ульмана
7. issue.life/questions/8176298.
8. github.com/chernouhov/CBioInfCpp-0- — репозиторий свободной библиотеки функций для работы со строками и графами на C++, алгоритм реализован с помощью функции SubGraphsInscribed.
Как мы увидели на примере выше, изоморфность доказать не всегда легко. С другой стороны, доказать неизоморфность двух графов обычно проще — нужно найти свойство, которое эти два графа не разделяют.
Например, два графа могут отличаться такими свойствами:
-
Разное количество вершин или ребер
-
Разное количество компонент
-
Степени вершин в каждом графе
-
Содержание абсолютно одинаковых подграфов
Чтобы лучше понять эти свойства, рассмотрим такой пример:

В этом примере графы имеют такие свойства:
-
Одинаковое количество вершин и ребер
-
Одна компонента в обоих случаях
-
По две вершины степени
, две вершины степени
и четыре вершин степени
Таким образом, первые три свойства не помогают. Однако нам на помощь приходит четвертое свойство: в первом графе нет треугольника-подграфа, а во втором — он есть.
Существует множество других возможностей доказать неизоморфность. Иногда для этого требуется немного творчества.
Например, вот эти графы неизоморфны:

Обратите внимание, что у них одинаковое количество вершин и ребер, степени почти всех вершин тоже одинаковы. Определим, в чем разница между ними. Второй граф содержит вершину степени
, смежную с двумя вершинами степени
— в первом графе это не так.
К этому же примеру можно подойти по-другому:
-
На первом графе есть два пути длиной в пять вершин:
-
Прямой путь по горизонтали
-
Путь справа налево с поворотом вверх
-
-
На втором графе пути другие:
-
Прямой путь по горизонтали в пять вершин
-
Путь в три вершины слева направо с поворотом вверх
-
From Wikipedia, the free encyclopedia
Unsolved problem in computer science:
Can the graph isomorphism problem be solved in polynomial time?
The graph isomorphism problem is the computational problem of determining whether two finite graphs are isomorphic.
The problem is not known to be solvable in polynomial time nor to be NP-complete, and therefore may be in the computational complexity class NP-intermediate. It is known that the graph isomorphism problem is in the low hierarchy of class NP, which implies that it is not NP-complete unless the polynomial time hierarchy collapses to its second level.[1] At the same time, isomorphism for many special classes of graphs can be solved in polynomial time, and in practice graph isomorphism can often be solved efficiently.[2][3]
This problem is a special case of the subgraph isomorphism problem,[4] which asks whether a given graph G contains a subgraph that is isomorphic to another given graph H; this problem is known to be NP-complete. It is also known to be a special case of the non-abelian hidden subgroup problem over the symmetric group.[5]
In the area of image recognition it is known as the exact graph matching.[6]
State of the art[edit]
In November 2015, László Babai announced a quasipolynomial time algorithm for all graphs, that is, one with running time  for some fixed
for some fixed  .[7][8][9][10] On January 4, 2017, Babai retracted the quasi-polynomial claim and stated a sub-exponential time bound instead after Harald Helfgott discovered a flaw in the proof. On January 9, 2017, Babai announced a correction (published in full on January 19) and restored the quasi-polynomial claim, with Helfgott confirming the fix.[11][12] Helfgott further claims that one can take c = 3, so the running time is 2O((log n)3).[13][14]
.[7][8][9][10] On January 4, 2017, Babai retracted the quasi-polynomial claim and stated a sub-exponential time bound instead after Harald Helfgott discovered a flaw in the proof. On January 9, 2017, Babai announced a correction (published in full on January 19) and restored the quasi-polynomial claim, with Helfgott confirming the fix.[11][12] Helfgott further claims that one can take c = 3, so the running time is 2O((log n)3).[13][14]
Prior to this, the best currently accepted theoretical algorithm was due to Babai & Luks (1983), and is based on the earlier work by Luks (1982) combined with a subfactorial algorithm of V. N. Zemlyachenko (Zemlyachenko, Korneenko & Tyshkevich 1985). The algorithm has run time 2O(√n log n) for graphs with n vertices and relies on the classification of finite simple groups. Without this classification theorem, a slightly weaker bound
2O(√n log2 n) was obtained first for strongly regular graphs by László Babai (1980), and then extended to general graphs by Babai & Luks (1983). Improvement of the exponent √n is a major open problem; for strongly regular graphs this was done by Spielman (1996). For hypergraphs of bounded rank, a subexponential upper bound matching the case of graphs was obtained by Babai & Codenotti (2008).
There are several competing practical algorithms for graph isomorphism, such as those due to McKay (1981), Schmidt & Druffel (1976), Ullman (1976), and Stoichev (2019). While they seem to perform well on random graphs, a major drawback of these algorithms is their exponential time performance in the worst case.[15]
The graph isomorphism problem is computationally equivalent to the problem of computing the automorphism group of a graph,[16][17] and is weaker than the permutation group isomorphism problem and the permutation group intersection problem. For the latter two problems, Babai, Kantor & Luks (1983) obtained complexity bounds similar to that for graph isomorphism.
Solved special cases[edit]
A number of important special cases of the graph isomorphism problem have efficient, polynomial-time solutions:
- Trees[18][19]
- Planar graphs[20] (In fact, planar graph isomorphism is in log space,[21] a class contained in P)
- Interval graphs[22]
- Permutation graphs[23]
- Circulant graphs[24]
- Bounded-parameter graphs
- Graphs of bounded treewidth[25]
- Graphs of bounded genus[26] (Planar graphs are graphs of genus 0.)
- Graphs of bounded degree[27]
- Graphs with bounded eigenvalue multiplicity[28]
- k-Contractible graphs (a generalization of bounded degree and bounded genus)[29]
- Color-preserving isomorphism of colored graphs with bounded color multiplicity (i.e., at most k vertices have the same color for a fixed k) is in class NC, which is a subclass of P[30]
Complexity class GI[edit]
Since the graph isomorphism problem is neither known to be NP-complete nor known to be tractable, researchers have sought to gain insight into the problem by defining a new class GI, the set of problems with a polynomial-time Turing reduction to the graph isomorphism problem.[31] If in fact the graph isomorphism problem is solvable in polynomial time, GI would equal P. On the other hand, if the problem is NP-complete, GI would equal NP and all problems in NP would be solvable in quasi-polynomial time.
As is common for complexity classes within the polynomial time hierarchy, a problem is called GI-hard if there is a polynomial-time Turing reduction from any problem in GI to that problem, i.e., a polynomial-time solution to a GI-hard problem would yield a polynomial-time solution to the graph isomorphism problem (and so all problems in GI). A problem  is called complete for GI, or GI-complete, if it is both GI-hard and a polynomial-time solution to the GI problem would yield a polynomial-time solution to .
is called complete for GI, or GI-complete, if it is both GI-hard and a polynomial-time solution to the GI problem would yield a polynomial-time solution to .
The graph isomorphism problem is contained in both NP and co-AM. GI is contained in and low for Parity P, as well as contained in the potentially much smaller class SPP.[32] That it lies in Parity P means that the graph isomorphism problem is no harder than determining whether a polynomial-time nondeterministic Turing machine has an even or odd number of accepting paths. GI is also contained in and low for ZPPNP.[33] This essentially means that an efficient Las Vegas algorithm with access to an NP oracle can solve graph isomorphism so easily that it gains no power from being given the ability to do so in constant time.
GI-complete and GI-hard problems[edit]
Isomorphism of other objects[edit]
There are a number of classes of mathematical objects for which the problem of isomorphism is a GI-complete problem. A number of them are graphs endowed with additional properties or restrictions:[34]
- digraphs[34]
- labelled graphs, with the proviso that an isomorphism is not required to preserve the labels,[34] but only the equivalence relation consisting of pairs of vertices with the same label
- «polarized graphs» (made of a complete graph Km and an empty graph Kn plus some edges connecting the two; their isomorphism must preserve the partition)[34]
- 2-colored graphs[34]
- explicitly given finite structures[34]
- multigraphs[34]
- hypergraphs[34]
- finite automata[34]
- Markov Decision Processes[35]
- commutative class 3 nilpotent (i.e., xyz = 0 for every elements x, y, z) semigroups[34]
- finite rank associative algebras over a fixed algebraically closed field with zero squared radical and commutative factor over the radical.[34][36]
- context-free grammars[34]
- balanced incomplete block designs[34]
- Recognizing combinatorial isomorphism of convex polytopes represented by vertex-facet incidences.[37]
GI-complete classes of graphs[edit]
A class of graphs is called GI-complete if recognition of isomorphism for graphs from this subclass is a GI-complete problem. The following classes are GI-complete:[34]
- connected graphs[34]
- graphs of diameter 2 and radius 1[34]
- directed acyclic graphs[34]
- regular graphs[34]
- bipartite graphs without non-trivial strongly regular subgraphs[34]
- bipartite Eulerian graphs[34]
- bipartite regular graphs[34]
- line graphs[34]
- split graphs[38]
- chordal graphs[34]
- regular self-complementary graphs[34]
- polytopal graphs of general, simple, and simplicial convex polytopes in arbitrary dimensions.[39]
Many classes of digraphs are also GI-complete.
Other GI-complete problems[edit]
There are other nontrivial GI-complete problems in addition to isomorphism problems.
- The recognition of self-complementarity of a graph or digraph.[40]
- A clique problem for a class of so-called M-graphs. It is shown that finding an isomorphism for n-vertex graphs is equivalent to finding an n-clique in an M-graph of size n2. This fact is interesting because the problem of finding a clique of order (1 − ε)n in a M-graph of size n2 is NP-complete for arbitrarily small positive ε.[41]
- The problem of homeomorphism of 2-complexes.[42]
GI-hard problems[edit]
- The problem of counting the number of isomorphisms between two graphs is polynomial-time equivalent to the problem of telling whether even one exists.[43]
- The problem of deciding whether two convex polytopes given by either the V-description or H-description are projectively or affinely isomorphic. The latter means existence of a projective or affine map between the spaces that contain the two polytopes (not necessarily of the same dimension) which induces a bijection between the polytopes.[39]
Program checking[edit]
Manuel Blum and Sampath Kannan (1995) have shown a probabilistic checker for programs for graph isomorphism. Suppose P is a claimed polynomial-time procedure that checks if two graphs are isomorphic, but it is not trusted. To check if graphs G and H are isomorphic:
- Ask P whether G and H are isomorphic.
- If the answer is «yes»:
- Attempt to construct an isomorphism using P as subroutine. Mark a vertex u in G and v in H, and modify the graphs to make them distinctive (with a small local change). Ask P if the modified graphs are isomorphic. If no, change v to a different vertex. Continue searching.
- Either the isomorphism will be found (and can be verified), or P will contradict itself.
- If the answer is «no»:
- Perform the following 100 times. Choose randomly G or H, and randomly permute its vertices. Ask P if the graph is isomorphic to G and H. (As in AM protocol for graph nonisomorphism).
- If any of the tests are failed, judge P as invalid program. Otherwise, answer «no».
- If the answer is «yes»:
This procedure is polynomial-time and gives the correct answer if P is a correct program for graph isomorphism. If P is not a correct program, but answers correctly on G and H, the checker will either give the correct answer, or detect invalid behaviour of P.
If P is not a correct program, and answers incorrectly on G and H, the checker will detect invalid behaviour of P with high probability, or answer wrong with probability 2−100.
Notably, P is used only as a blackbox.
Applications[edit]
Graphs are commonly used to encode structural information in many fields, including computer vision and pattern recognition, and graph matching, i.e., identification of similarities between graphs, is an important tools in these areas. In these areas graph isomorphism problem is known as the exact graph matching.[44]
In cheminformatics and in mathematical chemistry, graph isomorphism testing is used to identify a chemical compound within a chemical database.[45] Also, in organic mathematical chemistry graph isomorphism testing is useful for generation of molecular graphs and for computer synthesis.
Chemical database search is an example of graphical data mining, where the graph canonization approach is often used.[46] In particular, a number of identifiers for chemical substances, such as SMILES and InChI, designed to provide a standard and human-readable way to encode molecular information and to facilitate the search for such information in databases and on the web, use canonization step in their computation, which is essentially the canonization of the graph which represents the molecule.
In electronic design automation graph isomorphism is the basis of the Layout Versus Schematic (LVS) circuit design step, which is a verification whether the electric circuits represented by a circuit schematic and an integrated circuit layout are the same.[47]
See also[edit]
- Graph automorphism problem
- Graph canonization
Notes[edit]
- ^ Schöning (1987).
- ^ Babai, László; Erdős, Paul; Selkow, Stanley M. (1980-08-01). «Random Graph Isomorphism». SIAM Journal on Computing. 9 (3): 628–635. doi:10.1137/0209047. ISSN 0097-5397.
- ^ McKay (1981).
- ^ Ullman (1976).
- ^ Moore, Russell & Schulman (2008).
- ^ Endika Bengoetxea, «Inexact Graph Matching Using Estimation of Distribution Algorithms», Ph.
D., 2002, Chapter 2:The graph matching problem (retrieved June 28, 2017) - ^ «Mathematician claims breakthrough in complexity theory». Science. November 10, 2015.
- ^ Babai (2015)
- ^ Video of first 2015 lecture linked from Babai’s home page
- ^ «The Graph Isomorphism Problem». Communications of the ACM. Retrieved 4 May 2021.
- ^ Babai, László (January 9, 2017), Graph isomorphism update
- ^ Erica Klarreich (January 14, 2017). «Graph Isomorphism Vanquished — Again». Quanta Magazine.
- ^ Helfgott, Harald (January 16, 2017), Isomorphismes de graphes en temps quasi-polynomial (d’après Babai et Luks, Weisfeiler-Leman…), arXiv:1701.04372, Bibcode:2017arXiv170104372A
- ^ Dona, Daniele; Bajpai, Jitendra; Helfgott, Harald Andrés (October 12, 2017). «Graph isomorphisms in quasi-polynomial time». arXiv:1710.04574 [math.GR].
- ^ Foggia, Sansone & Vento (2001).
- ^ Luks, Eugene (1993-09-01). «Permutation groups and polynomial-time computation». DIMACS Series in Discrete Mathematics and Theoretical Computer Science. Vol. 11. Providence, Rhode Island: American Mathematical Society. pp. 139–175. doi:10.1090/dimacs/011/11. ISBN 978-0-8218-6599-6. ISSN 1052-1798.
- ^ Algeboy (https://cs.stackexchange.com/users/90177/algeboy), Graph isomorphism and the automorphism group, URL (version: 2018-09-20): https://cs.stackexchange.com/q/97575
- ^ Kelly (1957).
- ^ Aho, Hopcroft & Ullman (1974), p. 84-86.
- ^ Hopcroft & Wong (1974).
- ^ Datta et al. (2009).
- ^ Booth & Lueker (1979).
- ^ Colbourn (1981).
- ^ Muzychuk (2004).
- ^ Bodlaender (1990).
- ^ Miller 1980; Filotti & Mayer 1980.
- ^ Luks (1982).
- ^ Babai, Grigoryev & Mount (1982).
- ^ Miller (1983).
- ^ Luks (1986).
- ^ Booth & Colbourn 1977; Köbler, Schöning & Torán 1993.
- ^ Köbler, Schöning & Torán 1992; Arvind & Kurur 2006
- ^ Arvind & Köbler (2000).
- ^ a b c d e f g h i j k l m n o p q r s t u v w x Zemlyachenko, Korneenko & Tyshkevich (1985)
- ^ Narayanamurthy & Ravindran (2008).
- ^ Grigor’ev (1981).
- ^ Johnson (2005); Kaibel & Schwartz (2003).
- ^ Chung (1985).
- ^ a b Kaibel & Schwartz (2003).
- ^ Colbourn & Colbourn (1978).
- ^ Kozen (1978).
- ^ Shawe-Taylor & Pisanski (1994).
- ^ Mathon (1979); Johnson 2005.
- ^ Endika Bengoetxea, Ph.D., Abstract
- ^ Irniger (2005).
- ^ Cook & Holder (2007).
- ^ Baird & Cho (1975).
References[edit]
- Aho, Alfred V.; Hopcroft, John; Ullman, Jeffrey D. (1974), The Design and Analysis of Computer Algorithms, Reading, MA: Addison-Wesley.
- Arvind, Vikraman; Köbler, Johannes (2000), «Graph isomorphism is low for ZPP(NP) and other lowness results.», Proceedings of the 17th Annual Symposium on Theoretical Aspects of Computer Science, Lecture Notes in Computer Science, vol. 1770, Springer-Verlag, pp. 431–442, doi:10.1007/3-540-46541-3_36, ISBN 3-540-67141-2, MR 1781752.
- Arvind, Vikraman; Kurur, Piyush P. (2006), «Graph isomorphism is in SPP», Information and Computation, 204 (5): 835–852, doi:10.1016/j.ic.2006.02.002, MR 2226371.
- Babai, László (1980), «On the complexity of canonical labeling of strongly regular graphs», SIAM Journal on Computing, 9 (1): 212–216, doi:10.1137/0209018, MR 0557839.
- Babai, László; Codenotti, Paolo (2008), «Isomorphism of hypergraphs of low rank in moderately exponential time» (PDF), Proceedings of the 49th Annual IEEE Symposium on Foundations of Computer Science (FOCS 2008), IEEE Computer Society, pp. 667–676, doi:10.1109/FOCS.2008.80, ISBN 978-0-7695-3436-7, S2CID 14025744.
- Babai, László; Grigoryev, D. Yu.; Mount, David M. (1982), «Isomorphism of graphs with bounded eigenvalue multiplicity», Proceedings of the 14th Annual ACM Symposium on Theory of Computing, pp. 310–324, doi:10.1145/800070.802206, ISBN 0-89791-070-2, S2CID 12837287.
- Babai, László; Kantor, William; Luks, Eugene (1983), «Computational complexity and the classification of finite simple groups», Proceedings of the 24th Annual Symposium on Foundations of Computer Science (FOCS), pp. 162–171, doi:10.1109/SFCS.1983.10, S2CID 6670135.
- Babai, László; Luks, Eugene M. (1983), «Canonical labeling of graphs», Proceedings of the Fifteenth Annual ACM Symposium on Theory of Computing (STOC ’83), pp. 171–183, doi:10.1145/800061.808746, ISBN 0-89791-099-0, S2CID 12572142.
- Babai, László (2015), Graph Isomorphism in Quasipolynomial Time, arXiv:1512.03547, Bibcode:2015arXiv151203547B
- Baird, H. S.; Cho, Y. E. (1975), «An artwork design verification system», Proceedings of the 12th Design Automation Conference (DAC ’75), Piscataway, NJ, USA: IEEE Press, pp. 414–420.
- Blum, Manuel; Kannan, Sampath (1995), «Designing programs that check their work», Journal of the ACM, 42 (1): 269–291, CiteSeerX 10.1.1.38.2537, doi:10.1145/200836.200880, S2CID 52151779.
- Bodlaender, Hans (1990), «Polynomial algorithms for graph isomorphism and chromatic index on partial k-trees», Journal of Algorithms, 11 (4): 631–643, doi:10.1016/0196-6774(90)90013-5, MR 1079454.
- Booth, Kellogg S.; Colbourn, C. J. (1977), Problems polynomially equivalent to graph isomorphism, Technical Report, vol. CS-77-04, Computer Science Department, University of Waterloo.
- Booth, Kellogg S.; Lueker, George S. (1979), «A linear time algorithm for deciding interval graph isomorphism», Journal of the ACM, 26 (2): 183–195, doi:10.1145/322123.322125, MR 0528025, S2CID 18859101.
- Boucher, C.; Loker, D. (2006), Graph isomorphism completeness for perfect graphs and subclasses of perfect graphs (PDF), Technical Report, vol. CS-2006-32, Computer Science Department, University of Waterloo.
- Chung, Fan R. K. (1985), «On the cutwidth and the topological bandwidth of a tree», SIAM Journal on Algebraic and Discrete Methods, 6 (2): 268–277, doi:10.1137/0606026, MR 0778007.
- Colbourn, C. J. (1981), «On testing isomorphism of permutation graphs», Networks, 11: 13–21, doi:10.1002/net.3230110103, MR 0608916.
- Colbourn, Marlene Jones; Colbourn, Charles J. (1978), «Graph isomorphism and self-complementary graphs», ACM SIGACT News, 10 (1): 25–29, doi:10.1145/1008605.1008608, S2CID 35157300.
- Cook, Diane J.; Holder, Lawrence B. (2007), «Section 6.2.1: Canonical Labeling», Mining Graph Data, Wiley, pp. 120–122, ISBN 978-0-470-07303-2.
- Datta, S.; Limaye, N.; Nimbhorkar, P.; Thierauf, T.; Wagner, F. (2009), «Planar graph isomorphism is in log-space», 2009 24th Annual IEEE Conference on Computational Complexity, p. 203, arXiv:0809.2319, doi:10.1109/CCC.2009.16, ISBN 978-0-7695-3717-7, S2CID 14836820.
- Filotti, I. S.; Mayer, Jack N. (1980), «A polynomial-time algorithm for determining the isomorphism of graphs of fixed genus», Proceedings of the 12th Annual ACM Symposium on Theory of Computing, pp. 236–243, doi:10.1145/800141.804671, ISBN 0-89791-017-6, S2CID 16345164.
- Foggia, P.; Sansone, C.; Vento, M. (2001), «A performance comparison of five algorithms for graph isomorphism» (PDF), Proc. 3rd IAPR-TC15 Workshop Graph-Based Representations in Pattern Recognition, pp. 188–199.
- Garey, Michael R.; Johnson, David S. (1979), Computers and Intractability: A Guide to the Theory of NP-Completeness, W. H. Freeman, ISBN 978-0-7167-1045-5.
- Grigor’ev, D. Ju. (1981), «Complexity of ‘wild’ matrix problems and of the isomorphism of algebras and graphs», Zapiski Nauchnykh Seminarov Leningradskogo Otdeleniya Matematicheskogo Instituta Imeni V. A. Steklova Akademii Nauk SSSR (LOMI) (in Russian), 105: 10–17, 198, MR 0628981. English translation in Journal of Mathematical Sciences 22 (3): 1285–1289, 1983.
- Hopcroft, John; Wong, J. (1974), «Linear time algorithm for isomorphism of planar graphs», Proceedings of the Sixth Annual ACM Symposium on Theory of Computing, pp. 172–184, doi:10.1145/800119.803896, S2CID 15561884.
- Irniger, Christophe-André Mario (2005), Graph Matching: Filtering Databases of Graphs Using Machine Learning, Dissertationen zur künstlichen Intelligenz, vol. 293, AKA, ISBN 1-58603-557-6.
- Kaibel, Volker; Schwartz, Alexander (2003), «On the complexity of polytope isomorphism problems», Graphs and Combinatorics, 19 (2): 215–230, arXiv:math/0106093, doi:10.1007/s00373-002-0503-y, MR 1996205, S2CID 179936, archived from the original on 2015-07-21.
- Kelly, Paul J. (1957), «A congruence theorem for trees», Pacific Journal of Mathematics, 7: 961–968, doi:10.2140/pjm.1957.7.961, MR 0087949.
- Köbler, Johannes; Schöning, Uwe; Torán, Jacobo (1992), «Graph isomorphism is low for PP», Computational Complexity, 2 (4): 301–330, doi:10.1007/BF01200427, MR 1215315, S2CID 8542603.
- Kozen, Dexter (1978), «A clique problem equivalent to graph isomorphism», ACM SIGACT News, 10 (2): 50–52, doi:10.1145/990524.990529, S2CID 52835766.
- Luks, Eugene M. (1982), «Isomorphism of graphs of bounded valence can be tested in polynomial time», Journal of Computer and System Sciences, 25: 42–65, doi:10.1016/0022-0000(82)90009-5, MR 0685360, S2CID 2572728.
- Luks, Eugene M. (1986), «Parallel algorithms for permutation groups and graph isomorphism», Proc. IEEE Symp. Foundations of Computer Science, pp. 292–302.
- Mathon, Rudolf (1979), «A note on the graph isomorphism counting problem», Information Processing Letters, 8 (3): 131–132, doi:10.1016/0020-0190(79)90004-8, MR 0526453.
- McKay, Brendan D. (1981), «Practical graph isomorphism», 10th. Manitoba Conference on Numerical Mathematics and Computing (Winnipeg, 1980), Congressus Numerantium, vol. 30, pp. 45–87, MR 0635936.
- Miller, Gary (1980), «Isomorphism testing for graphs of bounded genus», Proceedings of the 12th Annual ACM Symposium on Theory of Computing, pp. 225–235, doi:10.1145/800141.804670, ISBN 0-89791-017-6, S2CID 13647304.
- Miller, Gary L. (1983), «Isomorphism testing and canonical forms for k-contractable graphs (a generalization of bounded valence and bounded genus)», Proc. Int. Conf. on Foundations of Computer Theory, Lecture Notes in Computer Science, vol. 158, pp. 310–327, doi:10.1007/3-540-12689-9_114. Full paper in Information and Control 56 (1–2): 1–20, 1983.
- Moore, Cristopher; Russell, Alexander; Schulman, Leonard J. (2008), «The symmetric group defies strong Fourier sampling», SIAM Journal on Computing, 37 (6): 1842–1864, arXiv:quant-ph/0501056, doi:10.1137/050644896, MR 2386215, S2CID 9550284.
- Muzychuk, Mikhail (2004), «A Solution of the Isomorphism Problem for Circulant Graphs», Proc. London Math. Soc., 88: 1–41, doi:10.1112/s0024611503014412, MR 2018956, S2CID 16704931.
- Narayanamurthy, S. M.; Ravindran, B. (2008), «On the hardness of finding symmetries in Markov decision processes» (PDF), Proceedings of the Twenty-Fifth International Conference on Machine Learning (ICML 2008), pp. 688–696.
- Schmidt, Douglas C.; Druffel, Larry E. (1976), «A fast backtracking algorithm to test directed graphs for isomorphism using distance matrices», Journal of the ACM, 23 (3): 433–445, doi:10.1145/321958.321963, MR 0411230, S2CID 6163956.
- Schöning, Uwe (1987), «Graph isomorphism is in the low hierarchy», Proceedings of the 4th Annual Symposium on Theoretical Aspects of Computer Science, pp. 114–124; also Journal of Computer and System Sciences 37: 312–323, 1988.
- Shawe-Taylor, John; Pisanski, Tomaž (1994), «Homeomorphism of 2-complexes is graph isomorphism complete», SIAM Journal on Computing, 23 (1): 120–132, doi:10.1137/S0097539791198900, MR 1258998.
- Spielman, Daniel A. (1996), «Faster isomorphism testing of strongly regular graphs», Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing (STOC ’96), ACM, pp. 576–584, ISBN 978-0-89791-785-8.
- Ullman, Julian R. (1976), «An algorithm for subgraph isomorphism» (PDF), Journal of the ACM, 23: 31–42, CiteSeerX 10.1.1.361.7741, doi:10.1145/321921.321925, MR 0495173, S2CID 17268751.
Surveys and monographs[edit]
- Read, Ronald C.; Corneil, Derek G. (1977), «The graph isomorphism disease», Journal of Graph Theory, 1 (4): 339–363, doi:10.1002/jgt.3190010410, MR 0485586.
- Gati, G. (1979), «Further annotated bibliography on the isomorphism disease», Journal of Graph Theory, 3 (2): 95–109, doi:10.1002/jgt.3190030202.
- Zemlyachenko, V. N.; Korneenko, N. M.; Tyshkevich, R. I. (1985), «Graph isomorphism problem», Journal of Mathematical Sciences, 29 (4): 1426–1481, doi:10.1007/BF02104746, S2CID 121818465. (Translated from Zapiski Nauchnykh Seminarov Leningradskogo Otdeleniya Matematicheskogo Instituta im. V. A. Steklova AN SSSR (Records of Seminars of the Leningrad Department of Steklov Institute of Mathematics of the USSR Academy of Sciences), Vol. 118, pp. 83–158, 1982.)
- Arvind, V.; Torán, Jacobo (2005), «Isomorphism testing: Perspectives and open problems» (PDF), Bulletin of the European Association for Theoretical Computer Science, 86: 66–84. (A brief survey of open questions related to the isomorphism problem for graphs, rings and groups.)
- Köbler, Johannes; Schöning, Uwe; Torán, Jacobo (1993), The Graph Isomorphism Problem: Its Structural Complexity, Birkhäuser, ISBN 978-0-8176-3680-7. (From the book cover: The books focuses on the issue of the computational complexity of the problem and presents several recent results that provide a better understanding of the relative position of the problem in the class NP as well as in other complexity classes.)
- Johnson, David S. (2005), «The NP-Completeness Column», ACM Transactions on Algorithms, 1 (1): 160–176, doi:10.1145/1077464.1077476, S2CID 12604799. (This 24th edition of the Column discusses the state of the art for the open problems from the book Computers and Intractability and previous columns, in particular, for Graph Isomorphism.)
- Torán, Jacobo; Wagner, Fabian (2009), «The complexity of planar graph isomorphism» (PDF), Bulletin of the European Association for Theoretical Computer Science, 97, archived from the original (PDF) on 2010-09-20, retrieved 2010-06-03.
- Stoichev, Stoicho D. (2019), «New Exact and Heuristic Algorithms for Graph Automorphism Group and Graph Isomorphism», Journal of Experimental Algorithmics, 24: 1–27, doi:10.1145/3333250, S2CID 202676274.
Software[edit]
- Graph Isomorphism, review of implementations, The Stony Brook Algorithm Repository.
ПРАКТИЧЕСКАЯ РАБОТА №4
ОПРЕДЕЛЕНИЕ ИЗОМОРФНОСТИ ГРАФОВ
-
ОБЩИЕ СВЕДЕНИЯ
Отображение графов — это отображение
множеств вершин, которое сохраняет
отношение смежности и, таким образом,
индуцирует вполне определенное
отображение на множестве ребер.
Графы G1=(V1,E1) и G2=(V2,E2) называются изоморфными
(обозначение G1~G2), если между графами
существует взаимнооднозначное отображение
j: G1~G2 (V1~V2, E1~E2), которое сохраняет
соответствие между ребрами (дугами)
графов, т.е. для любого ребра (дуги)
e=(v,u) верно:
e’=j(v,u)=(j(v),j(u))
(e~E1, e’~E2) (1)
Отображение j называется изоморфным
отображением.
Дадим другое определение изоморфности:
два графа G1 и G2
называются изоморфными, если между их
вершинами установлено взаимнооднозначное
соответствие, такое, что любые две
вершины графа G1 соединены
так же, как и соответствующие вершины
графа G2
Рассмотрим графы 1 и 2

Рисунок 1 Изоморфные
графы
На рисунке 1 видно, что между графами
существует взаимнооднозначное
соответствие, то есть, например, ребро
(2,6) первого графа подобно ребру
(2,6) второго графа. Это можно наблюдать
для всех вершин и ребер.
Иными словами, изоморфные
графы различаются только обозначением
вершин.
Условимся называть
(0,1)-матрицу булевой,
если с её элементами
мы намерены обращаться по правилам
булевой алгебры.
Изоморфизм графов можно
определить в матричных терминах.
Предварительно введём понятие
перестановочного подобия матриц.
Оно формулируется одинаково для булевых
матриц и матриц над полем.
Квадратная (0,1)-матрица P называется
перестановочной, если она имеет в
каждой строке и каждом столбце ровно
одну единицу. Легко проверить, что тогда
![]()
Матрицы A и B называются перестановочно
подобными, если
![]()
для некоторой перестановочной матрицы
P. Содержательный смысл этого определения
заключается в том, что A получается из
B одинаковыми перестановками строк и
столбцов.
Пусть графы с n вершинами, заданные
матрицами смежности A и B, изоморфны, то
есть существует такая биекция
(перестановка) σ на множестве {1,2, … , n},
что для любых ij
![]()
(2)
Сопоставим перестановке перестановочную
матрицу P = (p) порядка n, где

(3)
Прямыми вычислениями проверяется, что
![]()
(4)
Итак, если графы изоморфны, то их матрицы
смежности перестановочно подобны.
Наоборот, если матрицы смежности
перестановочно подобны, то графы
изоморфны, причем изоморфизм σ определяется
по матрице подобия P из равенств (3).
Вывод: графы изоморфны тогда и только
тогда, когда их матрицы смежности
перестановочно подобны.
В
соответствии с определением изоморфизма
графов у нас появляются варианты для
организации проверки изоморфизма
графов: либо мы для каждой пары графов
ищем свое взаимнооднозначное соответствие,
сохраняющее смежность; либо мы каждому
графу взаимнооднозначно сопоставляем
элемент некоторого одного и того же
множества, сохраняющий информацию о
смежности вершин графа, а затем ищем
взаимнооднозначное соответствие между
элементами этого множества. Понятно,
что в последнем случае нас также
интересует взаимнооднозначное
соответствие, которое сохраняло бы
информацию о смежности. В силу того, что
взаимнооднозначное соответствие,
сохраняющее смежность, рефлексивно,
симметрично и транзитивно, т.е. является
отношением эквивалентности, эти два
варианта организации проверки изоморфизма
графов равнозначны относительно
результата.
В
качестве упоминаемого выше множества,
элементам которого взаимнооднозначно
сопоставляются графы, можно взять
множество матриц смежности, поскольку
каждая матрица смежности несет в себе
информацию о смежности вершин графа.
Тогда в качестве соответствующего
взаимнооднозначного соответствия между
парами матриц смежности будет отношение
перестановочного подобия.
Для последующего рассмотрения алгоритма
определения изоморфности двух графов
дадим определение связных вершин и
подграфа.
Вершины в графе связаны,
если существует соединяющая их (простая)
цепь,
где цепь в графе — маршрут,
все рёбра которого различны. Если все
вершины
(а тем самым и рёбра) различны, то такая
цепь называется простой (элементарной).
Граф называется связным,
если любые две его
вершины связаны. Если граф не связен,
то он представляет собой объединение
нескольких связных подграфов.
Граф
![]()
называется подграфом
графа (V,E),
если
![]()
![]() .
.
Например, цепь в графе
можно рассматривать как подграф. Говорят,
что подграф порождён
подмножеством вершин
![]() если
если
![]()
состоит из рёбер,
соединяющих вершины из
![]() .
.
Говорят, что подграф
порождён подмножеством
рёбер
![]()
если
![]()
состоит из концов рёбер из
![]() .
.
Легко убедиться, что бинарное
отношение связанности на множестве
вершин графа рефлексивно, симметрично
и транзитивно, то есть, связанность
вершин является отношением эквивалентности.
Замечание. Многие
практические задачи приводят к
необходимости распознавания изоморфизма
и изоморфного вложения сложных структур,
заданных в виде графов. С содержательной
точки зрения изоморфизм графов структур
означает тождественность функционирования
самих структур, что допускает в некоторых
случаях замену одной структуры другой,
ей изоморфной. Однако для того чтобы
выяснить, изоморфны ли два графа имеющие
![]() вершин,
вершин,
в общем случае требуется выполнить
![]() попарных
попарных
сравнений, а для распознавания изоморфного
вложения графа
![]() ,
,
имеющего
![]() вершин,
вершин,
в граф
![]() ,
,
у которого
![]() вершин,
вершин,
необходимо провести
![]() сравнений.
сравнений.
Поэтому даже при относительно небольшом
количестве элементов в графах (порядка
100) решение задачи об изоморфизме методом
полного перебора практически не реально,
необходимо использовать для этой цели
специальные методы.
2. ЦЕЛЬ И ПОРЯДОК РАБОТЫ
Цель работы — научится определять
изоморфность двух графов.
Порядок работы:
-
изучить описание работы;
-
согласно своему варианту, решить
заданные примеры без использования
ЭВМ; -
написать и отладить программу в
соответствии с заданием; -
оформить отчет.
3. ЗАДАНИЯ
3.1 Задания для ручного просчета:
Для данных графов выяснить, являются
ли они изоморфными. Если да, то установить
изоморфизм, в противном случае доказать,
почему графы неизоморфны.
Пример.
Даны два графа. Выяснить, являются ли
они изоморфными.

Покажем, что данные графы изоморфны.



 Действительно,
Действительно,
отображение a e, b f, c g, d h, являющееся
изоморфизмом легко представить как
модификацию первого графа, передвигающую
вершину d в центр рисунка.
Составим матрицу смежности для первого
графа:
|
a |
b |
c |
d |
|
|
a |
0 |
1 |
1 |
1 |
|
b |
1 |
0 |
1 |
1 |
|
c |
1 |
1 |
0 |
1 |
|
d |
1 |
1 |
1 |
0 |
Составим матрицу смежности для второго
графа:
|
e |
f |
g |
h |
|
|
e |
0 |
1 |
1 |
1 |
|
f |
1 |
0 |
1 |
1 |
|
g |
1 |
1 |
0 |
1 |
|
h |
1 |
1 |
1 |
0 |
Так как соответствующие матрицы смежности
одинаковы, то графы 1 и 2 изоморфны.
Решите задание вашего варианта.
 Вариант
Вариант
1

Вариант 2
 Вариант
Вариант
3

Вариант 4
 Вариант
Вариант
5
 Вариант
Вариант
6

Вариант 7
 Вариант
Вариант
8
 Вариант
Вариант
9

Вариант 10
3.2 Задания для вычисления с помощью
программы:
Для заданных пользователем графов
определить изоморфность (результатом
программы является вывод «да-нет» в
зависимости от заданных графов)
4. МЕТОДИЧЕСКИЕ УКАЗАНИЯ
Для проверки изоморфности графов можно
использовать следующий модуль (C#):
//проверка изоморфности подграфов
//int[, ,] X — матрица смежности подграфа
//int f1, int f2 — счетчики
//int k — кол-во вершин подграфа
//f1,f2 — номера
подграфов
bool izomorf(int[, ,] X, int f1, int f2, int k)
{
int i, j, f;
bool b;
int n = 1;
for (i = 1; i <= k; i++) n = n * i;
int[,] M = new int[n, k]; //массив перстановок
вершин,
perestan(M, k); //построение массива
перестановок вершин
//сравнение подграфов с перестановкой
строк и столбцов
for (f = 1; f < n; f++)
{
b = true;
for (i = 0; i < k; i++)
{
for (j = 0; j < k; j++)
if (X[f1, i, j] != X[f2, M[f, i], M[f, j]])
{
b = false; break;
}
if (!b) break;
}
if (b) return true;
}
return false;
}//izomorf
5. СОДЕРЖАНИЕ ОТЧЕТА
-
наименование работы, постановку задачи;
-
выбранный вариант задания;
-
результаты решения задач без применения
ЭВМ; -
программу решения задачи (представляется
в электронном виде); -
результаты работы программы и их анализ.
6. КОНТРОЛЬНЫЕ ВОПРОСЫ
-
Какие графы называются изоморфными?
-
Докажите, что графы на рис. 1 изоморфны
(выпишите все соответствующие
вершины и ребра). -
Дайте определение булевой матрицы.
-
Объясните понятие перестановочного
подобия матриц. -
Известно, что если графы изоморфны, то
их матрицы смежности перестановочно
подобны. Верно ли это утверждение
наоборот? -
В каком случае вершины u
и v связны? -
Какой граф называется подграфом?
-
Среди данных графов выберете изоморфные
и неизоморфные графы.

7. ОСНОВНАЯ ЛИТЕРАТУРА
-
Ф. А. Новиков, Дискретная математика
для программистов: Учеб. пособие для
ВУЗов по направлениям: «Информатика и
вычислительная техника»/Ф. А. Новиков
– 2-е изж. – М. Спб.: Питер, 2007 – 363 с. -
А. И. Белоусов Дискретная математика:
Учеб. пособие для втузов/Белоусов А.
И., Ткачев С. Б., Под ред. Зарубина В. С.,
Ирищенко А. П. – 3-е изд., стер. – М.: Изд-во
МГТУ им. Баумана, 2004. – 743 с. -
Оре, Ойстин Теория графов/ Пер. с
англ. И. Н. Врублевской. Под редакцией
Н. Н. Воробьева –2-е изд. Стереотипное.
М.: Наука, 1980.-336с -
Горбатов В. А. Дискретная математика:
Учеб. для втузов В. А. Горбатов. – М.АСТ;
Астель, 2003 – 447с (Высшая школа)
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
1. О.
П. Кузнецов «Дискретная математика
для инженера».
Издательство:
Лань,
2007 г., 400 стр.
2.Н.
И. Костюкова Графы и их применение.
Комбинаторные алгоритмы для программистов.
Издательства:
Интернет-университет
информационных технологий, Бином.
Лаборатория знаний, 2007 , 312 стр.
3. В.
Ф. Пономарев «Дискретная
математика для инженеров»
Издательство:
Горячая
Линия — Телеком, 2009 г. Мягкая
обложка, 320 стр.
4. Род
Хаггарти «Дискретная
математика для программистов. Discrete
Mathematics for
Computing».
Издательство:
Техносфера,
2005 г. Твердый переплет, 400 стр.
10
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Абстрактно, изоморфизмом называют обратимое отображение (биекцию) между двумя множествами, наделенными какой-то структурой, с сохранением этой структуры.
Например, два графа называются изоморфными, если вершинам одного графа можно сопоставить вершины другого графа, так чтобы соединённым вершинам первого графа соответствовали соединённые вершины второго графа и наоборот. Иными словами, два графа изоморфны, если они «одинаковы» с точностью до переименования вершин.
Хороший общий способ выполнять проверки на изоморфизм — посчитать от них какую-то хеш-функцию, значение которой не изменяется от переименования объектов, и сравнить её значение.
#Множества
Пусть мы хотим научиться сравнивать множества чисел или строк на равенство с
точностью до перестановки.
Например:
$$
{1, 2, 3} = {2, 1, 3}
\ {«lal», «abc»} = {«abc», «lal»}
\ {4, 5} neq {5, 6}
\ {«lal», «abc»} neq {«abc», «all»}
$$
Эту задачу можно решить, если отсортировать это множество и посчитать полиномиальный хеш от получившейся последовательности. Результат не будет зависеть от изначальной перестановки элементов, и таким образом мы решим задачу за $O(n log n)$. Но задачу можно решить и за линейное время.
Сопоставим всем возможным ключам различные 64-битные случайные числа (будем называть их хешом ключа), а хешом множества тогда будем считать xor-сумму хешей всех входящих в него ключей. Тогда хеши равных с точностью до перестановки множеств будут одинаковые из-за коммутативности xor, а вероятность коллизии будет в точности равна $frac{1}{2^{64}}$.
Сопоставить хеши ключам можно либо хеш-функцией, либо, если количество различных значений ключей невелико, предподсчитанной таблицей случайных чисел. В обоих случаях подсчет хеша множества потребует подсчет $O(n)$ хешей ключей.
Этот метод также примечателен тем, что пересчет хешей от множеств можно проводить за $O(1)$ при определенных изменениях, таких как добавление элемента в множество, удаление элемента из множества или слияние двух непересекающихся множеств.
#Игры
Последний метод можно обобщить для хеширования позиций в абстрактных играх вроде шахмат или шашек.
Быстрый способ пересчета хеша позиций критически важен для реализации компьютерных стратегий для этих игр, потому что большинство из них основываются на переборе всех возможных ходов, который будет работать быстрее, если запоминать результаты и не запускать перебор дважды из одной и той же вершины. Для этого нужно завести хеш-таблицу, в которую нужно складывать хеши и посчитанные результаты от посещенных позиций, для чего в свою очередь нужно уметь их быстро пересчитывать.
На примере шахмат, у нас есть $8 times 8 = 64$ поля, каждое из которых может быть в одном из $6 times 2 + 1 = 13$ возможных состояний (на нем может стоять король, ферзь, ладья, конь, слон или пешка одного из двух цветов или ничего). Сгенерируем $64 times 13 = 832$ случайных 64-битных чисел — каждое будет соответствовать факту, что на такой-то позиции стоит такая-то фигура. Теперь пройдемся по всем полям и посчитаем xor-сумму. Получившееся 64-битное число и будет хешом позиции.
Помимо того, что его легко посчитать (64 раз посмотреть в lookup-таблицу быстрее, чем считать полиномиальные хеши по модулю), его ещё можно очень быстро пересчитывать, если изменение позиции было небольшим. А именно, если сделан один ход, то будут затронуты всего две ячейки, и хеш позиции нужно проксорить с ровно 4 числами (двумя старыми, чтобы их удалить, и двумя новыми, чтобы их добавить).
С поправкой на возможность рокировки, взятие на проходе, симметрию цветов, невозможность поместить пешки на первый и последний ряд, и несколько других шахматных нюансов, мы описали то, что называется хешированием Зобриста.
#Подматрицы
Задача. Дана матрица $A_{i, j}$ размера $n times m$, состоящая из чисел. Требуется отвечать на запросы, равны ли подматрицы $A_{x_1:x_2, y_1:y_2}$ и $A_{x_3:x_4, y_3:y_4}$.
Если посмотреть на матрицу как на набор строк, то сравнивать подматрицы это то же самое, что сравнивать набор подстрок на равенство, что мы уже умеем делать хешами. Если предпосчитать массив полиномиальных хешей от каждой строки матрицы и сравнивать хеши за константу, то каждый запрос будет работать за $O(n)$, что не очень быстро, но хотя бы не $O(n^2)$.
#Двумерный хеш
Давайте обобщим идею полиномиального хеширования строк на матрицы. Для этого нам понадобится два разных $k$ — «горизонтальный» $k_h$ и «вертикальный» $k_v$. Положим теперь
$$
h(A_{x_1:x_2, y_1:y_2})
=
sum_{i=x_1}^{x_2}
sum_{j=y_1}^{y_2}
A_{i,j} cdot k_h^i cdot k_v^j
$$
Предподсчитаем такие хеши для всех угловых подматриц (обобщение понятия префикс строки):
$$
h(x, y) = h(A_{:x, :y})
$$
Заметим, что для всех угловых подматриц, которые содержат только первую строку или первый столбец, определение хеша совпадает с определением полиномиального хеша для строки, а значит такие хеши мы умеем предподсчитать за линию.
Теперь заметим, что для всех остальных подматриц
$$
h(x, y) = A_{x, y} k_h^x k_v^y + h(x — 1, y) + h(x, y — 1) — h(x — 1, y — 1)
$$
Таким образом, мы можем посчитать хеш за $O(n^2)$ таким же методом, как для двумерных префиксных сумм.
Теперь мы можем выполнять проверку на равенство за $O(1)$, считая хеш от подматриц через префиксные суммы. Единственным нюансом остается то, что этот хеш будет «сдвинут» на $k_h^{x_1} cdot k_v^{y_1}$ — это можно исправить, либо поделив по модулю на него, либо домножив хеш от подматриц на $k_h^{n-x_1} cdot k_v^{m-y_1}$.
Примечание. Можно определять не два разных $k_h$ и $k_v$, а одно, если мысленно соединить все строки матрицы в одну. Это эквивалентно тому, что сделать $k_h = k_v^m$.
#Корневые деревья
Теперь мы хотим научиться проверять корневые деревья на изоморфизм, то есть на равенство с точностью до перенумерования вершин, при том, что известно, что корень одного дерева обязательно переходит в корень другого дерева.
#Хеш от вершины
Заметим, что поскольку мы не можем апеллировать к номерам вершин, единственная информация, которую мы можем использовать — это структура нашего дерева.
Положим тогда хешем вершины без детей какую-нибудь константу (например, 179), а для вершины с детьми положим в качестве хеша некоторую функцию от отсортированного (поскольку мы не знаем истинного порядка, в котором дети должны идти, нужно привести их к одинаковому виду) списка хешей детей.
Хешом корневого дерева будем считать хеш корня. Индукцией построению можно показать, что у изоморфных корневых деревьев хеши совпадают.
Единственный нюанс заключается в том, что стандартный полиномиальный хеш для агрегации хешей от детей не подходит. Например, рассмотрим 2 дерева:
$$
begin{aligned}
T_1 &= { (1, 2), (1, 3), (1, 4) }
\ T_2 &= { (1, 2), (1, 3), (3, 4), (3, 5) }
end{aligned}
$$
Если в качестве функции от детей взять полиномиальный хеш, то получим:
$$
h(T_1) = 179 + 179p + 179p^2 = 179 + p(179 + 179p) = h(T_2)
$$
В качестве неплохой хеш-функции подойдёт, например
$$
h(v) = 42 + sum_u log(h(u))
$$
Для этой хеш-функции может показаться, что можно не сортировать хеши детей, однако это не так, потому что при вычислении чисел с плавающей точкой у нас возникает погрешность, и чтобы это результат суммирования был одинаковый для изоморфных деревьев, суммировать детей надо тоже в одинаковом порядке.
Пример более сложной хеш-функции:
$$
h(v) = sum_u h(u)^2 + h(u) cdot p^i + 42 bmod m
$$
В любом случае, асимптотика будет $O(n log n$, так как всё что нам нужно делать в каждой вершине — это сортировка детей по хешу и суммирование. Так как у нас могут быть два изоморфных ребенка с одинаковым хешом, трюки с xor— и другими суммами не работают, и поэтому быстрее нельзя.
#Некорневые деревья
Для некорневых деревьев можно найти центроид и запуститься от него как от корневого. Если центроидов два, то можно запуститься от двух центроидов, посчитать два хеша, упорядочить (свапнуть если hash_a меньше hash_b) и посчитать мини-хеш от них (hash = hash_a + k * hash_b).