Для
характеристики рассеяния значений
количественного признака X
генеральной
совокупности вокруг своего среднего
значения служат понятия генеральной
дисперсии и генерального среднего
квадратического отклонения.
Генеральной
дисперсией
DT
называется
среднее арифметическое квадратов
отклонения значений признака X
генеральной
совокупности от их среднего значения![]()
Если все значения ![]()
признака
генеральной совокупности объема N
являются
различными, то
![]()
(9.23)
Если
значения x1,
x2,
…, xk
имеют соответственно частоты
N1,
N2,..,Nk
причем
N1+
N2+…+,Nk=N
,
то
![]()
(9.24)
Генеральным
средним квадратическим отклонением
![]()
называется
корень квадратный из генеральной
дисперсии, т.е.
![]()
(9.25)
Для
характеристики рассеяния значений
количественного признака выборки вокруг
среднего значения ![]()
вводят
понятия выборочной дисперсии и выборочного
среднего квадратического отклонения
Выборочной
дисперсией
DB
называют среднее арифметическое
квадратов отклонения наблюдаемых
значений выборки от их среднего
значения![]()
.
Если
все значения![]()
,
признака выборки объема n
различны,
то
![]()
(9.26)
Если
значения x1,
x2,
…, xk
имеют соответственно частоты n1,
n2, …,
nk,
причем
n1+n2+…+nk=n,
то
![]()
(9.27)
Выборочное
среднее квадратическое отклонение
![]()
определяется
формулой
![]()
(9.28)
Для
вычисления выборочной дисперсии можно
пользоваться формуло
DB=![]()
,
(9.29)
где
![]()
![]()
(9.30)
Докажем
формулу (9.29). Преобразуя формулу (9.27),
получаем
DВ=![]()
Из
формулы (9.24) аналогично находим
![]()
.
Следовательно,
для обоих случаев
![]()
(9.31)
где
x2
–
среднее квадратов значение; (x2)
– квадрат общей средней.
Можно
доказать, что
![]()
(9.32)
Так
как
![]()
,
то выборочная дисперсия DВ
является смещенной оценкой генеральной
дисперсии DГ
.
Чтобы получить несмещенную оценку
генеральной дисперсии
DГ,
вводят понятие так называемой эмпирической
(или исправленной) дисперсии s2.
Эмпирическая,
или исправленная,
дисперсия
s2
определяется
формулой
![]()
![]()
![]()
![]()
(9.33)
Исправленная
дисперсия (9.33) является несмешанной
оценкой генеральной дисперсии, так как
M(
)=M(![]()
![]()
![]()
Для
оценки среднего квадратического
отклонения генеральной совокупности
служит «исправленное» среднее
квадратическое отклонение, или
эмпирический стандарт
s=![]()
(9.34)
В
случае, когда все значения x1,
x2,
…, xn
различны,
т.е. все ni=1
и k
= n,
формулы
(9.33)
и (9.34) принимают вид
![]()
(9.35)
![]()
(9.36)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
30.04.2022143.36 Кб0Учебное пособие 40024.doc
- #
- #
Как найти дисперсию?
Полезная страница? Сохрани или расскажи друзьям
Дисперсия — это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая — значения сравнительно близки друг к другу, если большая — далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии — среднеквадратическое отклонение $sigma(X)=sqrt{D(X)}$, которое имеет ту же размерность, что и исходная величина и также описывает разброс.
Еще одно формальное определение дисперсии звучит так: «Дисперсия — это второй центральный момент случайной величины» (напомним, что первый начальный момент — это как раз математическое ожидание).
Нужна помощь? Решаем теорию вероятностей на отлично
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле:
$$
D(X)=M(X-M(X))^2,
$$
которую также часто записывают в более удобном для расчетов виде:
$$
D(X)=M(X^2)-(M(X))^2.
$$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2.
$$
Если же речь идет о непрерывной случайной величине (заданной плотностью вероятностей $f(x)$ в общем случае), формула дисперсии Х выглядит следующим образом:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения:
$$
x_i quad 1 quad 2 \
p_i quad 0.5 quad 0.5
$$
и
$$
y_i quad -10 quad 10 \
p_i quad 0.5 quad 0.5
$$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором — дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2 =\
= 1^2cdot 0.5 + 2^2 cdot 0.5 — (1cdot 0.5 + 2cdot 0.5)^2=2.5-1.5^2=0.25.
$$
$$
D(Y)=sum_{i=1}^{n}{y_i^2 cdot p_i}-left(sum_{i=1}^{n}{y_i cdot p_i} right)^2 =\
= (-10)^2cdot 0.5 + 10^2 cdot 0.5 — (-10cdot 0.5 + 10cdot 0.5)^2=100-0^2=100.
$$
Итак, значения случайных величин различались на 1 и 20 единиц, тогда как дисперсия показывает меру разброса в 0.25 и 100. Если перейти к среднеквадратическому отклонению, получим $sigma(X)=0.5$, $sigma(Y)=10$, то есть вполне ожидаемые величины: в первом случае значения отстоят в обе стороны на 0.5 от среднего 1.5, а во втором — на 10 единиц от среднего 0.
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Снова используем формулу для дисперсии дискретной случайной величины:
$$
D(X)=M(X^2)-(M(X))^2.
$$
В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Потом математическое ожидание квадрата случайной величины:
$$
M(X^2)=sum_{i=1}^{n}{x_i^2 cdot p_i}
= (-1)^2cdot 0.1 + 2^2 cdot 0.2 +5^2cdot 0.3 +10^2cdot 0.3+20^2cdot 0.1=78.4.
$$
А потом подставим все в формулу для дисперсии:
$$
D(X)=M(X^2)-(M(X))^2=78.4-6.8^2=32.16.
$$
Дисперсия равна 32.16 квадратных единиц.
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Вычислим сначала математическое ожидание:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{6} frac{x}{18} cdot x dx = int_{0}^{6} frac{x^2}{18} dx =
left.frac{x^3}{54} right|_0^6=frac{6^3}{54} = 4.
$$
Теперь вычислим
$$
M(X^2)=int_{-infty}^{+infty} f(x) cdot x^2 dx = int_{0}^{6} frac{x}{18} cdot x^2 dx = int_{0}^{6} frac{x^3}{18} dx = left.frac{x^4}{72} right|_0^6=frac{6^4}{72} = 18.
$$
Подставляем:
$$
D(X)=M(X^2)-(M(X))^2=18-4^2=2.
$$
Дисперсия равна 2.
Другие задачи с решениями по ТВ
Подробно решим ваши задачи на вычисление дисперсии
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку «Вычислить».
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Лучшее спасибо — порекомендовать эту страницу
Полезные ссылки
Не забывайте сначала прочитать том, как найти математическое ожидание. А тут можно вычислить также СКО: Калькулятор математического ожидания, дисперсии и среднего квадратического отклонения.
Что еще может пригодиться? Например, для изучения основ теории вероятностей — онлайн учебник по ТВ. Для закрепления материала — еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Сейчас Вы научитесь находить числовые характеристики статистического распределения выборки. Примеры подобраны на основании индивидуальных заданий по теории вероятностей, которые задавали студентам ЛНУ им. И. Франка. Ответы послужат для студентов математических дисциплин хорошей инструкцией на экзаменах и тестах. Подобные решения точно используют в обучении экономисты , поскольку именно им задавали все что приведено ниже. ВУЗы Киева, Одессы, Харькова и других городов Украины имеют подобную систему обучения поэтому много полезного для себя должен взять каждый студент. Задачи различной тематики связаны между собой линками в конце статьи, поэтому можете найти то, что Вам нужно.
Индивидуальное задание 1
Вариант 11
Задача 1. Построить статистическое распределение выборки, записать эмпирическую функцию распределения и вычислить такие числовые характеристики:
- выборочное среднее;
- выборочную дисперсию;;
- подправленную дисперсию;
- выборочное среднее квадратичное отклонение;
- подправленное среднее квадратичное отклонение;
- размах выборки;
- медиану;
- моду;
- квантильное отклонение;
- коэффициент вариации;
- коэффициент асимметрии;
- эксцесс для выборки:
Выборка задана рядом 11, 9, 8, 7, 8, 11, 10, 9, 12, 7, 6, 11, 8, 7, 10, 9, 11, 8, 13, 8.
Решение:
Запишем выборку в виде вариационного ряда (в порядке возрастания):
6; 7; 7; 7; 8; 8; 8; 8; 8; 9; 9; 9; 10; 10; 11; 11; 11; 11; 12; 13.
Далее записываем статистическое распределение выборки в виде дискретного статистического распределения частот:
![]()
Эмпирическую функцию распределения определим по формуле
![]()
Здесь nx – количество элементов выборки которые меньше х. Используя таблицу и учитывая что объем выборки равен n = 20, запишем эмпирическую функцию распределения:

Далее вычислим числовые характеристики статистического распределения выборки.
Выборочное среднее вычисляем по формуле
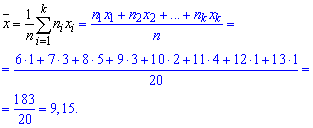
Выборочную дисперсию находим по формуле
![]()
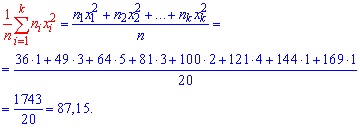
Выборочное среднее, что фигурирует в формуле дисперсии в квадрате найдено выше. Остается все подставить в формулу
![]()
Подправленную дисперсию вычисляем согласно формулы
![]()
Выборочное среднее квадратичное отклонение вычисляем по формуле
![]()
Подправленное среднее квадратичное отклонение вычисляем как корень из подправленной дисперсии
![]()
Размах выборки вычисляем как разность между наибольшим и наименьшим значениями вариант, то есть:
![]()
Медиану находим по 2 формулам:
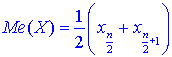 если число n — четное;
если число n — четное;
![]() если число n — нечетное.
если число n — нечетное.
Здесь берем индексы в xi согласно нумерации варианта в вариационном ряду.
В нашем случае n = 20, поэтому
![]()
Мода – это варианта которая в вариационном ряду случается чаще всего, то есть
![]()
Квантильное отклонение находят по формуле
![]()
где ![]() – первый квантиль,
– первый квантиль, ![]() – третий квантиль.
– третий квантиль.
Квантили получаем при разбивке вариационного ряда на 4 равные части.
Для заданного статистического распределения квантильное отклонения примет значение
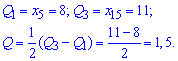
Коэффициент вариации равный процентному отношению подправленного среднего квадратичного к выборочному среднему
![]()
Коэффициент асимметрии находим по формуле
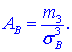
Здесь 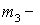 центральный эмпирический момент 3-го порядка,
центральный эмпирический момент 3-го порядка,
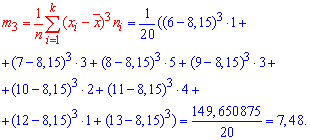
Подставляем в формулу коэффициента асимметрии
![]()
Эксцессом ![]() статистического распределения выборки называется число, которое вычисляют по формуле:
статистического распределения выборки называется число, которое вычисляют по формуле:
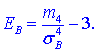
Здесь m4 центральный эмпирический момент 4-го порядка. Находим момент
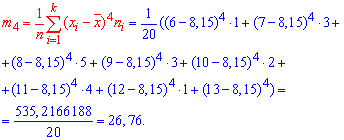
а далее эксцесс![]()
Теперь Вы имеете все необходимые формулы чтобы найти числовые характеристики статистического распределения. Как найти моду, медиану и дисперсию должен знать каждый студент, который изучает теорию вероятностей.
Готовые решения по теории вероятностей
- Следующая статья — Построение уравнения прямой регрессии Y на X
![]()
Загрузить PDF
![]()
Загрузить PDF
Дисперсия случайной величины является мерой разброса значений этой величины. Малая дисперсия означает, что значения сгруппированы близко друг к другу. Большая дисперсия свидетельствует о сильном разбросе значений. Понятие дисперсии случайной величины применяется в статистике. Например, если сравнить дисперсию значений двух величин (таких как результаты наблюдений за пациентами мужского и женского пола), можно проверить значимость некоторой переменной.[1]
Также дисперсия используется при построении статистических моделей, так как малая дисперсия может быть признаком того, что вы чрезмерно подгоняете значения.[2]
-

1
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
2
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:[3]
-
3
Вычислите среднее значение выборки. Оно обозначается как x̅.[4]
Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
4
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность
— x̅, где – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.[5]
-
5
Возведите в квадрат каждый полученный результат. Как отмечалось выше, сумма разностей
— x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность — x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.[6]
-
6
-
7
Полученный результат разделите на n — 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n — 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.[7]
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
8
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как
, а стандартное отклонение выборки – как .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Реклама












-
1
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
-
2
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные: [8]
-
3
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = = 10,5
-
4
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере: — μ = 5 — 10,5 = -5,5 — μ = 5 — 10,5 = -5,5 — μ = 8 — 10,5 = -2,5 — μ = 12 — 10,5 = 1,5 — μ = 15 — 10,5 = 4,5 — μ = 18 — 10,5 = 7,5
- В нашем примере:
-
5
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( — μ) для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) = 30,25
(-5,5) = 30,25
(-2,5) = 6,25
(1,5) = 2,25
(4,5) = 20,25
(7,5) = 56,25
- В нашем примере:
-
6
Найдите среднее значение полученных результатов. Вы нашли, как далеко каждое значение совокупности расположено от ее среднего значения. Найдите среднее значение суммы квадратов разностей, поделив ее на количество значений в генеральной совокупности.
- В нашем примере:
Дисперсия совокупности = 24,25
- В нашем примере:
-
7
Соотнесите это решение с формулой. Если вы не поняли, как приведенное выше решение соотносится с формулой, ниже представлено объяснение решения:
Реклама
















Советы
- Дисперсию довольно сложно интерпретировать, поэтому в большинстве случаев она вычисляется как промежуточная величина, которая необходима для нахождения стандартного отклонения.
- При вычислении дисперсии выборки деление на n-1, а не просто на n, называется коррекцией Бесселя. Дисперсия выборки представляет собой только оценочное значение дисперсии генеральной совокупности, при этом выборочное среднее смещено, чтобы соответствовать этому оценочному значению. Коррекция Бесселя устраняет такое смещение.[9]
Это связано с тем, что при анализе n – 1 значения использование n-го значения уже ограничено, так как только определенные значения приводят к выборочному среднему (x̅), которое используется в формуле для вычисления дисперсии.[10]
Реклама
Об этой статье
Эту страницу просматривали 122 353 раза.
Была ли эта статья полезной?
From Wikipedia, the free encyclopedia

The green curve, which asymptotically approaches heights of 0 and 1 without reaching them, is the true cumulative distribution function of the standard normal distribution. The grey hash marks represent the observations in a particular sample drawn from that distribution, and the horizontal steps of the blue step function (including the leftmost point in each step but not including the rightmost point) form the empirical distribution function of that sample. (Click here to load a new graph.)
In statistics, an empirical distribution function (commonly also called an empirical Cumulative Distribution Function, eCDF) is the distribution function associated with the empirical measure of a sample.[1] This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
The empirical distribution function is an estimate of the cumulative distribution function that generated the points in the sample. It converges with probability 1 to that underlying distribution, according to the Glivenko–Cantelli theorem. A number of results exist to quantify the rate of convergence of the empirical distribution function to the underlying cumulative distribution function.
Definition[edit]
Let (X1, …, Xn) be independent, identically distributed real random variables with the common cumulative distribution function F(t). Then the empirical distribution function is defined as[2]

where  is the indicator of event A. For a fixed t, the indicator
is the indicator of event A. For a fixed t, the indicator  is a Bernoulli random variable with parameter p = F(t); hence
is a Bernoulli random variable with parameter p = F(t); hence  is a binomial random variable with mean nF(t) and variance nF(t)(1 − F(t)). This implies that
is a binomial random variable with mean nF(t) and variance nF(t)(1 − F(t)). This implies that  is an unbiased estimator for F(t).
is an unbiased estimator for F(t).
However, in some textbooks, the definition is given as
- [3][4]

Mean[edit]
The mean of the empirical distribution is an unbiased estimator of the mean of the population distribution.

which is more commonly denoted 
Variance[edit]
The variance of the empirical distribution times  is an unbiased estimator of the variance of the population distribution, for any distribution of X that has a finite variance.
is an unbiased estimator of the variance of the population distribution, for any distribution of X that has a finite variance.
![{displaystyle {begin{aligned}operatorname {Var} (X)&=operatorname {E} left[(X-operatorname {E} [X])^{2}right]\[4pt]&=operatorname {E} left[(X-{bar {x}})^{2}right]\[4pt]&={frac {1}{n}}left(sum _{i=1}^{n}{(x_{i}-{bar {x}})^{2}}right)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/856a9443ed6145aee944520e94efa625bfadd3bd)
Mean squared error[edit]
The mean squared error for the empirical distribution is as follows.
![{displaystyle {begin{aligned}operatorname {MSE} &={frac {1}{n}}sum _{i=1}^{n}(Y_{i}-{hat {Y_{i}}})^{2}\[4pt]&=operatorname {Var} _{hat {theta }}({hat {theta }})+operatorname {Bias} ({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2928ea7b7ebfcad86439fae9b35ad4f576eaabfe)
Where  is an estimator and
is an estimator and  an unknown parameter
an unknown parameter
Quantiles[edit]
For any real number  the notation
the notation  (read “ceiling of a”) denotes the least integer greater than or equal to . For any real number a, the notation
(read “ceiling of a”) denotes the least integer greater than or equal to . For any real number a, the notation  (read “floor of a”) denotes the greatest integer less than or equal to .
(read “floor of a”) denotes the greatest integer less than or equal to .
If  is not an integer, then the
is not an integer, then the  -th quantile is unique and is equal to
-th quantile is unique and is equal to 
If is an integer, then the -th quantile is not unique and is any real number  such that
such that

Empirical median[edit]
If  is odd, then the empirical median is the number
is odd, then the empirical median is the number

If is even, then the empirical median is the number

Asymptotic properties[edit]
Since the ratio (n + 1)/n approaches 1 as n goes to infinity, the asymptotic properties of the two definitions that are given above are the same.
By the strong law of large numbers, the estimator  converges to F(t) as n → ∞ almost surely, for every value of t:[2]
converges to F(t) as n → ∞ almost surely, for every value of t:[2]

thus the estimator is consistent. This expression asserts the pointwise convergence of the empirical distribution function to the true cumulative distribution function. There is a stronger result, called the Glivenko–Cantelli theorem, which states that the convergence in fact happens uniformly over t:[5]

The sup-norm in this expression is called the Kolmogorov–Smirnov statistic for testing the goodness-of-fit between the empirical distribution and the assumed true cumulative distribution function F. Other norm functions may be reasonably used here instead of the sup-norm. For example, the L2-norm gives rise to the Cramér–von Mises statistic.
The asymptotic distribution can be further characterized in several different ways. First, the central limit theorem states that pointwise, has asymptotically normal distribution with the standard  rate of convergence:[2]
rate of convergence:[2]

This result is extended by the Donsker’s theorem, which asserts that the empirical process  , viewed as a function indexed by
, viewed as a function indexed by  , converges in distribution in the Skorokhod space
, converges in distribution in the Skorokhod space ![scriptstyle D[-infty ,+infty ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/3215d9f75e16a202f9c838f5664d27e250e93b9b) to the mean-zero Gaussian process
to the mean-zero Gaussian process  , where B is the standard Brownian bridge.[5] The covariance structure of this Gaussian process is
, where B is the standard Brownian bridge.[5] The covariance structure of this Gaussian process is
![{displaystyle operatorname {E} [,G_{F}(t_{1})G_{F}(t_{2}),]=F(t_{1}wedge t_{2})-F(t_{1})F(t_{2}).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b540ccd042666531c829625255e117fabd2d112e)
The uniform rate of convergence in Donsker’s theorem can be quantified by the result known as the Hungarian embedding:[6]

Alternatively, the rate of convergence of can also be quantified in terms of the asymptotic behavior of the sup-norm of this expression. Number of results exist in this venue, for example the Dvoretzky–Kiefer–Wolfowitz inequality provides bound on the tail probabilities of  :[6]
:[6]

In fact, Kolmogorov has shown that if the cumulative distribution function F is continuous, then the expression converges in distribution to  , which has the Kolmogorov distribution that does not depend on the form of F.
, which has the Kolmogorov distribution that does not depend on the form of F.
Another result, which follows from the law of the iterated logarithm, is that [6]

and

Confidence intervals[edit]

Empirical CDF, CDF and Confidence Interval plots for various sample sizes of Normal Distribution
As per Dvoretzky–Kiefer–Wolfowitz inequality the interval that contains the true CDF,  , with probability
, with probability  is specified as
is specified as

Empirical CDF, CDF and Confidence Interval plots for various sample sizes of Cauchy Distribution

As per the above bounds, we can plot the Empirical CDF, CDF and Confidence intervals for different distributions by using any one of the Statistical implementations. Following is the syntax from Statsmodel for plotting empirical distribution.
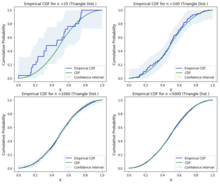
Empirical CDF, CDF and Confidence Interval plots for various sample sizes of Triangle Distribution
Statistical implementation[edit]
A non-exhaustive list of software implementations of Empirical Distribution function includes:
- In R software, we compute an empirical cumulative distribution function, with several methods for plotting, printing and computing with such an “ecdf” object.
- In MATLAB we can use Empirical cumulative distribution function (cdf) plot
- jmp from SAS, the CDF plot creates a plot of the empirical cumulative distribution function.
- Minitab, create an Empirical CDF
- Mathwave, we can fit probability distribution to our data
- Dataplot, we can plot Empirical CDF plot
- Scipy, we can use scipy.stats.ecdf
- Statsmodels, we can use statsmodels.distributions.empirical_distribution.ECDF
- Matplotlib, we can use histograms to plot a cumulative distribution
- Seaborn, using the seaborn.ecdfplot function
- Plotly, using the plotly.express.ecdf function
- Excel, we can plot Empirical CDF plot
See also[edit]
- Càdlàg functions
- Count data
- Distribution fitting
- Dvoretzky–Kiefer–Wolfowitz inequality
- Empirical probability
- Empirical process
- Estimating quantiles from a sample
- Frequency (statistics)
- Kaplan–Meier estimator for censored processes
- Survival function
- Q–Q plot
References[edit]
- ^ A modern introduction to probability and statistics : understanding why and how. Michel Dekking. London: Springer. 2005. p. 219. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ a b c
van der Vaart, A.W. (1998). Asymptotic statistics. Cambridge University Press. p. 265. ISBN 0-521-78450-6. - ^ Coles, S. (2001) An Introduction to Statistical Modeling of Extreme Values. Springer, p. 36, Definition 2.4. ISBN 978-1-4471-3675-0.
- ^ Madsen, H.O., Krenk, S., Lind, S.C. (2006) Methods of Structural Safety. Dover Publications. p. 148-149. ISBN 0486445976
- ^ a b van der Vaart, A.W. (1998). Asymptotic statistics. Cambridge University Press. p. 266. ISBN 0-521-78450-6.
- ^ a b c van der Vaart, A.W. (1998). Asymptotic statistics. Cambridge University Press. p. 268. ISBN 0-521-78450-6.
Further reading[edit]
- Shorack, G.R.; Wellner, J.A. (1986). Empirical Processes with Applications to Statistics. New York: Wiley. ISBN 0-471-86725-X.
External links[edit]
 Media related to Empirical distribution functions at Wikimedia Commons
Media related to Empirical distribution functions at Wikimedia Commons