— Друг! У вас какая система? Разрешите взглянуть…
— Система обычная. Нажал на кнопку — и дома.
«Кин-Дза-Дза»
01
Метафора дома появилась в гипертекстовых системах задолго до всемирной паутины. В те времена пиктограммой домика обозначался возврат к началу координат — к оглавлению или в корневую директорию.
03
Кнопка «дом» присутствует теперь в любом браузере на одном и том же месте — на панели управления. Первоначальная функция дома утратила свое значение, и даже название места, куда вела кнопка, — домашняя страница — перестало ассоциироваться с кнопкой «дом». Домов стало много, это и есть повсеместно протянутая паутина.
04
Раньше как было? Сделаешь домашнюю страницу — это твой трамплин во внешний (или внутренний) мир. И кнопка удобная была под рукой, вела как раз домой. Сегодня кнопка с домиком стала удобной закладкой, доступной на панели управления, а не в списке излюбленных мест.
05
Алчные провайдеры, поставляющие браузеры новичкам, прописывают свой адрес в качестве домашнего. Сайты конкурируют за свое место под кнопкой — каждый хочет быть домом для пользователя.
06
Лирическое отступление
Кнопки «вперед» и «назад» помогают в навигации по сайту. Перезагрузкой можно обновить только текущую страницу. Кнопки печати, размера шрифта, просмотра исходного кода, а также стоп — все они работают с открытой в данный момент страницей.
Сегодня кнопка «дом» является фактически единственной на панели управления браузера, чья функция не связана со страницей, открытой в данный момент.
07
В идеальном интерфейсе браузера кнопка с домиком должна отправлять на главную страницу того сайта, который смотришь. Она должна быть неактивна, если пользователь находится как раз на главной странице сайта.
08
Можно так сделать? Не вопрос. Через несколько лет так и будет. (А заодно появится кнопка «инфо», которая будет открывать страницу с информацией о текущем сайте — сейчас ее очень не хватает.)
09
Но пока производители до этого не дошли, сайтостроители нашли альтернативу — для этой цели используется логотип наверху страницы. Де-факто это уже стало мировым стандартом.
10
Лирическое отступление
Еще один популярный вид ссылки на главную страницу — домик. Эта пиктограмма, ставшая самой распространенной в рунете, впервые была применена автором на сайте «Комстара» в начале 1997 года.
11
Делать ссылку с логотипа на главную («домашнюю») страницу — хорошо и правильно. Но при этом надо избегать самой часто распространенной ошибки (ради которой и написан этот параграф) — если мы находимся дома, то ссылки «на главную» там быть не должно. Это относится и к другим местам на сайте: любая ссылка подразумевает перемещение.
12
Один из основных законов ориентирования на вебе и гипертекстовой навигации: ничто не должно содержать ссылку на само себя.
- Простейший DOM
- Пример посложнее
- Пример с атрибутами и DOCTYPE
- Нормализация в различных браузерах
- Возможности, которые дает DOM
-
Доступ к элементам
- document.documentElement
- document.body
-
Типы DOM-элементов
- Пример
- Дочерние элементы
-
Свойства элементов
-
tagName -
style -
innerHTML -
className -
onclick,onkeypress,onfocus…
-
Основным инструментом работы и динамических изменений на странице является DOM (Document Object Model) — объектная модель, используемая для XML/HTML-документов.
Согласно DOM-модели, документ является иерархией.
Каждый HTML-тег образует отдельный элемент-узел, каждый фрагмент текста — текстовый элемент, и т.п.
Проще говоря, DOM — это представление документа в виде дерева тегов. Это дерево образуется за счет вложенной структуры тегов плюс текстовые фрагменты страницы, каждый из которых образует отдельный узел.
Простейший DOM
Построим, для начала, дерево DOM для следующего документа.
<html>
<head>
<title>Заголовок</title>
</head>
<body>
Прекрасный документ
</body>
</html>
Самый внешний тег — <html>, поэтому дерево начинает расти от него.
Внутри <html> находятся два узла: <head> и <body> — они становятся дочерними узлами для <html>.
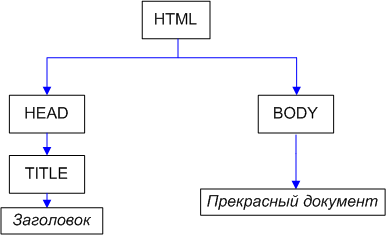
Теги образуют узлы-элементы (element node). Текст представлен текстовыми узлами (text node). И то и другое — равноправные узлы дерева DOM.
Пример посложнее
Рассмотрим теперь более жизненную страничку:
<html>
<head>
<title>
О лосях
</title>
</head>
<body>
Правда о лосях.
<ol>
<li>
Лось - животное хитрое
</li>
<li>
.. И коварное
</li>
</ol>
</body>
</html>
Корневым элементом иерархии является html. У него есть два потомка. Первый — head, второй — body. И так далее, каждый вложенный тег является потомком тега выше:

На этом рисунке синим цветом обозначены элементы-узлы, черным — текстовые элементы.
Дерево образовано за счет синих элементов-узлов — тегов HTML.
А вот так выглядит дерево, если изобразить его прямо на HTML-страничке:
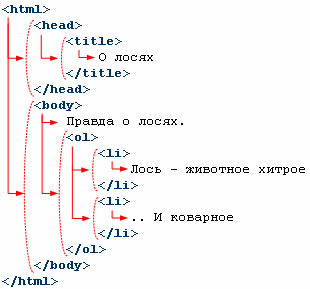
Кстати, дерево на этом рисунке не учитывает текст, состоящий из одних пробельных символов. Например, такой текстовый узел должен идти сразу после <ol>. DOM, не содержащий таких «пустых» узлов, называют «нормализованным».
Пример с атрибутами и DOCTYPE
Рассмотрим чуть более сложный документ.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>Документ</title>
</head>
<body>
<div id="dataKeeper">Data</div>
<ul>
<li style="background-color:red">Осторожно</li>
<li class="info">Информация</li>
</ul>
<div id="footer">Made in Russia ©</div>
</body>
</html>
Верхний тег — html, у него дети head и body, и так далее. Получается дерево тегов:

Атрибуты
В этом примере у узлов есть атрибуты: style, class, id. Вообще говоря, атрибуты тоже считаются узлами в DOM-модели, родителем которых является элемент DOM, у которого они указаны.
Однако, в веб-программировании в эти дебри обычно не лезут, и считают атрибуты просто свойствами DOM-узла, которые, как мы увидим в дальнейшем, можно устанавливать и менять по желанию программиста.
DOCTYPE
Вообще-то это секрет, но DOCTYPE тоже является DOM-узлом, и находится в дереве DOM слева от HTML (на рисунке этот факт скрыт).
P.S. Насчет секрета — конечно, шутка, но об этом и правда далеко не все знают. Сложно придумать, где такое знание может пригодиться…
Нормализация в различных браузерах
При разборе HTML Internet Explorer сразу создает нормализованный DOM, в котором не создаются узлы из пустого текста.
Firefox — другого мнения, он создает DOM-элемент из каждого текстового фрагмента.
Поэтому в Firefox дерево этого документа выглядит так:
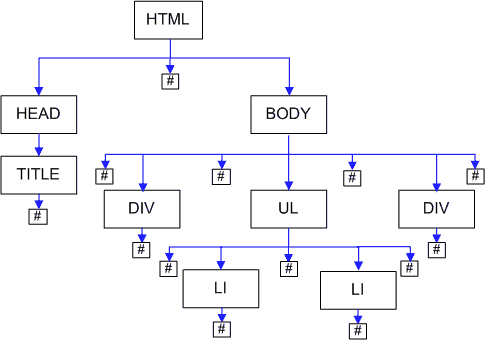
На рисунке для краткости текстовые узлы обозначены просто решеткой. У body вместо 3 появилось 7 детей.
Opera тоже имеет чем похвастаться. Она может добавить лишний пустой элемент «просто от себя».
Чтобы это увидеть — откройте документ по этой ссылке. Он выдает число дочерних узлов document.body, включая текстовые узлы.
У меня получается 3 для IE, 7 для Firefox и 8 (!?) для Opera.
На практике эта несовместимость не создает больших проблем, но нужно о ней помнить. Например, разница может проявить себя в случае перебора узлов дерева.
Возможности, которые дает DOM
Зачем, кроме красивых рисунков, нужна иерархическая модель DOM?
Очень просто:
Каждый DOM-элемент является объектом и предоставляет свойства для манипуляции своим содержимым, для доступа к родителям и потомкам.
Для манипуляций с DOM используется объект document.
Используя document, можно получать нужный элемент дерева и менять его содержание.
Например, этот код получает первый элемент с тэгом ol, последовательно удаляет два элемента списка и затем добавляет их в обратном порядке:
var ol = document.getElementsByTagName('ol')[0]
var hiter = ol.removeChild(ol.firstChild)
var kovaren = ol.removeChild(ol.firstChild)
ol.appendChild(kovaren)
ol.appendChild(hiter)
Для примера работы такого скрипта — кликните на тексте на лосиной cтраничке
document.write
В старых руководствах и скриптах можно встретить модификацию HTML-кода страницы напрямую вызовом document.write.
В современных скриптах этот метод почти не используется, случаи его правильного применения можно пересчитать по пальцам.
Избегайте document.write.. Кроме случаев, когда вы действительно знаете, что делаете (а зачем тогда читаете самоучитель — вы и так гуру)
Разберем подробнее способы доступа и свойства элементов DOM.
Доступ к элементам
Любой доступ и изменения DOM берут свое начало от объекта document.
Начнем с вершины дерева.
document.documentElement
Самый верхний тег. В случае корректной HTML-страницы, это будет <html>.
document.body
Тег <body>, если есть в документе (обязан быть).
Это свойство работает немного по-другому, если установлен DOCTYPE Strict. Обычно проще поставить loose DOCTYPE.
Следующий пример при нажатии на кнопку выдаст текстовое представление объектов document.documentElement и document.body. Сама строка зависит от браузера, хотя объекты везде одни и те же.
<html>
<body>
<script>
function go() {
alert(document.documentElement)
alert(document.body)
}
</script>
<input type="button" onclick="go()" value="Go"/>
</body>
</html>
Типы DOM-элементов
У каждого элемента в DOM-модели есть тип. Его номер хранится в атрибуте elem.nodeType
Всего в DOM различают 12 типов элементов.
Обычно используется только один: Node.ELEMENT_NODE, номер которого равен 1. Элементам этого типа соответствуют HTML-теги.
Иногда полезен еще тип Node.TEXT_NODE, который равен 3. Это текстовые элементы.
Остальные типы в javascript программировании не используются.
Следующий пример при нажатии на кнопку выведет типы document.documentElement, а затем тип последнего потомка узла document.body. Им является текстовый узел.
<html>
<body>
<script>
function go() {
alert(document.documentElement.nodeType)
alert(document.body.lastChild.nodeType)
}
</script>
<input type="button" onclick="go()" value="Go"/>
Текст
</body>
</html>
Пример
Например, вот так выглядел бы в браузере документ из примера выше, если каждый видимый элемент обвести рамкой с цифрой nodeType в правом верхнем углу.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head><title>...</title></head>
<body>
<div id="dataKeeper">Data</div>
<ul>
<li style="background-color:red">Осторожно</li>
<li class="info">Информация</li>
</ul>
<div id="footer">Made in Russia ©</div>
</body>
</html>

Здесь показаны только элементы внутри body, т.к только они отображаются на странице. Для элементов типа 1 (теги) в скобочках указан соответствующий тег, для текстовых элементов (тип 3) — стоит просто цифра.
Дочерние элементы
С вершины дерева можно пойти дальше вниз. Для этого каждый DOM-узел содержит массив всех детей, отдельно — ссылки на первого и последнего ребенка и еще ряд полезных свойств.
-
Все дочерние элементы, включая текстовые находятся в массиве
childNodes.В следующем примере цикл перебирает всех детей
document.body.for(var i=0; i<document.body.childNodes.length; i++) { var child = document.body.childNodes[i] alert(child.tagName) } -
Свойства
firstChildиlastChildпоказывают на первый и последний дочерние элементы и равныnull, если детей нет. -
Свойство
parentNodeуказывает на родителя. Например, для<body>таким элементом является<html>:alert(document.body.parentNode == document.documentElement) // true
- Свойства
previousSiblingиnextSiblingуказывают на левого и правого братьев узла.
В общем. если взять отдельно <body> с детьми из нормализованного DOM — такая картинка получается ОТ <body>:

И такая — для ссылок наверх и между узлами:

- Синяя линия — массив
childNodes - Зеленые линии — свойства
firstChild,lastChild. - Красная линия — свойство
parentNode - Бордовая и лавандовая линии внизу —
previousSibling,nextSibling
Этих свойств вполне хватает для удобного обращения к соседям.
Свойства элементов
У DOM-элементов есть масса свойств. Обычно используется максимум треть из них. Некоторые из них можно читать и устанавливать, другие — только читать.
Есть еще и третий вариант, встречающийся в IE — когда устанавливать свойство можно только во время создания элемента.
Рассмотрим здесь еще некоторые (не все) свойства элементов, полезные при работе с DOM.
tagName
Атрибут есть у элементов-тегов и содержит имя тега в верхнем регистре, только для чтения.
Например,
alert(document.body.tagName) // => BODY
style
Это свойство управляет стилем. Оно аналогично установке стиля в CSS.
Например, можно установить element.style.width:
Исходный код этой кнопки:
<input type="button" style="width: 300px" onclick="this.style.width = parseInt(this.style.width)-10+'px'" value="Укоротить на 10px" />
Обработчик события onclick обращается в этом примере к свойству this.style.width, т.к значением this в обработчике события является текущий элемент (т.е сама кнопка). Подробнее об этом — во введении в события.
Есть общее правило замены — если CSS-атрибут имеет дефисы, то для установки style нужно заменить их на верхний регистр букв.
Например, для установки свойства z-index в 1000, нужно поставить:
element.style.zIndex = 1000
innerHTML
Когда-то это свойство поддерживалось только в IE. Теперь его поддерживают все современные браузеры.
Оно содержит весь HTML-код внутри узла, и его можно менять.
Свойство innerHTML применяется, в основном, для динамического изменения содержания страницы, например:
document.getElementById('footer').innerHTML = '<h1>Bye!</h1> <p>See ya</p>'
Пожалуй, innerHTML — одно из наиболее часто используемых свойств DOM-элемента.
className
Это свойство задает класс элемента. Оно полностью аналогично html-атрибуту «class».
elem.className = 'newclass'
onclick, onkeypress, onfocus…
.. И другие свойства, начинающиеся на «on…», хранят функции-обработчики соответствующих событий. Например, можно присвоить обработчик события onclick.
Подробнее об этих свойствах и обработчиках событий — см. введение в события.
Редактировать шаблон в автономном режиме
1. Загрузите и установите версию Nicepage для Windows, Mac, WordPress и Joomla с страница загрузки
2. Создайте новую страницу или выберите существующую.
3. Нажмите «Добавить новый блок», найдите идентификатор 154580 и нажмите «Ввод».
Редактировать шаблон онлайн
Запустите edit online этот шаблон на нашем хостинге
Создавайте потрясающие сайты
![]()
WordPress
![]()
Windows App
![]()
Joomla
![]()
Mac OS App
![]()
HTML5
![]()
Online
Бесплатный конструктор Nicepage Builder
10,000+ веб-шаблонов
Легкое перетаскивание
Без кодирования
Удобство для мобильных
Ключевые слова
В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
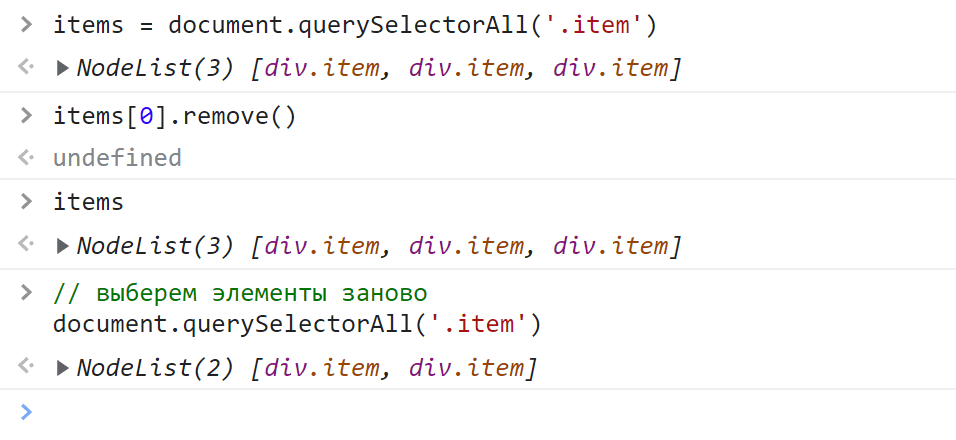
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>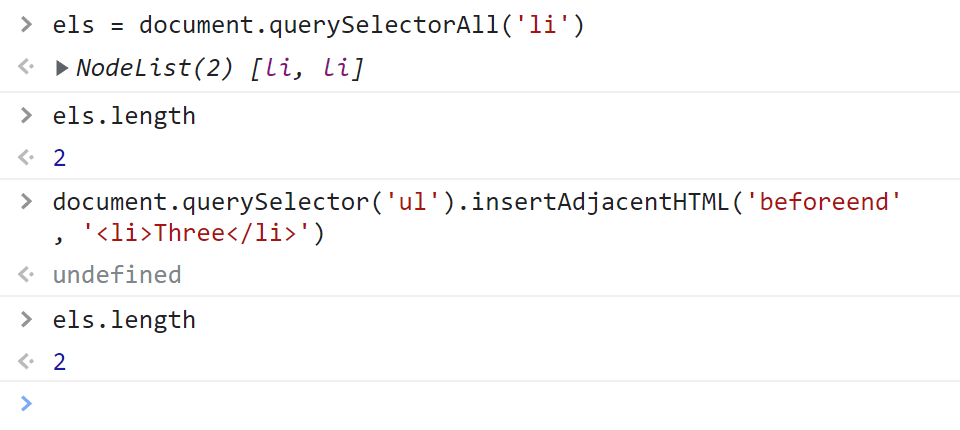
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
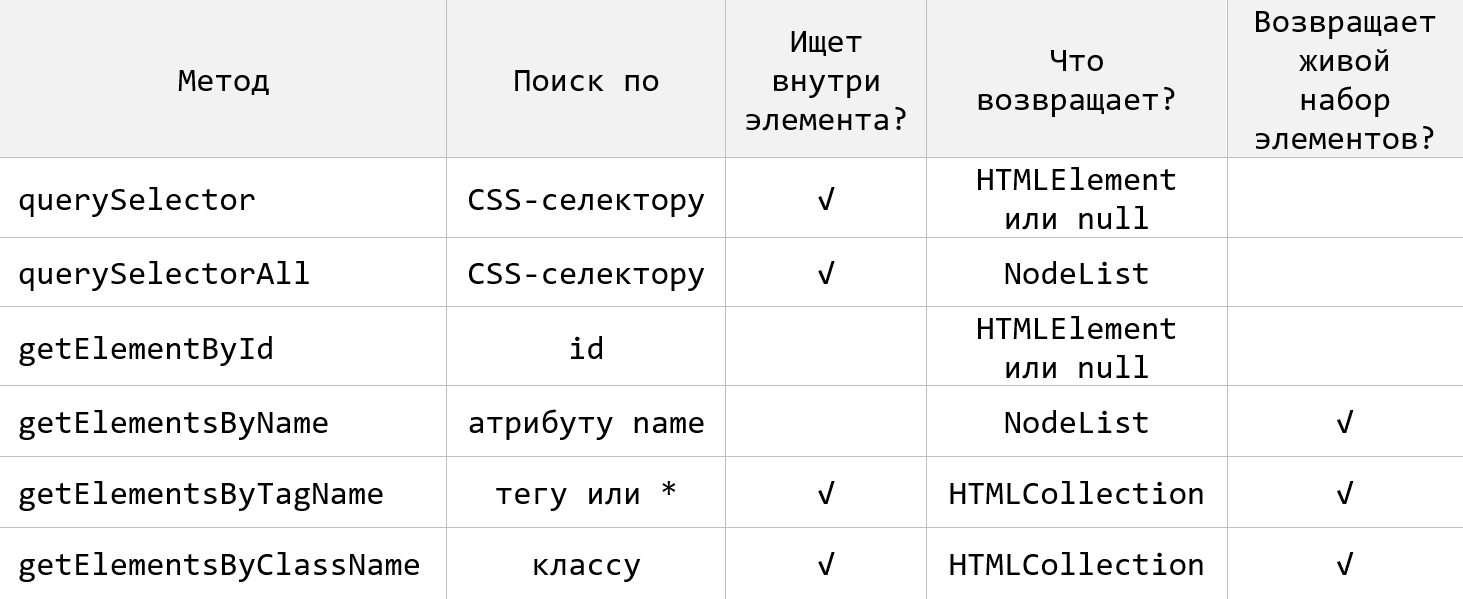
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
из расширения Crome пытаюсь получить DOM-структуру страницы по ссылке. Использую такой код:
var doc = document.body;
fetch(order_data['skuhref']).then(function(response) {
response.text().then(function(text) {
doc.textContent = text;
});
});
В этой переменной order_data[‘skuhref’] находится url.
Скрипт возвращает страницу в виде html текста. А как получить страницу в виде DOM, чтобы удобно можно было обращаться к нужным элементам?
задан 26 авг 2020 в 11:12
![]()
SturmerSturmer
12510 бронзовых знаков
7
Как вариант, можно создать div элемент и в innerHTML положить полученный html.
var doc = document.body;
fetch(order_data['skuhref']).then(function(response) {
response.text().then(function(text) {
doc.textContent = text;
let dom = document.createElement('div');
dom.innerHTML = text;
// теперь можно пользоваться селекторами как обычно
console.log(dom.querySelector('h1'));
});
});
ответ дан 26 авг 2020 в 11:38
![]()
EinEin
2,4935 серебряных знаков12 бронзовых знаков
3
По совету Grundy сделал вот так:
fetch(order_data['skuhref']).then(function(response) {
response.text().then(function(text) {
var parser = new DOMParser();
var sku_document = parser.parseFromString(text, "text/html");
........
});
});
Просто, красиво и работает!
ответ дан 26 авг 2020 в 16:28
![]()
SturmerSturmer
12510 бронзовых знаков
Если речь идет про браузер, то в браузере уже есть DOM:
const dom = window.document;
ответ дан 26 авг 2020 в 11:37
![]()
trunovtrunov
12 бронзовых знака