Время на прочтение
10 мин
Количество просмотров 146K
Когда вы выполняете какой-нибудь запрос, оптимизатор запросов MySQL пытается придумать оптимальный план выполнения этого запроса. Вы можете посмотреть этот самый план используя запрос с ключевым словом EXPLAIN. EXPLAIN – это один из самых мощных инструментов, предоставленных в ваше распоряжение для понимания MySQL-запросов и их оптимизации, но печальным фактом является то, что многие разработчики редко его используют. В данной статье вы узнаете о том, какие данные предлагает EXPLAIN на выходе и ознакомитесь с примером того, как использовать его для оптимизации запросов.
Что предлагает EXPLAIN?
Использовать оператор EXPLAIN просто. Его необходимо добавлять в запросы перед оператором SELECT. Давайте проанализируем вывод, чтобы познакомиться с информацией, возвращаемой командой.
EXPLAIN SELECT * FROM categories********************** 1. row **********************
id: 1
select_type: SIMPLE
table: categories
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra:
1 row in set (0.00 sec)
Вывод может не выглядеть точь-в-точь так, тем не менее, в нем будут содержаться те же 10 столбцов. Что же это за возвращаемые столбцы?
- id – порядковый номер для каждого SELECT’а внутри запроса (когда имеется несколько подзапросов)
- select_type – тип запроса SELECT.
- SIMPLE — Простой запрос SELECT без подзапросов или UNION’ов
- PRIMARY – данный SELECT – самый внешний запрос в JOIN’е
- DERIVED – данный SELECT является частью подзапроса внутри FROM
- SUBQUERY – первый SELECT в подзапросе
- DEPENDENT SUBQUERY – подзапрос, который зависит от внешнего запроса
- UNCACHABLE SUBQUERY – не кешируемый подзапрос (существуют определенные условия для того, чтобы запрос кешировался)
- UNION – второй или последующий SELECT в UNION’е
- DEPENDENT UNION – второй или последующий SELECT в UNION’е, зависимый от внешнего запроса
- UNION RESULT – результат UNION’а
- Table – таблица, к которой относится выводимая строка
- Type — указывает на то, как MySQL связывает используемые таблицы. Это одно из наиболее полезных полей в выводе потому, что может сообщать об отсутствующих индексах или почему написанный запрос должен быть пересмотрен и переписан.
Возможные значения:- System – таблица имеет только одну строку
- Const – таблица имеет только одну соответствующую строку, которая проиндексирована. Это наиболее быстрый тип соединения потому, что таблица читается только один раз и значение строки может восприниматься при дальнейших соединениях как константа.
- Eq_ref – все части индекса используются для связывания. Используемые индексы: PRIMARY KEY или UNIQUE NOT NULL. Это еще один наилучший возможный тип связывания.
- Ref – все соответствующие строки индексного столбца считываются для каждой комбинации строк из предыдущей таблицы. Этот тип соединения для индексированных столбцов выглядит как использование операторов = или < = >
- Fulltext – соединение использует полнотекстовый индекс таблицы
- Ref_or_null – то же самое, что и ref, но также содержит строки со значением null для столбца
- Index_merge – соединение использует список индексов для получения результирующего набора. Столбец key вывода команды EXPLAIN будет содержать список использованных индексов.
- Unique_subquery – подзапрос IN возвращает только один результат из таблицы и использует первичный ключ.
- Index_subquery – тоже, что и предыдущий, но возвращает более одного результата.
- Range – индекс, использованный для нахождения соответствующей строки в определенном диапазоне, обычно, когда ключевой столбец сравнивается с константой, используя операторы вроде: BETWEEN, IN, >, >=, etc.
- Index – сканируется все дерево индексов для нахождения соответствующих строк.
- All – Для нахождения соответствующих строк используются сканирование всей таблицы. Это наихудший тип соединения и обычно указывает на отсутствие подходящих индексов в таблице.
- Possible_keys – показывает индексы, которые могут быть использованы для нахождения строк в таблице. На практике они могут использоваться, а могут и не использоваться. Фактически, этот столбец может сослужить добрую службу в деле оптимизации запросов, т.к значение NULL указывает на то, что не найдено ни одного подходящего индекса .
- Key– указывает на использованный индекс. Этот столбец может содержать индекс, не указанный в столбце possible_keys. В процессе соединения таблиц оптимизатор ищет наилучшие варианты и может найти ключи, которые не отображены в possible_keys, но являются более оптимальными для использования.
- Key_len – длина индекса, которую оптимизатор MySQL выбрал для использования. Например, значение key_len, равное 4, означает, что памяти требуется для хранения 4 знаков. На эту тему вот cсылка
- Ref – указываются столбцы или константы, которые сравниваются с индексом, указанным в поле key. MySQL выберет либо значение константы для сравнения, либо само поле, основываясь на плане выполнения запроса.
- Rows – отображает число записей, обработанных для получения выходных данных. Это еще одно очень важное поле, которое дает повод оптимизировать запросы, особенно те, которые используют JOIN’ы и подзапросы.
- Extra – содержит дополнительную информацию, относящуюся к плану выполнения запроса. Такие значения как “Using temporary”, “Using filesort” и т.д могут быть индикатором проблемного запроса. С полным списком возможных значений вы можете ознакомиться здесь
После EXPLAIN в запросе вы можете использовать ключевое слово EXTENDED и MySQL покажет вам дополнительную информацию о том, как выполняется запрос. Чтобы увидеть эту информацию, вам нужно сразу после запроса с EXTENDED выполнить запрос SHOW WARNINGS. Наиболее полезно смотреть эту информацию о запросе, который выполнялся после каких-либо изменений сделанных оптимизатором запросов.
EXPLAIN EXTENDED SELECT City.Name FROM City
JOIN Country ON (City.CountryCode = Country.Code)
WHERE City.CountryCode = 'IND' AND Country.Continent = 'Asia'********************** 1. row **********************
id: 1
select_type: SIMPLE
table: Country
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 3
ref: const
rows: 1
filtered: 100.00
Extra:
********************** 2. row **********************
id: 1
select_type: SIMPLE
table: City
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4079
filtered: 100.00
Extra: Using where
2 rows in set, 1 warning (0.00 sec)
SHOW WARNINGS********************** 1. row **********************
Level: Note
Code: 1003
Message: select `World`.`City`.`Name` AS `Name` from `World`.`City` join `World`.`Country` where ((`World`.`City`.`CountryCode` = 'IND'))
1 row in set (0.00 sec)
Поиск и устранение проблем с производительностью с помощью EXPLAIN.
Теперь давайте посмотрим на то, как мы может оптимизировать не очень шустрый запрос, анализируя вывод команды EXPLAIN. Несомненно, что в действующих рабочих приложениях существует ряд таблиц со многими связями между ними, но иногда сложно предвидеть наиболее оптимальный способ написания запроса.
Я создал тестовую базу данных для приложения электронной торговли, которая не имеет никаких индексов или первичных ключей, и продемонстрирую влияние такого не очень хорошего способа создания таблиц при помощи “страшных” запросов. Дамп это таблицы вы можете скачать здесь — github.com/phpmasterdotcom/UsingExplainToWriteBetterMySQLQueries
EXPLAIN SELECT * FROM
orderdetails d
INNER JOIN orders o ON d.orderNumber = o.orderNumber
INNER JOIN products p ON p.productCode = d.productCode
INNER JOIN productlines l ON p.productLine = l.productLine
INNER JOIN customers c on c.customerNumber = o.customerNumber
WHERE o.orderNumber = 10101
Если вы посмотрите на результат (на него вам придется посмотреть только в примере ниже, по ссылке выше лежит дамп с уже добавленными ключами), то увидите все симптомы плохого запроса.
UPDATE. Здесь лежит исправленный дамп без индексов. В оригинальном авторском дампе индексы почему-то изначально добавлены.
Но даже если я напишу запрос получше, результат будет тем же самым, пока я не добавлю индексов. Указанный тип соединения ALL (худший), что означает, что MySQL не смог определить ни одного ключа, который бы мог использоваться при соединении. Отсюда следует и то, что possible_keys и key имеют значение NULL. Самым важным является то, что поле rows показывает, что MySQL сканирует все записи каждой таблицы для запроса. Это означает, что она просканирует 7 × 110 × 122 × 326 × 2996 = 91,750,822,240 записей, чтобы найти подходящие четыре (уберите из запроса EXPLAIN, проверьте сами). Это очень нехорошо и количество этих записей будет экспоненциально увеличиваться по мере роста базы данных.
Теперь давайте добавим очевидные индексы, такие, как первичный ключ для каждой таблицы, и выполним запрос еще раз. Взяв это за основное правило, в качестве кандидатов для добавления ключей вы можете использовать те столбцы которые используются в JOIN’ах, т.к. MySQL всегда сканирует их для нахождения соответствующих записей.
ALTER TABLE customers
ADD PRIMARY KEY (customerNumber);
ALTER TABLE employees
ADD PRIMARY KEY (employeeNumber);
ALTER TABLE offices
ADD PRIMARY KEY (officeCode);
ALTER TABLE orderdetails
ADD PRIMARY KEY (orderNumber, productCode);
ALTER TABLE orders
ADD PRIMARY KEY (orderNumber),
ADD KEY (customerNumber);
ALTER TABLE payments
ADD PRIMARY KEY (customerNumber, checkNumber);
ALTER TABLE productlines
ADD PRIMARY KEY (productLine);
ALTER TABLE products
ADD PRIMARY KEY (productCode),
ADD KEY (buyPrice),
ADD KEY (productLine);
ALTER TABLE productvariants
ADD PRIMARY KEY (variantId),
ADD KEY (buyPrice),
ADD KEY (productCode);
Давайте выполним наш прежний запрос после добавления индексов. Вы увидите это:
********************** 1. row **********************
id: 1
select_type: SIMPLE
table: o
type: const
possible_keys: PRIMARY,customerNumber
key: PRIMARY
key_len: 4
ref: const
rows: 1
Extra:
********************** 2. row **********************
id: 1
select_type: SIMPLE
table: c
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 1
Extra:
********************** 3. row **********************
id: 1
select_type: SIMPLE
table: d
type: ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 4
Extra:
********************** 4. row **********************
id: 1
select_type: SIMPLE
table: p
type: eq_ref
possible_keys: PRIMARY,productLine
key: PRIMARY
key_len: 17
ref: classicmodels.d.productCode
rows: 1
Extra:
********************** 5. row **********************
id: 1
select_type: SIMPLE
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra:
5 rows in set (0.00 sec)
После добавления индексов, число считанных записей упало до 1 × 1 × 4 × 1 × 1 = 4 Для каждой записи order_number = 10101 в таблице orderdetails – это значит, что MySQL смогла найти соответствующие записи во всех других таблицах с использованием индексов и не стала прибегать к полному сканированию таблицы.
В первом выводе вы можете что использован тип соединения – “const”, который является самым быстрым типом соединения для таблиц с более, чем одной записью. MySQL смогла использовать PRIMARY KEY как индекс. В поле “ref” отображается “const”, что есть ни что иное, как значение 10101, указанное в запросе после ключевого слова WHERE.
Смотрим на еще один запрос. В нем мы выбираем объединение двух таблиц, products и productvariants, каждая объединена с productline. productvariants, которая состоит из разных вариантов продуктов с полем productCode – ссылкой на их цены.
EXPLAIN SELECT * FROM (
SELECT p.productName, p.productCode, p.buyPrice, l.productLine, p.status, l.status AS lineStatus FROM
products p
INNER JOIN productlines l ON p.productLine = l.productLine
UNION
SELECT v.variantName AS productName, v.productCode, p.buyPrice, l.productLine, p.status, l.status AS lineStatus FROM productvariants v
INNER JOIN products p ON p.productCode = v.productCode
INNER JOIN productlines l ON p.productLine = l.productLine
) products
WHERE status = 'Active' AND lineStatus = 'Active' AND buyPrice BETWEEN 30 AND 50
********************** 1. row **********************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 219
Extra: Using where
********************** 2. row **********************
id: 2
select_type: DERIVED
table: p
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 110
Extra:
********************** 3. row **********************
id: 2
select_type: DERIVED
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra:
********************** 4. row **********************
id: 3
select_type: UNION
table: v
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 109
Extra:
********************** 5. row **********************
id: 3
select_type: UNION
table: p
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 17
ref: classicmodels.v.productCode
rows: 1
Extra:
********************** 6. row **********************
id: 3
select_type: UNION
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra:
********************** 7. row **********************
id: NULL
select_type: UNION RESULT
table: <union2,3>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra:
7 rows in set (0.01 sec)
Вы можете заметить ряд проблем в этом запросе. Он сканирует все записи в products и productvarians. Т.к. в этих таблицах нет индексов для столбцов productLine и buyPrice, в полях possible_keys и key отображаются значения NULL. Статус таблиц products и productlines проверяется после UNION’а, поэтому перемещение их внутри UNION’а уменьшит число записей. Добавим индексы.
CREATE INDEX idx_buyPrice ON products(buyPrice);
CREATE INDEX idx_buyPrice ON productvariants(buyPrice);
CREATE INDEX idx_productCode ON productvariants(productCode);
CREATE INDEX idx_productLine ON products(productLine);
EXPLAIN SELECT * FROM (
SELECT p.productName, p.productCode, p.buyPrice, l.productLine, p.status, l.status as lineStatus FROM products p
INNER JOIN productlines AS l ON (p.productLine = l.productLine AND p.status = 'Active' AND l.status = 'Active')
WHERE buyPrice BETWEEN 30 AND 50
UNION
SELECT v.variantName AS productName, v.productCode, p.buyPrice, l.productLine, p.status, l.status FROM productvariants v
INNER JOIN products p ON (p.productCode = v.productCode AND p.status = 'Active')
INNER JOIN productlines l ON (p.productLine = l.productLine AND l.status = 'Active')
WHERE
v.buyPrice BETWEEN 30 AND 50
) product
********************** 1. row **********************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 12
Extra:
********************** 2. row **********************
id: 2
select_type: DERIVED
table: p
type: range
possible_keys: idx_buyPrice,idx_productLine
key: idx_buyPrice
key_len: 8
ref: NULL
rows: 23
Extra: Using where
********************** 3. row **********************
id: 2
select_type: DERIVED
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra: Using where
********************** 4. row **********************
id: 3
select_type: UNION
table: v
type: range
possible_keys: idx_buyPrice,idx_productCode
key: idx_buyPrice
key_len: 9
ref: NULL
rows: 1
Extra: Using where
********************** 5. row **********************
id: 3
select_type: UNION
table: p
type: eq_ref
possible_keys: PRIMARY,idx_productLine
key: PRIMARY
key_len: 17
ref: classicmodels.v.productCode
rows: 1
Extra: Using where
********************** 6. row **********************
id: 3
select_type: UNION
table: l
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 52
ref: classicmodels.p.productLine
rows: 1
Extra: Using where
********************** 7. row **********************
id: NULL
select_type: UNION RESULT
table: <union2,3>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra:
7 rows in set (0.01 sec)
Как вы видите, в результате количество сканированных строк уменьшилось с 2,625,810 (219 × 110 × 109) до 276 (12 × 23), что является отличным приобретением в производительности. Если вы выполните этот же запрос без предыдущих перестановок в запросе сразу после добавления индексов, вы не увидите такого уменьшения просканированных строк. MySQL не способна использовать индексы, когда в производном результате используется WHERE. После помещения этих условий внутри UNION становится возможных использование индексов. Это значит, что добавления индексов не всегда достаточно. MySQL не сможет их использовать до тех пор, пока вы не будете писать подходящие запросы. (http://www.php.su/mysql/manual/?page=MySQL_indexes – доп. информация).
Итог
В статье рассмотрено ключевое слово EXPLAIN, информация на выводе и примеры того, как вы можете использовать вывод команды для улучшения запросов. В реальном мире данная команда может быть более полезна, чем в рассмотренных сценариях. Почти всегда вы будете соединять ряд таблиц вместе, используя сложные конструкции с WHERE. При этом, просто добавленные индексы к таблицам не всегда приведут к нужному результату. В таком случае нужно пересмотреть ваши запросы.
Медленные SQL-запросы могут негативно отразиться на производительности WordPress-сайта. Иногда медленные запросы – это результат плохо сформированного SQL-кода, который должен быть реализован несколько иным путем. И в некоторых ситуациях медленные запросы сначала являлись быстрыми – но с ростом возраста сайта запросы становились все медленнее и медленнее, и уже начинали отставать от расширяющейся базы данных.
Вне зависимости от того, каким образом ваш SQL-код стал медленным, давайте взглянем на некоторые пути поиска и устранения проблемных запросов в WordPress.
Содержание
- Поиск медленных запросов
- Обнаружение медленных запросов с помощью EXPLAIN
- Исправление медленных запросов
- Выбор подхода
Поиск медленных запросов
Поиск источника медленных запросов включает в себя два шага:
- Определяем, какие запросы на самом деле медленные.
- Ищем код, который генерирует и исполняет их.
Давайте рассмотрим два плагина и одно SaaS-решение, которые помогут нам найти медленные запросы.
Query Monitor
Query Monitor – плагин, выводящий различную информацию о текущей странице. В дополнение к многочисленным данным о внутренних механизмах WordPress, плагин выводит детальную статистику по следующим пунктам:
- Сколько запросов произошло по этому вызову
- Какие запросы на странице заняли больше всего времени
- Какие функции выполнялись дольше всего в SQL-запросах
- Какие запросы шли от плагинов, тем и ядра WordPress
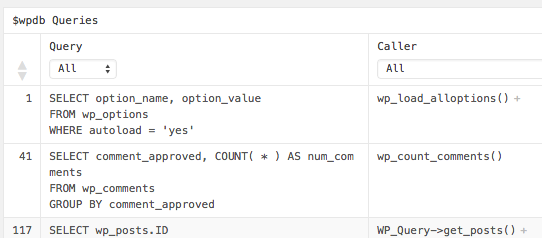
Query Monitor выделяет медленные запросы с помощью страшного красного текста, который упрощает выявление проблемного SQL:
Debug Bar
Еще один великолепный инструмент для поиска медленного SQL– это старый добрый плагин Debug Bar. Debug Bar выводит информацию о внутренних механизмах WordPress, когда вы загружаете страницу с такими данными, как:
- Параметры WP_Query
- Информация вызова (включая соответствие правил перезаписи)
- SQL-запросы, генерируемые текущей страницей
Чтобы активировать третий пункт в Debug Bar (SQL-отслеживание), убедитесь в том, что SAVEQUERIES включена на вашем сайте – обычно это делается в файле wp-config.php:
if ( ! defined( 'SAVEQUERIES' ) ) {
define( 'SAVEQUERIES', true );
}
Предостережение: SAVEQUERIES отражается на производительности вашего сайта, и, скорее всего, не должна использоваться на рабочем сайте. Используйте ее только на разрабатываемом сайте.
Поиск медленного SQL в Debug Bar не так прост. К примеру, плагин не имеет сортируемых таблиц и не подсвечивает медленные запросы. Debug Bar обеспечивает трассировку функций, которая позволяет выявить источник запроса.
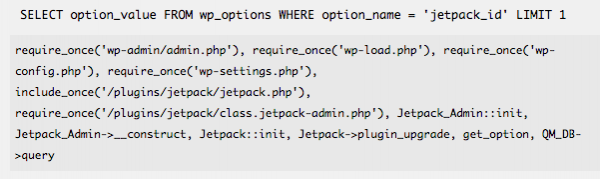
Здесь приведен список загружаемых файлов и функций, которые приводят к выполнению запроса. В основном вам будет интересна самая последняя запись в списке; именно там выполняется самый медленный запрос и именно с него вам нужно будет начать свой поиск. Также удобным является наличие контекста для каждой отдельной функции.
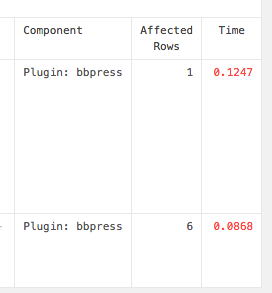
NewRelic
NewRelic – это сервис, который измеряет и отслеживает произвольность вашего веб-приложения, включая WordPress. Сервис предлагает массу разной информации о производительности вашего сайта. Очень легко потеряться в данных, которые предлагает NewRelic, начиная с детального выполнения кода и заканчивая пошаговыми отчетами по SQL-запросам.
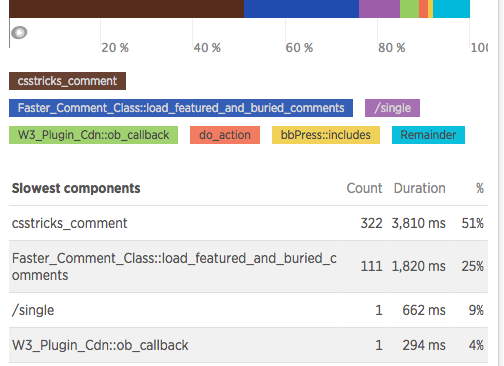
Есть два крупных различия между NewRelic и плагинами, упомянутыми выше:
- NewRelic отображает более детальную информацию о производительности вашего PHP, вплоть до миллисекунд, потраченных на выполнение каждой функции.
- NewRelic отслеживает каждый запрос к вашему сайту в фоновом режиме, т.е. вы можете проанализировать информацию позже для поиска медленного SQL. Плагины выводят информацию только для текущей страницы.
Стоит отметить, что NewRelic имеет бесплатный план, который позволяет вывести общую информацию о производительности вашего сайта, однако для получения всех важных деталей вам понадобится перейти на платный тариф. Именно в этом плане вы сможете отслеживать отдельные запросы и находить медленный SQL.
Обнаружение медленных запросов с помощью EXPLAIN
До недавнего момента мы рассматривали инструменты для поиска медленных запросов. Давайте теперь рассмотрим, почему эти запросы становятся медленными.
В этом нам поможет MySQL ключ EXPLAIN. Он позволит понять, что произошло. Добавление EXPLAIN в начало запроса покажет, как MySQL выполняет запрос. В случае с более сложными запросами EXPLAIN поможет выявить медленные участки в ваших SQL – к примеру, медленные подзапросы или неэффективные процессы.
К примеру, если у вас есть запрос следующего вида:
SELECT slow_column FROM slow_table
Вы можете добавить к нему EXPLAIN, просто выполнив следующее:
EXPLAIN SELECT slow_column FROM slow_table
Вот как выглядит вывод EXPLAIN в phpMyAdmin:

Я не совсем понимаю, как работают внутренние механизмы MySQL, но при этом запуск EXPLAIN для запросов дает мне понимание того, как MySQL выполняет мой SQL-запрос. Использует ли запрос индекс? Сканирует ли он всю таблицу? Даже для простых запросов EXPLAIN обеспечивает некоторую информацию, позволяющую понять, как все работает.
Вы можете запустить EXPLAIN либо из командной строки MySQL, либо через ваш предпочтительный MySQL-инструмент.
Исправление медленных запросов
Теперь, когда мы знаем, что наш запрос является медленным, и EXPLAIN показал нам, почему запрос является медленным, самое время посмотреть, как мы можем исправить эти проблемы.
Вариант 1. Изменение запроса.
На сайте CSS-Tricks у нас есть запрос, который выполняется очень медленно – этот запрос является частью мета-панели Custom Fields. Вот сам SQL:
SELECT meta_key FROM wp_postmeta GROUP BY meta_key HAVING meta_key NOT LIKE '\_%' ORDER BY meta_key LIMIT 100
Данный фрагмент кода содержит SQL, который позволяет получить список meta_keys из таблицы wp_postmeta. Интересующие нас meta_keys не должны начинаться с подчеркивания «_». Оператор GROUP BY означает, что каждый результат является уникальным.
Выполнив этот запрос 5 раз, мы получим следующие данные:
1.7146 сек
1.7912 сек
1.8077 сек
1.7708 сек
1.8456 сек
Могли бы мы написать другой запрос, чтобы получить тот же самый результат? Нам нужно выбрать уникальные meta_keys. Синоним к слову «unique» (уникальный) – distinct, и, как оказалось, в SQL есть такой оператор!
Используя оператор DISTINCT, мы можем сделать следующее:
SELECT DISTINCT meta_key FROM wp_postmeta WHERE meta_key NOT LIKE '\_%' ORDER BY meta_key
Выполнение нашего измененного запроса несколько раз дает следующие результаты:
0.3764 сек
0.2607 сек
0.2661 сек
0.2751 сек
0.2986 сек
Данное сравнение демонстрирует существенное улучшение!
Вариант 2. Добавление индекса.
Когда вы выполняете запрос SQL к стандартной таблице MySQL, MySQL сканирует всю таблицу, чтобы определить, какие строки соответствуют данному запросу. Если ваша таблица очень большая, то в таком случае сканирование займет довольно много времени.
В этом случае неплохо помогают индексы MySQL. Индексы берут данные из таблицы и располагают их так, чтобы эти данные было проще всего найти. Структурируя данные таким образом, индексы помогают избавиться от длительного сканирования, которое делает MySQL для каждого запроса.
Индексы могут быть добавлены к отдельным столбцам или к группе столбцов. Синтаксис выглядит следующим образом:
CREATE INDEX wp_postmeta_csstricks ON wp_postmeta (meta_key)
С индексом для meta_key исходный SQL-запрос будет выполняться следующим образом:
0.0042 сек
0.0024 сек
0.0031 сек
0.0026 сек
0.0020 сек
Улучшение налицо!
Предостережение по поводу использования индексов: всякий раз, когда INSERT создает строку, или UPDATE используется для индексированной страницы, индекс высчитывается заново, что является довольно долгой операцией. Индексы ускоряют считывание из таблицы, но замедляют внесение данных в нее. Удачно расположенный индекс может значительно ускорить ваши запросы, однако не стоит везде их расставлять, не изучив общее влияние индексов на вашу базу данных.
Вариант 3. Кэширование результатов запроса
Мы знаем, что у нас имеются медленные запросы. Вместо того чтобы переписывать их, мы можем просто сохранить результаты запроса. Таким образом, мы ограничим частоту выполнения запроса, а также получим «быстрый ответ».
Чтобы кэшировать запрос, нам понадобится WordPress Transients API. Transients используются для хранения результатов сложных операций, таких как:
- Запросы к внешним сайтам (к примеру, получение последних записей Facebook)
- Медленные блоки обработки (к примеру, поиск длинных строк с помощью регулярных выражений)
- Медленные запросы к базе данных
Хранение результатов запроса в transients будет выглядеть следующим образом:
if ( false === ( $results = get_transient( 'transient_key_name' ) ) ) {
$results = ...; // Do the slow query to get the results here
// 60 * 60 is the expiration in seconds - in this case, 3600 seconds (1 hour)
set_transient( 'transient_key_name', $results, 60 * 60 );
}
Это означает, что запрос будет выполняться только один раз в час или что-то около того. Отсюда вытекает одно из основных предостережений по использованию transient: будьте осторожны при использовании transient с данными, которые часто меняются.
Если у вас есть запрос, результаты которого меняются не так часто, использование transients – прекрасный способ обойти частое обращение к базе данных.
Выбор подхода
Мы рассмотрели три варианта, и кроме них есть еще примерно 17 способов решения проблемы с медленными запросами. Какой подход лучше всего выбрать?
Когда я работаю с чужим кодом, я предпочитаю ориентироваться на принцип программистов: «Выбирай самое простое решение, которое может работать».
Первый вариант (переписывание запроса) позволил получить превосходные результаты, однако как быть, если переписанный запрос не всегда выдает те же самые результаты? Мы можем неосознанно нарушить код путем замены запросов.
Второй вариант (добавление индекса) не всегда возможен, что зависит от таблицы и столбцов, используемых запросом. В случае с базовыми таблицами WordPress вам нужно будет подумать о возможных побочных эффектах индексации:
- Поддерживает ли обновление ядра дополнительные индексы?
- Не замедлит ли добавление индекса другие запросы, такие как INSERT и UPDATE?
Третий вариант (кэширование результатов через transients) оказывает минимальное воздействие – мы не меняем исходный запрос и нам не нужно изменять структуру базы данных.
Большую часть времени я использую третий вариант. В вашем случае вы можете выбрать другой вариант, что зависит от запроса, который вы хотите исправить, а также от SQL-проблем. Одного решения, которое бы подошло во всех ситуациях, нет, поэтому пробуйте разные варианты.
Источник: css-tricks.com
14.1. Использование EXPLAIN
PostgreSQL разрабатывает план запроса для каждого полученного запроса. Выбор правильного плана, соответствующего структуре запроса и свойствам данных, абсолютно важен для хорошей производительности, поэтому система включает в себя сложный планировщик, который пытается выбрать хорошие планы. Вы можете использовать команду EXPLAIN , чтобы увидеть, какой план запроса создает планировщик для любого запроса. Чтение плана — это искусство, для овладения которым требуется некоторый опыт, но в этом разделе делается попытка охватить основы.
Примеры в этом разделе взяты из базы данных регрессионного теста после выполнения VACUUM ANALYZE с использованием источников разработки 9.3. Вы сможете получить аналогичные результаты, если попробуете сами примеры, но ваши предполагаемые затраты и количество строк могут незначительно отличаться, потому что статистика ANALYZE является случайной выборкой, а не точной, и потому что затраты по своей природе в некоторой степени зависят от платформы.
В примерах используется «текстовый» выходной формат EXPLAIN по умолчанию, который компактен и удобен для чтения людьми. Если вы хотите передать вывод EXPLAIN в программу для дальнейшего анализа, вам следует вместо этого использовать один из машиночитаемых форматов вывода (XML, JSON или YAML).
14.1.1. EXPLAIN Основы
Структура плана запроса — это дерево узлов плана . Узлы на нижнем уровне дерева являются узлами сканирования: они возвращают необработанные строки из таблицы. Существуют разные типы узлов сканирования для разных методов доступа к таблицам: последовательное сканирование, сканирование индекса и сканирование индекса битовой карты. Существуют также источники строк, не относящиеся к таблице, такие как предложения VALUES и функции возврата набора в FROM , которые имеют свои собственные типы узлов сканирования. Если запрос требует объединения, агрегирования, сортировки или других операций с необработанными строками, тогда над узлами сканирования будут дополнительные узлы для выполнения этих операций. Опять же, обычно существует несколько возможных способов выполнения этих операций, поэтому здесь также могут появляться разные типы узлов. Вывод EXPLAIN имеет одну строку для каждого узла в дереве плана, показывающую базовый тип узла плюс оценки затрат, сделанные планировщиком для выполнения этого узла плана. Могут появиться дополнительные строки с отступом от итоговой строки узла, чтобы показать дополнительные свойства узла. Самая первая строка (итоговая строка для самого верхнего узла) содержит предполагаемую общую стоимость выполнения плана; именно это число планировщик стремится минимизировать.
Вот тривиальный пример,просто чтобы показать,как выглядит результат:
EXPLAIN SELECT * FROM tenk1; QUERY PLAN Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)
Поскольку в этом запросе нет WHERE , он должен сканировать все строки таблицы, поэтому планировщик решил использовать простой план последовательного сканирования. Цифры, указанные в скобках (слева направо):
-
Сметная начальная стоимость.Это время,потраченное до начала фазы выхода,например,время на сортировку в узле сортировки.
-
Ориентировочная общая стоимость. Это указано в предположении, что узел плана выполнен до конца, т. Е. Все доступные строки получены. На практике родительский узел узла может перестать читать все доступные строки (см. Пример
LIMITниже). -
Расчетное количество строк,выводимых этим узлом плана.Снова предполагается,что узел будет запущен до конца.
-
Расчетная средняя ширина выводимых строк по данному узлу плана (в байтах).
Затраты измеряются в произвольных единицах, определяемых параметрами затрат планировщика (см. Раздел 20.7.2 ). Традиционная практика заключается в измерении затрат в единицах выборки страниц с диска; то есть seq_page_cost обычно устанавливается равным 1.0 , а другие параметры стоимости устанавливаются относительно этого. Примеры в этом разделе запускаются с параметрами стоимости по умолчанию.
Важно понимать,что стоимость узла верхнего уровня включает стоимость всех его дочерних узлов.Также важно понимать,что стоимость отражает только то,что волнует планировщика.В частности,стоимость не учитывает время,затраченное на передачу строк результата клиенту,что может быть важным фактором в реальном прошедшем времени;но планировщик игнорирует ее,потому что не может изменить ее,изменив план.(Мы верим,что каждый правильный план будет выдавать один и тот же набор строк).
Значение rows немного сложно, потому что это не количество строк, обработанных или сканируемых узлом плана, а скорее число, выданное узлом. Часто это меньше, чем отсканированное число, в результате фильтрации по любым условиям WHERE , которые применяются на узле. В идеале оценка строк верхнего уровня будет приблизительно соответствовать количеству строк, фактически возвращенных, обновленных или удаленных запросом.
Возвращаясь к нашему примеру:
EXPLAIN SELECT * FROM tenk1; QUERY PLAN Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)
Эти числа выведены очень просто.Если ты это сделаешь:
SELECT relpages, reltuples FROM pg_class WHERE relname = 'tenk1';
вы обнаружите, что tenk1 имеет 358 дисковых страниц и 10000 строк. Ориентировочная стоимость рассчитывается как (прочитанные страницы диска * seq_page_cost ) + (отсканированные строки * cpu_tuple_cost ). По умолчанию seq_page_cost составляет 1,0, а cpu_tuple_cost — 0,01, поэтому расчетная стоимость составляет (358 * 1,0) + (10000 * 0,01) = 458.
Теперь давайте изменим запрос, добавив условие WHERE :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 7000; QUERY PLAN Seq Scan on tenk1 (cost=0.00..483.00 rows=7001 width=244) Filter: (unique1 < 7000)
Обратите внимание, что выходные EXPLAIN показывают, что WHERE применяется в качестве условия «фильтра», прикрепленного к узлу плана Seq Scan. Это означает, что узел плана проверяет условие для каждой сканируемой им строки и выводит только те, которые удовлетворяют условию. Оценка выходных строк была уменьшена из-за WHERE . Однако при сканировании все равно придется просмотреть все 10 000 строк, поэтому стоимость не уменьшилась; на самом деле он немного вырос (точнее, на 10000 * cpu_operator_cost ), чтобы отразить дополнительное время ЦП, затраченное на проверку условия WHERE .
Фактическое количество строк, которое выберет этот запрос, составляет 7000, но оценка rows является лишь приблизительной. Если вы попытаетесь повторить этот эксперимент, вы, вероятно, получите немного другую оценку; более того, он может изменяться после каждой команды ANALYZE , потому что статистика, производимая ANALYZE , берется из случайной выборки таблицы.
Теперь,давайте сделаем условие более ограничительным:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100; QUERY PLAN Bitmap Heap Scan on tenk1 (cost=5.07..229.20 rows=101 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) Index Cond: (unique1 < 100)
Здесь планировщик решил использовать двухэтапный план:дочерний узел плана обращается к индексу,чтобы найти расположение строк,соответствующих условию индекса,а затем верхний узел плана фактически извлекает эти строки из самой таблицы.Выборка строк по отдельности намного дороже,чем их последовательное чтение,но поскольку посещать нужно не все страницы таблицы,это все равно дешевле,чем последовательное сканирование.(Причина использования двух уровней плана заключается в том,что верхний узел плана сортирует местоположения строк,определенные индексом,в физическом порядке перед их чтением,чтобы минимизировать затраты на отдельные выборки.»Битовая карта»,упомянутая в именах узлов,-это механизм,который выполняет сортировку).
Теперь давайте добавим еще одно условие в WHERE :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND stringu1 = 'xxx'; QUERY PLAN Bitmap Heap Scan on tenk1 (cost=5.04..229.43 rows=1 width=244) Recheck Cond: (unique1 < 100) Filter: (stringu1 = 'xxx'::name) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) Index Cond: (unique1 < 100)
Добавленное условие stringu1 = 'xxx' уменьшает оценку количества выходных строк, но не снижает стоимость, потому что нам все равно нужно посещать тот же набор строк. Обратите внимание, что предложение stringu1 не может применяться как условие индекса, поскольку этот индекс находится только в столбце unique1 . Вместо этого он применяется как фильтр к строкам, полученным индексом. Таким образом, стоимость фактически немного выросла, чтобы отразить эту дополнительную проверку.
В некоторых случаях планировщик предпочтет «простой» план сканирования индексов:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 = 42; QUERY PLAN Index Scan using tenk1_unique1 on tenk1 (cost=0.29..8.30 rows=1 width=244) Index Cond: (unique1 = 42)
В этом типе плана строки таблицы выбираются в порядке индекса, что делает их еще более дорогостоящими для чтения, но их так мало, что дополнительные затраты на сортировку местоположений строк не окупаются. Чаще всего вы увидите этот тип плана для запросов, которые выбирают только одну строку. Он также часто используется для запросов, у которых есть условие ORDER BY , которое соответствует порядку индекса, потому что в этом случае не требуется дополнительного шага сортировки для удовлетворения ORDER BY . В этом примере добавление ORDER BY unique1 будет использовать тот же план, потому что индекс уже неявно предоставляет запрошенный порядок.
Планировщик может реализовать предложение ORDER BY несколькими способами. Приведенный выше пример показывает, что такое предложение о порядке может быть реализовано неявно. Планировщик также может добавить явный шаг sort :
EXPLAIN SELECT * FROM tenk1 ORDER BY unique1; QUERY PLAN Sort (cost=1109.39..1134.39 rows=10000 width=244) Sort Key: unique1 -> Seq Scan on tenk1 (cost=0.00..445.00 rows=10000 width=244)
Если часть плана гарантирует упорядочение по префиксу требуемых ключей сортировки, то планировщик может вместо этого решить использовать incremental sort :
EXPLAIN SELECT * FROM tenk1 ORDER BY four, ten LIMIT 100; QUERY PLAN Limit (cost=521.06..538.05 rows=100 width=244) -> Incremental Sort (cost=521.06..2220.95 rows=10000 width=244) Sort Key: four, ten Presorted Key: four -> Index Scan using index_tenk1_on_four on tenk1 (cost=0.29..1510.08 rows=10000 width=244)
По сравнению с обычными сортировками, постепенная сортировка позволяет возвращать кортежи до того, как будет отсортирован весь набор результатов, что, в частности, позволяет проводить оптимизацию с помощью запросов LIMIT . Это также может уменьшить использование памяти и вероятность сброса сортировок на диск, но это происходит за счет увеличения накладных расходов, связанных с разделением набора результатов на несколько пакетов сортировки.
Если есть отдельные индексы для нескольких столбцов, указанных в WHERE , планировщик может выбрать комбинацию индексов И или ИЛИ:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000; QUERY PLAN Bitmap Heap Scan on tenk1 (cost=25.08..60.21 rows=10 width=244) Recheck Cond: ((unique1 < 100) AND (unique2 > 9000)) -> BitmapAnd (cost=25.08..25.08 rows=10 width=0) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) Index Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique2 (cost=0.00..19.78 rows=999 width=0) Index Cond: (unique2 > 9000)
Но это требует посещения обоих индексов,так что это не обязательно победа по сравнению с использованием только одного индекса и отношением к другому состоянию как к фильтру.Если вы измените соответствующие диапазоны,вы увидите,что план изменится соответствующим образом.
Вот пример, показывающий эффекты LIMIT :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2; QUERY PLAN Limit (cost=0.29..14.48 rows=2 width=244) -> Index Scan using tenk1_unique2 on tenk1 (cost=0.29..71.27 rows=10 width=244) Index Cond: (unique2 > 9000) Filter: (unique1 < 100)
Это тот же запрос, что и выше, но мы добавили LIMIT , чтобы не все строки нужно было извлекать, и планировщик передумал, что делать. Обратите внимание, что общая стоимость и количество строк узла сканирования индекса отображаются так, как если бы он был выполнен до конца. Однако ожидается, что узел Limit остановится после получения только пятой части этих строк, поэтому его общая стоимость составляет только пятую часть от стоимости, и это фактическая расчетная стоимость запроса. Этот план предпочтительнее добавления узла Limit к предыдущему плану, потому что Limit не может избежать оплаты начальных затрат на сканирование растрового изображения, поэтому общая стоимость при таком подходе будет более 25 единиц.
Давайте попробуем присоединиться к двум столам,используя колонки,которые мы обсуждали:
EXPLAIN SELECT * FROM tenk1 t1, tenk2 t2 WHERE t1.unique1 < 10 AND t1.unique2 = t2.unique2; QUERY PLAN Nested Loop (cost=4.65..118.62 rows=10 width=488) -> Bitmap Heap Scan on tenk1 t1 (cost=4.36..39.47 rows=10 width=244) Recheck Cond: (unique1 < 10) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.36 rows=10 width=0) Index Cond: (unique1 < 10) -> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.29..7.91 rows=1 width=244) Index Cond: (unique2 = t1.unique2)
В этом плане у нас есть узел соединения вложенного цикла с двумя сканированиями таблицы в качестве входных данных или дочерних элементов. Отступ строк сводки узла отражает структуру дерева плана. Первый или «внешний» дочерний элемент соединения — это растровое изображение, похожее на те, что мы видели раньше. Его стоимость и количество строк такие же, как мы получили бы от SELECT ... WHERE unique1 < 10 , потому что мы применяем предложение WHERE unique1 < 10 в этом узле. Предложение t1.unique2 = t2.unique2 еще не актуально, поэтому оно не влияет на количество строк внешнего сканирования. Узел соединения с вложенным циклом будет запускать свой второй или «внутренний» дочерний узел один раз для каждой строки, полученной от внешнего дочернего элемента. Значения столбца из текущей внешней строки могут быть подключены к внутреннему сканированию; здесь t1.unique2 значение из внешней строки доступно, поэтому мы получаем план и затраты, аналогичные тому, что мы видели выше для простого SELECT ... WHERE t2.unique2 = constant случай. (Расчетная стоимость на самом деле немного ниже, чем та, что была показана выше, в результате кэширования, которое, как ожидается, произойдет во время повторных сканирований индекса на t2 .) Затем стоимость узла цикла устанавливается на основе стоимости узла цикла. внешнее сканирование плюс одно повторение внутреннего сканирования для каждой внешней строки (здесь 10 * 7,91), плюс немного процессорного времени для обработки соединения.
В этом примере счетчик выходных строк соединения совпадает с произведением счетчиков строк двух сканирований, но это не так во всех случаях, потому что могут быть дополнительные WHERE которые упоминают обе таблицы и поэтому могут применяться только в точке соединения. , а не сканирование ввода. Вот пример:
EXPLAIN SELECT * FROM tenk1 t1, tenk2 t2 WHERE t1.unique1 < 10 AND t2.unique2 < 10 AND t1.hundred < t2.hundred; QUERY PLAN --------------------------------------------------------------------------------------------- Nested Loop (cost=4.65..49.46 rows=33 width=488) Join Filter: (t1.hundred < t2.hundred) -> Bitmap Heap Scan on tenk1 t1 (cost=4.36..39.47 rows=10 width=244) Recheck Cond: (unique1 < 10) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.36 rows=10 width=0) Index Cond: (unique1 < 10) -> Materialize (cost=0.29..8.51 rows=10 width=244) -> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.29..8.46 rows=10 width=244) Index Cond: (unique2 < 10)
Условие t1.hundred < t2.hundred не может быть проверено в индексе tenk2_unique2 , поэтому оно применяется на узле соединения. Это уменьшает предполагаемое количество выходных строк узла соединения, но не меняет сканирование входных данных.
Обратите внимание, что здесь планировщик решил «материализовать» внутреннее отношение соединения, поместив поверх него узел плана «Материализировать». Это означает, что сканирование индекса t2 будет выполнено только один раз, хотя узлу соединения с вложенным циклом необходимо прочитать эти данные десять раз, по одному разу для каждой строки из внешнего отношения. Узел Materialize сохраняет данные в памяти по мере их чтения, а затем возвращает данные из памяти при каждом последующем проходе.
При работе с внешними соединениями вы можете увидеть узлы плана соединения с прикрепленными условиями «Фильтр соединения» и «Фильтр». Условия фильтра соединения берутся из предложения ON внешнего соединения , поэтому строка, которая не соответствует условию фильтра соединения, все равно может быть сгенерирована как строка с нулевым расширением. Но простое условие фильтра применяется после правил внешнего соединения и, таким образом, безоговорочно удаляет строки. Во внутреннем объединении нет семантической разницы между этими типами фильтров.
Если мы немного изменим селективность запроса,то можем получить совсем другой план соединения:
EXPLAIN SELECT * FROM tenk1 t1, tenk2 t2 WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2; QUERY PLAN Hash Join (cost=230.47..713.98 rows=101 width=488) Hash Cond: (t2.unique2 = t1.unique2) -> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) -> Hash (cost=229.20..229.20 rows=101 width=244) -> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) Index Cond: (unique1 < 100)
Здесь планировщик решил использовать хэш-соединение, при котором строки одной таблицы вводятся в хеш-таблицу в памяти, после чего другая таблица сканируется, и хеш-таблица проверяется на совпадения с каждой строкой. Снова обратите внимание, как отступ отражает структуру плана: сканирование растрового изображения на tenk1 является входом для узла Hash, который создает хеш-таблицу. Затем он возвращается в узел Hash Join, который считывает строки из своего внешнего дочернего плана и ищет каждую из них в хеш-таблице.
Другой возможный тип соединения-слияние,проиллюстрированное здесь:
EXPLAIN SELECT * FROM tenk1 t1, onek t2 WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2; QUERY PLAN Merge Join (cost=198.11..268.19 rows=10 width=488) Merge Cond: (t1.unique2 = t2.unique2) -> Index Scan using tenk1_unique2 on tenk1 t1 (cost=0.29..656.28 rows=101 width=244) Filter: (unique1 < 100) -> Sort (cost=197.83..200.33 rows=1000 width=244) Sort Key: t2.unique2 -> Seq Scan on onek t2 (cost=0.00..148.00 rows=1000 width=244)
Соединение слиянием требует, чтобы его входные данные были отсортированы по ключам соединения. В этом плане данные tenk1 сортируются с использованием сканирования индекса для посещения строк в правильном порядке, но для onek предпочтительнее последовательное сканирование и сортировка , поскольку в этой таблице есть намного больше строк, которые нужно посетить. (Последовательное сканирование и сортировка часто превосходит сканирование индекса при сортировке большого количества строк из-за непоследовательного доступа к диску, необходимого для сканирования индекса.)
Один из способов взглянуть на варианты планов — заставить планировщика игнорировать любую стратегию, которую он считал самой дешевой, используя флаги включения / выключения, описанные в Разделе 20.7.1 . (Это грубый, но полезный инструмент. См. Также Раздел 14.3 .) Например, если мы не уверены, что последовательное сканирование и сортировка — лучший способ справиться с таблицей onek в предыдущем примере, мы могли бы попробовать
SET enable_sort = off; EXPLAIN SELECT * FROM tenk1 t1, onek t2 WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2; QUERY PLAN Merge Join (cost=0.56..292.65 rows=10 width=488) Merge Cond: (t1.unique2 = t2.unique2) -> Index Scan using tenk1_unique2 on tenk1 t1 (cost=0.29..656.28 rows=101 width=244) Filter: (unique1 < 100) -> Index Scan using onek_unique2 on onek t2 (cost=0.28..224.79 rows=1000 width=244)
который показывает, что планировщик считает, что сортировка onek методом сканирования индекса примерно на 12% дороже, чем последовательное сканирование и сортировка. Конечно, следующий вопрос — правда ли это? Мы можем исследовать это с помощью EXPLAIN ANALYZE , как описано ниже.
14.1.2. EXPLAIN ANALYZE
Можно проверить точность оценок в планировщике с помощью EXPLAIN «s ANALYZE вариант. С этой опцией EXPLAIN фактически выполняет запрос, а затем отображает истинное количество строк и истинное время выполнения, накопленное в каждом узле плана, вместе с теми же оценками, которые показывает простой EXPLAIN . Например, мы можем получить такой результат:
EXPLAIN ANALYZE SELECT * FROM tenk1 t1, tenk2 t2 WHERE t1.unique1 < 10 AND t1.unique2 = t2.unique2; QUERY PLAN Nested Loop (cost=4.65..118.62 rows=10 width=488) (actual time=0.128..0.377 rows=10 loops=1) -> Bitmap Heap Scan on tenk1 t1 (cost=4.36..39.47 rows=10 width=244) (actual time=0.057..0.121 rows=10 loops=1) Recheck Cond: (unique1 < 10) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.36 rows=10 width=0) (actual time=0.024..0.024 rows=10 loops=1) Index Cond: (unique1 < 10) -> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.29..7.91 rows=1 width=244) (actual time=0.021..0.022 rows=1 loops=10) Index Cond: (unique2 = t1.unique2) Planning time: 0.181 ms Execution time: 0.501 ms
Обратите внимание, что значения «фактического времени» указаны в миллисекундах реального времени, тогда как оценки cost выражаются в произвольных единицах; так что вряд ли они совпадут. Обычно важнее всего обратить внимание на то, достаточно ли близко предполагаемое количество строк к реальности. В этом примере все оценки были точны, но на практике это довольно необычно.
В некоторых планах запросов возможно выполнение узла подплана более одного раза. Например, сканирование внутреннего индекса будет выполняться один раз для каждой внешней строки в приведенном выше плане вложенного цикла. В таких случаях loops значение сообщает общее количество выполнений узла, а фактическое время и значение строк показаны средние за-исполнения. Это сделано для того, чтобы цифры были сопоставимы с тем, как отображается смета расходов. Умножение с помощью loops дорожит , чтобы получить общее время фактически проведенное в узле. В приведенном выше примере мы потратили в общей сложности 0,220 миллисекунды на выполнение сканирования индекса на tenk2 .
В некоторых случаях EXPLAIN ANALYZE показывает дополнительную статистику выполнения помимо времени выполнения узла плана и количества строк. Например, узлы сортировки и хеширования предоставляют дополнительную информацию:
EXPLAIN ANALYZE SELECT * FROM tenk1 t1, tenk2 t2 WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2 ORDER BY t1.fivethous; QUERY PLAN Sort (cost=717.34..717.59 rows=101 width=488) (actual time=7.761..7.774 rows=100 loops=1) Sort Key: t1.fivethous Sort Method: quicksort Memory: 77kB -> Hash Join (cost=230.47..713.98 rows=101 width=488) (actual time=0.711..7.427 rows=100 loops=1) Hash Cond: (t2.unique2 = t1.unique2) -> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.007..2.583 rows=10000 loops=1) -> Hash (cost=229.20..229.20 rows=101 width=244) (actual time=0.659..0.659 rows=100 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 28kB -> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) (actual time=0.080..0.526 rows=100 loops=1) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.049..0.049 rows=100 loops=1) Index Cond: (unique1 < 100) Planning time: 0.194 ms Execution time: 8.008 ms
Узел Sort показывает используемый метод сортировки (в частности,была ли сортировка в памяти или на диске),а также необходимый объем памяти или дискового пространства.Хэш-узел показывает количество хэш-вёдер и партий,а также пиковый объем памяти,используемый для хэш-таблицы.(Если количество партий превысит единицу,то будет задействовано и дисковое пространство,но это не показано).
Другим типом дополнительной информации является количество строк,удаленных условием фильтрации:
EXPLAIN ANALYZE SELECT * FROM tenk1 WHERE ten < 7; QUERY PLAN Seq Scan on tenk1 (cost=0.00..483.00 rows=7000 width=244) (actual time=0.016..5.107 rows=7000 loops=1) Filter: (ten < 7) Rows Removed by Filter: 3000 Planning time: 0.083 ms Execution time: 5.905 ms
Эти подсчеты могут быть особенно ценными для условий фильтрации,применяемых в узлах соединения.Строка «Rows Removed» появляется только тогда,когда хотя бы одна отсканированная строка или потенциальная пара присоединения в случае узла присоединения отклоняется условием фильтрации.
Случай,похожий на условия фильтрации,возникает при сканировании индекса с «потерями».Например,рассмотрим поиск полигонов,содержащих определенную точку:
EXPLAIN ANALYZE SELECT * FROM polygon_tbl WHERE f1 @> polygon '(0.5,2.0)'; QUERY PLAN Seq Scan on polygon_tbl (cost=0.00..1.05 rows=1 width=32) (actual time=0.044..0.044 rows=0 loops=1) Filter: (f1 @> '((0.5,2))'::polygon) Rows Removed by Filter: 4 Planning time: 0.040 ms Execution time: 0.083 ms
Планировщик считает (вполне корректно),что этот образец таблицы слишком мал,чтобы беспокоиться о сканировании индексов,поэтому у нас есть простая последовательная проверка,в которой все строки были отвергнуты условием фильтрации.Но если мы заставим использовать проверку индексов,мы увидим:
SET enable_seqscan TO off; EXPLAIN ANALYZE SELECT * FROM polygon_tbl WHERE f1 @> polygon '(0.5,2.0)'; QUERY PLAN Index Scan using gpolygonind on polygon_tbl (cost=0.13..8.15 rows=1 width=32) (actual time=0.062..0.062 rows=0 loops=1) Index Cond: (f1 @> '((0.5,2))'::polygon) Rows Removed by Index Recheck: 1 Planning time: 0.034 ms Execution time: 0.144 ms
Здесь мы видим,что индекс вернул одну строку-кандидат,которая затем была отклонена при повторной проверке условия индекса.Это происходит потому,что индекс GiST является «потерянным» для тестов на сдерживание полигонов:он фактически возвращает строки с полигонами,которые перекрывают цель,а затем мы должны выполнить точный тест на сдерживание для этих строк.
EXPLAIN имеет параметр BUFFERS , который можно использовать с ANALYZE , чтобы получить еще больше статистики времени выполнения:
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000; QUERY PLAN Bitmap Heap Scan on tenk1 (cost=25.08..60.21 rows=10 width=244) (actual time=0.323..0.342 rows=10 loops=1) Recheck Cond: ((unique1 < 100) AND (unique2 > 9000)) Buffers: shared hit=15 -> BitmapAnd (cost=25.08..25.08 rows=10 width=0) (actual time=0.309..0.309 rows=0 loops=1) Buffers: shared hit=7 -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.043..0.043 rows=100 loops=1) Index Cond: (unique1 < 100) Buffers: shared hit=2 -> Bitmap Index Scan on tenk1_unique2 (cost=0.00..19.78 rows=999 width=0) (actual time=0.227..0.227 rows=999 loops=1) Index Cond: (unique2 > 9000) Buffers: shared hit=5 Planning time: 0.088 ms Execution time: 0.423 ms
Цифры, предоставляемые BUFFERS помогают определить, какие части запроса являются наиболее интенсивными по вводу-выводу.
Имейте в виду, что, поскольку EXPLAIN ANALYZE фактически выполняет запрос, любые побочные эффекты будут происходить как обычно, даже если любые результаты, которые мог бы выдать запрос, отбрасываются в пользу печати данных EXPLAIN . Если вы хотите проанализировать запрос, изменяющий данные, не изменяя свои таблицы, вы можете откатить команду назад, например:
BEGIN; EXPLAIN ANALYZE UPDATE tenk1 SET hundred = hundred + 1 WHERE unique1 < 100; QUERY PLAN Update on tenk1 (cost=5.08..230.08 rows=0 width=0) (actual time=3.791..3.792 rows=0 loops=1) -> Bitmap Heap Scan on tenk1 (cost=5.08..230.08 rows=102 width=10) (actual time=0.069..0.513 rows=100 loops=1) Recheck Cond: (unique1 < 100) Heap Blocks: exact=90 -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.05 rows=102 width=0) (actual time=0.036..0.037 rows=300 loops=1) Index Cond: (unique1 < 100) Planning Time: 0.113 ms Execution Time: 3.850 ms ROLLBACK;
Как видно в этом примере, когда запрос представляет собой INSERT , UPDATE или DELETE , фактическая работа по применению изменений таблицы выполняется узлом плана верхнего уровня Вставить, Обновить или Удалить. Узлы плана под этим узлом выполняют работу по поиску старых строк и / или вычислению новых данных. Итак, выше мы видим тот же вид сканирования таблицы растровых изображений, который мы уже видели, и его вывод передается на узел обновления, в котором хранятся обновленные строки. Стоит отметить, что хотя узел изменения данных может занять значительное время выполнения (здесь он потребляет львиную долю времени), планировщик в настоящее время ничего не добавляет к оценкам затрат для учета этой работы. Это связано с тем, что работа, которую необходимо выполнить для каждого правильного плана запроса, не влияет на решения по планированию.
Когда команда UPDATE или DELETE влияет на иерархию наследования, вывод может выглядеть следующим образом:
EXPLAIN UPDATE parent SET f2 = f2 + 1 WHERE f1 = 101; QUERY PLAN Update on parent (cost=0.00..24.59 rows=0 width=0) Update on parent parent_1 Update on child1 parent_2 Update on child2 parent_3 Update on child3 parent_4 -> Result (cost=0.00..24.59 rows=4 width=14) -> Append (cost=0.00..24.54 rows=4 width=14) -> Seq Scan on parent parent_1 (cost=0.00..0.00 rows=1 width=14) Filter: (f1 = 101) -> Index Scan using child1_pkey on child1 parent_2 (cost=0.15..8.17 rows=1 width=14) Index Cond: (f1 = 101) -> Index Scan using child2_pkey on child2 parent_3 (cost=0.15..8.17 rows=1 width=14) Index Cond: (f1 = 101) -> Index Scan using child3_pkey on child3 parent_4 (cost=0.15..8.17 rows=1 width=14) Index Cond: (f1 = 101)
В этом примере узел Update должен рассмотреть три дочерние таблицы,а также первоначально упомянутую родительскую таблицу.Таким образом,существует четыре подплана входного сканирования,по одному на каждую таблицу.Для наглядности узел Update аннотирован,чтобы показать конкретные целевые таблицы,которые будут обновлены,в том же порядке,что и соответствующие подпланы.
Время Planning time показываемое EXPLAIN ANALYZE , — это время, которое потребовалось для создания плана запроса из проанализированного запроса и его оптимизации. Он не включает синтаксический анализ или перезапись.
Время Execution time показываемое EXPLAIN ANALYZE , включает время запуска и выключения исполнителя, а также время запуска любых срабатывающих триггеров, но не включает время синтаксического анализа, перезаписи или планирования. Время, затраченное на выполнение триггеров BEFORE , если они есть, включается во время связанного узла Вставка, Обновление или Удаление; но время, потраченное на выполнение триггеров AFTER , не учитывается, потому что триггеры AFTER срабатывают после завершения всего плана. Общее время, затраченное на каждый триггер ( BEFORE или AFTER ) также отображается отдельно. Обратите внимание, что триггеры отложенных ограничений не будут выполняться до конца транзакции и, таким образом, не будут учитываться EXPLAIN ANALYZE .
14.1.3. Caveats
Время выполнения, измеренное с помощью EXPLAIN ANALYZE , может отличаться от нормального выполнения одного и того же запроса двумя важными способами . Во-первых, поскольку никакие выходные строки не доставляются клиенту, затраты на передачу по сети и затраты на преобразование ввода-вывода не включаются. Во-вторых, накладные расходы на измерения, добавленные EXPLAIN ANALYZE , могут быть значительными, особенно на машинах с медленными gettimeofday() операционной системы gettimeofday () . Вы можете использовать инструмент pg_test_timing , чтобы измерить накладные расходы времени в вашей системе.
EXPLAIN Результаты EXPLAIN не следует экстраполировать на ситуации, сильно отличающиеся от той, которую вы фактически тестируете; например, нельзя предполагать, что результаты для таблицы размером с игрушку применимы к большим таблицам. Смета расходов планировщика не является линейной, поэтому он может выбрать другой план для большего или меньшего стола. Ярким примером является то, что для таблицы, занимающей только одну страницу на диске, вы почти всегда получаете план последовательного сканирования независимо от того, доступны ли индексы или нет. Планировщик понимает, что для обработки таблицы в любом случае потребуется чтение одной страницы с диска, поэтому нет смысла расходовать дополнительные чтения страницы для просмотра индекса. (Мы видели это в polygon_tbl выше примере polygon_tbl .)
Бывают случаи, когда фактические и расчетные значения не совпадают, но на самом деле все в порядке. Один из таких случаев происходит, когда выполнение узла плана прекращается из-за LIMIT или аналогичного эффекта. Например, в запросе LIMIT ,который мы использовали ранее,
EXPLAIN ANALYZE SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2; QUERY PLAN Limit (cost=0.29..14.71 rows=2 width=244) (actual time=0.177..0.249 rows=2 loops=1) -> Index Scan using tenk1_unique2 on tenk1 (cost=0.29..72.42 rows=10 width=244) (actual time=0.174..0.244 rows=2 loops=1) Index Cond: (unique2 > 9000) Filter: (unique1 < 100) Rows Removed by Filter: 287 Planning time: 0.096 ms Execution time: 0.336 ms
расчетная стоимость и количество строк для узла Index Scan отображаются так,как будто он был запущен до конца.Но в реальности узел Limit перестал запрашивать строки после того,как их стало два,поэтому фактическое количество строк составляет всего 2,а время выполнения меньше,чем можно предположить по расчетной стоимости.Это не ошибка оценки,а только расхождение в способе отображения оценок и истинных значений.
Объединения слиянием также имеют артефакты измерения, которые могут сбить с толку неосторожных. Соединение слиянием прекратит чтение одного ввода, если оно исчерпало другой ввод, и следующее значение ключа в одном вводе больше, чем последнее значение ключа другого ввода; в таком случае совпадений больше не может быть, и поэтому нет необходимости сканировать оставшуюся часть первого ввода. Это приводит к тому, что не читается весь один дочерний элемент, с результатами, подобными упомянутым для LIMIT . Кроме того, если внешний (первый) дочерний элемент содержит строки с повторяющимися значениями ключа, внутренний (второй) дочерний элемент создается резервной копии и повторно проверяется для части его строк, соответствующей этому значению ключа. EXPLAIN ANALYZE считает эти повторные выбросы одних и тех же внутренних строк, как если бы они были реальными дополнительными строками. Когда имеется много внешних дубликатов, сообщаемое фактическое количество строк для внутреннего дочернего узла плана может быть значительно больше, чем количество строк, которые фактически находятся во внутренней связи.
BitmapAnd и BitmapOr узлы всегда сообщают о том,что их реальная строка считается нулевой,в связи с ограничениями по реализации.
Обычно EXPLAIN отображает каждый узел плана, созданный планировщиком. Однако есть случаи, когда исполнитель может определить, что определенные узлы не нужно выполнять, потому что они не могут создавать какие-либо строки, на основе значений параметров, которые не были доступны во время планирования. (В настоящее время это может происходить только для дочерних узлов узла Append или MergeAppend, который сканирует секционированную таблицу.) Когда это происходит, эти узлы плана пропускаются из вывода EXPLAIN , и вместо этого появляется аннотация Subplans Removed: N
PostgreSQL
15.0
-
F.48. unaccent
unaccent-это словарь для поиска текста,который удаляет ударения (диакритические знаки)из лексем.
-
19.6.Обновление кластера PostgreSQL
В этом разделе рассматривается,как обновить базу данных с одного выпуска PostgreSQL на более новый Текущие номера версий PostgreSQL состоят из мажорного и минорного For
-
F.49. uuid-ossp
Модуль uuid-ossp предоставляет функции для генерации универсально уникальных идентификаторов (UUID)с использованием одного из нескольких стандартных алгоритмов.
-
54.3. pg_available_extension_versions
В представлении pg_available_extension_versions перечислены конкретные версии,предназначенные для установки.
Во время выполнения запроса, оптимизатор запросов MySQL пытается ускорить этот процесс. Вы можете увидеть это, если добавите ключевое слово EXPLAIN перед запросом. EXPLAIN – один из самых мощных инструментов, находящийся в вашем распоряжении, для анализа процесса выполнения и оптимизации сложных MySQL-запросов, но, к сожалению, многие разработчики используют его редко. В этой статье я расскажу вам о том, какую информацию выводит EXPLAIN и как, используя ее, можно оптимизировать запросы и структуру базы данных.
Чтобы использовать EXPLAIN, нужно добавить его перед вашим запросом:
SQL
EXPLAIN SELECT * FROM categories;
EXPLAIN: выборка всех данных из таблицы Хоть в это и трудно поверить, но в 10 строчках, которые возвращает запрос, хранится много полезной информации. Что же выводит EXPLAIN?

id— порядковый идентификатор каждого SELECT, находящегося внутри запроса (в случае использования вложенных подзапросов)select_type– тип SELECT запроса. Возможные значения:SIMPLE– запрос содержит простую выборку без подзапросов иUNION‘овPRIMARY– запрос является внешним запросов вJOINDERIVED– запросSELECTявляется частью подзапроса внутри выраженияFROMSUBQUERY– первыйSELECTв подзапросеDEPENDENT SUBQUERY— первыйSELECT, зависящий от внешнего подзапросаUNCACHEABLE SUBQUERY– некешируемый подзапросUNION–SELECTявляется вторым или последующим вUNIONDEPENDENT UNION–SELECTявляется вторым или последующим запросом вUNIONи зависит от внешних запросов/li>UNION RESULT–SELECTявляется результатомUNION‘а
table– таблица, которой относится текущая строкаtype– тип связывания таблиц. Это один из самых важных столбцов в результате, потому что по нему можно вычислить потерянные индексы или понять, как можно улучшить запрос.
Возможные значения:system– таблица содержит только одну строку (системная таблица);const— таблица содержит не более одной соответствующей строки, которая будет считываться в начале запроса. Поскольку имеется только одна строка, оптимизатор в дальнейшем может расценивать значения этой строки в столбце как константы. Таблицыconstявляются очень быстрыми, поскольку они читаются только однажды;eq_ref— для каждой комбинации строк из предыдущих таблиц будет cчитываться одна строка из этой таблицы. Это наилучший возможный тип связывания среди типов, отличных отconst. Данный тип применяется, когда все части индекса используются для связывания, а сам индекс —UNIQUEилиPRIMARY KEY;ref— из этой таблицы будут считываться все строки с совпадающими значениями индексов для каждой комбинации строк из предыдущих таблиц. Типrefприменяется, если для связывания используется только крайний левый префикс ключа, или если ключ не являетсяUNIQUEилиPRIMARY KEY(другими словами, если на основании значения ключа для связывания не может быть выбрана одна строка). Этот тип связывания хорошо работает, если используемый ключ соответствует только нескольким строкам;fulltext– объединение, использующее полнотекстовый (FULLTEXT) индекс таблиц;ref_or_null– то же самое, что иref, только содержащее строки со значениемNULLв полях;index_merge– объединение, использующее список индексов для получения результата запроса;unique_subquery– результат подзапроса в выраженииINвозвращает одну строку, используемую в качестве первичного ключа;index_subquery– то же самое, что и unique_subquery, только в результате больше одной строки;range– в запросе происходит сравнение ключевого поля с диапазоном значений (используются операторыBETWEEN,IN, >, >=);index– в процессе выполнения запроса сканируется только дерево индексов;all– в процессе выполнения запроса сканируются все таблицы. Это наихудший тип объединения и обычно указывает на отсутствие надлежащих индексов в таблице;
possible_keys– показаны возможные индексы, которые могут использоваться MySQL для поиска данных в таблице. На самом деле, значение этого столбца, очень часто помогает оптимизировать запросы. Если значение равно NULL, значит, никаких индексов не используется.key– отображается текущий ключ, используемый MySQL в данный момент. В этом столбце может отображаться индекс, отсутствующий вpossible_keys. Оптимизатор запросов MySQL всегда пытается найти оптимальный ключ, который будет использоваться в запросе. При объединении нескольких таблиц, MySQL может использовать индексы, также не указанные вpossible_keys.key_len– содержит длину ключа, выбранного оптимизатором запросов MySQL. Если значениеkeyравноNULL, тоkey_lenтожеNULL. По значению длины ключа можно определить, сколько частей составного ключа в действительности будет использовать MySQL. Подробнее об этом можно почитать в руководстве по MySQL.ref– показаны поля или константы, которые используются совместно с ключом, указанным в столбцеkey.rows– количество строк, которые анализируются MySQL в процессе запроса. Это еще один важный показатель, указывающий на необходимость оптимизации запросов, особенно тех, которые содержатJOINи подзапросы.extra– содержит дополнительную информацию о процессе выполнения запроса. Если значениями этого столбца являются ”Using temporary”, “Using filesort” и т.п, то это говорит о том, что это «проблемный» запрос, требующий оптимизации. С полным список значений этого столбца можно ознакомиться в руководстве по MySQL.
Вы можете добавить ключевое слово EXTENDED после EXPLAIN, чтобы увидеть дополнительную информацию о выполнении запроса. После запроса EXPLAIN бывает полезно выполнить запрос SHOW WARNING, показывающий предупреждения и сообщения, касающиеся последнего запроса, а именно перобразований, сделанных оптимизатором запросов MySQL.
SQL
EXPLAIN EXTENDED SELECT City.Name FROM City JOIN Country ON (City.CountryCode = Country.Code) WHERE City.CountryCode = 'IND' AND Country.Continent = 'Asia';
Расширенный вариант EXPLAIN EXTENDED SQL
Результат запроса SHOW WARNINGS Оптимизация производительности с помощью EXPLAIN.
Давайте сейчас попробуем проанализировать информацию, предоставляемую EXPLAIN, и поймем, как можно оптимизировать неэффективные запросы. В реальном приложении используется множество связанных таблиц, поэтому сложно заранее знать то, как нужно написать запрос, который выполняется быстро.
Я создал простую базу данных приложения электронной коммерции, в которой нет ни индексов, ни первичных ключей и сейчас я продемонстрирую, то, как ужасно она спроектирована, путем выполнения довольно сложного запроса. Вы можете скачать дамп этой базы данных с GitHub.
SQL
EXPLAIN SELECT * FROM orderdetails d INNER JOIN orders o ON d.orderNumber = o.orderNumber INNER JOIN products p ON p.productCode = d.productCode INNER JOIN productlines l ON p.productLine = l.productLine INNER JOIN customers c on c.customerNumber = o.customerNumber WHERE o.orderNumber = 10101
Анализируем запрос с помощью EXPLAIN Если вы взглянете на рисунок выше, то увидите все признаки «плохого» запроса. Но даже если я поправлю запрос, результаты не сильно изменятся, потому что в таблицах отсутствуют индексы. Тип объединения равен ”ALL” (напоминаю, что это наихудший вариант). Это значит, что MySQL не может найти ни одного ключа, который может участвовать в объединении, поэтому значение столбцов
possible_keysиkeyравноNULL. Хуже всего то, что в процессе запроса MySQL будет сканировать все записи во всех таблицах, об этом говорит значение столбцовrows. При выполнении запроса будут просмотрены 91.750.822.240 записей (7 × 110 × 122 × 326 × 2996), чтобы получить результат из 4 записей. Это действительно ужасно, и будет только хуже, когда количество записей в базе данных будет увеличиваться.А сейчас давайте добавим первичные ключи у всех таблиц и выполним запрос еще раз. Как правило, при создании индексов, обращают внимание на поля, по которым происходит объединение (
JOIN), — это отличные кандидаты, для присвоения индексов, потому что MySQL всегда «просматривает» их при поиске связанных записей.SQL
ALTER TABLE customers ADD PRIMARY KEY (customerNumber); ALTER TABLE employees ADD PRIMARY KEY (employeeNumber); ALTER TABLE offices ADD PRIMARY KEY (officeCode); ALTER TABLE orderdetails ADD PRIMARY KEY (orderNumber, productCode); ALTER TABLE orders ADD PRIMARY KEY (orderNumber), ADD KEY (customerNumber); ALTER TABLE payments ADD PRIMARY KEY (customerNumber, checkNumber); ALTER TABLE productlines ADD PRIMARY KEY (productLine); ALTER TABLE products ADD PRIMARY KEY (productCode), ADD KEY (buyPrice), ADD KEY (productLine); ALTER TABLE productvariants ADD PRIMARY KEY (variantId), ADD KEY (buyPrice), ADD KEY (productCode);Теперь давайте выполним наш сложный запрос еще раз после добавления индексов. Результат будет следующий:
Результат запроса после добавления индексов После добавления индексов, количество сканируемых записей снизилось до 4 (1 × 1 × 4 × 1 × 1). Это говорит о том, что для каждой записи с ключом orderNumber из таблицы orderdetails MySQL сможет найти связанные записи во всех таблицах, используя индексы, а не сканируя все таблицы полностью.
В первой строке результата, который выводит
EXPLAIN, вы можете видеть, что тип объединения равен ”const”, — это самым быстрый тип объединения таблиц, содержащих более одной записи. В данном случае MySQL будет использовать первичный ключ в качестве индекса.Давайте рассмотрим еще один запрос. Объединим 2 запроса
SELECTк таблицам products и productvariants с помощьюUNION, при этом в каждом из запросов будет участвовать таблица productline. В таблице productvariants хранятся разновидности товара. В ней содержатся поля productCode (ссылка на записи в таблице products) и поле с ценой buyPrice.SQL
EXPLAIN SELECT * FROM ( SELECT p.productName, p.productCode, p.buyPrice, l.productLine, p.status, l.status AS lineStatus FROM products p INNER JOIN productlines l ON p.productLine = l.productLine UNION SELECT v.variantName AS productName, v.productCode, p.buyPrice, l.productLine, p.status, l.status AS lineStatus FROM productvariants v INNER JOIN products p ON p.productCode = v.productCode INNER JOIN productlines l ON p.productLine = l.productLine ) products WHERE status = 'Active' AND lineStatus = 'Active' AND buyPrice BETWEEN 30 AND 50;
EXPLAIN с UNION Вы можете увидеть некоторые проблемы в этом запросе. Сканируются все записи из таблиц products и productvariants. Так как в этих таблицах нет индексов по полям productLine и buyPrice, значения
possible_keysиkey, которые выводитEXPLAIN, имеют значенияNULL.Статус таблиц products и productlines проверяется после
UNION, если перенести их внутрьUNION, это уменьшит количество обрабатываемых записей. Давайте добавим еще несколько дополнительных индексов и повторим запрос.SQL
CREATE INDEX idx_buyPrice ON products(buyPrice); CREATE INDEX idx_buyPrice ON productvariants(buyPrice); CREATE INDEX idx_productCode ON productvariants(productCode); CREATE INDEX idx_productLine ON products(productLine);SQL
EXPLAIN SELECT * FROM ( SELECT p.productName, p.productCode, p.buyPrice, l.productLine, p.status, l.status as lineStatus FROM products p INNER JOIN productlines AS l ON (p.productLine = l.productLine AND p.status = 'Active' AND l.status = 'Active') WHERE buyPrice BETWEEN 30 AND 50 UNION SELECT v.variantName AS productName, v.productCode, p.buyPrice, l.productLine, p.status, l.status FROM productvariants v INNER JOIN products p ON (p.productCode = v.productCode AND p.status = 'Active') INNER JOIN productlines l ON (p.productLine = l.productLine AND l.status = 'Active') WHERE v.buyPrice BETWEEN 30 AND 50 ) product;
Результат EXPLAIN после добавления индексов Как вы видите, сейчас количество обрабатываемых строк значительно снизилось с 2.625.810 (219 × 110 × 109) до 276 (12 × 23), что дает огромный прирост производительности. MySQL не будет использовать индексы в этом запросе, из-за условий в
WHERE. После переноса этих условий внутрьUNION, использование индексов стало возможным. Все это говорит о том, что не всегда достаточно создавать индексы, MySQL не сможет использовать их в определенных запросах.Заключение
В этой статье я познакомил вас с ключевым словом
EXPLAIN, рассказал о том, что означают данные, которые выводятся в результате его работы и как вы можете их использовать для оптимизации запросов. ИспользоватьEXPLAINв реальном приложении это будет более полезно, чем на демонстрационной базе данных из этой статьи. Почти всегда вы будете объединять несколько таблиц вместе, и использоватьWHERE. Простое добавление индексов нескольким полям обычно не приносит выгоды, поэтому в процессе составления запросов особое внимание надо уделять самим запросам.Перевод – Земсков Матвей
Оригинал статьи: http://phpmaster.com/using-explain-to-write-better-mysql-queries/






- Профилирование запроса
- Оптимизация
- Рекомендации для решения данной проблемы
- Заключение
Включение профилирования — это доступный способ получить точную оценку времени выполнения запроса. Сначала нужно включить профилирование и вызвать show profiles, чтобы получить время выполнения запроса.
Например, у нас есть следующая операция добавления данных. Предположим, что User1 и Gallery1 уже созданы:
INSERT INTO `homestead`.`images` (`id`, `gallery_id`, `original_filename`, `filename`, `description`) VALUES (1, 1, 'me.jpg', 'me.jpg', 'A photo of me walking down the street'), (2, 1, 'dog.jpg', 'dog.jpg', 'A photo of my dog on the street'), (3, 1, 'cat.jpg', 'cat.jpg', 'A photo of my cat walking down the street'), (4, 1, 'purr.jpg', 'purr.jpg', 'A photo of my cat purring');
Выполнение этого запроса не вызовет проблем. Но рассмотрим следующую команду:
SELECT * FROM `homestead`.`images` AS i WHERE i.description LIKE '%street%';
Этот запрос является подходящим примером того, что может стать причиной проблем в будущем, если мы сделаем выборку из базы данных большого количества изображений.
Чтобы получить точное время выполнения этого запроса, можно использовать следующий SQL-код:
set profiling = 1; SELECT * FROM `homestead`.`images` AS i WHERE i.description LIKE '%street%'; show profiles;
Результат:
| Query_Id | Продолжительность | Запрос |
| 1 | 0.00016950 | SHOW WARNINGS |
| 2 | 0.00039200 | SELECT * FROM homestead.images AS i nWHERE i.description LIKE ’%street%’nLIMIT 0, 1000 |
| 3 | 0.00037600 | SHOW KEYS FROM homestead.images |
| 4 | 0.00034625 | SHOW DATABASES LIKE ’homestead |
| 5 | 0.00027600 | SHOW TABLES FROM homestead LIKE ’images’ |
| 6 | 0.00024950 | SELECT * FROM homestead.images WHERE 0=1 |
| 7 | 0.00104300 | SHOW FULL COLUMNS FROM homestead.images LIKE ’id’ |
Команда show profiles отображает время выполнения не только исходного запроса, но и всех остальных. Таким образом, можно точно профилировать запросы.
Но как их оптимизировать? Для этого можно использовать MySQL- команду explain и улучшить производительность запросов на основе фактической информации.
Explain используется для получения плана выполнения запроса. Того, как MySQL будет выполнять запрос. Эта команда работает с операторами SELECT, DELETE, INSERT, REPLACE и UPDATE. Официальная документация описывает команду explain следующим образом:
С помощью EXPLAIN можно увидеть, куда следует добавлять индексы в таблице, чтобы оператор выполнялся быстрее. Вы также можете использовать EXPLAIN, чтобы проверить, объединяет ли оптимизатор таблицы в оптимальном порядке.
В качестве примера мы рассмотрим запрос, выполняемый UserManager.php для нахождения пользователя по адресу электронной почты:
SELECT * FROM `homestead`.`users` WHERE email = 'claudio.ribeiro@examplemail.com';
Чтобы использовать команду explain, добавьте ее перед запросом на выборку:
EXPLAIN SELECT * FROM `homestead`.`users` WHERE email = 'claudio.ribeiro@examplemail.com';
Результат работы:
| id | select_type | table | partitions | type | possible_keys | Key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ‘users’ | NULL | ‘const’ | ‘UNIQ_1483A5E9E7927C74’ | ‘UNIQ_1483A5E9E7927C74’ | ‘182’ | ‘const’ | 100.00 | NULL |
- id: это последовательный идентификатор для каждого из запросов SELECT.
- select_type: тип запроса SELECT. Это поле может принимать различные значения:
- SIMPLE: простой запрос без подзапросов или объединений
- PRIMARY: select находится во внешнем запросе;
- DERIVED: select является частью подзапроса;
- SUBQUERY: первый select в подзапросе;
- UNION: select является вторым или последующим оператором объединения.
Полный список значений, которые могут указываться в поле select_type, можно найти здесь.
- table: название таблицы базы данных.
- type: указывается, как MySQL объединяет используемые таблицы. Значение может указывать на отсутствующие индексы и как должен быть переписан запрос. Возможные значения для этого поля:
- system: таблица имеет ноль или одну строку.
- const: таблица имеет только одну соответствующую строку, которая проиндексирована. Это самый быстрый тип объединения.
- eq_ref: все части индекса используются объединением. Используется индекс PRIMARY_KEY или UNIQUE NOT NULL.
- ref: из таблицы будут считаны все строки с совпадающим индексом для каждой комбинации строк из предыдущей. Этот тип объединения отображается для индексированных столбцов, сравниваемых с помощью операторов=или<=>.
- fulltext: объединение использует индекс таблицы FULLTEXT.
- ref_or_null: это то же самое, что и ref, но также содержит строки со значением NULL.
- index_merge: объединение использует список индексов для получения результирующего набора. Столбец KEY будет содержать используемые ключи.
- unique_subquery: подзапрос IN возвращает только один результат из таблицы и использует первичный ключ.
- range: индекс используется для поиска подходящих строк в определенном диапазоне.
- index: сканируется все дерево индексов, чтобы найти соответствующие строки.
- all: таблица сканируется, чтобы найти подходящие строки для объединения. Это наименее оптимальный тип объединения. Он часто указывает на отсутствие соответствующих индексов в таблице.
- possible_keys: показывает ключи, которые могут быть использованы MySQL для поиска строк в таблице.
- keys: фактический индекс, используемый MySQL. СУБД всегда ищет оптимальный ключ, который можно использовать для запроса. При объединении многих таблиц она может определить другие ключи, которые не перечислены в списке possible_keys, но являются более оптимальными.
- key_len: указывает длину индекса, который оптимизатор запросов выбрал для использования.
- ref: показывает столбцы или константы, которые сравниваются с индексом, указанным в столбце ключей.
- rows: количество записей, которые были проверены, чтобы произвести вывод. Это важный показатель; чем меньше проверенных записей, тем лучше.
- Extra: содержит дополнительную информацию. Такие значения, как Using filesort или Using temporary в этом столбце, могут указывать на проблемный запрос.
Полную документацию по формату вывода explain можно найти на официальной странице MySQL.
Возвращаясь к нашему запросу. Он имеет тип выборки SIMPLE с типом объединения const. Это наиболее оптимальное сочетание. Но что произойдет при выполнении более сложных запросов?
Например, когда нужно получить все изображения галереи. Или вывести только фотографии, которые содержат слово «cat» в описании. Рассмотрим следующий запрос:
SELECT gal.name, gal.description, img.filename, img.description FROM `homestead`.`users` AS users LEFT JOIN `homestead`.`galleries` AS gal ON users.id = gal.user_id LEFT JOIN `homestead`.`images` AS img on img.gallery_id = gal.id WHERE img.description LIKE '%dog%';
В этом случае у нас будет больше информации для анализа explain:
EXPLAIN SELECT gal.name, gal.description, img.filename, img.description FROM `homestead`.`users` AS users LEFT JOIN `homestead`.`galleries` AS gal ON users.id = gal.user_id LEFT JOIN `homestead`.`images` AS img on img.gallery_id = gal.id WHERE img.description LIKE '%dog%';
Результат работы запроса:
| id | select_type | table | partitions | type | possible_keys | Key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ‘users’ | NULL | ‘index’ | ‘PRIMARY,UNIQ_1483A5E9BF396750’ | ‘UNIQ_1483A5E9BF396750’ | ‘108’ | NULL | 100.00 | ‘Using index’ | |
| 1 | SIMPLE | ‘gal’ | NULL | ‘ref’ | ‘PRIMARY,UNIQ_F70E6EB7BF396750,IDX_F70E6EB7A76ED395’ | ‘UNIQ_1483A5E9BF396750’ | ‘108’ | ‘homestead.users.id’ | 100.00 | NULL | |
| 1 | SIMPLE | ‘img’ | NULL | ‘ref’ | ‘IDX_E01FBE6A4E7AF8F’ | ‘IDX_E01FBE6A4E7AF8F’ | ‘109’ | ‘homestead.gal.id’ | ‘25.00’ | ‘Using where’ |
Основными столбцами, на которые мы должны обратить внимание, являются type
и . Цель заключается в том, чтобы получить лучшее значение в столбце type и как можно меньшее число в столбце rows.
Результат первого запроса index плохой. Это означает, что мы можем оптимизировать запрос.
Таблица Users не используется. Поэтому можно расширить запрос, чтобы убедиться, что мы охватываем пользователей, или удалить часть запроса users. Но это только увеличит сложность и время выполнения.
SELECT gal.name, gal.description, img.filename, img.description FROM `homestead`.`galleries` AS gal LEFT JOIN `homestead`.`images` AS img on img.gallery_id = gal.id WHERE img.description LIKE '%dog%';
Посмотрим на вывод explain:
| id | select_type | Table | partitions | type | possible_keys | key | key_len | Ref | rows | filtered | Extra |
| 1 | SIMPLE | ‘gal’ | NULL | ‘ALL’ | ‘PRIMARY,UNIQ_1483A5E9BF396750’ | NULL | NULL | NULL | 100.00 | NULL | |
| 1 | SIMPLE | ‘img’ | NULL | ‘ref’ | ‘IDX_E01FBE6A4E7AF8F’ | ‘IDX_E01FBE6A4E7AF8F’ | ‘109’ | ‘homestead.gal.id’ | ‘25.00’ | ‘Using where’ |
У нас все равно осталось значение type ALL. Это один из худших вариантов объединения, но иногда это единственно возможный тип.
Нам нужны все изображения галереи, поэтому следует просмотреть всю таблицу галереи. Индексы подходят для поиска конкретных данных в таблице. Но не для выборки всей информации из таблицы.
Последнее, что мы можем сделать, добавить в поле описания индекс FULLTEXT. Так мы изменим LIKE на match() и повысим производительность. Подробнее о полнотекстовых индексах можно узнать здесь.
Вернемся к функционалу разрабатываемого нами приложения: newest и related. Они применяются в галереях. В них используются следующие запросы:
EXPLAIN SELECT * FROM `homestead`.`galleries` AS gal LEFT JOIN `homestead`.`users` AS u ON u.id = gal.user_id WHERE u.id = 1 ORDER BY gal.created_at DESC LIMIT 5;
Приведенный выше код предназначен для related.
EXPLAIN SELECT * FROM `homestead`.`galleries` AS gal ORDER BY gal.created_at DESC LIMIT 5;
Приведенный выше код предназначен для newest.
На первый взгляд эти запросы быстрые, потому что используют . К сожалению, в нашем приложении эти запросы также используют оператор ORDER BY. Поэтому мы теряем преимущества использования LIMIT.
Работа с может ухудшать производительность. Чтобы проверить это, выполним команду explain.
| id | select_type | Table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ‘gal’ | NULL | ‘ALL’ | ‘IDX_F70E6EB7A76ED395’ | NULL | NULL | NULL | 100.00 | ‘Using where; Using filesort’ | |
| 1 | SIMPLE | ‘u’ | NULL | ‘eq_ref’ | ‘PRIMARY,UNIQ_1483A5E9BF396750’ | ‘PRIMARY | ‘108’ | ‘homestead.gal.id’ | ‘100.00’ | NULL |
и
| id | select_type | table | partitions | Type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ‘gal’ | NULL | ‘ALL’ | NULL | NULL | NULL | NULL | 100.00 | ‘Using filesort’ |
Как мы видим, у нас наихудший тип объединения: ALL для обоих запросов.
Комбинация и LIMIT часто являлась причиной проблем с производительностью MySQL. Эта связка операторов используется в большинстве интерактивных приложений с большими наборами данных.
- Используйте индексы. В нашем случае created_at — отличный вариант. Таким образом, мы выполняем , и LIMIT без сканирования и сортировки полного набора результатов.
- Сортировка по столбцу в ведущей таблице. Если ORDER BY указывается после поля из таблицы, которое не является первым в порядке объединения, индекс не может быть использован.
- Не сортируйте по выражениям. Выражения и функции не позволяют использовать индексы по ORDER BY.
- Остерегайтесь большого значения . Большие значения LIMIT приводят к сортировке ORDER BY по большему количеству строк. Это влияет на производительность.
Команда explain позволяет выявить проблемы в запросах на ранней стадии разработки приложения и обеспечить программе высокую производительность.