Содержание:
- Что такое инциденты?
- Что такое проблемы и чем они отличаются от инцидентов?
- Что такое система управления инцидентами?
- Почему так сложно управлять инцидентами?
- Как внедрить систему управления инцидентами?
- Каковы особенности хороших инструментов управления инцидентами?
- Как ServiceDesk может помочь в системе управления инцидентами?
- Резюмируя
Усиление конкуренции на рынке услуг заставляет бизнес бороться за клиентов, улучшая качество продуктов и услуг, обеспечивая большую прозрачность работы сервисов. Бизнес-процессы фирм все сильнее зависят от IT среды. Для нормального функционирования компаний приоритетной задачей становится быстрое реагирование на возникающие инциденты.
Что такое инциденты?

Сегодня утром в офисе у бухгалтера, готовящего отчет для начальства неисправен принтер. Замятие бумаги или закончились чернила – это можно назвать инцидентом.
Инцидент в IT сфере является нарушением любого рабочего процесса, приводящего к прекращению нормального функционирования инфраструктуры.
Можно выделить следующие типы инцидентов:
- Технические — любое происшествие, которое мешает правильному функционированию оборудования и программного обеспечения (нехватка рабочего места на диске, отказ компьютерных систем или ПО, обрыв проводов, замыкания, снижение уровня сигнала и т.д.).
- Информационные — несанкционированный доступ к конфиденциальным данным, их раскрытие или изменение. Нанесение урона компьютерным программам вследствие заражения вирусом и внешних атак.
- Нарушение нормативных актов, политики или законов ИТ-инфраструктуры.
- Выявленные отклонения и недостатки программного обеспечения, сказывающиеся на скорости обработки обращения.
Инцидент носит временный характер и является единичным происшествием, которое пагубно воздействует на лояльность пользователей и скорость рабочего процесса предприятия. Необходимо как можно быстрее устранить инцидент и как можно быстрее нормализовать работу сервисов. В идеале без каких-либо негативных последствий для бизнеса.
Что такое проблемы и чем они отличаются от инцидентов?

Инциденты одиночные происшествия, которые могут и не возникать повторно с течением времени. Проблемы — это неизвестные причины, приводящие к появлению одного или нескольких инцидентов на постоянной основе. Например, каждую неделю пользователь сталкивается с перезагрузкой сервера. Если решать проблему поверхностно, потребуется направлять сотрудника технической поддержки к клиенту несколько раз в месяц. Это увеличивает затраты всей компании. Комплексный подход позволит выявить первопричину неполадок (проблему) и устранить ее. Важность сбора данных об инцидентах IT систем невозможно переоценить. Их анализ позволит зафиксировать появление глобальных проблем в работе, сохранить удовлетворенность пользователей предоставляемыми услугами и снизить общие убытки компании.
Что такое система управления инцидентами?
Чтобы дать подробное определение понятия, нужно разобраться с терминологией IT-служб, расшифровать наиболее важные понятия в управлении инцидентами.
Предприятие, предоставляющие определенный комплекс услуг или информационный продукт, осуществляет свою деятельность на основе SLA — соглашения об уровне обслуживания пользователя. Инциденты, возникающие в ходе работы, могут повлиять на соблюдения условий договора. Для обеспечения качества предоставляемого продукта, был разработан специальный подход к управлению инцидентами—ITSM (IT Service Management). Его основными составляющими является:
- фиксирование случаев неправильного функционирования IT систем;
- их каталогизация;
- управление инцидентами, проблемами, конфигурациями и.т.д;
- налаживания взаимодействия разных подразделений для совместного устранения инцидентов и других ошибок;
- налаживание работы компании и улучшения качества предоставляемых услуг.
ITSM базируется на определенном своде правил и практик, которые описаны в ITIL (библиотеке инфраструктуры информационных технологий). С внедрением системы управления инцидентами качественно улучшается функционирование всей системы, конкурентоспособность предприятия, лояльность клиентов и экономическая прибыль. На ее основе создаются службы, помогающие бизнесу организовать работу в ИТ среде: HelpDesk, ServiceDesk или более продвинутая версия MySmartService. Подобная система управления увеличивает скорость обработки происшествий, их устранение и увеличение удовлетворенности пользователей поставляемыми услугами. Также службы берут на себя полную ответственность за соблюдение SLA соглашения перед клиентом, их работа основана на принципах ITIL.
Процесс управления инцидентами можно разделить следующим образом:
Шаг 1. Фиксация инцидента.
Инцидент можно зафиксировать с помощью телефонных звонков, электронных писем, SMS, веб-форм, размещенных на корпоративном портале, или через сообщения в чате.
Шаг 2: Категоризация инцидента.
Инциденты можно классифицировать и разбить на подкатегории в зависимости от области ИТ или бизнеса, в которой инцидент вызывает сбой, например сети, оборудования и т.д.
Шаг 3: Приоритезация инцидента.
Приоритет инцидента может быть определен на основе его воздействия и срочности с помощью матрицы приоритетов. Воздействие инцидента означает степень ущерба, которую проблема причинит пользователю или компании. Срочность инцидента указывает время, в течение которого инцидент должен быть разрешен. По приоритету инциденты можно классифицировать как:
- Критический
- Высокий
- Средний
- Низкий
Шаг 4: Назначение ответственного.
После того, как инцидент классифицирован и расставлен по приоритетам, автоматически назначается технический специалист с соответствующим опытом.
Шаг 5: Создавайте задачи и управляйте ими.
В зависимости от сложности инцидента его можно разбить на задачи и/или подзадачи. Задачи обычно создаются, когда для разрешения инцидента требуется участие нескольких технических специалистов из разных отделов.
Шаг 6: Управление и продвижение SLA.
Во время обработки инцидента технический специалист должен убедиться, что SLA не нарушается. SLA — это приемлемое время, в течение которого на инцидент должен быть дан ответ (Response SLA) или разрешен (Resolution SLA). SLA могут быть назначены инцидентам на основе их параметров, таких как категория, инициатор запроса, влияние, срочность и т. Д. В случаях, когда SLA вот-вот будет нарушено или уже было нарушено, инцидент может быть функционально или иерархически повышен, чтобы гарантировать, что он будет разрешен как можно скорее.
Шаг 7: Разрешение инцидента.
Инцидент считается решенным, когда технический специалист нашел временное или постоянное решение проблемы.
Шаг 8: Закрытие инцидента.
Инцидент может быть закрыт после того, как проблема будет решена, и пользователь примет решение и будет удовлетворен им.
Почему так сложно управлять инцидентами?
Организовать работающую систему управления инцидентами на предприятие собственными силами достаточно сложно. Это происходит в связи со следующими причинами:
- Необходим не только учет инцидентов, но и их приоритетная расстановка, от которой зависит правильное распределение времени на решение задачи.
- Нужно координировать работы сразу нескольких служб одновременно.
- Распределять нагрузку на разные отделы равномерно.
- Учитывать связь между системами филиалов.
- Брать личную ответственность за локальные решения сотрудников.
- Учитывать компетенцию специалистов, стоимость их работы.
- Организовать несколько линий поддержки, укомплектовать их нужными специалистами.
- Создать систему числовых метрик с точным указанием времени на решение определенных типов инцидентов.
- Расширять количество персонала в зависимости от роста компании, проводить модернизацию рабочих инструментов и переподготовку сотрудников.
Кроме всего этого, нужно тщательно фиксировать выявленные инциденты, процесс работы по их устранению, удовлетворенность пользователей. Подобный анализ позволит повысить уровень обслуживания, снизит риск возникновения будущих проблем. Для организации всего процесса, нужно привлекать дополнительные рабочие ресурсы, либо воспользоваться специализированными поставщиками решений Service Desk / ITSM.
Как внедрить систему управления инцидентами?
Внедрить систему управления инцидентами можно двумя путями: организовав специальный отдел с наемными сотрудниками; воспользоваться компьютеризированными решениями поставщиков Service Desk / ITSM. Второй вариант решения обладает большим количеством преимуществ:
- Постоянный доступ к информации об инциденте для всего персонала техподдержки.
- Сокращение времени обслуживания.
- Точная процедура отслеживания, эскалации и отработки инцидента.
- Доступность и актуальность управленческой информации.
- Устранение ее потерь, ошибок и дублирования.
- Оптимальное использование квалификации персонала на всех линиях.
- Налаживание связи структурных подразделений компании.
- Составление отчетов и чек-листов.
Компьютеризированные системы Service Desk полностью интегрированы с важными компонентами управления ИТ-ресурсами. Они позволяют экономить средства на привлечение дополнительного персонала или переподготовки действующего. Компьютерные программы точно передают информацию без искажений и ошибок, могут предоставлять дополнительные сведения управляющему составу компании.
Каковы особенности хороших инструментов управления инцидентами?

Поставщики решений Service Desk / ITSM предлагают широкий набор инструментов и функций управления жизненным циклом инцидентов. Они позволяют быстро обнаружить причину проблемы и смягчить ее последствия. MySmartService представляет собой облачное программное решение, которое объединяет традиционные и современные инструменты управления инцидентами. К особенностям сервиса относится:
- Легкое управление и отслеживание всех инцидентов на протяжении всего жизненного цикла, настраивайте пользовательские статусы.
- Автоматическое распределение задач в зависимости от занятости сотрудников.
- Автоматическое назначение ответственных на основе опыта технических специалистов или групп для точного и быстрого разрешения инцидентов.
- Обеспечение быстрого разрешения, установив SLA.
Как ServiceDesk может помочь в системе управления инцидентами?
SmartService современный инструмент управления проектами, платформа, которую можно использовать для управления инцидентами. В отличие от других решений она включает ряд функций обычно недоступных при работе с подобными системами. Это дает дополнительные возможности для улучшения рабочего процесса, делает работу технической поддержки понятной и прозрачной для пользователей. В итоге бизнес экономит средства, увеличивает прибыль и конкурентоспособность на рынке услуг.
Попробовать Smart Service
Резюме
Сфера ИТ-услуг усложняется с каждым годом, растут требования к организации процесса и функционирования IT-инфраструктуры. Эффективность сопровождения рабочих программ и оборудования имеют большое значение для достижения бизнес целей. Service Desk — единая точка контакта для пользователя, ИТ-персонала, возможных поставщиков вспомогательных услуг компании. Она помогает:
- зафиксировать инцидент, причислить его к определенной категории важности, перенаправить в нужный отдел;
- вести учет времени его устранения, сохранять важную информацию и контролировать процесс на всех этапах;
- информировать пользователя о состояние проблемы в режиме реального времени;
- оповещение руководства о возможных задержках устранения инцидента и их причинах;
- формирование управленческой информации-степени загруженности ресурсов, производительности и эффективности услуг, возможном обучении клиентов, общей стоимости услуг или их дефиците.
Service Desk выполняет ряд экономически выгодных для компании функций: снижает стоимость владения ИТ-инфраструктурой с помощью повышения эффективности ее работы; оптимизирует инвестиции и управляет функциями поддержки бизнеса; выявляет возможные пути развития с последующим получением прибыли; увеличивает лояльность клиентов и их повторное обращение в конкретную фирму; участвует в формирование прибавочной стоимости.
Ранее в своих материалах о том, как защититься от DDoS-атак, мы неоднократно советовали составить план своей инфраструктуры, ее уязвимых мест и первичных действий при кибератаках. Сегодня поговорим о том, что такое план реагирования на киберинциденты, почему он нужен каждой организации, как его составить и что он в себя включает.
По мере развития изощренности кибератак, должна трансформироваться и стратегия их предотвращения. К сожалению, многие компании полагаются на устаревшие планы, а еще большее количество и вовсе их не имеет.
Чтобы увеличить шансы пережить непредвиденную атаку и сохранить репутацию, любому бизнесу, проекту, компании нужно задуматься о создании плана реагирования на инциденты кибербезопасности.
Что такое инцидент кибербезопасности
Инцидент кибербезопасности — это ситуация, которая ведет к нарушению политики информационной безопасности организации и подвергает риску ее конфиденциальные сведения: личные данные клиентов, государственные, коммерческие и врачебные тайны. Далее в тексте вы встретите аббревиатуру КБ — это сокращенный вариант термина «кибербезопасность».
Национальный координационный центр по компьютерным инцидентам (НКЦКИ) выделяет следующие виды инцидентов кибербезопасности:
| 1. DoS-атаки | 8. несанкционированный вывод объекта из строя |
| 2. DDoS-атаки | 9. публикация в объекте мошеннической информации |
| 3. рассылка спама с объекта | 10. использование объекта для распространения вредоносного ПО |
| 4. захват сетевого трафика объекта | 11. социальная инженерия, направленная на компрометацию объекта |
|
5. компрометация учетной записи в объекте |
12. публикация в объекте запрещенной законодательством РФ информации |
| 6. успешная эксплуатация уязвимости в объекте | 13. несанкционированное изменение информации, обрабатываемой в объекте |
| 7. внедрение в объект модулей вредоносного ПО | 14. несанкционированное разглашение информации, обрабатываемой в объекте |
Атаки могут производиться бесчисленным количеством способов, поэтому невозможно разработать единую инструкцию для решения всех нарушений. Каждый отдельный тип инцидента нуждается в уникальной стратегии реагирования. Далее рассмотрим несколько типов угроз, основанных на общих векторах атак. Они помогут определиться с выбором стратегии реагирования.
Типы инцидентов КБ по вектору атаки:
Внешний или съемный носитель: атака выполняется со съемного носителя (например, флэш-накопителя, компакт-диска) или периферийного устройства.
Истощение: атака, в которой используются методы компрометации, ухудшения качества или уничтожения систем, сетей или сервисов. Механизм заключается в подборе учетных данных пользователя для получения несанкционированного доступа.
Веб: Атака, осуществляемая с сайта или веб-приложения.
Email: атака идет с помощью сообщений на электронную почту или вложения, ее цель — скомпрометировать данные пользователя. Этот вид атаки известен под названием «фишинг» и является одним из наиболее распространенных.
Ненадлежащее использование: любой инцидент, возникший в результате нарушения авторизованным пользователем политики организации.
Потеря или кража оборудования: потеря ноутбука, смартфона или другого носителя информации, используемого организацией.
Эксперт компании DDoS-Guard, руководитель направления защиты L7 Дмитрий Никонов, отмечает: «Мы видим, что атаки становятся более интеллектуальными. Мы активно наблюдаем за созданием геораспределенных ботнет-сетей, которые включают в себя почти все континенты планеты.
Злоумышленники создают и выкладывают проекты с открытым кодом, и инструкцией как развернуть проект у себя на ПК, чтобы стать частью ботнета. Наиболее популярные атаки сейчас: backdoors, malware, ransomware, phishing и website defacement.
Из уникальных примеров можно выделить случай, когда злоумышленники использовали онлайн-игру для атак. Все пользователи, которые заходили в нее, автоматически становились участниками централизованной атаки на определенные веб-ресурсы».
Возможные цели и мотивы злоумышленников:
| 1. вымогательство | 6. создание нечестной конкуренции |
| 2. похищение средств | 7. демонстрация силы и возможностей |
| 3. уничтожение бизнеса | 8. ущерб репутации компании или государства |
| 4. корпоративный шпионаж | 9. площадка для дальнейших атак на другие компании |
| 5. государственный шпионаж | 10. похищение ценной информации для ее продажи или использования |
Что такое план реагирования на инцидент кибербезопасности
План реагирования на инциденты кибербезопасности — это свод четко регламентированных правил, где прописаны шаги, которые сотрудники должны выполнять при обнаружении опасности. План разрабатывается совместно с высшим руководством организации и SOC (Центр информационной безопасности). Составляются сценарии по реагированию на самые распространенные методы атак. Это поможет сотрудникам правильно и оперативно действовать в любой критической ситуации.
План реагирования может использоваться в качестве руководства при ряде действий:
- обнаружение угроз;
- реагирование на инциденты;
- анализ и документирование инцидента;
- взаимодействие между подразделениями внутри организации;
- определение необходимых шагов для повышения эффективности процедур реагирования.
Необходимо регулярно проводить тестовый контроль обучения, чтобы план реагирования был знаком команде. Реакция должна быть чёткой и быстрой. Ошибки крайне нежелательны, поэтому важно проверять план на практике и анализировать скорость устранения инцидента.
Почему каждой организации нужен план реагирования
Злоумышленники атакуют как небольшие проекты, так и крупные компании, среди которых банки, энергетические компании, медиаресурсы, ИТ-предприятия и другие. Сегодня кибербезопасность — стратегическая необходимость для каждой организации.
В 2020 году компания IBM опубликовала отчет, согласно которому, лишь 26% компаний имеют четкий план реагирования на киберинциденты. Низкий уровень защищенности чреват для бизнеса и общества серьезными последствиями. Общее число происшествий растет ежеквартально, злоумышленники постоянно совершенствуют атаки, а их эффективность только повышается, поэтому важно быть начеку.
Согласно анализу компании Dragos, которая занимается вопросами кибербезопасности, средняя стоимость одного киберинцидента обходится пострадавшей стороне почти в $3 миллиона. В сумму включены расходы на устранение пришествия, и при этом они не включают упущенную выгоду.
Компания Veeam опубликовала отчет о тенденциях в области защиты данных за 2022 год, согласно которому:
- 76% организаций подверглись хотя бы одной атаке программ-вымогателей;
- 24% либо не подвергались атаке, либо еще не знают об этом;
- 42% сотрудников компаний активировали фишинговые ссылки;
- 43% инцидентов были вызваны невнимательностью со стороны администратора.
По данным опроса, в котором участвовали 1376 непредвзятых организаций, в среднем, пострадавшим удалось восстановить только 64% своих данных. Это означает, что более 1/3 данных невозможно восстановить.
Три причины, почему вам нужен план реагирования на киберинциденты
1. Сотрудники будут готовы к сложным ситуациям. Грамотно составленный план поможет вашей команде чувствовать себя уверенно. В критической ситуации каждый сотрудник будет знать, что ему делать. Это сохранит время и позволит быстро среагировать на инцидент.
2. Сохраните репутацию, деньги и нервы. Чем быстрее обнаружите вторжение злоумышленников, тем безболезненнее предотвратите возможные последствия. Хакеры не смогут завершить процесс взлома, а значит не потребуют выкуп за украденные данные или не навредят другим способом.
3. Компания будет под надежной защитой надолго. Невозможно гарантировать, что после одной атаки не последует следующей. Если у вас будет четкий план реагирования, вы не только сможете им воспользоваться, но и неоднократно улучшить, чтобы все последующие атаки все меньше воздействовали на инфраструктуру компании. Ваша команда разберет все шаги и ошибки, которые привели к атаке, что позволит действовать эффективнее в будущем.
Как составить план реагирования на инциденты кибербезопасности
План реагирования на киберинциденты должен включать в себя понятную схему действий и подробные пошаговые инструкции к ним. Для разработки плана привлекайте специалистов, которые будут участвовать в реагировании и устранении угроз.
План должен быть согласован и утвержден с высшим руководством организации. К разработке и процессу согласования могут быть привлечены также юридические специалисты и другие ответственные лица.
6 этапов создания плана реагирования на киберинциденты

1. Подготовка
На этом этапе строится вся архитектура вашего плана. Формируются основные компоненты процесса реагирования и выполняются следующие задачи:
1.1. Создать и описать стандарты политики безопасности.
1.2. Создать команду реагирования и определить роли сотрудников.
1.3. Создать и описать политику реагирования.
1.4. Определить план коммуникации для команды реагирования и всех заинтересованных сторон.
1.5. Создать журнал документирования инцидентов, в котором каждая ответственная сторона должна описать свои шаги на каждом этапе реагирования:
- кто отреагировал?
- что было затронуто?
- где произошел инцидент?
- почему было принято то или иное действие?
- как действие помогло и если нет, то описать возможную причину.
1.6. Провести обучение команды.
1.7. Проверить контроли доступа.
2. Обнаружение
На этом этапе команда должна оперативно определить, следует ли реализовывать план реагирования. Необходимо тщательно анализировать сообщения об ошибках и следить за состоянием системы.
При обнаружении подозрительной активности, предупредите всех членов команды реагирования как можно скорее. На этом этапе эффективно настроенная коммуникация критически важна.
Следует убедиться, что вся команда после обнаружения угрозы начала документировать свои действия по реагированию в журнале инцидентов (см. раздел 1.5.)
Обнаружение потенциальных угроз является обязанностью всех сотрудников компании вне зависимости, входят они в команду по реагированию на инциденты или нет. Это должно быть четко отражено в политике безопасности и регулярно повторяться на учебных мероприятиях.
Например, отдел маркетинга обнаружил странную активность на своем компьютере после открытия ссылки, которая пришла на почту. Сотрудник должен незамедлительно сообщить ответственному лицу из команды реагирования о ситуации.
3. Сдерживание
Цель данного этапа — оперативно предотвратить повреждение сети, даже если это задерживает основные бизнес-процессы. Сдерживание состоит из следующих шагов:
3.1. Краткосрочное сдерживание. Постарайтесь предотвратить дальнейшее повреждение сети и сделать это быстро. Несколько примеров краткосрочной стратегии сдерживания:
- отключение зараженных устройств из сети;
- изоляция зараженного элемента сети;
- отключение маршрутизатора в зараженных сетях.
3.2. Выполните судебную экспертизу, если того требует устав вашей компании.
3.3. Регулярно делайте резервные копии системы. Это образ диска с программным обеспечением и данные, которые сохранены на нем. Процедура необходима для того, чтобы в случае критических изменений была возможность вернуть систему в исходное рабочее состояние. Также сохраните копию зараженной системы, чтобы в дальнейшем была возможность проанализировать инцидент.
3.4. Долгосрочное сдерживание. Восстановите работоспособность бизнеса путем исправления затронутых систем, удаления backdoor, либо перенаправьте сетевой трафик для очистки систем резервного копирования.
3.5. Протестируйте бизнес-операции, чтобы убедиться, что они вернулись к рабочему состоянию.
4. Ликвидация
Первые шаги по ликвидации киберугрозы предпринимаются уже на 3 этапе (сдерживание). Они продолжаются до завершения этапа ликвидации.
Условия по устранению включают:
- Сканирование зараженных систем на наличие вредоносных программ и их следов.
- Отключение зараженных систем, чтобы защитить сеть.
- Устранение уязвимостей в исправных резервных копиях.
5. Восстановление
На этом этапе идет возвращение систем в их первоначальное состояние. Процесс начинается с замены сред, уже прошедших стадию ликвидации, безопасными резервными копиями.
Важно помнить, что копии могут содержать те же уязвимости, которые и привели к инциденту. Поэтому зараженные файлы необходимо устранить в первую очередь.
Перед повторным подключением всей восстановленной системы рекомендуется проверить журнал событий системы на предмет аномалий, которые укажут на продолжающееся заражение вредоносным ПО или же наличие АРТ-атак (Advanced Persistent Threat).
6. Получение знаний
Цель этапа — завершение документации по прошедшему циклу атаки. В отчете следует четко прописать всю последовательность действий. Описание должно быть понятно заинтересованным сторонам.
Рекомендуется собраться всем участникам инцидента не позднее двух недель после события. На встрече следует обсудить киберинцидент, его обнаружение, обработку и устранение, а также предложить варианты по возможному улучшению каждого из этапов.
На обсуждении участники могут обсудить следующие вопросы:
- Кто обнаружил инцидент?
- Кто сообщил об инциденте?
- Как локализовали инцидент?
- Когда был обнаружен инцидент?
- Кому было сообщено об инциденте?
- Как очищали скомпрометированные системы?
- Какие процессы задействовали для восстановления?
- В какой области команда наиболее эффективно сработала?
- Какие шаги были приняты для анализа успеха мер по ликвидации?
- Как можно улучшить действия по реагированию на возможные киберугрозы?
Подходите к составлению плана как к жизненному циклу, где каждая фаза реагирования идет в правильной последовательности. Шаги должны основываться на понимании и четкой работе.
Что должно быть в плане реагирования: чек-лист из 10 шагов
Когда случается непредвиденная ситуация, нет времени разбирать стратегии реагирования. В таком случае пригодится сжатая и полезная информация о том, какие шаги следует предпринять в кратчайшие сроки, чтобы ликвидировать угрозу.
Используйте инструкцию по контрольному списку действий реагирования на киберинциденты.

Что должен включать в себя план реагирования на инциденты
1. Оценка рисков в масштабе организации
Основной целью является определение вероятности рисков в инфраструктуре кибербезопасности.
2. Анализ инфраструктуры предприятия в ключевых областях
Используйте оценку рисков для выявления уязвимых мест. Определите и опишите приоритет реагирования по низким и средним рискам.
3. Определение членов команды реагирования
Задокументируйте роли и обязанности каждого ключевого лица команды. Проведите обучение, и протестируйте функции команды.
4. Документирование и приоритизация основных типов киберинцидентов
В плане реагирования должно быть определено, что считается инцидентом и кто отвечает за активацию стратегии реагирования. Важно выявить и описать приоритет инцидентов. От этой информации будет зависеть насколько оперативно произойдет обработка угрозы, и какие ресурсы будут задействованы для нормализации и восстановления инфраструктуры компании. Обновляйте информацию в документах, изучайте новые атаки злоумышленников и хакерские тренды.
5. Инвентаризация всех ресурсов и активов компании
- Бизнес-ресурсы: члены команды, отдел кибербезопасности, деловые партнеры.
- Бизнес-процессы: частичное сдерживание, стратегия наблюдения и отключения системы, деактивация, — все эти ресурсы следует включить в ваш план реагирования. Воспользуйтесь ими в зависимости от типа и серьезности нарушения безопасности.
6. Создание блок-схем с иерархией полномочий и последовательностью действий команды реагирования
Определите шаги, которые нужно выполнить на разных этапах реагирования. Выявите, кто является ответственным менеджером на этих этапах, а кто контактным лицом между вами, вашими клиентами, правоохранительными органами, СМИ.
Все данные соберите в единую схему полномочий.
7. Актуализация контактной информации о команде реагирования и всех заинтересованных сторон (страховые компании, юристы и так далее)
Составьте базу контактной информации, которая будет обновляться. Команда сможет обратиться к ней в критической ситуации, чтобы не тратить время на поиски.
8. Подготовка шаблонов публичных заявлений
Заранее спланируйте публичные заявления. Шаблоны должны быть на разные случаи: электронные письма скомпрометированным пользователям, письма для связи со СМИ, шаблоны заявлений о нарушении. Отнеситесь внимательно к информации, которую сообщаете массовой аудитории.
9. Подготовка и ведение журнала инцидента
Во время и после инцидента кибербезопасности вам потребуется отслеживать как, кто, когда и где обнаружил и устранил нарушение. Эта информация должна вноситься в журнал инцидента. Подготовьте шаблон заранее, чтобы его было легко заполнить. Он должен включать:
- место, время и характер обнаружения инцидента;
- детали связи: кто, что и когда;
- релевантные данные вашего ПО для создания актуальных отчетов о безопасности и журналов событий.
10. Разработка и описание стратегии тестирования эффективности мер реагирования
Совместно с командой реагирования пропишите несколько ключевых стратегий реагирования. Регулярно собирайтесь для обсуждения и улучшения данного процесса. Используйте руководства, шаблоны и чек-листы, которые будут дополняться и расширяться в соответствии с актуальными изменениями.
Примеры плана реагирования на инциденты кибербезопасности
В сети есть общедоступные примеры планов реагирования на киберинциденты. Мы собрали несколько полезных и эффективных шаблонов, которые можно использовать как руководство, чтобы создать собственный план реагирования. Изучите примеры и адаптируйте под свою компанию. Обратите внимание, что все документы англоязычны.
1. Шаблон Национального института стандартов и технологий (NIST)
Основные разделы документа:
- организация реагирования;
- регулирование;
- координация и обмен информацией;
- сценарии обработки;
- анализ данных, связанных с инцидентом.
2. Шаблон Калифорнийского института технологий
Файл содержит 17-шаговую базовую процедуру реагирования на инциденты со ссылками на более подробные специализированные планы. Кратко рассмотрены различные типы инцидентов.
3. Шаблон Института передовых технологий (SANS)
Руководство разработано институтом SANS и базируется на общедоступных источниках. SANS является одним из крупнейших в мире исследовательских центров в области кибербезопасности.
В документе представлены подробные рекомендации и стандарты реагирования на различные угрозы. Он доступен для использования, изменения и переформатирования в соответствии с конкретными потребностями вашей организации.
Еще один полезный инструмент — чек-лист Microsoft для подготовки вашей команды безопасности к реагированию на инциденты кибербезопасности.
Является ли план реагирования обязательным
Наличие плана реагирования КБ имеет рекомендательный характер. Российское законодательство не предусматривает обязательным использование и разработку плана реагирования на киберинциденты. Однако ряд законов и ГОСТов регулируют юридическую сторону вопроса обеспечения информационной безопасности.
В частности ГОСТ Р ИСО/МЭК ТО 18044-2007 регулирует вопросы менеджмента инцидентов информационной безопасности, куда входят рекомендации по созданию плана реагирования на инциденты КБ.
Для принятия правильных правовых мер, следует точно определить уровень защиты информации вашей компании.
Выделяют три уровня системы защиты конфиденциальной информации:
- правовой;
- организационный;
- технический.
Важным моментом является не только установление самого перечня конфиденциальной информации, но и порядка ее защиты, а также порядка её использования.
В соответствии со ст. 10 Закона N 98-ФЗ по охране конфиденциальности информации, меры принимаемые ее обладателем, должны включать в себя:
- определение перечня данных, составляющих коммерческую тайну;
- ограничение доступа к таким сведениям путем установления порядка обращения с ними и контроля за соблюдением этого порядка;
- организацию учета лиц, получивших доступ к конфиденциальной информации, или лиц, которым она была предоставлена;
- регулирование отношений по использованию данных, составляющих коммерческую тайну, работниками на основании трудовых договоров и контрагентами на основании гражданско-правовых договоров;
- нанесение на материальные носители и документы, содержащие конфиденциальную информацию грифа «Коммерческая тайна» с указанием владельца такой информации.
В соответствии с ГОСТ Р 50922-2006 можно выделить следующие меры защиты конфиденциальной информации:
- защита от утечки;
- защита от разглашения;
- защита от неправомерного воздействия;
- защита от преднамеренного воздействия;
- защита от несанкционированного доступа;
- защита от несанкционированного воздействия.
Как использовать информацию об инцидентах КБ для избежания их в будущем
Используйте всю собранную информацию по прошедшим инцидентам для регулярного обучения сотрудников. Совместно с командой реагирования разбирайте шаги плана реагирования и пересматривайте действия. Анализ и обсуждение всех инцидентов позволит улучшить и внедрить новые элементы управления. Рекомендуется пересматривать политику реагирования минимум раз в год.
Если у вас еще нет команды реагирования на инциденты кибербезопасности, пришло время ее создать. Включите в команду ключевых членов компании: специалистов отдела безопасности, юристов, PR-специалистов.
Подведем итоги
План реагирования на инциденты кибербезопасности — это необходимая мера защиты, которая поможет пережить эмоциональный хаос, часто сопутствующий атакам. Сценарий реагирования даст понятную стратегию смягчения последствий и минимизирует воздействие активных киберугроз.
Ваш план должен стать четким и действенным документом, который удобно использовать в самых разнообразных сценариях.
Помните, что защита вашей организации от кибератак — это масштабный процесс, который включает в себя различные этапы: от базы, на которой строится защита сетевой инфраструктуры, до создания плана реагирования на киберинциденты.
Пока вы маленький старпап, команда легко справляется со всеми ошибками и сбоями сама. Если вы развиваетесь, и делаете это быстро, неизбежно приходит время, когда разработчиков становится больше, компания — крупнее, а проблемы перестают быть локальными и требуют участия смежных команд для их решения. Так и Skyeng прошел путь от маленького стартапа до известной онлайн-школы. Сейчас на платформе десятки тысяч учеников, 40 распределенных команд разработки и сотни сервисов, взаимодействующих друг с другом.
Конечно, в какой-то момент инциденты вышли за пределы наших команд, и мы задумались о едином подходе работы с ними. Ответственным за процесс организации оказался я — Дима Кузнецов, один из юнит-лидов в Skyeng. Так в декабре 2019 года мы создали MVP этого проекта, и к TechLead Conf 2020 получили первые результаты, о чем я и рассказал на конференции. Сегодня я опишу, каким был процесс и что мы получили в результате.

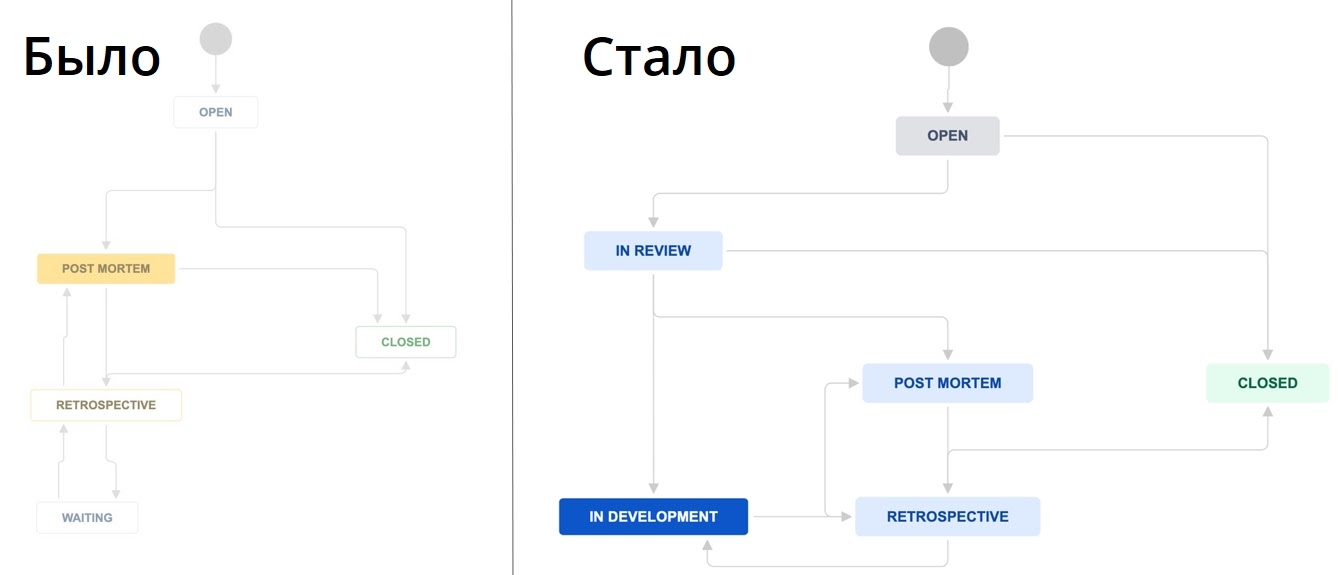
План был очень простым
Мы сформировали рабочую группу и на старте решили сфокусироваться только на серьезных инцидентах, чтобы получить больше эффекта в краткосрочной перспективе.
Сам MVP-процесс описали вот так:
-
Заводим канал #dev-disaster в Slack для быстрого реагирования на критические инфраструктурные сбои. Например, если сервис недоступен на проде, его разработчик пишет об этом — и дежурный сотрудник инфраструктуры подключается, чтобы помочь исправить проблему. Slack — наш основной инструмент коммуникации, поэтому выделенный канал для таких проблем должен стать отличной точкой старта. Плюс мы будем видеть, сколько обращений было на входе.
-
Инцидент фиксируется задачей в Jira, а заводить его будет QA. У него будет на это время, пока разработчик с сотрудником инфраструктуры решают проблему. Так мы увидим конверсию в инциденты на выходе: то есть сможем измерить, работает ли процесс и фиксируется ли сбой.
-
Когда инцидент устранен (и QA убедится в этом), пишем обязательный Postmortem (так как все рассматриваемые сбои у нас критичные). Постмортем пишет тот, у кого больше контекста: это может быть как разработчик, так и сотрудник инфраструктуры.
-
Инциденты за неделю разбирает рабочая группа: два руководителя разработки, руководитель эксплуатации инфраструктуры, руководители DevOps и QA. В первую очередь обращаем внимание на наличие системных проблем — тех, что могут возникать не только у одной команды. В процессе контролируем выполнение action-плана по устранению инцидента. А когда все задачи в составе инцидента выполнены, считаем инцидент проработанным и закрываем его.
Схема процесса получилась такой:
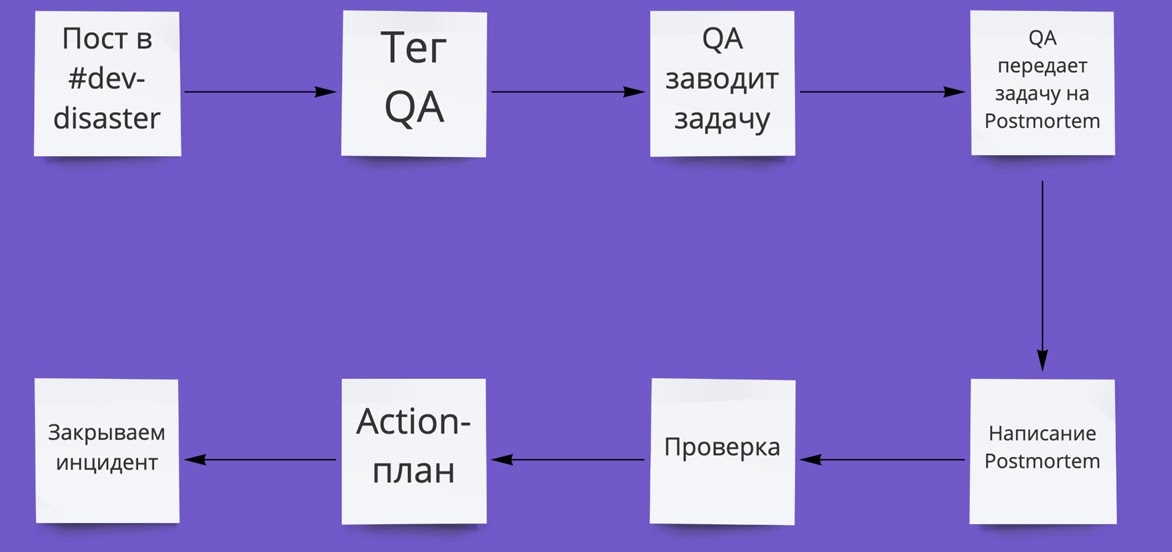
Я оформил этот регламент в Confluence, анонсировал в паре публичных каналов в Slack, и мы стали наблюдать, как все работает на практике.
Картина через месяц
Уже на первом еженедельном разборе мы увидели, что сам еженедельный разбор работает отлично, но фиксируется лишь часть инцидентов. Конверсия зафиксированных сбоев — количество постов из #dev-disaster, для которых были заведены задачи в Jira — была меньше 20%.
Когда я начал разбираться, вскрылось много интересного. У кого-то из команд не были настроены мониторинги и алертинги — из-за чего мы знать не знали про некоторые сбои. Кто-то пропустил анонс из-за информационного шума в мессенджере. У некоторых команд еще не было QA — и они решили, что к ним процесс не относится. Другие почему-то посчитали, что их будут наказывать за сбои, хотя никаких наказаний не подразумевалось. А кто-то не хотел писать постмортем — «заполнять бумажки ваши, ну такое…».
Но чаще всего ребята банально забывали, что нужно сделать. Разработчик забывал тегнуть QA. А тот — завести задачу и правильно ее оформить. Или не понимал, кому нужно передать написание постмортема. Назначенные SLA (3 дня) на написание постмортема не соблюдались, так как ответственные могли забыть про сроки или о том, чтобы перевести задачу в нужный статус.
Я мог бы с этим смириться и просто постоянно напоминать всем про процесс, смену статусов и так далее. Или мог бы делегировать эту задачу в отдел административных ассистентов, где коллеги по регламенту выполняли бы всю рутину: отправляли напоминалки и передвигали задачи. Но от перекладывания решения этой проблемы на других процесс лучше не станет. Поэтому я выбрал другой вариант.
Упрощаем
Наш MVP-процесс, как выяснилось, был непрозрачным, непонятным и неочевидным. Любые изменения внести в него было очень сложно — я и сам почти сразу столкнулся с этим. Недостаточно было просто изменить регламент — нужно было еще вручную отправить кучу уведомлений об этом. И надеяться, что их не только увидят, но запомнят и начнут учитывать.
Поэтому я решил всё это автоматизировать. И для этого нужно было собрать более полную картину происходящего.
Определяем маршруты инцидентов
Я собрал все источники, из которых мы могли узнавать об инцидентах: автотесты, аналитика, мониторинги команд разработки, инфраструктурные мониторинги и, конечно, техподдержка. Составил по каждому источнику схему обнаружения.
Вот, например, схема наших регулярных end-to-end тестов. Они отправляют отчеты о сбоях в отдельные Slack-каналы, где автоматизаторы анализируют отчет и находят места поломок. Если поломка критичная, то уведомление обязательно отправляется командам:

После составления схем стало очевидно, что все маршруты инцидентов упираются в команду разработки. Тогда мы договорились, что разработчик, узнавая о наличии инцидента, решал что лучше:
-
Если проблема инфраструктурная — писать в канал #dev-disaster и исправлять ее вместе с инфраструктурой;
-
Или, если это критичная бага на production, выполнить откат и решить проблему вместе с командой.

Определяем, что такое инцидент
По ходу процесса я также обратил внимание, что у ребят возникает непонимание того, что является инцидентом, а что — нет. И это даже без учета серьезности сбоев.
Поэтому мы выделили два типа сбоев:
-
Блокирующий инцидент — полная недоступность сервиса;
-
Критический инцидент — влияние на основной бизнес-процесс конкретного сервиса с учетом массовости его использования. Например, когда много пользователей не видят кнопки входа на урок в личном кабинете. Сюда же вошли сбои, которые хоть и не видны клиентам, но нарушают бизнес-процесс сервиса: например, если отвалились консьюмеры или не сработал cron.
В результате мы пришли к следующей схеме:

Тем не менее сами инциденты фиксировались все еще вручную, а я хотел упростить ребятам жизнь.
Упрощаем заведение инцидента
Можно было бы автоматически фиксировать любое сообщение в #dev-disaster как инцидент, но мне показалось, что если так сделать, то коллеги забудут через некоторое время о том, что мы просим фиксировать все виды инцидентов. Поэтому я сделал автоматизацию, которая при публикации поста в #dev-disaster спрашивала, является ли это инцидентом:
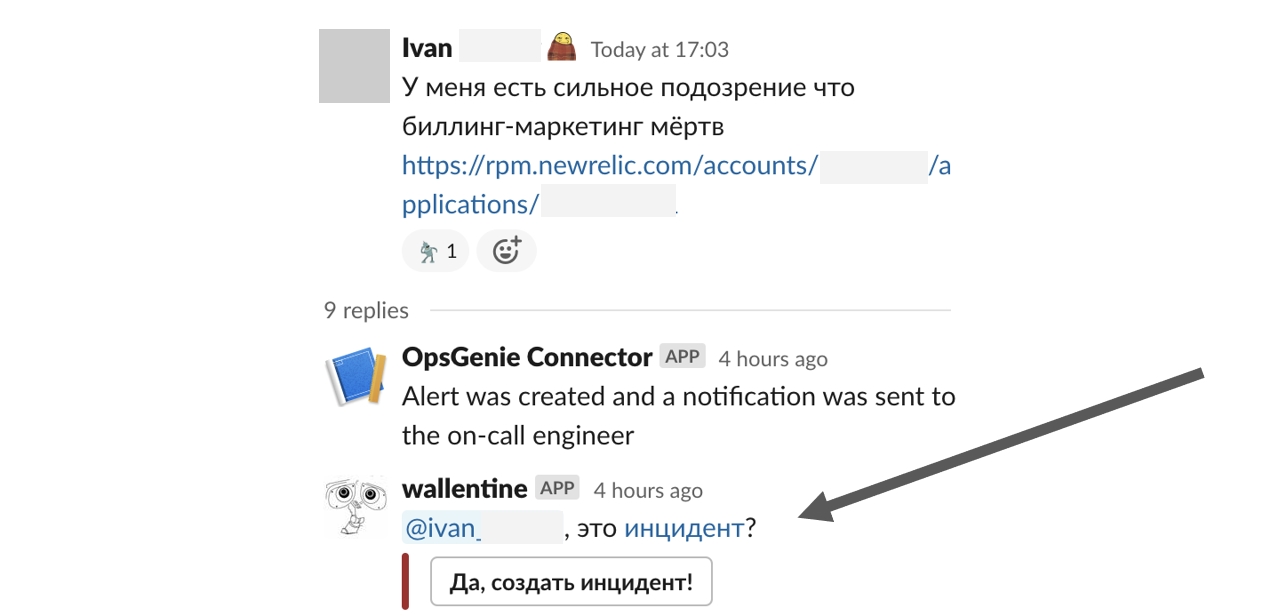
Одновременно это решило проблему того, что не все ребята помнили, где и как заводить задачу. Бот показывал модальное окно, в котором оставалось только дать название инциденту и выбрать его приоритет. Это же модальное окно можно было вызвать абсолютно из любого диалога в любом канале Slack, чтобы создать инцидент из треда:

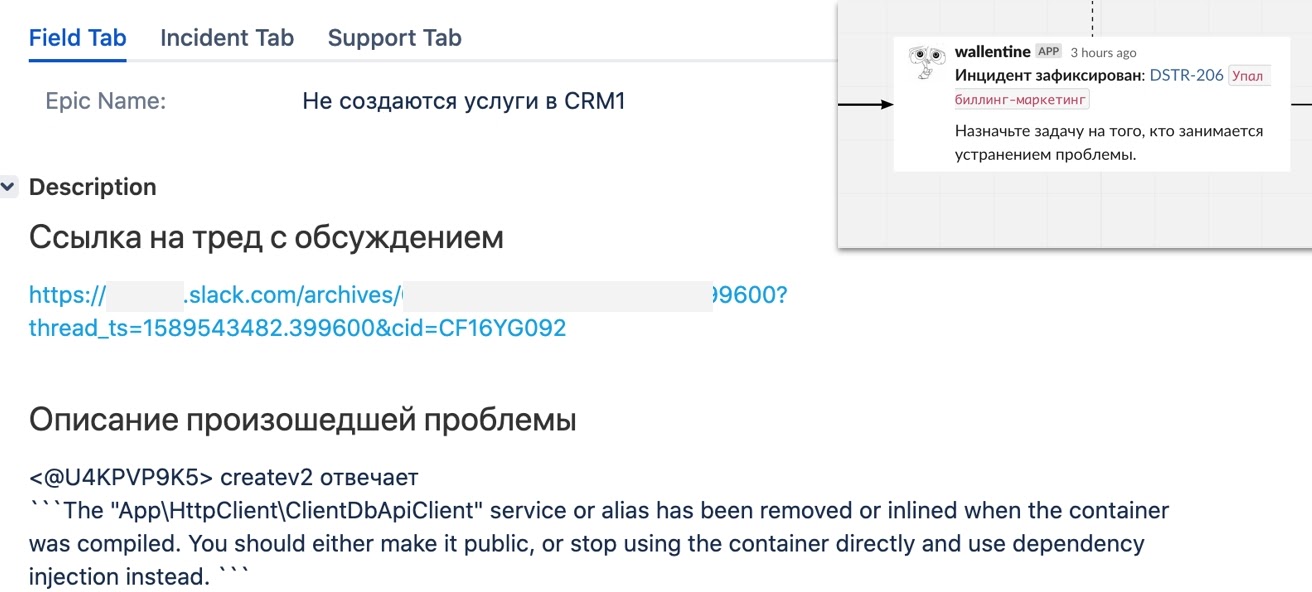
При нажатии «Зафиксировать» бот автоматически создавал задачу в Jira по шаблону: описание проблемы брал из поста в Slack, а в задачу добавлял ссылку на тред, чтобы по нему можно было восстановить всю историю инцидента:
После этого бот сообщал об этом в треде и предлагал назначить ответственного. А сами инциденты мы сделали эпиками, чтобы в них можно было создавать задачи для любых команд на исправление. Если у команды уже был свой эпик, — например, у нашей инфры это эпики, направленные на повышение стабильности — то задача просто линковалась из другого проекта с типом blocked by.
В результате мы могли смотреть статистику и по задачам, созданным от эпиков, и по тем задачам, которые слинкованы с таким типом.
Упрощаем воркфлоу в Jira
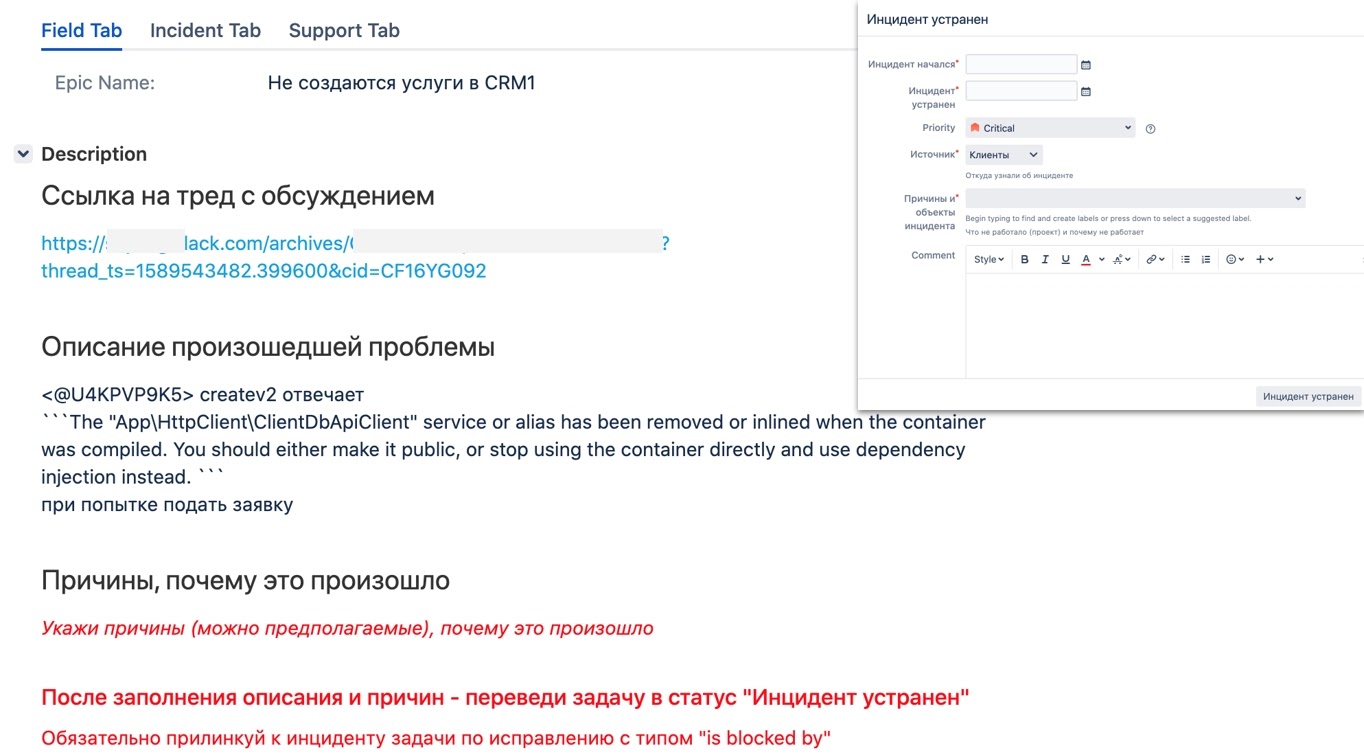
Чтобы коллегам легче работалось с инцидентами в Jira, я стал прямо в задачу дописывать краткие инструкции того, что нужно сделать дальше. А наполнение задачи обязательными данными реализовал с помощью перехода и диалогового окна. Это оказалось супер-удобно. Мне теперь не нужно было исправлять регламенты, чтобы изменить процесс. А ребята понимали, что от них ожидается на каждом этапе. Я просто добавлял новое обязательное поле в модельное окно и писал подсказку:
Убираем лишнюю бюрократию: делаем постмортем необязательным
Когда я проанализировал все инциденты, которые были зафиксированы за время работы MVP, то пришел к выводу, что Postmortem был нужен максимум в 30% случаев. Если до этого мы писали Postmortem после того, как инцидент был устранен, теперь, в результате работы бота, задача наполнялась минимально необходимой информацией в процессе создания.
Поэтому мы ввели статус ревью для задачи, где была указана причина сбоя, дата начала и устранения, а также источник. А дальше рабочая группа по инциденту принимала решение — нужно ли здесь писать постмортем (то есть, нужны ли нам подробности). Или по этой задаче и так все понятно — и ее можно переводить в ожидание выполнения action-плана. В результате команды стали делать меньше «бумажной» работы.
Запрашиваем постмортем только когда он нужен
Хотя постмортем и стал опциональным, я решил упростить и его создание. Теперь, чтобы запросить его, кто-то из рабочей группы:
-
перетаскивал задачу в соответствующий статус,
-
выбирал, кто будет писать постмортем,
-
и указывал дату, к которой хотел бы получить результат:

Сразу после этого человеку в личку уходило сообщение о том, что его просят составить постмортем к определенной дате. А в Confluence автоматически создавалась страница с шаблоном и той информацией, которая уже была в задаче:

А чтобы ребята не забывали про то, что от них требуется постмортем, незадолго до срока бот отправлял напоминание в личку. Внутри также была инструкция, что нужно сделать:

Еженедельный дайджест инцидентов
Благодаря автоматизации и упрощению процесса, у нас существенно возросло количество зафиксированных инцидентов и… мы перестали успевать разбирать все на еженедельном созвоне. Для решения этой проблемы мы внедрили новую идею — накануне встречи бот присылает нам емкую выжимку с самой важной информацией, на которую нужно обратить внимание:

Такой дайджест упростил нашу подготовку ко встрече. Мы с коллегой созванивались и определяли, какие инциденты считаем важными. Обычно это что-то серьезное, системное, что может повторяться у других команд. Это и становилось повесткой общей встречи. А заодно мы отправляли напоминания, проталкивая зависшие инциденты, если бота кто-то проигнорировал.
Составляем наглядную документацию
Когда я внедрял наш обновленный процесс, то решил не повторять ошибок. Вместо публикации в общий канал я провел встречи с каждым юнитом. Я показывал схемы и рассказывал, для чего это нужно, объясняя, что и от кого требуется. По ходу встреч я ответил на кучу вопросов и получил прекрасную обратную связь.
В итоге собрал всю документацию на доске в Miro, и это помогло нам избавиться от больших текстов в Confluence. Каждый участок процесса я разбил на этапы и для наглядности прикрепил скриншоты:

Взаимодействие с техподдержкой
Одним из источников информации о сбоях была техподдержка. Я обратил внимание, что коллеги и так регистрируют массовые обращения, как инциденты, но — в своих внутренних системах, о которых разработка была не в курсе.

Поэтому в процессе нашего проекта мы наладили синхронизацию между разработкой и сотрудниками технической поддержки, заведя канал в слаке #incidents. При регистрации инцидента бот присылал туда уведомление, а сотрудники техподдержки брали ситуацию под контроль и, если требовалось, доносили информацию до пользователей по прогнозам устранения.Этот прямой канал коммуникации с техподдержкой открыл нам неочевидные, на первый взгляд, возможности:
-
ребята научились сами регистрировать инциденты в случае массовых обращений, тем самым повысив общее количество регистрируемых событий;
-
сотрудники инфраструктуры получили понятное место, где можно делать анонсы о плановой недоступности.
Результаты
Благодаря автоматизации и выстроенным процессам, каждый месяц мы отслеживаем метрики по количеству инцидентов, среднему времени и сумме потерь (если ее удается посчитать). Инциденты при этом приоритизируются по серьезности и количеству возможных повторений. А в зависимости от проблемы, мы выбираем что будет лучше: быстрое локальное решение или системное, которое требуется раскатить на всю компанию.
А самое главное — мы шаг за шагом исправляем ошибки и улучшаем стабильность нашей системы в целом, сокращая сумму убытков из-за сбоев для бизнеса.
Эти результаты я описывал на TechLead Conf 2020. Но на этом наш процесс не остановился и за год работы видоизменился еще несколько раз. Сейчас у нас появилась команда SRE, тимлид которой курирует весь этот процесс. А наша база основных проблем и сбоев разрослась и структурировалась.
Еще мы столкнулись с тем, что достаточно сложно раскатить необходимые изменения, чтобы предупреждать инциденты. Такие задачи всегда конкурируют с продуктовыми. Поэтому мы придумали прозрачный способ, который уже три квартала подряд показывает хорошие результаты. Мы назвали его фреймворк стабилизации, но это тема для отдельной статьи:
Если вы задумались над внедрением подобного в своей компании:
-
Определитесь сразу, для чего это вам. Чтобы собирать метрики? Чтобы улучшать вашу систему? Для каких-то других целей?
-
Выберите ответственного за процесс и будьте готовы к тому, что он потратит на это много времени. Первое время, особенно пока работал MVP-процесс, я тратил 100% своего времени на его поддержку. С внедрением автоматизации стало проще, но инциденты нужно анализировать и разбирать, поэтому сократить свое участие до нуля можно только выйдя из проекта;
-
Определите метрики: какие хотите снимать и на какие хотите влиять. Это может быть количество инцидентов, время простоя или сумма потерь. Метрики помогут быстро понять, работает процесс или нет;
-
Очень важно, чтобы у ответственного за процесс было достаточно административного ресурса для изменений. У меня он был. Не уверен, что процесс заработал бы, отвечай за него разработчик, QA или кто-то из тимлидов — у нас очень много команд;
-
Определите путь инцидентов — как вы о них узнаете, из каких источников. Это поможет собрать общую картину и вы обязательно увидите какие-то точки пересечения;
-
Упрощайте процесс. Сложный процесс не будет работать. Команды будут его избегать, а вы будете тратить много сил и ресурсов на его поддержание.
-
Внедряйте процесс в режиме диалога: так вы быстрее сможете получить обратную связь и провести работу над ошибками, а также сходу закрыть кучу возражений. Возражения точно будут — не все будут понимать, для чего это нужно, и что от них требуется;
-
Держите процесс под контролем. Я выстроил несколько уровней подстраховки, что помогает нам теперь фиксировать 90% инцидентов. Напоминания, контроль со стороны рабочей группы, помощь техподдержки — без этого фиксаций было бы намного меньше.
TechLead Conf 2021 пройдет с 30 июня по 1 июля 2021 в московском отеле Radisson Slavyanskaya. Расписание можно посмотреть здесь. А билеты — здесь.
До встречи на конференции, полностью посвященной инженерным процессам и практикам


Инцидент
— Случай, столкновение, неожиданное
происшествие, как правило, неприятное,
связанное с конфликтом.
Для
производства и работы любого предсприятия
Инцидент – есть любое событие, которое
не является частью стандартных операций
сервиса и вызывает, или может вызвать,
прерывание обслуживания или снижение
качества сервиса.
Инцидент
Переход
конфликта из латентного состояния в
открытое противоборств происходит в
результате того или иного инцидента
(от лат. incidens – случай, случающийся).
Инцидент – это тот случай, который
инициирует открытое противоборство
сторон. Инцидент конфликта слезет
отличать от его повода. Повод – это то
конкретное событие, которое служит
толчком, предметом к началу конфликтных
действий. При этом оно может возникнуть
случайно, а может и специально
придумываться, но во всяком случае повод
еще не есть конфликт. В отличие от этого
инцидент – это уже конфликт, его начало.
Например,
Сараевское убийство – убийство наследника
австро венгерского престола Франца
Фердинанда и его жены, осуществленное
28 июня 1914 г. (по новому стилю) в городе
Сараево, было использовано Австро
Венгрией как повод для развязывания
Первой мировой войны. Уже 15 июля 1914 г.
Австро Венгрия под прямым давлением
Германии объявила войну Сербии. А прямое
вторжение Германии 1 сентября 1939 г. в
Польшу – это уже не повод, а инцидент,
свидетельствующий о начале Второй
мировой войны.
Инцидент
обнажает позиции сторон и делает явным
деление на «своих» и «чужих», друзей и
врагов, союзников и противников. После
инцидента становится ясным «кто есть
кто», ибо маски уже сброшены. Однако
реальные силы оппонентов еще до конца
не известны и неясно, как далеко в
противоборстве может пойти тот или иной
участник конфликта. И эта неопределенность
истинных сил и ресурсов (материальных,
физических, финансовых, психических,
информационных и т.д.) противника является
весьма важным фактором сдерживания
развития конфликта на его начальной
стадии. Вместе с тем эта неопределенность
способствует и дальнейшему развитию
конфликта. Поскольку ясно, что если бы
обе стороны имели четкое представление
о потенциале противника, его ресурсах,
то многие конфликты были бы прекращены
с самого начала. Более слабая сторона
не стала бы во многих случаях усугублять
бесполезное противоборство, а сильная
сторона, не долго думая, подавила бы
противника своей мощью. В обоих случаях
инцидент был бы достаточно быстро
исчерпан.
Таким
образом, инцидент часто создает
амбивалентную ситуацию в установках и
действиях оппонентов конфликта. С одной
стороны, хочется быстрее «ввязаться в
драку» и победить, а с другой – трудно
входить в воду «не зная броду».
Поэтому
важными элементами развития конфликта
на этой стадии являются: «разведка»,
сбор информации об истинных возможностях
и намерениях оппонентов, поиск союзников
и привлечение на свою сторону дополнительных
сил. Поскольку в инциденте противоборство
носит локальный характер, весь потенциал
участников конфликта еще не демонстрируется.
Хотя все силы уже начинают приводиться
в боевое состояние.
Однако
даже после инцидента сохраняется
возможность решить конфликт мирным
путем, посредством переговоров придти
к компромиссу между субъектами конфликта.
И эту возможность следует использовать
в полной мере.
Если
после инцидента найти компромисс и
предотвратить дальнейшее развитие
конфликта не удалось, то за первым
инцидентом следуют второй, третий и т.
д. Конфликт вступает в следующий этап
– происходит его эскалация (нарастание).
Так, после первого инцидента во Второй
мировой войне – вторжения Германии в
Польшу – последовали другие, не менее
опасные. Уже в апреле – мае 1940 г. немецкие
войска оккупировали Данию и Норвегию,
в мае – вторглись в Бельгию, Нидерланды
и Люксембург, а затем и во Францию. В
апреле 1941 г. Германия захватила территорию
Греции и Югославии, а 22 июня 1941 г. напала
на Советский Союз.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
|
Трагический инцидент произошел совершенно неожиданно. Очень странный инцидент, ведь никто его не ожидал. Инцидент в аэропорту поверг всех в шок. Необычайно сложно разобраться в причинах этого инцидента. Произошедшего вчера инцидента, вполне можно было избежать. Инциденты происходили на этой территории очень часто. автор вопроса выбрал этот ответ лучшим
Sophiya-777 2 года назад Недалеко от леса произошел опасный инцидент. Странный инцидент произошел с документами за три часа до судебного заседания. Более странного инцидента мне не доводилось видеть. В северном ледовитом океане произошел трагический инцидент. Странный инцидент, с которым предстоит еще разобраться. Знаете ответ? |


